
In practical control problems, the state and action spaces are often high-dimensional, continuous, and noisy, which makes reinforcement learning algorithms based on tabular methods difficult to apply directly. Once function approximation is introduced, the two components that are conceptually well separated in theory of value evaluation and policy improvement become tightly intertwined, bringing with them challenges related to stability and variance. This article focuses on on-policy control methods under function approximation, with particular attention to Sarsa.
The complete code for this chapter can be found in .
Table of Contents
Control Problem
In control problems, the agent’s objective is no longer merely to evaluate a given policy, but to simultaneously perform value estimation and policy improvement through continuous interaction with the environment, ultimately approaching an optimal policy.
For episodic tasks, we first define the discounted return starting from time step  as:
as:

where ![\gamma \in [0,1]](https://s0.wp.com/latex.php?latex=%5Cgamma+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002) is the discount factor and
is the discount factor and  denotes the terminal time step of the episode. Based on this definition, the action-value function under a policy
denotes the terminal time step of the episode. Based on this definition, the action-value function under a policy  can be written as:
can be written as:
![q_\pi(s, a) \doteq \mathbb{E} [ G_t \mid S_t=s, A_t=a]](https://s0.wp.com/latex.php?latex=q_%5Cpi%28s%2C+a%29+%5Cdoteq+%5Cmathbb%7BE%7D+%5B+G_t+%5Cmid+S_t%3Ds%2C+A_t%3Da%5D+&bg=ffffff&fg=000&s=1&c=20201002)
The goal of the control problem is to find an optimal policy  such that, for all states, the action selected by this policy maximizes the corresponding action-value. Formally, we seek
such that, for all states, the action selected by this policy maximizes the corresponding action-value. Formally, we seek

That is, the optimal policy is implicitly defined by the optimal action-value function.
Under tabular methods, we can maintain an independent value 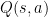 for each state–action pair
for each state–action pair 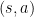 , and gradually approximate
, and gradually approximate  through TD control–based algorithms while interacting with the environment. This approach relies on the assumption that both the state space and the action space are sufficiently small, so that all state–action pairs can be explicitly enumerated and stored.
through TD control–based algorithms while interacting with the environment. This approach relies on the assumption that both the state space and the action space are sufficiently small, so that all state–action pairs can be explicitly enumerated and stored.
Once the state space or action space becomes large, or even continuous, this assumption no longer holds. In such cases, tabular representations cease to be practical, and the control problem must move into the framework of function approximation, where the action-value function is represented in a parameterized form and the interaction between policy learning and value learning must be reconsidered.
In prediction problems, function approximation primarily affects the accuracy of value estimation. In control problems, however, approximation errors in the value function are directly fed back into policy improvement, thereby influencing subsequent data distributions and learning stability. This feedback loop is precisely why control problems under function approximation are inherently more challenging than their prediction counterparts.
Value Function Approximation
When the state space or action space becomes large, or even continuous, tabular representations are no longer feasible. In such cases, the action-value function must instead be approximated by a parameterized function:

where  denotes a vector of learnable parameters. The object of learning is no longer the value associated with an individual state–action pair, but rather the representation of the entire action-value function in parameter space. That is, the parameter vector
denotes a vector of learnable parameters. The object of learning is no longer the value associated with an individual state–action pair, but rather the representation of the entire action-value function in parameter space. That is, the parameter vector  itself.
itself.
The introduction of function approximation brings about two fundamental changes.
First, different state–action pairs share the same set of parameters. As a result, an update derived from a single experience can simultaneously affect the value estimates of multiple states and actions. This parameter sharing endows the agent with generalization capability, allowing limited experience to be extrapolated to states that are rarely or never visited. At the same time, it also means that updates for different states are no longer independent; interference between states may occur, potentially leading to less stable learning dynamics.
Second, once function approximation is used, value estimation can no longer be viewed as the exact solution of a well-defined Bellman operator. Because the estimated value function is restricted to a finite-dimensional function class, the learning process can only search within this space for a solution that approximately satisfies Bellman consistency, rather than converging to the true fixed point.
