
Attention mechanisms is a method in deep learning that lets a model focus on the most relevant parts of its input when producing each piece of its output. Unlike traditional sequence models that often struggle with longer inputs, attention allows models to dynamically focus on different parts of the input sequence when generating each part of the output sequence.
The complete code for this chapter can be found in .
Table of Contents
Attention Mechanism
Traditional neural sequence models (like simple encoder-decoders) would read an entire input sequence and then attempt to compress it all into a single vector, or thought vector. This single vector is used to produce each output token. The problem is that a single summary might lose important details about the input. If you don’t know much about sequence model, you can refer to the following article first.

Attention fixes this by allowing the model to look at different parts of the input separately each time it generates a piece of output. Instead of a single summary of the input, it uses a set of weights that say how much each part of the input should matter when predicting the next output. Attention models enable a neural network to weigh the importance of different elements in an input sequence, dynamically adjusting these weights based on context.
Two prominent types of attention mechanisms are Bahdanau Attention and Luong Attention.
Bahdanau Attention
Introduced by D. Bahdanau et al. in 2015, it is therefore called Bahdanau attention. It uses an alignment model to calculate the alignment scores between the previous hidden state of the decoder and the hidden state of each encoder, and then generates a context vector by applying these attention weights.
The figure below is a Bahdanau attention model. We use single layer of bi-directional GRU (BiGRU) in the encoder and single layer of uni-directional GRU in the decoder. In the paper, Bahdanau uses a model very similar to GRU, so we will use GRU directly here. Of course, the encoder and decoder can also use other RNN models, or multi-layers RNN. When the encoder uses a bi-directional RNN, we need to stack its forward and backward hidden states vertically.

After the encoder outputs all hidden states, we use the following formula to calculate the context vector. For the context vector 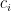 , first use the alignment model
, first use the alignment model  to calculate the energy
to calculate the energy  of each encoder hidden state
of each encoder hidden state  at the time step
at the time step  . The alignment model scores how well the input around position
. The alignment model scores how well the input around position  and the output at the position match. This is the alignment score. Then, use
and the output at the position match. This is the alignment score. Then, use softmax to calculate the weight  of each encoder hidden state . This weight can determine the importance of each encoder hidden state to the context vector , so multiplying them and then adding them together is the final context vector
of each encoder hidden state . This weight can determine the importance of each encoder hidden state to the context vector , so multiplying them and then adding them together is the final context vector

Finally, the calculated context vector , the previous output 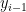 , and a decoder hidden state
, and a decoder hidden state  will be used as the input of the RNN of the current time step.
will be used as the input of the RNN of the current time step.

