
Word2Vec is a model for learning word embeddings, which converts words and their semantics into vectors through neural networks. Word2Vec provides two training methods: CBOW and Skip-gram, and improves efficiency through Negative Sampling and Subsampling technologies. This article will introduce the basic principles and training methods of Word2Vec.
The complete code for this chapter can be found in .
Table of Contents
Word Embeddings
In natural language processing (NLP), word embeddings are a way of representing words. This representation somehow encodes the word and its meaning into a real-valued vector. This makes words that are close in the vector space have similar semantics. Therefore, in such a vector space, assuming that the vectors of Germany and its capital Berlin and France are known, we can use the following formula to derive the vector of Paris, the capital of France.

Each word is represented as a vector; and a group of words will form a word embedding matrix. In the word embedding matrix below, each word is represented as a 300-dimensional vector.
| Word | Feature 1 | Feature 2 | … | Feature 300 |
|---|---|---|---|---|
| cat | 0.12 | -0.45 | … | 1.24 |
| dog | 0.10 | -0.50 | … | 1.30 |
| king | 0.80 | -0.22 | … | 0.65 |
| queen | 0.85 | -0.20 | … | 0.70 |
Word2Vec Model
Word2Vec is a word embeddings learning model proposed by Tomas Mikolov et al. of Google in 2013. The Word2Vec model can learn a word embedding matrix from a given corpus. The model contains two architectures, namely Continuous Bad-of-Words model (CBOW) and Continuous Skip-gram model.
Continuous Bag-of-Words Model (CBOW)
The learning method of CBOW is to predict the center word based on the context words of the center word. As shown in the figure below, the center word is fox, and the context window size is 2, so the context is the two words before and the two words after fox. During training, we calculate the average word embedding of context words as input, and the true label is the center word fox.

Forward Propagation
CBOW uses a neural network with only one hidden layer to learn word embeddings. After training, the weight of the hidden layer is the word embedding matrix. The figure below shows the forward propagation of CBOW.

The formula in CBOW’s forward propagation is as follows:

The dimensions of each variable are as follows:
 |  |  | 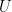 |  |  |
|---|---|---|---|---|---|
 |  |  | | | |
Loss Function
The output of CBOW is the probability of each word, so softmax is used as the activation function of the output layer. Therefore, cross-entropy loss is used as its loss function.

Backward Propagation
The formula in CBOW backpropagation is as follows:

Implementation
We use Wikipedia’s Oolong articles as the corpus to train the model. In the following code, we download the article Oolong from Wikipedia, split it into sentences, and then split each sentence into words.
wiki = wikipediaapi.Wikipedia(user_agent="waynestalk/1.0", language="en")
page = wiki.page("Oolong")
corpus = page.text
nltk.download("punkt")
sentences = nltk.sent_tokenize(corpus)
tokenized_corpus = [[word.lower() for word in nltk.word_tokenize(sentence) if word.isalpha()] for sentence in sentences]
vocab = set([word for sentence in tokenized_corpus for word in sentence])
word_to_index = {word: i for i, word in enumerate(vocab)}
index_to_word = {i: word for i, word in enumerate(vocab)}
len(vocab)
# Output
580We use PyTorch to implement CBOW, and we can see that it is quite simple to implement. Among them, embedding is the hidden layer and linear is the output layer. In foward(), we convert the input into vectors and then take the average of these vectors. Finally, the average is passed to the output layer.
class CBOW(nn.Module):
def __init__(self, vocab_size, embedding_size):
super(CBOW, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_size)
self.linear = nn.Linear(embedding_size, vocab_size)
def forward(self, context_words):
vectors = self.embedding(context_words)
average_vector = torch.mean(vectors, dim=0)
return self.linear(average_vector)Next, we need to prepare training data. For each word in each sentence and the two words before and after it, we treat it as a piece of training data.
window_size = 2
training_pairs = []
for sentence in tokenized_corpus:
for i in range(window_size, len(sentence) - window_size):
context = [sentence[j] for j in range(i - window_size, i + window_size + 1) if j != i]
training_pairs.append((context, sentence[i]))
training_pairs[:5]
# Output
[(['oolong', 'uk', 'simplified', 'chinese'], 'us'),
(['uk', 'us', 'chinese', '乌龙茶'], 'simplified'),
(['us', 'simplified', '乌龙茶', 'traditional'], 'chinese'),
(['simplified', 'chinese', 'traditional', 'chinese'], '乌龙茶'),
(['chinese', '乌龙茶', 'chinese', '烏龍茶'], 'traditional')]In the following code, the CBOW model will learn word embeddings from the training data. We set the embedding dimension to 1000. So, the embedding matrix will be  .
.
model = CBOW(len(vocab), 1000)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
epochs = 500
start_time = time.time()
for epoch in range(epochs):
total_loss = 0
for context, target in training_pairs:
context_tensor = torch.tensor([word_to_index[word] for word in context], dtype=torch.long)
target_tensor = torch.tensor([word_to_index[target]], dtype=torch.long)
output = model(context_tensor)
loss = loss_function(output.unsqueeze(0), target_tensor)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if epoch == 0 or (epoch + 1) % 100 == 0:
print(f"Epoch: {epoch}, Loss: {total_loss}")
end_time = time.time()
print(f"Training time: {end_time - start_time} seconds")
# Output
Epoch: 0, Loss: 6856.648630566895
Epoch: 99, Loss: 65.55343400325
Epoch: 199, Loss: 58.981725521754925
Epoch: 299, Loss: 55.93582288858761
Epoch: 399, Loss: 53.808607134100384
Epoch: 499, Loss: 52.07664276908599
Training time: 304.94574093818665 secondsThe following code prints the word embedding of oolong.
word = "oolong"
word_index_tensor = torch.tensor(word_to_index[word], dtype=torch.long)
embedding_vector = model.embedding(word_index_tensor).detach().numpy()
print(f"Embedding {embedding_vector.shape} for '{word}': {embedding_vector}")
# Output
Embedding (1000,) for 'oolong': [ 1.41568875e+00 -3.54769737e-01 -1.37265265e+00 -6.58394694e-01
8.31549525e-01 -9.42143202e-01 9.70315874e-01 -5.99202693e-01
1.84273362e+00 9.20817614e-01 -5.58760583e-01 1.00353360e+00
-2.15644687e-01 -4.58650626e-02 -2.28673637e-01 1.86233068e+00
...The following code shows that we can use the learned embedding matrix and
cosine similarity to calculate the similarity between two sentences.
sentence1 = "tea is popular in taiwan".split()
sentence2 = "oolong is famous in taiwan".split()
sentence1_embeddings = [model.embedding(torch.tensor(word_to_index[word], dtype=torch.long)).detach() for word in sentence1]
sentence2_embeddings = [model.embedding(torch.tensor(word_to_index[word], dtype=torch.long)).detach() for word in sentence2]
vector1 = torch.stack(sentence1_embeddings).mean(dim=0)
vector2 = torch.stack(sentence2_embeddings).mean(dim=0)
cosine_sim = nn.CosineSimilarity(dim=0)
similarity = cosine_sim(vector1, vector2).item()
print(f"Sentence 1: {sentence1}")
print(f"Sentence 2: {sentence2}")
print(f"Similarity between sentences: {similarity}")
# Output
Sentence 1: ['tea', 'is', 'popular', 'in', 'taiwan']
Sentence 2: ['oolong', 'is', 'famous', 'in', 'taiwan']
Similarity between sentences: 0.6053189635276794We can also calculate the cosine similarity ourselves, as follows.
sentence1_embeddings = [model.embedding(torch.tensor(word_to_index[word], dtype=torch.long)).detach().numpy() for word in sentence1] sentence2_embeddings = [model.embedding(torch.tensor(word_to_index[word], dtype=torch.long)).detach().numpy() for word in sentence2] vector1 = np.mean(sentence1_embeddings, axis=0) vector2 = np.mean(sentence2_embeddings, axis=0) similarity = (np.dot(vector1, vector2) / (np.linalg.norm(vector1) * np.linalg.norm(vector2)))
In the following code, we use principal component analysis (PCA) to display the distribution of word embeddings.
word_embeddings_tensor = model.embedding.weight.detach()
U, S, V = torch.pca_lowrank(word_embeddings_tensor, q=2)
reduced_embeddings = U.numpy()
plt.figure(figsize=(8, 6))
for word, index in word_to_index.items():
x, y = reduced_embeddings[index]
plt.scatter(x, y, marker='o', color='blue')
tea_index = word_to_index['tea']
x, y = reduced_embeddings[tea_index]
plt.scatter(x, y, marker='o', color='red')
plt.text(x, y, 'tea', fontsize=8)
oolong_index = word_to_index['oolong']
x, y = reduced_embeddings[oolong_index]
plt.scatter(x, y, marker='o', color='red')
plt.text(x, y, 'oolong', fontsize=8)
plt.xlabel("PCA Component 1")
plt.ylabel("PCA Component 2")
plt.title("CBOW Word Embeddings Visualization of Corpus 'Oolong`")
plt.grid(True)
plt.show()
Continuous Skip-gram Model
The learning method of Skip-gram is opposite to that of CBOW. It uses the center word to predict context words. As shown in the figure below, the center word is fox, and the context window size is 2, so the context is the two words before and the two words after fox. In this way, there will be four pieces of training data, with the center word as input and the output of each set of data being the context words.