Consequently, when function approximation is introduced into control problems, the learning objective itself changes. Instead of recovering the true optimal action-value function , the goal becomes to learn an approximate action-value function, within the chosen feature representation and function class, that is sufficient to support effective policy improvement. It is precisely this shift that causes approximate control problems to be inherently accompanied by issues of stability and bias, making them a central challenge in both algorithm analysis and design.
It is worth emphasizing that, in prediction problems, function approximation primarily affects the accuracy of value estimation. In control problems, however, approximation errors are fed back through policy improvement into the subsequent data distribution, forming a closed feedback loop. This interaction explains why the combination of function approximation, bootstrapping, and policy improvement leads to significant difficulties in both theory and practice.
On-Policy
Although the representational capacity and theoretical guarantees change once function approximation is introduced, the control problem can still be understood, at a structural level, as an instance of Generalized Policy Iteration (GPI). That is, an iterative process in which policy evaluation and policy improvement alternate. The key difference is that when the action-value function is approximated by  , neither step is exact; both can only be carried out approximately within the chosen function class.
, neither step is exact; both can only be carried out approximately within the chosen function class.
Under the on-policy setting, the behavior policy is identical to the policy being evaluated. Concretely, the agent interacts with the environment according to an exploratory policy (for example, an  -greedy policy with respect to
-greedy policy with respect to  ), and this same policy is used to define the TD target for updates. In other words, data generation and value-function evaluation are always governed by the same policy.
), and this same policy is used to define the TD target for updates. In other words, data generation and value-function evaluation are always governed by the same policy.
Policy improvement then proceeds by adjusting the policy based on the current approximate action-value function, gradually reducing the degree of exploration while moving toward a policy that is more greedy with respect to . As the parameter vector is updated, the behavior policy changes accordingly, which in turn affects the distribution of future experience.
Consequently, the entire on-policy control process can be viewed as an online, incremental approximation of GPI: at each step, only a small amount of recent experience is used to perform local updates to both the value function and the policy, rather than waiting for policy evaluation to fully converge before improvement. It is precisely this tightly interleaved update scheme that allows on-policy methods to exhibit relatively good stability when combined with function approximation.
Action-Value Function Approximation
Before moving on to specific control algorithms, it is necessary to clarify a fundamental question: once function approximation is introduced, how is the action-value function represented, and how is it updated?
Under the setting of linear function approximation, the basic assumption is that each state–action pair can be mapped to a fixed-dimensional feature vector  . With this assumption, the action-value function is represented as a linear combination of features parameterized by a vector :
. With this assumption, the action-value function is represented as a linear combination of features parameterized by a vector :

In this representation, all states and actions share the same parameter vector . It is precisely this parameter sharing that enables function approximation to generalize. A single parameter update simultaneously affects all state–action pairs that are similar in feature space. However, this shared representation also comes with a cost, that is updates for different states may interfere with one another, a phenomenon that does not arise in tabular methods.
One important advantage of linear approximation is the simplicity of its gradient. Taking the gradient of the above approximation with respect to the parameters yields:

As a result, all gradient-based TD control methods can express their parameter updates in a unified form:
![\delta_t \doteq U_t - \hat{q}(S_t, A_t, \mathbf{w}_t) \\\\ \mathbf{w}_{t+1} \doteq \mathbf{w}_t + \alpha \Big[ U_t - \hat{q}(S_t, A_t, \mathbf{w}_t) \Big] \nabla \hat{q}(S_t, A_t, \mathbf{w}_t) \\\\ \hphantom{\mathbf{w}_{t+1}} = \mathbf{w}_t + \alpha \delta_t \nabla \hat{q}(S_t, A_t, \mathbf{w}_t)](https://s0.wp.com/latex.php?latex=%5Cdelta_t+%5Cdoteq+U_t+-+%5Chat%7Bq%7D%28S_t%2C+A_t%2C+%5Cmathbf%7Bw%7D_t%29+%5C%5C%5C%5C+%5Cmathbf%7Bw%7D_%7Bt%2B1%7D+%5Cdoteq+%5Cmathbf%7Bw%7D_t+%2B+%5Calpha+%5CBig%5B+U_t+-+%5Chat%7Bq%7D%28S_t%2C+A_t%2C+%5Cmathbf%7Bw%7D_t%29+%5CBig%5D+%5Cnabla+%5Chat%7Bq%7D%28S_t%2C+A_t%2C+%5Cmathbf%7Bw%7D_t%29+%5C%5C%5C%5C+%5Chphantom%7B%5Cmathbf%7Bw%7D_%7Bt%2B1%7D%7D+%3D+%5Cmathbf%7Bw%7D_t+%2B+%5Calpha+%5Cdelta_t+%5Cnabla+%5Chat%7Bq%7D%28S_t%2C+A_t%2C+%5Cmathbf%7Bw%7D_t%29+&bg=ffffff&fg=000&s=1&c=20201002)
Here,  denotes the step size, while the TD target
denotes the step size, while the TD target  and the corresponding TD error
and the corresponding TD error  are determined by the specific control algorithm being used. For this reason, in practical implementations, the critical aspect of linear approximation is not how the gradient is computed, but how the features are designed.
