
Recurrent Neural Networks (RNN) is a neural network architecture that specializes in processing sequential data. RNN uses recurrent connections to retain previous output information, allowing the network to consider past states while processing the current step. This article will introduce the basic principles of RNN.
The complete code for this chapter can be found in .
Table of Contents
RNN Architecture
Recurrent Neural Networks (RNN) have a hidden state at each time step and use it as input for the next time step. This allows the RNN to capture some information from previous time steps. Therefore, compared with the traditional neural network, it is more suitable for dealing with sequential or context-dependent problems.
The figure below shows the architecture of the basic RNN (vanilla RNN). The left side is the unfolded representation, and the right side is the folded representation. Therefore, the neural network architecture in each time step on the right is the same.
In this article, we will use a character-level RNN model to explain the principle of RNN. The input for each time step  is a character in the input text. The RNN cell will be passed in, and the RNN cell will produce a hidden state
is a character in the input text. The RNN cell will be passed in, and the RNN cell will produce a hidden state  . On the one hand, it outputs as
. On the one hand, it outputs as  , and on the other hand, it is passed to the RNN cell of the next time step.
, and on the other hand, it is passed to the RNN cell of the next time step.
Each time step will affect the next time step  . In other words, captures some information from the previous time step. Therefore, there is a dependency relationship between each time step.
. In other words, captures some information from the previous time step. Therefore, there is a dependency relationship between each time step.

RNN Types
The number of inputs 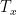 and outputs
and outputs  of RNNs are not always the same, so there are five different types of RNNs. Each type of RNN is suitable for different applications, as follows. The vanilla RNN in this article is the many-to-many type on the bottom left.
of RNNs are not always the same, so there are five different types of RNNs. Each type of RNN is suitable for different applications, as follows. The vanilla RNN in this article is the many-to-many type on the bottom left.

Forward Propagation
If you are not familiar with the forward propagation of neural networks, please refer to the following article first.

The following figure shows our RNN cell. The input is and the hidden state of the previous time step  . These two inputs, along with the parameters
. These two inputs, along with the parameters  , are processed and then passed through the activation function tanh, resulting in the output , which is used as the input for the RNN cell in the next time step. Additionally, is combined with the parameters
, are processed and then passed through the activation function tanh, resulting in the output , which is used as the input for the RNN cell in the next time step. Additionally, is combined with the parameters  , and this result is passed through the softmax activation function, producing
, and this result is passed through the softmax activation function, producing  as the output for the current time step.
as the output for the current time step.
It is worth noting that the parameters  are shared parameters. In other words, every RNN cell at each time step uses the same set of parameters.
are shared parameters. In other words, every RNN cell at each time step uses the same set of parameters.

The formula in the RNN cell is as follows:

The dimensions of the RNN input  and true labels
and true labels  are as follows:
are as follows:

In the RNN cell, the dimensions of each variable are as follows:
 |  |  | |  |  |  | |
|---|---|---|---|---|---|---|---|
 |  |  |  |  |  |  |  |
The following is the implementation of forward propagation of a vanilla RNN.
class VanillaRNN:
def cell_forward(self, xt, at_prev, parameters):
"""
Implements a single forward step of the RNN-cell.
Parameters
----------
xt: (ndarray (n_x, m)) - input data at timestep "t"
at_prev: (ndarray (n_a, m)) - hidden state at timestep "t-1"
parameters:
Waa: (ndarray (n_a, n_a)) - weight matrix multiplying the hidden state at_prev
Wax: (ndarray (n_a, n_x)) - weight matrix multiplying the input xt
Wya: (ndarray (n_y, n_a)) - weight matrix relating the hidden-state to the output
ba: (ndarray (n_a, 1)) - bias
by: (ndarray (n_y, 1)) - bias
Returns
-------
at: (ndarray (n_a, m)) - hidden state at timestep "t"
yt: (ndarray (n_y, m)) - prediction at timestep "t"
cache: (tuple) - returning (at, at_prev, xt, zxt, y_hat_t, zyt) for the backpropagation
"""
Wax, Waa, ba = parameters["Wax"], parameters["Waa"], parameters["ba"]
Wyx, by = parameters["Wya"], parameters["by"]
zxt = Waa @ at_prev + Wax @ xt + ba
at = np.tanh(zxt)
zyt = Wyx @ at + by
y_hat_t = softmax(zyt)
cache = (at, at_prev, xt, zxt, y_hat_t, zyt)
return at, y_hat_t, cache
def forward(self, X, a0, parameters):
"""
Implements the forward propagation of the RNN.
Parameters
----------
X: (ndarray (n_x, m, T_x)) - input data for each timestep
a0: (ndarray (n_a, m)) - initial hidden state
parameters:
Waa: (ndarray (n_a, n_a)) - weight matrix multiplying the hidden state at_prev
Wax: (ndarray (n_a, n_x)) - weight matrix multiplying the input xt
Wyx: (ndarray (n_y, n_a)) - weight matrix relating the hidden-state to the output
ba: (ndarray (n_a, 1)) - bias
by: (ndarray (n_y, 1)) - bias
Returns
-------
a: (ndarray (n_a, m, T_x)) - hidden states for each timestep
Y_hat: (ndarray (n_y, m, T_x)) - predictions for each timestep
caches: (tuple) - returning (list of cache, x) for the backpropagation
"""
caches = []
n_x, m, T_x = X.shape
n_y, n_a = parameters["Wya"].shape
A = np.zeros((n_a, m, T_x))
Y_hat = np.zeros((n_y, m, T_x))
at_prev = a0
for t in range(T_x):
at_prev, y_hat_t, cache = self.cell_forward(X[:, :, t], at_prev, parameters)
A[:, :, t] = at_prev
Y_hat[:, :, t] = y_hat_t
caches.append(cache)
return A, Y_hat, cachesLoss Function
Since our vanilla RNN is many-to-many, that is, it has multiple outputs, when calculating the loss, we must add up the loss of each time step, as shown in the following figure.

