
In probabilistic modeling and machine learning, entropy is a fundamental concept for quantifying uncertainty. It not only describes the inherent randomness of data, but also implicitly captures the minimum information cost required in prediction and modeling. Many learning objectives that may appear different on the surface, such as maximizing log-likelihood or designing loss functions, can in fact be traced back and understood through the lens of entropy.
Table of Contents
Self-Information
In information theory, self-information refers to the amount of information associated with the occurrence of a specific event, determined by its probability of happening. It is also commonly called information content. This concept originates from the information-theoretic framework established by Claude Shannon in 1948, and it is one of the most fundamental definitions in the entire theory.
Suppose the probability of an event  is
is 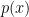 . The self-information
. The self-information  is defined as:
is defined as:

The base of the logarithm determines the unit of information. If a base-2 logarithm is used, the unit is bits; if the natural logarithm is used, the unit is nats. Throughout this article, we use  as the default.
as the default.
Let us consider an intuitive example. Suppose the probability that David passes an exam is  , while the probability that Wayne passes the exam is
, while the probability that Wayne passes the exam is  . When David passes the exam, this is a relatively rare event and therefore produces a higher sense of surprise. In contrast, when Wayne passes the exam, the event is highly likely, and we are hardly surprised at all. This intuitive notion of surprise is precisely what self-information attempts to quantify. The corresponding information values are:
. When David passes the exam, this is a relatively rare event and therefore produces a higher sense of surprise. In contrast, when Wayne passes the exam, the event is highly likely, and we are hardly surprised at all. This intuitive notion of surprise is precisely what self-information attempts to quantify. The corresponding information values are:

As we can see, events with lower probabilities have higher self-information, whereas events with higher probabilities carry less information. In other words, self-information quantifies the degree of surprise associated with the occurrence of an event, and is therefore often referred to in the literature as surprisal.
We can also interpret the information content of an event from a coding perspective. Suppose we have a set of 8 equally likely events  . To encode each event, we require 3 bits.
. To encode each event, we require 3 bits.
Beyond serving as a measure of surprise, self-information is also directly related to coding. Given a set of 8 equally likely events , each event can be represented using 3 bits:

Since the events are equiprobable, we have  . The self-information of each event is therefore:
. The self-information of each event is therefore:

That is, in this case, the amount of information carried by each event exactly corresponds to the shortest fixed-length code required to represent it, namely 3 bits.
When event probabilities are not equal, fixed-length coding is no longer optimal. According to results from information theory, the optimal coding strategy assigns shorter bit representations to high-probability events and longer bit representations to low-probability events. Under such an optimal coding scheme, the self-information  can be interpreted as the minimum code length required for that event in an optimal average sense.
can be interpreted as the minimum code length required for that event in an optimal average sense.
Entropy
Consider a random source composed of a set of events  , where each event
, where each event  occurs with probability
occurs with probability 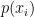 . In this setting, although the overall probability distribution
. In this setting, although the overall probability distribution  is known, before the event actually occurs we cannot know in advance which specific event will be realized, and therefore cannot determine beforehand which particular self-information value will be associated with it.
is known, before the event actually occurs we cannot know in advance which specific event will be realized, and therefore cannot determine beforehand which particular self-information value will be associated with it.
In other words, prior to the occurrence of an event, the system is in a state of uncertainty. What we care about is not the information content of a single event, but rather, on average, how much information the random source as a whole will produce. Given that the probability distribution is known, the only reasonable and consistent way to quantify this is to take the expectation of the self-information over all possible events, weighted by their probabilities.
Based on this motivation, entropy is defined as the expected value of the self-information of a random variable:
![\displaystyle H(X) = \mathbb{E}_{x \sim p} [I(x)] = \sum_{x \in X} p(x) (- \log p(x)) = - \sum_{x \in X} p(x) \log p(x)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+H%28X%29+%3D+%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%7D+%5BI%28x%29%5D+%3D+%5Csum_%7Bx+%5Cin+X%7D+p%28x%29+%28-+%5Clog+p%28x%29%29+%3D+-+%5Csum_%7Bx+%5Cin+X%7D+p%28x%29+%5Clog+p%28x%29+&bg=ffffff&fg=000&s=1&c=20201002)
Therefore, entropy measures the average amount of information required when a result is randomly drawn from the probability distribution before any event has occurred. This quantity was introduced by Claude Shannon in 1948 as one of the foundational concepts of information theory. To distinguish it from other generalized forms of entropy, it is commonly referred to as Shannon entropy.
From the definition, the relationship between entropy and self-information is clear:
- Self-information describes the amount of information produced when a particular event occurs.
- Entropy describes the average information content of the entire random source before any event occurs, that is, the degree of its uncertainty.
Let us return to the earlier example of David and Wayne taking an exam. Let the random variable  represent the exam outcome, with the event set:
represent the exam outcome, with the event set:

The entropies of David’s and Wayne’s exam outcomes are then given by:
![H_{\text{D}}(X) = \mathbb{E}_{x \sim p(x)} [I(x)] \\\\ \phantom{H_{\text{D}}(X)} = \sum_{x \in X} p(x) (- \log_2 p(x)) \\\\ \phantom{H_{\text{D}}(X)} = 0.3 (-\log_2 0.3) + 0.7 (-\log_2 0.7) \approx 0.88 \\\\ H_{\text{W}}(X) = 0.9 (-\log_2 0.9) + 0.1 (-\log_2 0.1) \approx 0.47](https://s0.wp.com/latex.php?latex=H_%7B%5Ctext%7BD%7D%7D%28X%29+%3D+%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%28x%29%7D+%5BI%28x%29%5D+%5C%5C%5C%5C+%5Cphantom%7BH_%7B%5Ctext%7BD%7D%7D%28X%29%7D+%3D+%5Csum_%7Bx+%5Cin+X%7D+p%28x%29+%28-+%5Clog_2+p%28x%29%29+%5C%5C%5C%5C+%5Cphantom%7BH_%7B%5Ctext%7BD%7D%7D%28X%29%7D+%3D+0.3+%28-%5Clog_2+0.3%29+%2B+0.7+%28-%5Clog_2+0.7%29+%5Capprox+0.88+%5C%5C%5C%5C+H_%7B%5Ctext%7BW%7D%7D%28X%29+%3D+0.9+%28-%5Clog_2+0.9%29+%2B+0.1+%28-%5Clog_2+0.1%29+%5Capprox+0.47+&bg=ffffff&fg=000&s=1&c=20201002)
We can see that Wayne’s exam outcome has a significantly lower entropy. This indicates that the outcome is highly predictable, with most of the probability mass concentrated on passing, and therefore the uncertainty faced before the event occurs is relatively lower.
Conditional Entropy
Consider two discrete random variables and  . In the absence of any additional information, the uncertainty of the random variable can be measured by its entropy
. In the absence of any additional information, the uncertainty of the random variable can be measured by its entropy  . However, if we have already observed the value of , the probability distribution of is updated from the marginal distribution
. However, if we have already observed the value of , the probability distribution of is updated from the marginal distribution  to the conditional distribution
to the conditional distribution  . In this case, the uncertainty of should be reassessed.
. In this case, the uncertainty of should be reassessed.
Given  , the self-information and entropy of under this condition are defined as:
, the self-information and entropy of under this condition are defined as:
![I(y \mid x) = -\log p(y \mid x) \\\\ \displaystyle H(Y \mid X=x) = \mathbb{E}_{y \sim p(\cdot \mid x)} [I(y \mid x)] = \sum_{y \in Y} p(y \mid x) (-\log p(y \mid x))](https://s0.wp.com/latex.php?latex=I%28y+%5Cmid+x%29+%3D+-%5Clog+p%28y+%5Cmid+x%29+%5C%5C%5C%5C+%5Cdisplaystyle+H%28Y+%5Cmid+X%3Dx%29+%3D+%5Cmathbb%7BE%7D_%7By+%5Csim+p%28%5Ccdot+%5Cmid+x%29%7D+%5BI%28y+%5Cmid+x%29%5D+%3D+%5Csum_%7By+%5Cin+Y%7D+p%28y+%5Cmid+x%29+%28-%5Clog+p%28y+%5Cmid+x%29%29+&bg=ffffff&fg=000&s=1&c=20201002)
Since we do not know in advance which value will take, we must further take the expectation over all possible values of . Accordingly, conditional entropy is defined as:
However, before the event occurs, we do not know which value will take. Therefore, in order to measure the overall average uncertainty of given knowledge of , we must take an expectation over all possible values of , weighted by their probabilities. Based on this motivation, conditional entropy is defined as:
![\displaystyle H(Y \mid X) = \mathbb{E}_{x \sim p} [H(Y \mid X=x)] \\\\ \hphantom{H(Y \mid X)} = \mathbb{E}_{x \sim p} \Big[ \mathbb{E}_{y \sim p(\cdot \mid x)} [I(y \mid x)] \Big] \\\\ \hphantom{H(Y \mid X)} = \sum_{x \in X} \sum_{y \in Y} p(x, y) (-\log p(y \mid x))](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+H%28Y+%5Cmid+X%29+%3D+%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%7D+%5BH%28Y+%5Cmid+X%3Dx%29%5D+%5C%5C%5C%5C+%5Chphantom%7BH%28Y+%5Cmid+X%29%7D+%3D+%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%7D+%5CBig%5B+%5Cmathbb%7BE%7D_%7By+%5Csim+p%28%5Ccdot+%5Cmid+x%29%7D+%5BI%28y+%5Cmid+x%29%5D+%5CBig%5D+%5C%5C%5C%5C+%5Chphantom%7BH%28Y+%5Cmid+X%29%7D+%3D+%5Csum_%7Bx+%5Cin+X%7D+%5Csum_%7By+%5Cin+Y%7D+p%28x%2C+y%29+%28-%5Clog+p%28y+%5Cmid+x%29%29+&bg=ffffff&fg=000&s=1&c=20201002)
Thus, conditional entropy measures the average amount of information required for given that the random variable is known. In other words, it quantifies the average remaining uncertainty about when is given.
The relationship between conditional entropy and Shannon entropy is as follows:
 : the uncertainty about when no information is known.
: the uncertainty about when no information is known.- : the remaining uncertainty about after is known.
 : the remaining uncertainty about
: the remaining uncertainty about Since additional information can only reduce, and never increase, uncertainty, we necessarily have:

If and are independent, that is,  , then observing provides no information about , and we have:
, then observing provides no information about , and we have:

Returning to the earlier example of David and Wayne taking an exam, if the two belong to different classes, or even different grades, their exam outcomes are independent. In this case, observing Wayne’s exam result does not change our assessment of David’s performance, and therefore:

However, if David and Wayne are in the same class and take the same exam, the situation is different. Suppose that when Wayne fails the exam, it often indicates that the exam was particularly difficult, which significantly reduces the probability that David passes. In this case, observing  does indeed reduce our uncertainty about David’s exam outcome.
does indeed reduce our uncertainty about David’s exam outcome.
Assume that under such circumstances:

Then, under the condition , the entropy of David’s exam outcome is:

We can see that, given the information that Wayne failed the exam, David’s outcome is almost certainly a failure as well, and the uncertainty is significantly reduced. This example clearly illustrates that conditional entropy characterizes the remaining uncertainty after some information has been observed.
Information Gain
Consider two discrete random variables and .
- When is unknown, the uncertainty of the random variable can be measured by its entropy .
- When a specific event is known, the probability distribution of is updated to , and the remaining uncertainty is given by .
 .
.Therefore, the reduction in uncertainty of after observing the specific event can be naturally defined as the information gain:

Information gain measures the amount of information we actually obtain about after observing the particular outcome , that is, the extent to which the uncertainty of is reduced. If observing makes the distribution of more concentrated, the information gain will be larger; conversely, if the conditional distribution is almost identical to the original distribution, the information gain will be close to zero.
Let us return to the earlier example of David and Wayne taking an exam. Suppose that before knowing Wayne’s exam result, the entropy of David’s exam outcome is:

After observing that Wayne failed the exam, the conditional entropy of David’s exam outcome is:

Thus, after learning that , the information gain about David’s exam outcome is:

This indicates that merely observing the single event that Wayne failed the exam reduces our average uncertainty about David’s exam outcome by approximately 0.69. This example clearly illustrates that information gain captures the informational value that a specific observation provides about another random variable.
Mutual Information
Since before an event occurs we do not know which specific value the random variable will take, if we wish to measure the amount of information that provides about in an overall average sense, we must take an expectation over all possible values of , weighted by their probabilities. In this setting, the expected value of information gain gives rise to mutual information:
![I(Y ; X) = \mathbb{E}_{x \sim p} [ IG(Y ; X = x)] = H(Y) - H(Y \mid X)](https://s0.wp.com/latex.php?latex=I%28Y+%3B+X%29+%3D+%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%7D+%5B+IG%28Y+%3B+X+%3D+x%29%5D+%3D+H%28Y%29+-+H%28Y+%5Cmid+X%29+&bg=ffffff&fg=000&s=1&c=20201002)
Mutual information is symmetric, and therefore we have:

This shows that mutual information does not favor either random variable, but instead describes the amount of information shared between and . That is, the portion of uncertainty about one variable that can be eliminated by knowing the other.
From another perspective, mutual information can also be written in an equivalent form that directly involves probability distributions:

This expression clearly shows that mutual information measures the discrepancy between the joint distribution  and the distribution
and the distribution  under the assumption of independence. If and are independent, these two distributions coincide and the mutual information is zero.
under the assumption of independence. If and are independent, these two distributions coincide and the mutual information is zero.
Returning to the earlier example of David and Wayne taking an exam, suppose that:
- , and .
- .
- When Wayne fails, .
- When Wayne passes, .
 , and
, and  .
. .
. .
. .
.First, the entropy of David’s exam outcome is:

Next, we compute the entropy under different conditions:

Taking the expectation over Wayne’s exam outcome yields the conditional entropy:

Therefore, the mutual information between David’s and Wayne’s exam outcomes is:

This indicates that Wayne’s exam result does indeed provide information about David’s outcome. When Wayne fails, David almost certainly fails as well; when Wayne passes, David’s probability of passing also increases slightly. However, because Wayne almost always passes, the highly informative event occurs with very low probability. As a result, in an overall average sense, the mutual information remains quite limited.
Cross-Entropy
We already know that Shannon entropy can be used to measure the average amount of information of a probability distribution :
![H(X) = \mathbb{E}_{x \sim p} [ I(x) ] = \mathbb{E}_{x \sim p} [ -\log p(x) ]](https://s0.wp.com/latex.php?latex=H%28X%29+%3D+%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%7D+%5B+I%28x%29+%5D+%3D+%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%7D+%5B+-%5Clog+p%28x%29+%5D+&bg=ffffff&fg=000&s=1&c=20201002)
However, in practical settings, the true data-generating distribution is often unknown. Typically, we can only obtain an approximate distribution  through some model, which is used to describe or predict the data-generating process. In other words, although the data are actually generated according to , during encoding or prediction we assign probabilities according to
through some model, which is used to describe or predict the data-generating process. In other words, although the data are actually generated according to , during encoding or prediction we assign probabilities according to  .
.
In this situation, a natural question arises: when data are generated from the true distribution but described using the model distribution , how much information is required on average?
Motivated by this question, cross-entropy is defined as:
![\displaystyle H(p, q) = \mathbb{E}_{x \sim p} [-\log q(x)] = \sum_{x \in X} p(x) (-\log q(x))](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+H%28p%2C+q%29+%3D+%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%7D+%5B-%5Clog+q%28x%29%5D+%3D+%5Csum_%7Bx+%5Cin+X%7D+p%28x%29+%28-%5Clog+q%28x%29%29+&bg=ffffff&fg=000&s=1&c=20201002)
Thus, cross-entropy measures the average information cost incurred when data are generated from the true distribution but encoded or predicted using the model distribution .
If the model distribution happens to be equal to the true distribution, that is,  , then cross-entropy reduces to entropy itself:
, then cross-entropy reduces to entropy itself:

From an intuitive perspective, we can summarize the relationship as follows:
- If the model distribution is very close to the true distribution , then will be slightly larger than, but very close to, .
- If the model distribution differs significantly from the true distribution , then will be much larger than .
Therefore, entropy  can be regarded as a theoretical lower bound of cross-entropy
can be regarded as a theoretical lower bound of cross-entropy  :
:
 。
。
This inequality reflects the fact that using an incorrect probability distribution to describe data inevitably incurs additional average information cost.
Let us return once again to David’s exam example, but this time consider only David. Suppose that a teacher from a neighboring class observes David looking toward the front during class (while actually daydreaming), mistakenly assumes that he is very attentive, and subjectively believes that David’s probability of passing the exam is 0.8. In this case, we have:

First, the entropy of the true distribution is:

This means that if the homeroom teacher uses the correct distribution to predict David’s exam outcome, the long-term average surprisal incurred per prediction is 0.88.
Next, if the neighboring-class teacher uses the incorrect model distribution to make predictions, the cross-entropy is:

When the neighboring-class teacher uses the incorrect model distribution to predict David’s exam outcome, the average surprisal incurred is 1.72. In other words, compared with the homeroom teacher, the neighboring-class teacher incurs an additional surprisal of  .
.
That is, under long-term prediction, the neighboring-class teacher must bear an average surprisal of 1.72 per prediction. Compared to using the correct distribution, this corresponds to an extra information cost of .
Kullback–Leibler Divergence (KL Divergence)
We have already seen that for a true probability distribution , its entropy is defined as:

This quantity describes the average uncertainty that is unavoidable even when the true distribution is fully known.
On the other hand, when data are still generated from the true distribution , but we use another model distribution to describe or encode the data, the average information cost is given by the cross-entropy:

In this setting, the difference between and corresponds precisely to the following question: beyond the unavoidable uncertainty inherent in the data itself, how much extra information cost is caused by using an incorrect distribution ?
Based on this motivation, the Kullback–Leibler divergence (KL divergence) is defined as the difference between cross-entropy and entropy:

Thus, KL divergence measures the average extra amount of information required when the true distribution is but the data are described using , relative to using the correct distribution . Because it quantifies the additional cost incurred relative to a correct description, KL divergence is also referred to as relative entropy in information theory.
It is important to note that although KL divergence is often used to measure the difference between two distributions, it is not a distance. In general,  , and it does not satisfy symmetry or the triangle inequality. Nevertheless, from the perspective of information theory and probabilistic modeling, it remains the most natural and operationally meaningful measure of distributional mismatch.
, and it does not satisfy symmetry or the triangle inequality. Nevertheless, from the perspective of information theory and probabilistic modeling, it remains the most natural and operationally meaningful measure of distributional mismatch.
Let us once again return to David’s exam example. The homeroom teacher uses the true distribution to predict David’s exam outcome, while the teacher from the neighboring class uses the incorrect model distribution . As computed earlier:

Therefore, the difference in average information cost between these two description strategies is:

This indicates that because the neighboring-class teacher uses an incorrect probability distribution to predict David’s exam outcome, they incur an additional average information cost of 0.84 per prediction. This value represents the degree of information inefficiency of the model distribution relative to the true distribution .
Maximum Likelihood Estimation (MLE)
Consider a set of independent and identically distributed (i.i.d.) observations  . Given a model distribution
. Given a model distribution  , the likelihood of the entire dataset under the model is defined as:
, the likelihood of the entire dataset under the model is defined as:

Here, i.i.d. means that each observation is independent of the others (independent) and that all observations are randomly drawn from the same probability distribution (identically distributed).
The goal of Maximum Likelihood Estimation (MLE) is to choose a set of parameters  such that the model assigns the highest probability to the observed data:
such that the model assigns the highest probability to the observed data:

Because the product form is inconvenient for numerical computation and optimization, in practice we usually take the logarithm of the likelihood, yielding the log-likelihood:

Therefore, MLE can equivalently be written as:

Multiplying the above maximization problem by 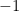 converts it into an equivalent minimization problem:
converts it into an equivalent minimization problem:

Here,  is precisely the self-information of the event under the model distribution . Therefore, the meaning of MLE can be restated as choosing model parameters such that the total self-information assigned by the model to the observed data is minimized.
is precisely the self-information of the event under the model distribution . Therefore, the meaning of MLE can be restated as choosing model parameters such that the total self-information assigned by the model to the observed data is minimized.
In other words, MLE is not merely a technique for probability maximization; in an information-theoretic sense, it is an attempt to describe the data as efficiently as possible using the model distribution.
However, the log-likelihood above still reflects only a single finite sampling outcome. Ideally, what we truly care about is the average information cost that the model incurs under the true data-generating distribution . That is, the following expectation:
![\mathbb{E}_{x \sim p}[-\log q\theta(x)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%7D%5B-%5Clog+q%5Ctheta%28x%29%5D+&bg=ffffff&fg=000&s=1&c=20201002)
Since the true distribution is unknown, this expectation cannot be computed directly. Given that we can only observe a finite dataset, the only feasible approach is to approximate the true distribution using the empirical distribution induced by the samples:

According to the law of large numbers, when the sample size  is sufficiently large and the data are i.i.d., for any integrable function
is sufficiently large and the data are i.i.d., for any integrable function  , the expectation computed under the empirical distribution converges to the expectation under the true distribution :
, the expectation computed under the empirical distribution converges to the expectation under the true distribution :
![\displaystyle \mathbb{E}_{x \sim \hat{p}_n}[f(x)] = \frac{1}{n} \sum_{i=1}^n f(x_i) \longrightarrow \mathbb{E}_{x \sim p}[f(x)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D_%7Bx+%5Csim+%5Chat%7Bp%7D_n%7D%5Bf%28x%29%5D+%3D+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5En+f%28x_i%29+%5Clongrightarrow+%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%7D%5Bf%28x%29%5D+&bg=ffffff&fg=000&s=1&c=20201002)
By taking  , we obtain:
, we obtain:
![\displaystyle \frac{1}{n} \sum_{i=1}^n -\log q_\theta(x_i) \approx \mathbb{E}_{x \sim p}\big[-\log q_\theta(x)\big] = H(p, q_\theta)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5En+-%5Clog+q_%5Ctheta%28x_i%29+%5Capprox+%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%7D%5Cbig%5B-%5Clog+q_%5Ctheta%28x%29%5Cbig%5D+%3D+H%28p%2C+q_%5Ctheta%29+&bg=ffffff&fg=000&s=1&c=20201002)
That is, the empirical average of the log-likelihood is precisely an approximation of the cross-entropy between the true distribution and the model distribution .
Therefore, maximizing the log-likelihood is equivalent to minimizing the cross-entropy:

Recalling the earlier relationship:

where is determined solely by the true data-generating distribution and is independent of the model parameters . Hence, when optimizing with respect to , we have:

This leads to an important conclusion: MLE is, in essence, equivalent to minimizing the KL divergence between the model distribution and the true distribution . From an information-theoretic perspective, MLE can be understood as choosing a model distribution that minimizes the average information cost required to describe samples generated by the true data-generating mechanism.
This also explains why, in modern machine learning, maximizing likelihood, minimizing cross-entropy, and minimizing KL divergence repeatedly appear in different forms. They all describe the same objective, viewed from different perspectives.
Conclusion
Through this sequence of derivations, we can see that entropy characterizes the unavoidable uncertainty inherent in the data itself, while cross-entropy and KL divergence quantify the additional information cost introduced by model choice. MLE is not merely a formal procedure for maximizing probability; in an information-theoretic sense, it represents an attempt to describe the data-generating mechanism as efficiently as possible using a model distribution. From this perspective, minimizing cross-entropy and minimizing KL divergence are simply different expressions of the same objective: approximating the true distribution. This also explains why these information-theoretic quantities repeatedly appear in loss functions and training objectives in modern machine learning. Understanding this theoretical thread helps us not only know how to apply models, but also why such practices are fundamentally well justified.