are determined by the specific control algorithm being used. For this reason, in practical implementations, the critical aspect of linear approximation is not how the gradient is computed, but how the features are designed.
From a representational perspective, linear action-value approximation is equivalent to assuming that the true action-value function  can be projected onto the linear subspace spanned by the feature vectors. The outcome of learning is therefore not the recovery of the true optimal action-value function , but rather the identification of a parameter vector such that satisfies an approximate form of Bellman consistency within the chosen feature space.
can be projected onto the linear subspace spanned by the feature vectors. The outcome of learning is therefore not the recovery of the true optimal action-value function , but rather the identification of a parameter vector such that satisfies an approximate form of Bellman consistency within the chosen feature space.
Episodic Semi-Gradient Sarsa
Under the tabular setting, the Sarsa update is given by:
![Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha \Big[ R_{t+1} + \gamma Q(S_{t+1}, A_{t+1}) - Q(S_t, A_t) \Big]](https://s0.wp.com/latex.php?latex=Q%28S_t%2C+A_t%29+%5Cleftarrow+Q%28S_t%2C+A_t%29+%2B+%5Calpha+%5CBig%5B+R_%7Bt%2B1%7D+%2B+%5Cgamma+Q%28S_%7Bt%2B1%7D%2C+A_%7Bt%2B1%7D%29+-+Q%28S_t%2C+A_t%29+%5CBig%5D+&bg=ffffff&fg=000&s=1&c=20201002)
This update can be interpreted as using the action  actually taken in the next state to estimate the action-value under the current policy , and then correcting the current estimate accordingly. For this reason, Sarsa is a canonical on-policy TD control method.
actually taken in the next state to estimate the action-value under the current policy , and then correcting the current estimate accordingly. For this reason, Sarsa is a canonical on-policy TD control method.
When the state–action space becomes too large to maintain in a table, we instead represent the action-value function using linear function approximation:

In this setting, the object being learned is no longer a scalar value associated with a particular , but the parameter vector itself. Our goal is to adjust so that, during interaction,

Therefore, once function approximation is introduced, the control problem becomes a parameter-learning problem, that is how to use the TD error to incrementally refine so that the approximate action-value function better matches the true values induced by the current policy.