Our vanilla RNN uses softmax for output  and therefore uses cross-entropy loss as its loss function.
and therefore uses cross-entropy loss as its loss function.

The following is the implementation of the loss function.
class VanillaRNN:
def compute_loss(self, Y_hat, Y):
"""
Computes the cross-entropy loss.
Parameters
----------
Y_hat: (ndarray (n_y, m, T_x)) - predictions for each timestep
Y: (ndarray (n_y, m, T_x)) - true labels
Returns
-------
loss: (float) - the cross-entropy loss
"""
return -np.sum(Y * np.log(Y_hat))Backward Propagation
Compared with traditional neural networks, RNN backpropagation is more complicated. As shown in the figure below, for each time step, we must take the partial derivatives of these.

In addition, each time step is affected by the hidden state of the previous time step. Therefore, when calculating gradients, the partial derivatives obtained in each time step must be summed up. This is backprogation through time (BPTT). If we only calculate the gradient at the last time step, we will ignore the impact of the intermediate time steps on the final result, and the weights will not be able to learn the correct adjustment in the entire time series.

The following is the partial derivatives in the output layer at a time step.

The following is the calculation of the remaining partial derivatives at a time step.

It is worth noting that when calculating the partial derivative of the hidden state, we must first calculate the partial derivative from the output layer with respect to . Then, we add the partial derivative with respect to calculated in the previous time step, as shown below.

The above is how to find all partial derivatives at each time step. We have to add up all the partial derivatives we calculated at the end.

