
In many machine learning and decision-making systems, what we encounter is not a directly measurable quality score, but rather a large number of preference judgments in the form of pairwise comparisons, that is deciding which of two options is better. Although such pairwise comparison data is simple in form, it implicitly contains rich structural information. Starting from a probabilistic semantics perspective, this article will gradually explain how the Bradley–Terry model can transform these preference comparisons into a learnable representation of latent utilities.
Table of Contents
Problem
In many real-world scenarios, when comparing two options, we are often unable to directly assign each option a meaningful absolute score. However, it is relatively easy to answer a simpler question, that is between the two options, which one is better? This type of problem is known as a pairwise comparison problem. Common examples include:
- Between two options, which one does the user prefer?
- When two players compete, who is more likely to win?
- In RLHF or preference learning, which response will a human annotator choose between two model-generated outputs?
A shared characteristic of such data is that we only observe whether A beats B, rather than an absolute quality rating for each individual option.
Our goal is to infer, from a large collection of comparison outcomes A vs. B, the latent utility parameters associated with each item, and then answer the question: Given any two items  , what is the probability that
, what is the probability that  is preferred over
is preferred over  ? Equivalently, what is the probability that beats ?
? Equivalently, what is the probability that beats ?
To answer this question, we first formalize the setting.
Assume there are  items in total. For each item , we assign a real-valued latent utility parameter
items in total. For each item , we assign a real-valued latent utility parameter  . This parameter represents the intrinsic utility level of item under preference comparisons. However, in practice, we cannot directly observe
. This parameter represents the intrinsic utility level of item under preference comparisons. However, in practice, we cannot directly observe 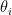 ; we only observe the outcomes of pairwise comparisons. Therefore, is an unobserved latent variable.
; we only observe the outcomes of pairwise comparisons. Therefore, is an unobserved latent variable.
Next, we would like to construct a probabilistic model that describes, given the latent utility parameters  , the probability that item beats item :
, the probability that item beats item :
![P( i \succ j \mid \theta_i, \theta_j) \in [0, 1]](https://s0.wp.com/latex.php?latex=P%28+i+%5Csucc+j+%5Cmid+%5Ctheta_i%2C+%5Ctheta_j%29+%5Cin+%5B0%2C+1%5D+&bg=ffffff&fg=000&s=1&c=20201002)
This probabilistic model should satisfy several intuitive and reasonable properties:
- If
 , then ; moreover, the larger the gap between , the closer is to 1.
, then ; moreover, the larger the gap between , the closer is to 1. - If , then , meaning that the two items are equally preferred.
- If , then ; moreover, the larger the gap, the closer is to 0.
- For any pair , the comparison outcome must be mutually exclusive and collectively exhaustive, thus satisfying .
 , then
, then  ; moreover, the larger the gap between
; moreover, the larger the gap between  , the closer
, the closer  is to 1.
is to 1. , then
, then  ; moreover, the larger the gap, the closer
; moreover, the larger the gap, the closer  .
.Together, these conditions characterize the fundamental behavior we expect from a pairwise comparison model, and they provide a clear and consistent theoretical starting point for introducing the concrete form of the Bradley–Terry model.
Odds
In probability-based comparisons, directly using the difference in probabilities can often be semantically misleading. For example, consider the following two probability changes,  and
and  。Although both have the same numerical difference of
。Although both have the same numerical difference of 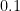 , the meaning they convey is not the same. The former corresponds to a significant change under moderate uncertainty, whereas the latter is already close to a near-certain outcome.
, the meaning they convey is not the same. The former corresponds to a significant change under moderate uncertainty, whereas the latter is already close to a near-certain outcome.
This illustrates that, when comparing the likelihood of two events, using probability differences as a measure is not always appropriate. In many situations, a more intuitive and semantically consistent question is: how many times more likely is one event than the other?
Motivated by this, we introduce the concept of odds.
For the event  , its odds is defined as:
, its odds is defined as:

Semantically, this asks: how many times more likely is choosing compared to choosing ?
Odds is a ratio, rather than a difference. Therefore, when describing the relative strength of preference, it can more faithfully reflect the relative relationship between probabilities, without being distorted by the absolute scale of the probabilities.
Furthermore, by taking the logarithm of odds, we obtain the log-odds:

An important property of log-odds is that it maps a probability originally constrained to the interval 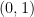 onto the entire real line
onto the entire real line 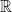 , allowing relative advantage to be expressed additively. This makes log-odds a particularly natural and convenient representation when constructing pairwise comparison models in later sections.
, allowing relative advantage to be expressed additively. This makes log-odds a particularly natural and convenient representation when constructing pairwise comparison models in later sections.
Bradley-Terry Model
The Bradley–Terry model was proposed in 1952 by Ralph A. Bradley and Milton E. Terry. It is a classic probabilistic model designed to handle pairwise comparison data.
At its core, the Bradley–Terry model is a log-odds difference model. For each item , the model assigns a real-valued latent utility parameter . It is important to emphasize that is not a probability; rather, it represents the item’s relative utility strength on the log scale in preference comparisons.
The key assumption of the model is that the log-odds of the event equals the difference between the corresponding latent utilities:

This assumption directly links the log-odds introduced in the previous section to the latent utility parameters , allowing relative preference strength to be expressed in a linear form.
Next, we can derive the corresponding probability form from the log-odds expression. From the equation above, we obtain:

Rearranging further yields:

where  denotes the sigmoid function. This shows that the Bradley–Terry model can be viewed as a logistic model that takes the latent utility difference as its input.
denotes the sigmoid function. This shows that the Bradley–Terry model can be viewed as a logistic model that takes the latent utility difference as its input.
Intuitively, if  , then under long-run repeated comparisons, the odds of choosing is three times the odds of choosing . When
, then under long-run repeated comparisons, the odds of choosing is three times the odds of choosing . When  , the model naturally reduces to the symmetric case
, the model naturally reduces to the symmetric case  .
.
Aligning with Maximum Likelihood Estimation (MLE)
In practice, we do not know the true probability distribution  underlying the pairwise comparison data. What we can obtain is only a finite number of observed samples, for example, when comparing
underlying the pairwise comparison data. What we can obtain is only a finite number of observed samples, for example, when comparing 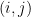 , we observe a binary label indicating whether the outcome is or the opposite.
, we observe a binary label indicating whether the outcome is or the opposite.
Under this setting, the Bradley–Terry model provides a parameterized probabilistic model  , which is used to describe the probability of observing any comparison result. However, the latent utility parameters in the model,
, which is used to describe the probability of observing any comparison result. However, the latent utility parameters in the model,  , are still unknown and must be estimated from data.
, are still unknown and must be estimated from data.
If we assume that these pairwise comparison samples are drawn independently and identically distributed (i.i.d.) from some fixed but unknown true distribution, then a natural strategy is to choose parameters  that maximize the probability of observing the dataset under the model. This is exactly Maximum Likelihood Estimation (MLE). If the reader is not familiar with MLE, the following article may be a useful reference:
that maximize the probability of observing the dataset under the model. This is exactly Maximum Likelihood Estimation (MLE). If the reader is not familiar with MLE, the following article may be a useful reference:

Concretely, suppose the dataset consists of pairwise comparison samples. Each sample can be represented as  , where
, where  indicates whether, in the
indicates whether, in the  -th comparison, item
-th comparison, item  is chosen over item
is chosen over item  . Under the Bradley–Terry model assumption, the overall negative log-likelihood can be written as:
. Under the Bradley–Terry model assumption, the overall negative log-likelihood can be written as:

This objective function is, in form, equivalent to minimizing the cross-entropy between the model distribution  and the true data distribution. Therefore, MLE can be viewed as, within a specified model family, finding an approximate distribution
and the true data distribution. Therefore, MLE can be viewed as, within a specified model family, finding an approximate distribution  that best matches the true data-generating mechanism.
that best matches the true data-generating mechanism.
Combining this with the sigmoid form derived in the previous section for the Bradley–Terry model, the learning task is ultimately reduced to a standard differentiable optimization problem, enabling us to efficiently estimate each item’s latent utility parameter using gradient-based methods.
Example 1
To concretely illustrate how the Bradley–Terry model works in practice when combined with MLE, we consider an extremely simple pairwise comparison example.
Suppose we have only three items  , and we collect the following pairwise comparison results (which can be viewed as coming from user preferences or human labeling):
, and we collect the following pairwise comparison results (which can be viewed as coming from user preferences or human labeling):
- : observed 8 times.
- : observed 2 times.
- : observed 9 times.
- : observed 1 time.
- : observed 6 times.
- : observed 4 times.
 : observed 8 times.
: observed 8 times. : observed 2 times.
: observed 2 times. : observed 9 times.
: observed 9 times. : observed 1 time.
: observed 1 time. : observed 6 times.
: observed 6 times. : observed 4 times.
: observed 4 times.These data only tell us who tends to beat whom more often, and do not provide any absolute quality score for each item.
In the Bradley–Terry model, we assign each item a latent utility parameter  , and assume that in any single comparison, the probability of observing is:
, and assume that in any single comparison, the probability of observing is:

The role of MLE is then to adjust these latent utility parameters  so that the win probabilities predicted by the model match the observed empirical comparison frequencies as closely as possible.
so that the win probabilities predicted by the model match the observed empirical comparison frequencies as closely as possible.
Take  and
and  as an example. The data show that out of 10 comparisons, the proportion of times beats is approximately 0.8. Therefore, the model will tend to adjust the parameters such that:
as an example. The data show that out of 10 comparisons, the proportion of times beats is approximately 0.8. Therefore, the model will tend to adjust the parameters such that:

This implies that  must be positive, and its magnitude must be large enough for the sigmoid output to be close to 0.8.
must be positive, and its magnitude must be large enough for the sigmoid output to be close to 0.8.
Similarly, since almost always beats  , the difference
, the difference  will be pushed to be even larger. In contrast, the comparison results between and indicate that the gap between them is smaller, and therefore the corresponding utility difference will be relatively closer as well.
will be pushed to be even larger. In contrast, the comparison results between and indicate that the gap between them is smaller, and therefore the corresponding utility difference will be relatively closer as well.
Under the joint constraints imposed by the full dataset, MLE considers all pairwise comparison samples simultaneously and searches for a set of parameters  that maximizes the joint likelihood of all observed outcomes. The resulting latent utility parameters are not determined by any single comparison; instead, they reflect a global and consistent preference ordering and strength structure induced by all pairwise information.
that maximizes the joint likelihood of all observed outcomes. The resulting latent utility parameters are not determined by any single comparison; instead, they reflect a global and consistent preference ordering and strength structure induced by all pairwise information.
It is worth noting that the Bradley–Terry model depends only on differences  . Therefore, adding the same constant to all does not affect the model’s predicted probabilities. This implies that the model suffers from parameter non-identifiability. In practice, this degree of freedom is typically removed by fixing one parameter to a constant value or by introducing appropriate regularization constraints.
. Therefore, adding the same constant to all does not affect the model’s predicted probabilities. This implies that the model suffers from parameter non-identifiability. In practice, this degree of freedom is typically removed by fixing one parameter to a constant value or by introducing appropriate regularization constraints.
This example demonstrates that the Bradley–Terry model provides a mechanism for recovering a global and consistent latent utility representation from local pairwise comparison outcomes. MLE, in turn, is the key step that operationalizes this mechanism in a data-driven manner.
Example 2
In the RLHF (Reinforcement Learning from Human Feedback) pipeline, human labelers do not assign absolute scores to model responses. Instead, they perform pairwise comparisons. Given the same prompt, the model generates two responses, and the labeler only needs to answer which one is better.
Consider the following scenario. For a given prompt, the language model generates three responses , and we collect preference data from human labelers:
- In the comparison between and , labelers mostly choose .
- In the comparison between and , labelers almost always choose .
- In the comparison between and , labelers slightly prefer .
These data contain only preference judgments about which response is better, and do not include any form of absolute quality rating.
Under the Bradley–Terry model, we assign each response a latent utility parameter , and assume that when humans compare two responses , the probability of choosing is:
In this context, can be interpreted as the implicit utility strength under human preference. It is not directly observable, and can only be inferred indirectly from pairwise comparison outcomes.
Next, MLE is responsible for adjusting these latent utility parameters based on the observed labels. For example, if in comparisons between and , labelers frequently choose , then MLE will push the parameters such that:

Similarly, if almost always beats , then will be pushed to be larger. Meanwhile, the comparison results between and suggest that the gap between them is smaller, and thus the corresponding difference in latent utility will be relatively closer. By considering all comparison samples jointly, MLE ultimately learns a set of latent utility parameters such that the model’s predictions over all pairwise preferences best match the preference distribution implied by human labels.
In RLHF implementations, this step corresponds to training the reward model.
The Bradley–Terry model provides a structural assumption that maps latent utility differences to preference probabilities, while MLE enables this assumption to be estimated from human comparison data, thereby learning a differentiable and generalizable reward representation.
Therefore, from this perspective, the reward model in RLHF is not learning a scoring function from scratch. Instead, it is grounded in a clear probabilistic model: human preferences are treated as random variables, and the Bradley–Terry model is one such hypothesis for describing this stochastic preference behavior.
Conclusion
Starting from the pairwise comparison problem, we first introduced odds and log-odds as a natural language for describing relative preference strength, and explained why this representation is more semantically consistent than directly comparing probability differences. Building on this foundation, the Bradley–Terry model adopts the simplest structural assumption over log-odds, modeling preference behavior as a function of latent score differences. Through MLE, the model can learn a consistent latent utility representation from real pairwise comparison data. In the context of RLHF and preference learning, the Bradley–Terry model not only provides a theoretically clear probabilistic interpretation, but also establishes a solid and implementable foundation for reward modeling.









