
Bi-directional recurrent neural betworks (BRNNs) are an extension of standard RNNs specifically designed to process sequential data in both forward and backward directions. Compared to traditional RNNs, BRNN architectures maintain more comprehensive context information, enabling them to capture useful dependencies across entire sequences for improved predictions in various natural language processing and speech recognition tasks.
The complete code for this chapter can be found in .
Table of Contents
BRNN
A traditional RNN only looks at the past, meaning it processes information in one direction. This one-directional flow can sometimes limit the model’s ability to capture important context from the future part of a sequence in real-world tasks. Bi-directional recurrent neural networks (BRNNs) solve this issue by processing the sequence in both forward and backward directions. In doing so, a BRNN is capable of leveraging context from the entire input sequence to make more accurate predictions.
The following figure shows the architecture of BRNN. BRNN consists of two independent RNNs:
- Forward RNN: Processes data sequentially from
 to .
to . - Backward RNN: Processes data sequentially from to .
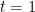 to
to  .
.At each time step, the final hidden state is a combination of the forward and backward hidden states. Finally, this combined hidden state outputs the predicted value through the output layer.

As can be seen, the computation time and memory requirements of BRNN are twice as high as those of unidirectional RNN. Next, we introduce a bidirectional vanilla RNN. As the name suggests, this BRNN is composed of two vanilla RNNs. If you are not familiar with RNN or vanilla RNN, please refer to the following article first.

Forward Propagation
The following figure shows BRNN forward propagation. This BRNN contains two vanilla RNNs, one is the forward direction RNN and the other is the backward direction RNN. The hidden states of these two RNNs are stacked vertically to become the hidden state of the cell.

The formula in BRNN cell is as follows:

The dimensions of the BRNN input  and true labels
and true labels  are as follows:
are as follows:

In a BRNN cell, the dimensions of each variable are as follows:
 |  |  |  |  |
 |  |  |  |  |
 | |  |  |  |
| | | | |
 |  |  |  | |
 |  |  |  |
The following is the implementation of forward propagation of BRNN.
class BRNN:
def cell_forward_forward(self, xt, aft_prev, parameters):
"""
Implement a single forward step for the BRNN-cell forward direction.
Parameters
----------
xt: (ndarray (n_x, m)) - input at timestep "t"
aft_prev: (ndarray (n_a, m)) - hidden state at timestep "t-1" in the forward direction
parameters: (dict) - the parameters
"Wfx": (ndarray (n_a, n_x)) - weights for the forward input
"Wfa": (ndarray (n_a, n_a)) - weights for the forward hidden state
"bfa": (ndarray (n_a, 1)) - bias for the forward hidden state
Returns
-------
aft: (ndarray (n_a, m)) - hidden state at timestep "t" in the forward direction
zfxt: (ndarray (n_a, m)) - logit at timestep "t" in the forward direction
"""
Wfx, Wfa, bfa = parameters["Wfx"], parameters["Wfa"], parameters["bfa"]
zfxt = Wfx @ xt + Wfa @ aft_prev + bfa
aft = np.tanh(zfxt)
return aft, zfxt
def cell_forward_backward(self, xt, abt_next, parameters):
"""
Implement a single forward step for the BRNN-cell backward direction.
Parameters
----------
xt: (ndarray (n_x, m)) - input at timestep "t"
abt_next: (ndarray (n_a, m)) - hidden state at timestep "t+1" in the backward direction
parameters: (dict) - the parameters
"Wbx": (ndarray (n_a, n_x)) - weights for the backward input
"Wba": (ndarray (n_a, n_a)) - weights for the backward hidden state
"bba": (ndarray (n_a, 1)) - bias for the backward hidden state
Returns
-------
abt: (ndarray (n_a, m)) - hidden state at timestep "t" in the backward direction
zbxt: (ndarray (n_a, m)) - logit at timestep "t" in the backward direction
"""
Wbx, Wba, bba = parameters["Wbx"], parameters["Wba"], parameters["bba"]
zbxt = Wbx @ xt + Wba @ abt_next + bba
abt = np.tanh(zbxt)
return abt, zbxt
def forward(self, X, af0, abl, parameters):
"""
Implement the forward propagation for the BRNN.
Parameters
----------
X: (ndarray (n_x, m, T_x)) - input data
af0: (ndarray (n_a, m)) - initial hidden state for the forward direction
abl: (ndarray (n_a, m)) - initial hidden state for the backward direction
parameters: (dict) - the parameters
"Wfx": (ndarray (n_a, n_x)) - weights for the forward input
"Wfa": (ndarray (n_a, n_a)) - weights for the forward hidden state
"Wbx": (ndarray (n_a, n_x)) - weights for the backward input
"Wba": (ndarray (n_a, n_a)) - weights for the backward hidden state
"Wy": (ndarray (n_y, n_a * 2)) - weights for the output
"bfa": (ndarray (n_a, 1)) - bias for the forward hidden state
"bba": (ndarray (n_a, 1)) - bias for the backward hidden state
"by": (ndarray (n_y, 1)) - bias for the output
Returns
-------
AF: (ndarray (n_a, m, T_x)) - hidden states for the forward direction
AB: (ndarray (n_a, m, T_x)) - hidden states for the backward direction
Y_hat: (ndarray (n_y, m, T_x)) - predictions for each timestep
caches: (list) - caches for each timestep
"""
n_x, m, T_x = X.shape
n_y, n_a_2 = parameters["Wy"].shape
n_a = n_a_2 // 2
fcaches = []
AF = np.zeros((n_a, m, T_x))
aft_prev = af0
for t in range(T_x):
xt = X[:, :, t]
aft, zfxt = self.cell_forward_forward(xt, aft_prev, parameters)
AF[:, :, t] = aft
fcaches.append((aft, aft_prev, xt, zfxt))
aft_prev = aft
bcaches = []
AB = np.zeros((n_a, m, T_x))
abt_next = abl
for t in reversed(range(T_x)):
xt = X[:, :, t]
abt, zbxt = self.cell_forward_backward(xt, abt_next, parameters)
AB[:, :, t] = abt
bcaches.insert(0, (abt, abt_next, xt, zbxt))
abt_next = abt
caches = []
Wy, by = parameters["Wy"], parameters["by"]
Y_hat = np.zeros((n_y, m, T_x))
for t in range(T_x):
aft, aft_prev, xt, zfxt = fcaches[t]
abt, abt_next, xt, zbxt = bcaches[t]
at = np.concatenate((aft, abt), axis=0)
zyt = Wy @ at + by
y_hat_t = softmax(zyt)
Y_hat[:, :, t] = y_hat_t
caches.append((fcaches[t], bcaches[t], (at, zyt, y_hat_t)))
return AF, AB, Y_hat, cachesLoss Function
Since our BRNN is composed of two vanilla RNNs, we also use softmax to output  , so we use cross-entropy loss as its loss function. For the formula and implementation of cross-entropy loss, please refer to the following article.
, so we use cross-entropy loss as its loss function. For the formula and implementation of cross-entropy loss, please refer to the following article.
Backward Propagation
The backpropagation of BRNN is a bit more complicated. We need to split  calculated in the output layer into two, one for the forward direction RNN and the other for the backward direction RNN. The backpropagation of the forward direction RNN is calculated from the last time step forward. However, the backpropagation of the backward direction RNN is calculated from the first time step backwards.
calculated in the output layer into two, one for the forward direction RNN and the other for the backward direction RNN. The backpropagation of the forward direction RNN is calculated from the last time step forward. However, the backpropagation of the backward direction RNN is calculated from the first time step backwards.

The following calculates the partial derivatives in the output layer.

The following calculates the partial derivatives of all parameters in the forward direction RNN.

The following calculates the partial derivatives of all parameters in the backward direction RNN.