Forward Propagation
Skip-gram uses a neural network with only one hidden layer to learn word embeddings. After training, the weight of the hidden layer is the word embedding matrix. The figure below shows the forward propagation of Skip-gram.

The formula for forward propagation of Skip-gram is as follows:

The dimensions of each variable are as follows:
|  | | | | |
|---|---|---|---|---|---|
| | | | | |
Loss Function
The output of Skip-gram is the probability of each word, so softmax is used as the activation function of the output layer. Therefore, cross-entropy loss is used as its loss function.

Backward Propagation
The formula in Skip-gram backpropagation is as follows:

Implementation
We use PyTorch to implement Skip-gram as follows.
class SkipGram(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(SkipGram, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.linear = nn.Linear(embedding_dim, vocab_size)
def forward(self, word):
vector = self.embedding(word)
return self.linear(vector)We also use the Wikipedia article on Oolong as the corpus. The context of each word in each sentence is the two words before and after it, so each word has multiple context words. We can treat each word and its context word as a piece of training data.
window_size = 2
training_pairs = []
for sentence in tokenized_corpus:
for i, target_word in enumerate(sentence):
context_indices = (list(range(max(i - window_size, 0), i)) +
list(range(i + 1, min(i + window_size + 1, len(sentence)))))
for context_index in context_indices:
training_pairs.append((target_word, sentence[context_index]))
training_pairs[:5]In the following code, the Skip-gram model will learn word embeddings from the training data. We set the embedding dimension to 1000. So, the embedding matrix will be .
model = SkipGram(len(vocab), 1000)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
epochs = 500
start_time = time.time()
for epoch in range(epochs):
total_loss = 0
for target, context in training_pairs:
target_tensor = torch.tensor([word_to_index[target]], dtype=torch.long)
context_tensor = torch.tensor([word_to_index[context]], dtype=torch.long)
output = model(target_tensor)
loss = loss_function(output, context_tensor)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if epoch == 0 or (epoch + 1) % 100 == 0:
print(f"Epoch: {epoch}, Loss: {total_loss}")
end_time = time.time()
print(f"Training time: {end_time - start_time} seconds")
# Output
Epoch: 0, Loss: 39987.801153186476
Epoch: 99, Loss: 30384.4197357425
Epoch: 199, Loss: 26906.040692283364
Epoch: 299, Loss: 24592.846442646056
Epoch: 399, Loss: 22867.418499057472
Epoch: 499, Loss: 21502.15208007075
Training time: 1074.5490338802338 secondsIn the figure below, we use principal component analysis (PCA) to show the distribution of word embeddings.