For episodic tasks, the TD target and TD error in Sarsa are defined as:

Because the action-value function is represented in a parameterized form, updates require taking gradients with respect to the parameters. Combining this with the gradient of the linear approximation,  , the parameter update for episodic Sarsa can be written as:
, the parameter update for episodic Sarsa can be written as:
![\mathbf{w}_{t+1} \doteq \mathbf{w}_t + \alpha \Big[ R_{t+1} + \gamma \hat{q}(S_{t+1}, A_{t+1}, \mathbf{w}_t) - \hat{q}(S_t, A_t, \mathbf{w}_t) \Big] \nabla \hat{q}(S_t, A_t, \mathbf{w}_t) \\\\ \hphantom{\mathbf{w}_{t+1}} = \mathbf{w}_t + \alpha \Big[ R_{t+1} + \gamma \hat{q}(S_{t+1}, A_{t+1}, \mathbf{w}_t) - \hat{q}(S_t, A_t, \mathbf{w}_t) \Big] \mathbf{x}(S_t, A_t)](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bw%7D_%7Bt%2B1%7D+%5Cdoteq+%5Cmathbf%7Bw%7D_t+%2B+%5Calpha+%5CBig%5B+R_%7Bt%2B1%7D+%2B+%5Cgamma+%5Chat%7Bq%7D%28S_%7Bt%2B1%7D%2C+A_%7Bt%2B1%7D%2C+%5Cmathbf%7Bw%7D_t%29+-+%5Chat%7Bq%7D%28S_t%2C+A_t%2C+%5Cmathbf%7Bw%7D_t%29+%5CBig%5D+%5Cnabla+%5Chat%7Bq%7D%28S_t%2C+A_t%2C+%5Cmathbf%7Bw%7D_t%29+%5C%5C%5C%5C+%5Chphantom%7B%5Cmathbf%7Bw%7D_%7Bt%2B1%7D%7D+%3D+%5Cmathbf%7Bw%7D_t+%2B+%5Calpha+%5CBig%5B+R_%7Bt%2B1%7D+%2B+%5Cgamma+%5Chat%7Bq%7D%28S_%7Bt%2B1%7D%2C+A_%7Bt%2B1%7D%2C+%5Cmathbf%7Bw%7D_t%29+-+%5Chat%7Bq%7D%28S_t%2C+A_t%2C+%5Cmathbf%7Bw%7D_t%29+%5CBig%5D+%5Cmathbf%7Bx%7D%28S_t%2C+A_t%29+&bg=ffffff&fg=000&s=1&c=20201002)
This method is referred to as episodic semi-gradient one-step Sarsa. The term semi-gradient indicates that, during the update, the component  appearing in the TD target is treated as a constant and its gradient is not taken. Although this approach deviates from full gradient descent on a well-defined error function, it nevertheless exhibits good practical stability under on-policy learning with linear function approximation.
appearing in the TD target is treated as a constant and its gradient is not taken. Although this approach deviates from full gradient descent on a well-defined error function, it nevertheless exhibits good practical stability under on-policy learning with linear function approximation.

Expected Sarsa with Function Approximation
Episodic Semi-Gradient Sarsa uses the action value corresponding to the actual next action taken as the TD target. Conceptually, this faithfully reflects the current behavior policy. However, this design also introduces a practical issue: the variance of the TD target is directly influenced by exploratory behavior.
When the policy is -greedy, even after the value function has largely converged, the agent will still take non-greedy actions with probability . These occasional exploratory actions can cause significant fluctuations in  , leading to highly unstable TD targets across time steps. As a result, the direction of parameter updates becomes sensitive to random sampling, which can degrade both learning efficiency and stability.
, leading to highly unstable TD targets across time steps. As a result, the direction of parameter updates becomes sensitive to random sampling, which can degrade both learning efficiency and stability.
Expected Sarsa is an improved variant proposed to address this issue. Its core idea is that, since the randomness of the TD target arises from sampling the next action, and since the distribution over actions is already explicitly defined by the current policy , one can take the expectation over action values directly, rather than performing another random sample. Specifically, at state  , the Expected Sarsa update is given by:
, the Expected Sarsa update is given by:
![\displaystyle Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha [R_{t+1} + \gamma \sum_a \pi(a \mid S_{t+1}) Q(S_{t+1}, a) - Q(S_t, A_t)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Q%28S_t%2C+A_t%29+%5Cleftarrow+Q%28S_t%2C+A_t%29+%2B+%5Calpha+%5BR_%7Bt%2B1%7D+%2B+%5Cgamma+%5Csum_a+%5Cpi%28a+%5Cmid+S_%7Bt%2B1%7D%29+Q%28S_%7Bt%2B1%7D%2C+a%29+-+Q%28S_t%2C+A_t%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
Under this formulation, exploratory behavior is still fully preserved in the policy , but its effect is incorporated in an averaged manner through the expectation, rather than being injected directly into the TD target as high-variance noise.