The following is the implementation of backward propagation of a vanilla RNN.
class VanillaRNN:
def cell_backward(self, y, dat, cache, parameters):
"""
Implements a single backward step of the RNN-cell.
Parameters
----------
y: (ndarray (n_y, m)) - true labels at timestep "t"
dat: (ndarray (n_a, m)) - gradient of the hidden state at timestep "t"
cache: (tuple) - (at, at_prev, xt, zxt, y_hat_t, zyt)
parameters:
Waa: (ndarray (n_a, n_a)) - weight matrix multiplying the hidden state at_prev
Wax: (ndarray (n_a, n_x)) - weight matrix multiplying the input xt
Wya: (ndarray (n_y, n_a)) - weight matrix relating the hidden-state to the output
ba: (ndarray (n_a, 1)) - bias
by: (ndarray (n_y, 1)) - bias
Returns
-------
gradients: (dict) - the gradients
dWaa: (ndarray (n_a, n_a)) - gradient of the weight matrix multiplying the hidden state at_prev
dWax: (ndarray (n_a, n_x)) - gradient of the weight matrix multiplying the input xt
dWya: (ndarray (n_y, n_a)) - gradient of the weight matrix relating the hidden-state to the output
dba: (ndarray (n_a, 1)) - gradient of the bias
dby: (ndarray (n_y, 1)) - gradient of the bias
dat: (ndarray (n_a, m)) - gradient of the hidden state
"""
at, at_prev, xt, zt, y_hat_t, zyt = cache
dy = y_hat_t - y
gradients = {
"dWya": dy @ at.T,
"dby": np.sum(dy, axis=1, keepdims=True),
}
dat = parameters["Wya"].T @ dy + dat
dz = (1 - at ** 2) * dat
gradients["dba"] = np.sum(dz, axis=1, keepdims=True)
gradients["dWax"] = dz @ xt.T
gradients["dWaa"] = dz @ at_prev.T
gradients["dat"] = parameters["Waa"].T @ dz
return gradients
def backward(self, X, Y, parameters, caches):
"""
Implements the backward propagation of the RNN.
Parameters
----------
X: (ndarray (n_x, m, T_x)) - input data
Y: (ndarray (n_y, m, T_x)) - true labels
parameters:
Waa: (ndarray (n_a, n_a)) - weight matrix multiplying the hidden state at_prev
Wax: (ndarray (n_a, n_x)) - weight matrix multiplying the input xt
Wya: (ndarray (n_y, n_a)) - weight matrix relating the hidden-state to the output
ba: (ndarray (n_a, 1)) - bias
by: (ndarray (n_y, 1)) - bias
caches: (list) - list of caches from rnn_forward
Returns
-------
gradients: (dict) - the gradients
dWaa: (ndarray (n_a, n_a)) - gradient of the weight matrix multiplying the hidden state at_prev
dWax: (ndarray (n_a, n_x)) - gradient of the weight matrix multiplying the input xt
dWya: (ndarray (n_y, n_a)) - gradient of the weight matrix relating the hidden-state to the output
dba: (ndarray (n_a, 1)) - gradient of the bias
dby: (ndarray (n_y, 1)) - gradient of the bias
dat: (ndarray (n_a, m)) - gradient of the hidden state
"""
n_x, m, T_x = X.shape
a1, a0, x1, zx1, y_hat1, zy1 = caches[0]
Waa, Wax, ba = parameters['Waa'], parameters['Wax'], parameters['ba']
Wya, by = parameters['Wya'], parameters['by']
gradients = {
"dWaa": np.zeros_like(Waa), "dWax": np.zeros_like(Wax), "dba": np.zeros_like(ba),
"dWya": np.zeros_like(Wya), "dby": np.zeros_like(by),
}
dat = np.zeros_like(a0)
for t in reversed(range(T_x)):
grads = self.cell_backward(Y[:, :, t], dat, caches[t], parameters)
gradients["dWaa"] += grads["dWaa"]
gradients["dWax"] += grads["dWax"]
gradients["dWya"] += grads["dWya"]
gradients["dba"] += grads["dba"]
gradients["dby"] += grads["dby"]
dat = grads["dat"]
return gradientsExploding Gradients
In deep RNNs, gradients are obtained by multiplying or adding during backpropagation. Therefore, if the weights are large, then when calculating the partial derivatives, even if the magnification is slightly greater than 1, the final result may explode when the number of layers increases. This will cause loss to reach a large value or NaN.
Therefore, before updating the parameters, we will do gradient clipping, which is actually done as follows.
class VanillaRNN:
def clip(self, gradients, max_value):
"""
Clips the gradients to a maximum value.
Parameters
----------
gradients: (dict) - the gradients
dWaa: (ndarray (n_a, n_a)) - gradient of the weight matrix multiplying the hidden state at_prev
dWax: (ndarray (n_a, n_x)) - gradient of the weight matrix multiplying the input xt
dWya: (ndarray (n_y, n_a)) - gradient of the weight matrix relating the hidden-state to the output
dba: (ndarray (n_a, 1)) - gradient of the bias
dby: (ndarray (n_y, 1)) - gradient of the bias
max_value: (float) - the maximum value to clip the gradients
Returns
-------
gradients: (dict) - the clipped gradients
"""
dWaa, dWax, dWya = gradients["dWaa"], gradients["dWax"], gradients["dWya"]
dba, dby = gradients["dba"], gradients["dby"]
for gradient in [dWax, dWaa, dWya, dba, dby]:
np.clip(gradient, -max_value, max_value, out=gradient)
gradients = {"dWaa": dWaa, "dWax": dWax, "dWya": dWya, "dba": dba, "dby": dby}
return gradientsParameter Initialization and Update
