
Crosstab shows the frequency distribution of the values of two variables. It can be used to find out whether there is correlation between two variables. pandas.crosstab() can help us calculate crosstabs and display beautiful tables.
pandas.crosstab(
index,
columns,
values=None,
rownames=None,
colnames=None,
aggfunc=None,
margins=False,
margins_name='All',
dropna=True,
normalize=False
)index: Values displayed in the rows. Types are array-like, Series, list of arrays/Series.columns: Value displayed in the columns. Types are array-like, Series, list of arrays/Series.margins: Display subtotals for columns and rows.
Examples
The following data is obtained from Women Entrepreneurship and Labor Force. We only extract part of them.
The complete code for this chapter can be found in .
import pandas as pd
import numpy as np
df = pd.DataFrame(
np.array([
['Austria', 'Developed', 'Member', 'Euro'],
['Spain', 'Developed', 'Member', 'Euro'],
['Japan', 'Developed', 'Not Member', 'National Currency'],
['Argentina', 'Developing', 'Not Member', 'National Currency'],
['Bolivia', 'Developing', 'Not Member', 'National Currency'],
['Taiwan', 'Developed', 'Not Member', 'National Currency'],
]),
columns=['Country', 'Level of development', 'European Union Membership', 'Currency']
)
pd.crosstab(df['Level of development'], df['European Union Membership'])
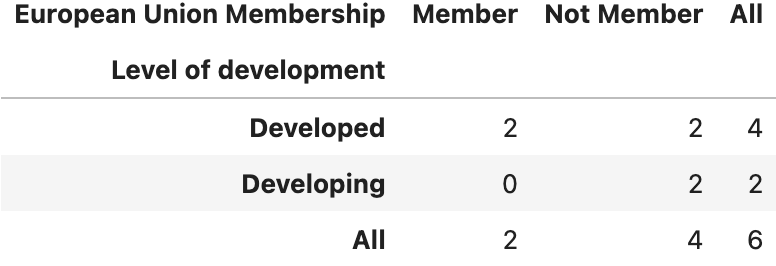
pd.crosstab(df['Level of development'], df['European Union Membership'], margins=True)
pd.crosstab(df["Level of development"], [df['European Union Membership'], df['Currency']])