Combining linear function approximation with the semi-gradient update scheme, the parameter update for Expected Sarsa can be written as:
![\displaystyle \mathbf{w}_{t+1} \doteq \mathbf{w}_t + \alpha \Big[ R_{t+1} + \gamma \sum_a \pi(a \mid S_{t+1}) \hat{q}(S_{t+1}, a, \mathbf{w}_t) - \hat{q}(S_t, A_t, \mathbf{w}_t \Big] \nabla \hat{q}(S_t, A_t, \mathbf{w}_t) \\\\ \hphantom{\mathbf{w}_{t+1}} = \mathbf{w}_t + \alpha \Big[ R_{t+1} + \gamma \sum_a \pi(a \mid S_{t+1}) \hat{q}(S_{t+1}, a, \mathbf{w}_t) - \hat{q}(S_t, A_t, \mathbf{w}_t \Big] \mathbf{x}(S_t, A_t)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbf%7Bw%7D_%7Bt%2B1%7D+%5Cdoteq+%5Cmathbf%7Bw%7D_t+%2B+%5Calpha+%5CBig%5B+R_%7Bt%2B1%7D+%2B+%5Cgamma+%5Csum_a+%5Cpi%28a+%5Cmid+S_%7Bt%2B1%7D%29+%5Chat%7Bq%7D%28S_%7Bt%2B1%7D%2C+a%2C+%5Cmathbf%7Bw%7D_t%29+-+%5Chat%7Bq%7D%28S_t%2C+A_t%2C+%5Cmathbf%7Bw%7D_t+%5CBig%5D+%5Cnabla+%5Chat%7Bq%7D%28S_t%2C+A_t%2C+%5Cmathbf%7Bw%7D_t%29+%5C%5C%5C%5C+%5Chphantom%7B%5Cmathbf%7Bw%7D_%7Bt%2B1%7D%7D+%3D+%5Cmathbf%7Bw%7D_t+%2B+%5Calpha+%5CBig%5B+R_%7Bt%2B1%7D+%2B+%5Cgamma+%5Csum_a+%5Cpi%28a+%5Cmid+S_%7Bt%2B1%7D%29+%5Chat%7Bq%7D%28S_%7Bt%2B1%7D%2C+a%2C+%5Cmathbf%7Bw%7D_t%29+-+%5Chat%7Bq%7D%28S_t%2C+A_t%2C+%5Cmathbf%7Bw%7D_t+%5CBig%5D+%5Cmathbf%7Bx%7D%28S_t%2C+A_t%29+&bg=ffffff&fg=000&s=1&c=20201002)
From an implementation perspective, this update is almost identical to that of semi-gradient Sarsa; the only difference lies in how the TD target is computed. Despite being a seemingly minor modification, this change has a substantial impact on learning behavior. Because the TD target no longer depends on a single randomly selected action, Expected Sarsa typically produces smoother update directions and is less sensitive to the choice of step size. In environments with high reward variance or high exploratory risk, Expected Sarsa often exhibits more stable convergence behavior than standard Sarsa.
Example
Implementation of Semi-Gradient Sarsa Using Neural Network
In the following code, we implement Semi-Gradient Sarsa as an on-policy TD control method and use a neural network to approximate the action-value function . Because the TD target itself contains an estimate of the next step (i.e., bootstrapping), and this estimate is also produced by the current approximator, propagating gradients through the target would cause the update to deviate from the standard TD formulation.
Therefore, this implementation adopts a semi-gradient update, that is the TD target is treated as a constant, and gradients are taken only with respect to the current prediction  when updating the parameters, while no gradient is propagated through the target term. In other words, backpropagation is applied solely to the current estimate, preserving the characteristic update structure and learning behavior of TD control.
when updating the parameters, while no gradient is propagated through the target term. In other words, backpropagation is applied solely to the current estimate, preserving the characteristic update structure and learning behavior of TD control.