Initializing the parameters is not difficult, but you need to make sure that the dimensions of each parameter are correct. The following is the implementation of parameter initialization.
class VanillaRNN:
def initialize_parameters(self, n_a, n_x, n_y):
"""
Initializes the parameters for the RNN.
Parameters
----------
n_a: (int) - number of units in the hidden state
n_x: (int) - number of units in the input data
n_y: (int) - number of units in the output data
Returns
-------
parameters: (dict) - initialized parameters
"Wax": (ndarray (n_a, n_x)) - weight matrix multiplying the input
"Waa": (ndarray (n_a, n_a)) - weight matrix multiplying the hidden state
"Wya": (ndarray (n_y, n_a)) - weight matrix relating the hidden-state to the output
"ba": (ndarray (n_a, 1)) - bias
"by": (ndarray (n_y, 1)) - bias
"""
Wax = np.random.randn(n_a, n_x) * 0.01
Waa = np.random.randn(n_a, n_a) * 0.01
Wya = np.random.randn(n_y, n_a) * 0.01
ba = np.zeros((n_a, 1))
by = np.zeros((n_y, 1))
parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "ba": ba, "by": by}
return parametersAfter having the gradients, we need to use the gradients to update the parameters, which is actually done as follows.
class VanillaRNN:
def update_parameters(self, parameters, gradients, learning_rate):
"""
Updates the parameters using the gradients.
Parameters
----------
parameters: (dict) - the parameters
Waa: (ndarray (n_a, n_a)) - weight matrix multiplying the hidden state at_prev
Wax: (ndarray (n_a, n_x)) - weight matrix multiplying the input xt
Wya: (ndarray (n_y, n_a)) - weight matrix relating the hidden-state to the output
ba: (ndarray (n_a, 1)) - bias
by: (ndarray (n_y, 1)) - bias
gradients: (dict) - the gradients
dWaa: (ndarray (n_a, n_a)) - gradient of the weight matrix multiplying the hidden state at_prev
dWax: (ndarray (n_a, n_x)) - gradient of the weight matrix multiplying the input xt
dWya: (ndarray (n_y, n_a)) - gradient of the weight matrix relating the hidden-state to the output
dba: (ndarray (n_a, 1)) - gradient of the bias
dby: (ndarray (n_y, 1)) - gradient of the bias
learning_rate: (float) - the learning rate
"""
parameters["Waa"] -= learning_rate * gradients["dWaa"]
parameters["Wax"] -= learning_rate * gradients["dWax"]
parameters["Wya"] -= learning_rate * gradients["dWya"]
parameters["ba"] -= learning_rate * gradients["dba"]
parameters["by"] -= learning_rate * gradients["dby"]Putting All Together
The following code implements a complete training process. First, we pass the training data into forward propagation, calculate the loss, and then pass it into backward propagation to finally get the gradients. To prevent exploding gradients, we clip the gradients. Then, use it to update the parameters. This is a complete training.
class VanillaRNN:
def optimize(self, X, Y, a_prev, parameters, learning_rate, clip_value):
"""
Implements the forward and backward propagation of the RNN.
Parameters
----------
X: (ndarray (n_x, m, T_x)) - the input data
Y: (ndarray (n_y, m, T_x)) - true labels
a_prev: (ndarray (n_a, m)) - the initial hidden state
parameters: (dict) - the initial parameters
Waa: (ndarray (n_a, n_a)) - weight matrix multiplying the hidden state A_prev
Wax: (ndarray (n_a, n_x)) - weight matrix multiplying the input Xt
Wya: (ndarray (n_y, n_a)) - weight matrix relating the hidden-state to the output
ba: (ndarray (n_a, 1)) - bias
by: (ndarray (n_y, 1)) - bias
learning_rate: (float) - the learning rate
Returns
-------
a: (ndarray (n_a, m)) - the hidden state at the last timestep
loss: (float) - the cross-entropy loss
"""
A, Y_hat, caches = self.forward(X, a_prev, parameters)
loss = self.compute_loss(Y_hat, Y)
gradients = self.backward(X, Y, parameters, caches)
gradients = self.clip(gradients, clip_value)
self.update_parameters(parameters, gradients, learning_rate)
at = A[:, :, -1]
return at, lossExample
So far, we have implemented optimize() in VanillaRNN, which performs a full training run. Next, we design VanillaRNN as a character-level language model. The training data is a passage from Shakespeare. It trains one character at a time, so the sequence length will be the length of the input characters. So, the first character is . Then, one-hot encoding is used to encode each character.
class VanillaRNN:
def preprocess_inputs(self, inputs, char_to_idx):
"""
Preprocess the input text data.
Parameters
----------
inputs: (str) - input text data
char_to_idx: (dict) - dictionary mapping characters to indices
Returns
-------
X: (ndarray (n_x, 1, T_x)) - input data for each time step
Y: (ndarray (n_y, 1, T_x)) - true labels for each time step
"""
n_x = n_y = len(char_to_idx)
T_x = T_y = len(inputs) - 1
X = np.zeros((n_x, 1, T_x))
Y = np.zeros((n_y, 1, T_y))
for t in range(T_x):
X[char_to_idx[inputs[t]], 0, t] = 1
Y[char_to_idx[inputs[t + 1]], 0, t] = 1