Comparison between CBOW and Skip-gram
In the above, we can see the training time of CBOW and Skip-gram for the same corpus. CBOW is 304 seconds, while Skip-gram is 1074 seconds. Each center word and its context words of CBOW become a piece of training data. However, each center word and each context word of Skip-gram becomes a piece of training data. Therefore, the training data of Skip-gram is relatively large.
From PCA, we can see that the word embeddings learned by Skip-gram have related words closer together, so it can learn the relationship between words in more detail.
Improving Word2Vec training efficiency
Skip-gram can learn high-quality word embeddings that capture the syntactic and semantic relationships of words. However, when training a large-scale corpus, we need to improve the performance of skip-gram to speed up training.
Negative Sampling
In Skip-gram, given a target word 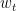 , we want to predict its context word
, we want to predict its context word  . We use
. We use softmax to calculate the following probabilities. In the denominator, we want to sum up the probabilities of all words. And when  is large, it will take quite a while.
is large, it will take quite a while.
Instead of calculating the probability of the entire vocabulary, negative sampling simplifies the problem as follows:
- For each (target word, context word), we want to maximize their similarity.
- For each (target word, random word), we want to minimize their similarity.
For each  , negative sampling select
, negative sampling select  words from the vocabulary that is not in the context words of the target word . Then, use the following loss function to calculate the loss. We want to maximize the first half of the formula, that is, the probability of the target word and the context word. Then, minimize the second half of the formula, that is, the probability of target word and negative words.
words from the vocabulary that is not in the context words of the target word . Then, use the following loss function to calculate the loss. We want to maximize the first half of the formula, that is, the probability of the target word and the context word. Then, minimize the second half of the formula, that is, the probability of target word and negative words.
![\log\sigma((v^{\prime}_{w_c})^Tv_{w_t})+\displaystyle\sum_{i=1}^k\mathbb{E}_{w_i\sim P_n(w)}\Big[\log\sigma(-(v^{\prime}_{wi})^Tv_{w_t})\Big] \\\\ v_w:\text{the input vector representations of }w \\\\ v^{\prime}_w:\text{the output vector representations of }w \\\\ k:\text{the number negative words} \\\\ \hphantom{k:}\text{5-20 for small training dataset} \\\\ \hphantom{k:}\text{2-5 for large training dataset} \mathbb{E}:\text{the expectation operator} \\\\ w_i\sim P_n(w):\text{mean }w_i\text{ is sampled from the negative sampling distribution }P_n(w)](https://s0.wp.com/latex.php?latex=%5Clog%5Csigma%28%28v%5E%7B%5Cprime%7D_%7Bw_c%7D%29%5ETv_%7Bw_t%7D%29%2B%5Cdisplaystyle%5Csum_%7Bi%3D1%7D%5Ek%5Cmathbb%7BE%7D_%7Bw_i%5Csim+P_n%28w%29%7D%5CBig%5B%5Clog%5Csigma%28-%28v%5E%7B%5Cprime%7D_%7Bwi%7D%29%5ETv_%7Bw_t%7D%29%5CBig%5D+%5C%5C%5C%5C+v_w%3A%5Ctext%7Bthe+input+vector+representations+of+%7Dw+%5C%5C%5C%5C+v%5E%7B%5Cprime%7D_w%3A%5Ctext%7Bthe+output+vector+representations+of+%7Dw+%5C%5C%5C%5C+k%3A%5Ctext%7Bthe+number+negative+words%7D+%5C%5C%5C%5C+%5Chphantom%7Bk%3A%7D%5Ctext%7B5-20+for+small+training+dataset%7D+%5C%5C%5C%5C+%5Chphantom%7Bk%3A%7D%5Ctext%7B2-5+for+large+training+dataset%7D+%5Cmathbb%7BE%7D%3A%5Ctext%7Bthe+expectation+operator%7D+%5C%5C%5C%5C+w_i%5Csim+P_n%28w%29%3A%5Ctext%7Bmean+%7Dw_i%5Ctext%7B+is+sampled+from+the+negative+sampling+distribution+%7DP_n%28w%29+&bg=ffffff&fg=000&s=1&c=20201002)
So how do you choose negative words? Negative sampling selects negative samples based on the following distribution.