import numpy as np
import torch
from torch import nn, optim
from mlp_q_network import MLPQNetwork
class MLPQNetwork(nn.Module):
def __init__(self, observation_dim: int, n_actions: int, hidden_dim: int):
super().__init__()
self.network = nn.Sequential(
nn.Linear(observation_dim, hidden_dim),
nn.LayerNorm(hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.LayerNorm(hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, n_actions),
)
def forward(self, s: torch.Tensor) -> torch.Tensor:
return self.network(s)
class MLPSarsa:
def __init__(
self,
observation_dim: int,
n_actions: int,
*,
hidden_dim: int,
lr=1e-4,
grad_clip=5.0,
gamma=0.99,
epsilon=0.1,
):
self.observation_dim = observation_dim
self.n_actions = n_actions
self.grad_clip = grad_clip
self.gamma = gamma
self.epsilon = epsilon
self.q_network = MLPQNetwork(observation_dim, n_actions, hidden_dim)
self.optimizer = optim.Adam(self.q_network.parameters(), lr=lr)
@torch.no_grad()
def q_s(self, s: np.ndarray) -> np.ndarray:
x = torch.tensor(s, dtype=torch.float32).unsqueeze(0)
q = self.q_network(x).squeeze(0)
return q.numpy()
def act(self, s: np.ndarray, greedy: bool = False) -> tuple[int, np.ndarray]:
q = self.q_s(s)
if not greedy and np.random.rand() < self.epsilon:
a = np.random.randint(self.n_actions)
else:
ties = np.flatnonzero(np.isclose(q, q.max()))
a = np.random.choice(ties)
p = np.ones(self.n_actions) * (self.epsilon / self.n_actions)
greedy_a = np.argmax(q)
p[greedy_a] += 1.0 - self.epsilon
return a, p
def update(self, s: np.ndarray, a: int, r: float, s_prime: np.ndarray, terminated: bool) -> float:
s_t = torch.tensor(s, dtype=torch.float32).unsqueeze(0)
s_tp1 = torch.tensor(s_prime, dtype=torch.float32).unsqueeze(0)
q_t_s = self.q_network(s_t).squeeze(0)
q_t_sa = q_t_s[a]
with torch.no_grad():
if terminated:
target = torch.tensor(r, dtype=torch.float32)
else:
a_tp1, _ = self.act(s_prime)
q_tp1_s = self.q_network(s_tp1).squeeze(0)
q_sa = q_tp1_s[a_tp1]
target = r + self.gamma * q_sa
loss = 0.5 * (target - q_t_sa) ** 2
self.optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(self.q_network.parameters(), self.grad_clip)
self.optimizer.step()
return float(loss.item())Implementation of Semi-Gradient Expected Sarsa Using Neural Network
In the following code, we implement Semi-Gradient Expected Sarsa as an on-policy TD control method and use a neural network to approximate the action-value function . The overall training procedure is identical to that of Semi-Gradient Sarsa; the only difference lies in how the TD target is defined.
Because the TD target contains the expected action-value at the next state, and this expectation is also computed using the current function approximator, the update still follows a semi-gradient approach. Specifically, the TD target is treated as a constant, and gradients are backpropagated only through the current prediction , with no gradient propagated through the target term.
In other words, when implemented with a neural network, Expected Sarsa does not alter the fundamental structure of the parameter update. Instead, it replaces the single-sample next-action estimate used in Sarsa with an expectation over action values. This design yields a smoother TD target and, while preserving the on-policy framework, further reduces the variance of the updates.