return X, Y
def train(self, inputs, char_to_idx, num_iterations=100, learning_rate=0.01, clip_value=5):
"""
Train the RNN model on the given text.
Parameters
----------
inputs: (str) - input text data
char_to_idx: (dict) - dictionary mapping characters to indices
num_iterations: (int) - number of iterations for the optimization loop
learning_rate: (float) - learning rate for the optimization algorithm
clip_value: (float) - maximum value for the gradients
Returns
-------
losses: (list) - cross-entropy loss at each iteration
"""
losses = []
a_prev = self.a0
X, Y = self.preprocess_inputs(inputs, char_to_idx)
for i in range(num_iterations):
a_prev, loss = self.optimize(X, Y, a_prev, self.parameters, learning_rate, clip_value)
losses.append(loss)
print(f"Iteration {i}, Loss: {loss}")
return lossesOnce trained, given a starting character, the VanillaRNN will generate Shakespearean-like strings.
class VanillaRNN:
def sample(self, start_char, char_to_idx, idx_to_char, num_chars=100):
"""
Generate text using the RNN model.
Parameters
----------
start_char: (str) - starting character for the text generation
char_to_idx: (dict) - dictionary mapping characters to indices
idx_to_char: (dict) - dictionary mapping indices to characters
num_chars: (int) - number of characters to generate
Returns
-------
text: (str) - generated text
"""
x = np.zeros((len(char_to_idx), 1))
a_prev = np.zeros_like(self.a0)
idx = char_to_idx[start_char]
x[idx] = 1
indices = [idx]
while len(indices) < num_chars:
a_prev, y_hat, cache = self.cell_forward(x, a_prev, self.parameters)
idx = np.random.choice(range(len(char_to_idx)), p=y_hat.ravel())
indices.append(idx)
x = np.zeros_like(x)
x[idx] = 1
text = "".join([idx_to_char[idx] for idx in indices])
return text
The following is an example of using VanillaRNN.
if __name__ == "__main__":
with open("shakespeare.txt", "r") as file:
text = file.read()
chars = sorted(list(set(text)))
vocab_size = len(chars)
char_to_idx = {ch: i for i, ch in enumerate(chars)}
idx_to_char = {i: ch for i, ch in enumerate(chars)}
rnn = VanillaRNN(64, vocab_size, vocab_size)
losses = rnn.train(text, char_to_idx, num_iterations=100, learning_rate=0.01, clip_value=5)
generated_text = rnn.sample("T", char_to_idx, idx_to_char, num_chars=100)
print(generated_text)Vanishing Gradients
The deeper the network, the more backpropagation paths there are, and each time step will have a corresponding partial derivative. Multiplying all the way down, those greater than 1 will easily lead to exploding gradients; those less than 1 will easily cause vanishing gradients. If inputs early in the sequence have an important influence on the final output, but the gradients are already very weak by the time they are passed back, then the model will not be able to learn the key to this early information.
Imagine you have a lengthy article whose very first sentence states the core topic, for example:
“This article is about the impact of social media on teenagers’ mental health. We’ll start by discussing how screen time correlates with well-being…”
Then, there are many descriptive details at the end of the article, which may include case analysis, data reports, etc. The entire article may have thousands of words. For models that want to do “topic classification” or “sentiment analysis”, the beginning of the article is likely to point out the main idea of the article or the author’s attitude. Ideally, the model should remember this core message because everything that follows will relate to this topic.
When the RNN processes this article, it feeds information into the model word by word or sentence by sentence and updates the hidden states. When backpropagation returns to the first half of the article, the gradients have been continuously reduced and are almost close to 0. The model will not remember the topic information mentioned at the beginning of the article. Finally, when the model outputs the “topic classification” or “sentiment analysis” results of the entire article, it does not have sufficient recognition ability for early key prompts and may make wrong or inconsistent judgments.
RNN models such as Long short-term memory (LSTM) or Gated Recurrent Unit (GRU) can better retain the key information at the beginning of the sequence.
Conclusion
Through the introduction of this article, I believe you have a more comprehensive understanding of the operation mode of RNN. We have seen the powerful capabilities of RNN in processing sequential data, and also understood the challenges it may face in long time series, such as vanishing gradients. To address this problem, models such as LSTM and GRU can be used to effectively retain long-term information.
References
- Andrew Ng, Deep Learning Specialization, Coursera.