The above is how to find all partial derivatives at each time step. Finally, we have to sum up all the partial derivatives we have taken.

The following is the implementation of backward propagation of BRNN.
class BRNN:
def cell_backward_forward(self, daft, fcache, parameters):
"""
Implement a single backward step for the BRNN-cell forward direction.
Parameters
----------
daft: (ndarray (n_a, m)) - gradient of the hidden state at timestep "t" in the forward direction
fcache: (tuple) - cache from the forward direction
parameters: (dict) - the parameters
"Wfa": (ndarray (n_a, n_a)) - weights for the forward hidden state
Returns
-------
gradients: (dict) - the gradients
"dWfx": (ndarray (n_a, n_x)) - gradients for the forward input
"dWfa": (ndarray (n_a, n_a)) - gradients for the forward hidden state
"dbfa": (ndarray (n_a, 1)) - gradients for the forward hidden state
"daft": (ndarray (n_a, m)) - gradient of the hidden state at timestep "t-1" in the forward direction
"""
aft, aft_prev, xt, zfxt = fcache
dfz = (1 - aft ** 2) * daft
gradients = {
"dbfa": np.sum(dfz, axis=1, keepdims=True),
"dWfx": dfz @ xt.T,
"dWfa": dfz @ aft_prev.T,
"daft": parameters["Wfa"].T @ dfz,
}
return gradients
def cell_backward_backward(self, dabt, bcache, parameters):
"""
Implement a single backward step for the BRNN-cell backward direction.
Parameters
----------
dabt: (ndarray (n_a, m)) - gradient of the hidden state at timestep "t" in the backward direction
bcache: (tuple) - cache from the backward direction
parameters: (dict) - the parameters
"Wba": (ndarray (n_a, n_a)) - weights for the backward hidden state
Returns
-------
gradients: (dict) - the gradients
"dWbx": (ndarray (n_a, n_x)) - gradients for the backward input
"dWba": (ndarray (n_a, n_a)) - gradients for the backward hidden state
"dbba": (ndarray (n_a, 1)) - gradients for the backward hidden state
"dabt": (ndarray (n_a, m)) - gradient of the hidden state at timestep "t+1" in the backward direction
"""
abt, abt_next, xt, zbxt = bcache
dbz = (1 - abt ** 2) * dabt
gradients = {
"dbba": np.sum(dbz, axis=1, keepdims=True),
"dWbx": dbz @ xt.T,
"dWba": dbz @ abt_next.T,
"dabt": parameters["Wba"].T @ dbz,
}
return gradients
def backward(self, X, Y, parameters, Y_hat, caches):
"""
Implement the backward propagation for the BRNN.
Parameters
----------
X: (ndarray (n_x, m, T_x)) - input data
Y: (ndarray (n_y, m, T_x)) - true labels
parameters: (dict) - the parameters
"Wfx": (ndarray (n_a, n_x)) - weights for the forward input
"Wfa": (ndarray (n_a, n_a)) - weights for the forward hidden state
"Wbx": (ndarray (n_a, n_x)) - weights for the backward input
"Wba": (ndarray (n_a, n_a)) - weights for the backward hidden state
"Wy": (ndarray (n_y, n_a * 2)) - weights for the output
"bfa": (ndarray (n_a, 1)) - bias for the forward hidden state
"bba": (ndarray (n_a, 1)) - bias for the backward hidden state
"by": (ndarray (n_y, 1)) - bias for the output
"""
n_x, m, T_x = X.shape
n_a, n_x = parameters["Wfx"].shape
Wfx, Wfa, bfa = parameters["Wfx"], parameters["Wfa"], parameters["bfa"]
Wbx, Wba, bba = parameters["Wbx"], parameters["Wba"], parameters["bba"]
Wy, by = parameters["Wy"], parameters["by"]
gradients = {
"dWfx": np.zeros_like(Wfx), "dWfa": np.zeros_like(Wfa), "dbfa": np.zeros_like(bfa),
"dWbx": np.zeros_like(Wbx), "dWba": np.zeros_like(Wba), "dbba": np.zeros_like(bba),
"dWy": np.zeros_like(Wy), "dby": np.zeros_like(by),
}