Therefore, the second half of the formula is:
![\displaystyle\sum_{i=1}^k\mathbb{E}_{w_i\sim P_n(w)}\Big[\log\sigma(-(v^{\prime}_{wi})^Tv_{w_t})\Big]=\displaystyle\sum_{i=1}^k P_n(w_i)\Big[\log\sigma(-(v^{\prime}_{wi})^Tv_{w_t})\Big]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Csum_%7Bi%3D1%7D%5Ek%5Cmathbb%7BE%7D_%7Bw_i%5Csim+P_n%28w%29%7D%5CBig%5B%5Clog%5Csigma%28-%28v%5E%7B%5Cprime%7D_%7Bwi%7D%29%5ETv_%7Bw_t%7D%29%5CBig%5D%3D%5Cdisplaystyle%5Csum_%7Bi%3D1%7D%5Ek+P_n%28w_i%29%5CBig%5B%5Clog%5Csigma%28-%28v%5E%7B%5Cprime%7D_%7Bwi%7D%29%5ETv_%7Bw_t%7D%29%5CBig%5D+&bg=ffffff&fg=000&s=1&c=20201002)
Implementation
First, prepare the training data as in the Skip-gram section. Then, we need to calculate the negative sampling distribution  .
.
word_frequency = np.zeros(len(vocab))
for sentence in tokenized_corpus:
for word in sentence:
word_frequency[word_to_index[word]] += 1
word_distribution = word_frequency / word_frequency.sum()
unigram_distribution = word_distribution ** (3 / 4)
unigram_distribution = unigram_distribution / unigram_distribution.sum()
print(f"Unigram distribution: {unigram_distribution[:5]}")
def get_negative_samples(num_samples, context_index):
negative_samples = []
while len(negative_samples) < num_samples:
sample_index = np.random.choice(len(vocab), p=unigram_distribution)
if sample_index != context_index:
negative_samples.append(sample_index)
return negative_samplesNext, change the SkipGram model to the following. The input_embedding in the code is  , and the
, and the output_embedding is  .
.
class SkipGramWithNegativeSampling(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(SkipGramWithNegativeSampling, self).__init__()
self.input_embedding = nn.Embedding(vocab_size, embedding_dim)
self.output_embedding = nn.Embedding(vocab_size, embedding_dim)
nn.init.uniform_(self.input_embedding.weight, a=-0.5, b=0.5)
nn.init.uniform_(self.output_embedding.weight, a=-0.5, b=0.5)
def forward(self, target_word, context_word, negative_samples):
target_embedding = self.input_embedding(target_word)
context_embedding = self.output_embedding(context_word)
negative_samples_embeddings = self.output_embedding(negative_samples)
pos_score = (target_embedding * context_embedding).sum(dim=1)
pos_loss = -torch.sigmoid(pos_score).log()
neg_score = torch.bmm(negative_samples_embeddings, target_embedding.unsqueeze(2)).squeeze(2)
neg_loss = -torch.sigmoid(-neg_score).log()
neg_loss = neg_loss.sum(dim=1)
return (pos_loss + neg_loss).mean()Then, we use the following code to train the Skip-gram model.
model = SkipGramWithNegativeSampling(len(vocab), 1000)
num_negative_samples = 5
optimizer = optim.SGD(model.parameters(), lr=0.01)
epochs = 500
start_time = time.time()
for epoch in range(epochs):
total_loss = 0
for target, context in training_pairs:
target_tensor = torch.tensor([word_to_index[target]], dtype=torch.long)
context_index = word_to_index[context]
context_tensor = torch.tensor([context_index], dtype=torch.long)
negative_samples_tensor = torch.tensor(
[get_negative_samples(num_negative_samples, context_index)], dtype=torch.long
)
loss = model(target_tensor, context_tensor, negative_samples_tensor)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if epoch == 0 or (epoch + 1) % 100 == 0:
print(f"Epoch: {epoch}, Loss: {total_loss}")
end_time = time.time()
print(f"Training time: {end_time - start_time} seconds")
# Output
Epoch: 0, Loss: 28936.812749773264
Epoch: 99, Loss: 3952.563685086556
Epoch: 199, Loss: 3894.3744740486145
Epoch: 299, Loss: 3726.271819884423
Epoch: 399, Loss: 3714.307072382886
Epoch: 499, Loss: 3639.7701731920242
Training time: 981.5462839603424 secondsSubsampling of Frequent Words
In a large corpus, the most frequently occurring words, such as “in”, “the”, “a”, etc., can easily appear millions of times. These words often provide less information then the rare words. In addition, since these high-frequency words appear too many times, this will also slow down the training. Therefore, subsampling of frequent words is to reduce the impact of extremely frequently occurring words during training.
Subsampling calculates the following probability for each word to decide whether to discard the word.