import numpy as np
import torch
from torch import nn, optim
from mlp_q_network import MLPQNetwork
class MLPExpectedSarsa:
def __init__(
self,
observation_dim: int,
n_actions: int,
*,
hidden_dim: int,
lr=1e-4,
grad_clip=5.0,
gamma=0.99,
epsilon=0.1,
):
self.observation_dim = observation_dim
self.n_actions = n_actions
self.grad_clip = grad_clip
self.gamma = gamma
self.epsilon = epsilon
self.q_network = MLPQNetwork(observation_dim, n_actions, hidden_dim)
self.optimizer = optim.Adam(self.q_network.parameters(), lr=lr)
@torch.no_grad()
def q_values(self, s: np.ndarray) -> np.ndarray:
x = torch.tensor(s, dtype=torch.float32).unsqueeze(0)
q = self.q_network(x).squeeze(0)
return q.numpy()
def act(self, s: np.ndarray, greedy: bool = False) -> tuple[int, np.ndarray]:
q = self.q_values(s)
if not greedy and np.random.rand() < self.epsilon:
a = np.random.randint(self.n_actions)
else:
ties = np.flatnonzero(np.isclose(q, q.max()))
a = np.random.choice(ties)
p = np.ones(self.n_actions) * (self.epsilon / self.n_actions)
greedy_a = np.argmax(q)
p[greedy_a] += 1.0 - self.epsilon
return a, p
def update(self, s: np.ndarray, a: int, r: float, s_prime: np.ndarray, terminated: bool) -> float:
s_t = torch.tensor(s, dtype=torch.float32).unsqueeze(0)
s_tp1 = torch.tensor(s_prime, dtype=torch.float32).unsqueeze(0)
q_t_s = self.q_network(s_t).squeeze(0)
q_t_sa = q_t_s[a]
with torch.no_grad():
if terminated:
target = torch.tensor(r, dtype=torch.float32)
else:
q_tp1_s = self.q_network(s_tp1).squeeze(0)
p = torch.ones(self.n_actions, dtype=torch.float32) * (self.epsilon / self.n_actions)
a_start = torch.argmax(q_tp1_s).item()
p[a_start] += 1.0 - self.epsilon
expected_q_tp1 = torch.sum(q_tp1_s * p)
target = r + self.gamma * expected_q_tp1
loss = 0.5 * (target - q_t_sa) ** 2
self.optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(self.q_network.parameters(), self.grad_clip)
self.optimizer.step()
return float(loss.item())Lunar Lander
LunarLander is a classic rocket-trajectory optimization problem. According to Pontryagin’s maximum principle, under an optimal policy the engine is either fired at full thrust or kept completely off. Accordingly, this environment uses a discrete action space, where each action corresponds to turning an engine on or off.
The action space contains four actions:
- 0: Do nothing.
- 1: Fire the left engine.
- 2: Fire the main engine.
- 3: Fire the right engine.
Each state is an 8-dimensional vector consisting of:
- The lander’s x and y position.
- The lander’s x and y linear velocity.
- The lander’s angle.
- The lander’s angular velocity.
- Two boolean values indicating whether the left and right legs are in contact with the ground.
At each time step, the reward is shaped as follows:
- The closer the lander is to the landing pad, the higher the reward; the farther away, the lower the reward.
- The slower the lander is moving, the higher the reward; the faster it is moving, the lower the reward.
- The more the lander is tilted, the lower the reward.
- A bonus of +10 is given for each leg that is in contact with the ground.
- A penalty of −0.03 is applied for each frame in which a side engine fires.
- A penalty of −0.3 is applied for each frame in which the main engine fires.
When an episode terminates by either crashing or landing safely, an additional terminal reward is given:
- Crash: −100.
- Safe landing: +100.
An episode is considered solved if its total reward reaches 200 or higher.
In the following code, we train Expected Sarsa and Sarsa for 1000 episodes.
import time
import gymnasium as gym
from expected_sarsa_nn import MLPExpectedSarsa
from sarsa_nn import MLPSarsa
GYM_ID = "LunarLander-v3"
N_EPISODES = 1000
MAX_STEPS = 10_000
ALGO = "Sarsa"
# ALGO = "Expected Sarsa"
def play_game(agent: MLPExpectedSarsa, episodes=1):
visual_env = gym.make(GYM_ID, render_mode="human")
for episode in range(episodes):
state, _ = visual_env.reset()
terminated = False
truncated = False
total_reward = 0.0
step_count = 0
input("Press Enter to play game")
print(f"Episode {episode + 1} starts")
while not terminated and not truncated:
action, _ = agent.act(state, greedy=True)
state, reward, terminated, truncated, _ = visual_env.step(action)
total_reward += reward
step_count += 1
visual_env.render()
print(f"Episode {episode + 1} is finished: Total reward is {total_reward}, steps = {step_count}")
time.sleep(1)
visual_env.close()
def train(env: gym.Env, agent: MLPExpectedSarsa):
for i_episode in range(1, N_EPISODES + 1):
print(f"\rEpisode: {i_episode}/{N_EPISODES}", end="", flush=True)
s, _ = env.reset()
done = False
G = 0.0
steps = 0
a, _ = agent.act(s)
while not done and steps < MAX_STEPS:
s_prime, r, terminated, truncated, _ = env.step(a)
G += r
done = terminated or truncated