daf = np.zeros((n_a, m, T_x))
dab = np.zeros((n_a, m, T_x))
for t in range(T_x):
_, _, (at, zyt, y_hat_t) = caches[t]
dy = Y_hat[:, :, t] - Y[:, :, t]
dWy = dy @ at.T
dby = np.sum(dy, axis=1, keepdims=True)
gradients["dWy"] += dWy
gradients["dby"] += dby
dat = Wy.T @ dy
daf[:, :, t] = dat[:n_a, :]
dab[:, :, t] = dat[n_a:, :]
daft = np.zeros((n_a, m))
for t in reversed(range(T_x)):
fcaches, _, _ = caches[t]
grads = self.cell_backward_forward(daf[:, :, t] + daft, fcaches, parameters)
gradients["dWfx"] += grads["dWfx"]
gradients["dWfa"] += grads["dWfa"]
gradients["dbfa"] += grads["dbfa"]
daft = grads["daft"]
dabt = np.zeros_like(daft)
for t in range(T_x):
_, bcache, _ = caches[t]
grads = self.cell_backward_backward(dab[:, :, t] + dabt, bcache, parameters)
gradients["dWbx"] += grads["dWbx"]
gradients["dWba"] += grads["dWba"]
gradients["dbba"] += grads["dbba"]
dabt = grads["dabt"]
return gradientsPutting All Together
The following code implements a complete training process. First, we pass the training data into forward propagation, calculate the loss, and then pass it into backward propagation to finally get the gradients. To prevent exploding gradients from happening, we will clip the gradients. Then, use it to update the parameters. This is a complete training.
class BRNN:
def optimize(self, X, Y, af_prev, ab_last, parameters, learning_rate, clip_value):
"""
Implement the forward and backward propagation for the BRNN.
Parameters
----------
X: (ndarray (n_x, m, T_x)) - input data
Y: (ndarray (n_y, m, T_x)) - true labels
af_prev: (ndarray (n_a, m)) - initial hidden state for the forward direction
ab_last: (ndarray (n_a, m)) - initial hidden state for the backward direction
parameters: (dict) - the parameters
"Wfx": (ndarray (n_a, n_x)) - weights for the forward input
"Wfa": (ndarray (n_a, n_a)) - weights for the forward hidden state
"Wbx": (ndarray (n_a, n_x)) - weights for the backward input
"Wba": (ndarray (n_a, n_a)) - weights for the backward hidden state
"Wy": (ndarray (n_y, n_a * 2)) - weights for the output
"bfa": (ndarray (n_a, 1)) - bias for the forward hidden state
"bba": (ndarray (n_a, 1)) - bias for the backward hidden state
"by": (ndarray (n_y, 1)) - bias for the output
learning_rate: (float) - learning rate
clip_value: (float) - the maximum value to clip the gradients
Returns
-------
af: (ndarray (n_a, m)) - hidden state at the last timestep for the forward direction
ab: (ndarray (n_a, m)) - hidden state at the first timestep for the backward direction
loss: (float) - the cross-entropy loss
"""
AF, AB, Y_hat, caches = self.forward(X, af_prev, ab_last, parameters)
loss = self.compute_loss(Y_hat, Y)
gradients = self.backward(X, Y, parameters, Y_hat, caches)
gradients = self.clip(gradients, clip_value)
self.update_parameters(parameters, gradients, learning_rate)
af = AF[:, :, -1]
ab = AB[:, :, 0]
return af, ab, lossExample
The example below is that the input to the BRNN model is a word, and then predicts whether the word is palindrome. Since the outcome is either yes or no palindrome, we only need the last prediction and ignore the rest of the output.
Below is the training function of the BRNN model.
class BRNN:
def preprocess_input(self, input, char_to_idx):
"""
Preprocess the input text data.
Parameters
----------
input: (tuple) - tuple containing the input text data and the true label
char_to_idx: (dict) - dictionary mapping characters to indices