Implementation
When we split the corpus by sentences and then by words, we use subsampling to remove some words directly, as shown below.
subsampling_threshold = 1e-5
subsampled_tokenized_corpus = []
for sentence in tokenized_corpus:
new_sentence = []
for word in sentence:
index = word_to_index[word]
frequency = word_frequency[index]
if frequency > subsampling_threshold:
drop_probability = 1 - np.sqrt(subsampling_threshold / frequency)
else:
drop_probability = 0
if np.random.rand() > drop_probability:
new_sentence.append(word)
if len(new_sentence) > 0:
subsampled_tokenized_corpus.append(new_sentence)
print(subsampled_tokenized_corpus[:5])Skip-gram can introduce negative sampling and subsampling at the same time. Therefore, the model and training code are the same as in the negative sampling section. You can get the code for this part from the complete code of this article.
Finally, we use Skip-gram with negative sampling and subsampling to learn word embeddings. After removing some high-frequency words, the training time is shortened a lot.
model = SkipGramWithNegativeSamplingAndSubsamplingOfFrequentWords(len(vocab), 1000)
num_negative_samples = 5
optimizer = optim.SGD(model.parameters(), lr=0.01)
epochs = 500
start_time = time.time()
for epoch in range(epochs):
total_loss = 0
for target, context in training_pairs:
target_tensor = torch.tensor([word_to_index[target]], dtype=torch.long)
context_index = word_to_index[context]
context_tensor = torch.tensor([context_index], dtype=torch.long)
negative_samples_tensor = torch.tensor(
[get_negative_samples(num_negative_samples, context_index)], dtype=torch.long
)
loss = model(target_tensor, context_tensor, negative_samples_tensor)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if epoch == 0 or (epoch + 1) % 100 == 0:
print(f"Epoch: {epoch}, Loss: {total_loss}")
end_time = time.time()
print(f"Training time: {end_time - start_time} seconds")
# Output
Epoch: 0, Loss: 953.0108479261398
Epoch: 99, Loss: 56.98700549826026
Epoch: 199, Loss: 25.619574746116996
Epoch: 299, Loss: 28.435157721862197
Epoch: 399, Loss: 14.342244805768132
Epoch: 499, Loss: 15.597246480174363
Training time: 26.50890588760376 secondsConclusion
Word2Vec is one of the most influential word embeddings learning technologies in NLP, which trains semantically rich word embeddings through CBOW and Skip-gram. In addition, techniques such as Negative Sampling and Subsampling further improve training efficiency, making Word2Vec the basis of many NLP applications.
References
- Andrew Ng, Deep Learning Specialization, Coursera.
- Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient Estimation of Word Representations in Vector Space. ICLR.
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Distributed Representations of Words and Phrases and their Compositionality. NIPS.