if done:
a_prime = 0
else:
a_prime, _ = agent.act(s_prime)
agent.update(s, a, r, s_prime, done)
s, a = s_prime, a_prime
steps += 1
if __name__ == "__main__":
env = gym.make(GYM_ID)
if ALGO == "Sarsa":
agent = MLPSarsa(
observation_dim=env.observation_space.shape[0],
n_actions=env.action_space.n,
hidden_dim=256,
)
else:
agent = MLPExpectedSarsa(
observation_dim=env.observation_space.shape[0],
n_actions=env.action_space.n,
hidden_dim=256,
)
train(env, agent)
env.close()
play_game(agent)Under the same experimental setup, we trained agents using Semi-Gradient Sarsa and Semi-Gradient Expected Sarsa in the LunarLander environment for a total of 1000 episodes, and observed markedly different learning behaviors. Agents trained with Sarsa tended to crash frequently during the early stages of training. In contrast, agents trained with Expected Sarsa were more inclined to adopt conservative strategies, gradually learning to decelerate and correct their attitude, and ultimately achieving relatively stable landings.
This difference can be directly understood from the way the TD target is defined in the two methods. In Semi-Gradient Sarsa, each update uses the action-value corresponding to the actual next action taken, , as the learning target. As a result, the TD target is strongly influenced by the randomness introduced by exploratory behavior. In a high-risk continuous control environment such as LunarLander, even when the exploration rate is relatively small, occasional non-greedy actions can still induce drastic changes in attitude or velocity near the ground, leading to extreme negative rewards.
These high-variance TD targets are injected directly into the parameter updates. Under function approximation, a large error from a single sample does not only affect the current state, but also propagates to other states and actions through shared parameters. Consequently, the learned policy tends to overcorrect or exhibit aggressive control behaviors, manifesting as fast but highly unstable actions and ultimately resulting in frequent crashes.
By contrast, Expected Sarsa does not rely on a single randomly sampled action when performing TD updates. Instead, it takes the expectation over the action values of all possible actions at the next state. This averages the risk introduced by exploratory behavior into the learning signal, thereby substantially reducing the variance of the TD target. In the context of function approximation, such smoother update directions help prevent violent oscillations in the parameters across successive updates, allowing the agent to more readily learn gradual deceleration, fine-grained attitude corrections, and stable control near the ground.
As a result, although Expected Sarsa may learn more slowly in the early stages, it ultimately exhibits safer behavior that better aligns with the task’s requirement for precise control.
Overall, these experimental results clearly demonstrate that, in the setting of on-policy control with function approximation, the critical distinction between algorithms does not lie in whether a neural network is used, but in how the TD target handles the uncertainty introduced by exploratory behavior. Through its expectation-based update mechanism, Expected Sarsa achieves a better balance between stability and learning efficiency, making it particularly well suited for control problems like LunarLander, where action continuity and precision are highly critical.
Conclusion
Once control problems enter the regime of function approximation, learning behavior is no longer determined solely by the name of the algorithm, but by the design of the TD target and how it handles the uncertainty introduced by exploration. Within the on-policy framework, Semi-Gradient Sarsa and Expected Sarsa share the same update structure and implementation pipeline; yet, the simple distinction of whether the TD target takes an expectation over the next action leads to markedly different stability and behavioral characteristics. As evidenced by the LunarLander experiments, Expected Sarsa trades smoother update directions for more stable and safer control behavior, clearly illustrating that, in on-policy control with function approximation, stability is often more critical than short-term learning speed. This observation reinforces the idea that understanding TD methods should go beyond the update equations themselves, and instead focus on how learning signals are constructed and how they shape the overall learning dynamics.
References
- Adam White and Martha White. Reinforcement Learning Specialization. University of Alberta and Coursera.
- Richard S. Sutton and Andrew G. Barto. 2020. Reinforcement Learning: An Introduction, 2nd. The MIT Press.