Returns
-------
X: (ndarray (n_x, 1, T_x)) - input data for each time step
Y: (ndarray (n_y, 1, T_x)) - true labels for each time step
"""
word, label = input
n_x = len(char_to_idx)
T_x = len(word)
X = np.zeros((n_x, 1, T_x))
for t, ch in enumerate(word):
X[char_to_idx[ch], 0, t] = 1
Y = np.zeros((2, 1, T_x))
if label == 1:
Y[0, 0, :] = 1.0
Y[1, 0, :] = 0.0
else:
Y[0, 0, :] = 0.0
Y[1, 0, :] = 1.0
return X, Y
def train(self, dataset, char_to_idx, num_iterations=100, learning_rate=0.01, clip_value=5):
"""
Train the RNN model on the given text.
Parameters
----------
dataset: (list) - list of tuples containing the input text data and the true labels
char_to_idx: (dict) - dictionary mapping characters to indices
num_iterations: (int) - number of iterations for the optimization loop
learning_rate: (float) - learning rate for the optimization algorithm
clip_value: (float) - maximum value for the gradients
Returns
-------
losses: (list) - cross-entropy loss at each iteration
"""
losses = []
for i in range(num_iterations):
np.random.shuffle(dataset)
total_loss = 0.0
af_prev = self.af0
ab_next = self.abl
for input in dataset:
X, Y = self.preprocess_input(input, char_to_idx)
af_prev, ab_next, loss = self.optimize(
X, Y, af_prev, ab_next, self.parameters, learning_rate, clip_value
)
total_loss += loss
avg_loss = total_loss / len(dataset)
losses.append(avg_loss)
print(f"Iteration {i}, Loss: {avg_loss}")
return lossesFinally, the following code shows how to train our model and use it to make predictions.
def get_palindrome_dataset():
palindromes = ["racecar", "madam", "kayak", "rotator", "noon", "civic"]
non_palindromes = ["hello", "abcde", "python", "world", "carrot", "banana"]
dataset = []
for palindrome in palindromes:
dataset.append((palindrome, 1))
for non_palindrome in non_palindromes:
dataset.append((non_palindrome, 0))
return dataset
if __name__ == "__main__":
dataset = get_palindrome_dataset()
chars = sorted(list(set(''.join([word for word, _ in dataset]))))
vocab_size = len(chars)
char_to_idx = {ch: i for i, ch in enumerate(chars)}
idx_to_char = {i: ch for ch, i in enumerate(chars)}
brnn = BRNN(64, vocab_size, 2)
losses = brnn.train(dataset, char_to_idx, 300, 0.01, 5.0)
correct = 0
for word, label in dataset:
X, Y = brnn.preprocess_input((word, label), char_to_idx)
_, _, Y_hat, _ = brnn.forward(X, brnn.af0, brnn.abl, brnn.parameters)
pred_probs = Y_hat[:, 0, -1]
predicted_label = 1 if (pred_probs[0] > pred_probs[1]) else 0
if predicted_label == label:
correct += 1
print(f"Accuracy: {correct / len(dataset)}")Variants
Just as there are multiple variants of standard RNNs (like LSTM and GRU), there are corresponding BRNN versions, such as bi-directional LSTM (BiLSTM) and bi-directional gated recurrent unit (BiGRU). They can capture long-term dependencies in both directions. This approach often yields superior performance in tasks requiring long-range context.
Conclusion
BRNNs provide an effective way to capture both past and future context in sequential data. Whether you’re working with text, speech, or any type of time series, BRNNs can offer significant performance benefits over standard RNN architectures. By incorporating LSTM or GRU units, you further mitigate the vanishing gradient problem and gain the ability to model long-term dependencies in both directions.
References
- Andrew Ng, Deep Learning Specialization, Coursera.