The alignment model is a feed-forward neural network, which is jointly trained with all the other components of the system. It will first take 和 and go through linear transformations and then add them together. Therefore, Bahdanau attention is also called additive attention.
Bahdanau Attention Implementation
Now let’s implement the Bahdanau attention model in the figure above. Below is the implementation of the encoder, which uses a bi-directional GRU (BiGRU). We use a fully connected layer at the end to convert the dimensions of the encoder hidden states to match the expected dimensions of the decoder.
class BahdanauAttentionEncoder(nn.Module):
def __init__(self, input_dim, embed_dim, encoder_hidden_dim, decoder_hidden_dim):
super(BahdanauAttentionEncoder, self).__init__()
self.embedding = nn.Embedding(input_dim, embed_dim)
self.gru = nn.GRU(embed_dim, encoder_hidden_dim, num_layers=1, batch_first=True, bidirectional=True)
self.fc = nn.Linear(encoder_hidden_dim * 2, decoder_hidden_dim)
def forward(self, src):
"""
Args
src: (batch_size, src_len)
Returns
all_hidden: (batch_size, src_len, encoder_hidden_dim * 2)
decoder_hidden_init: (batch_size, decoder_hidden_dim)
"""
embedded = self.embedding(src) # (batch_size, src_len, embed_dim)
# all_hidden: (batch_size, src_len, hidden_dim * 2)
# final_hidden_state: (num_layers * 2, batch_size, hidden_dim)
all_hidden, final_hidden = self.gru(embedded)
# Map to decoder's initial hidden state
final_forward_hidden = final_hidden[-2, :, :]
final_backward_hidden = final_hidden[-1, :, :]
hidden_cat = torch.cat((final_forward_hidden, final_backward_hidden), dim=1)
decoder_hidden_init = self.fc(hidden_cat) # (batch_size, decoder_hidden_dim)
return all_hidden, decoder_hidden_initThe following implements the calculation of weight 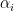 .
.
class BahdanauAttention(nn.Module):
def __init__(self, encoder_hidden_dim, decoder_hidden_dim, attention_dim):
super(BahdanauAttention, self).__init__()
self.W = nn.Linear(decoder_hidden_dim, attention_dim)
self.U = nn.Linear(encoder_hidden_dim * 2, attention_dim)
self.v = nn.Linear(attention_dim, 1, bias=False)
def forward(self, decoder_hidden, encoder_all_hidden):
"""
Args
decoder_hidden: (batch_size, decoder_hidden_dim)
encoder_all_hidden: (batch_size, src_len, encoder_hidden_dim * 2)
Returns
alpha: (batch_size, src_len)
"""
Ws = self.W(decoder_hidden).unsqueeze(1) # (batch_size, 1, decoder_hidden_dim)
Uh = self.U(encoder_all_hidden) # (batch_size, src_len, attention_dim)
energy = self.v(torch.tanh(Ws + Uh)) # (batch_size, src_len, 1)
energy = energy.squeeze(2) # (batch_size, src_len)
alpha = torch.softmax(energy, dim=1) # (batch_size, src_len)
return alphaThe following is the implementation of the decoder. It uses a uni-directional GRU. After calculating the context vector , it stacks the context vector vertically with the input of course as the input of GRU.
class BahdanauAttentionDecoder(nn.Module):
def __init__(self, output_dim, embed_dim, decoder_hidden_dim, encoder_hidden_dim, attention_dim):
super(BahdanauAttentionDecoder, self).__init__()
self.embedding = nn.Embedding(output_dim, embed_dim)
self.attention = BahdanauAttention(encoder_hidden_dim, decoder_hidden_dim, attention_dim)
self.gru = nn.GRU(
embed_dim + encoder_hidden_dim * 2, decoder_hidden_dim, num_layers=1, batch_first=True, bidirectional=False,
)
self.fc = nn.Linear(decoder_hidden_dim, output_dim)
def forward(self, input_token, decoder_hidden, encoder_all_hidden):
"""
Args
input_token: (batch_size)
decoder_hidden: (batch_size, decoder_hidden_dim)
encoder_all_hidden: (batch_size, src_len, encoder_hidden_dim * 2)
Returns
prediction: (batch_size, output_dim)
final_hidden: (batch_size, decoder_hidden_dim)
"""
input_token = input_token.unsqueeze(1) # (batch_size, 1)
embedded = self.embedding(input_token) # (batch_size, 1, embed_dim)
alpha = self.attention(decoder_hidden, encoder_all_hidden) # (batch_size, src_len)
alpha = alpha.unsqueeze(1) # (batch_size, 1, src_len)
context = torch.bmm(alpha, encoder_all_hidden) # (batch_size, 1, encoder_hidden_dim * 2)
rnn_input = torch.cat((embedded, context), dim=2) # (batch_size, 1, embed_dim + encoder_hidden_dim * 2)
decoder_hidden = decoder_hidden.unsqueeze(0) # (1, batch_size, decoder_hidden_dim)
# all_hidden: (batch_size, 1, decoder_hidden_dim)
# final_hidden: (1, batch_size, decoder_hidden_dim)
all_hidden, final_hidden = self.gru(rnn_input, decoder_hidden)
final_hidden = final_hidden.squeeze(0) # (batch_size, decoder_hidden_dim)
prediction = self.fc(all_hidden.squeeze(1)) # (batch_size, output_dim)
return prediction, final_hiddenThe following integrates the encoder, attention, and decoder.
class BahdanauAttentionModel(nn.Module):
def __init__(self, encoder, decoder):
super(BahdanauAttentionModel, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, src, tgt, teacher_forcing_ratio=0.5):
"""
Args
src: (batch_size, src_len)
tgt: (batch_size, tgt_len)
teacher_forcing_ratio: float - probability to use teacher forcing
Returns
outputs: (batch_size, tgt_len, tgt_vocab_size)
"""
batch_size, tgt_len = tgt.shape
tgt_vocab_size = self.decoder.fc.out_features
outputs = torch.zeros(batch_size, tgt_len, tgt_vocab_size)
encoder_all_hidden, decoder_hidden = self.encoder(src)
input_token = tgt[:, 0]
for t in range(1, tgt_len):
prediction, decoder_hidden = self.decoder(input_token, decoder_hidden, encoder_all_hidden)
outputs[:, t] = prediction
teacher_force = torch.rand(1).item() < teacher_forcing_ratio
input_token = tgt[:, t] if teacher_force else prediction.argmax(1)
return outputsLuong Attention
Introduced by M. Luong et al. in 2015, it is also called Luong attention. He proposed three methods for calculating alignment scores. These methods mainly simplify the calculation of alignment scores between the hidden states of the encoder and decoder through dot products. In addition, he also mentioned two types of attention, namely global attention and local attention.
The main idea of the global attention model is that when the decoder is calculating the context vector , it takes into account all the encoder hidden states, just like Bahdanau attention. Global attention has a drawback that every output word must attend to all input words. This is computationally expensive and becomes impractical when translating longer sequences. Local attention allows each output word to choose to focus on only a small part of the input word. This article will only introduce global attention.
The figure below is a Luong global attention model. We use a layer of bi-directional LSTM (BiLSTM) in the encoder and a layer of uni-directional LSTM in the decoder. Of course, the encoder and decoder can also use other RNN models, or multi-layers RNN. When the encoder uses a bi-directional RNN, we need to stack its forward and backward hidden states vertically.

The method for calculating context vector and weight is the same as it is in Bahdanau attention. However, when calculating the alignment scores, Luong attention uses the hidden state of the current decoder.

Let’s take a look at these three functions:
- Dot: It performs dot product on the hidden state
 of the current decoder and the hidden state of each encoder.
of the current decoder and the hidden state of each encoder. - General: Based on the dot function, it introduces a learnable parameter .
- Concat: Basically, this is similar to Bahdanau’s alignment model, the difference is that it uses the current decoder’s hidden state and only use multiplication.
 .
.After deriving the context vector , it and 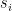 are directly used to predict the output after some operations, which is different from Bahdanau attention. Bahdanau attention uses the resulting context vector as the input of the RNN in the decoder.
are directly used to predict the output after some operations, which is different from Bahdanau attention. Bahdanau attention uses the resulting context vector as the input of the RNN in the decoder.

Among the three alignment score functions, the dot function is the simplest and most cited. Therefore, Luong attention is also called dot attention.
Luong Attention Implementation
Now let’s implement the Luong attention model in the figure above. Below is the implementation of the encoder, which uses a bi-directional LSTM (BiLSTM). We use a fully connected layer at the end to convert the dimensions of the encoder hidden states to match the expected dimensions of the decoder. This encoder is basically the same as the Bahdanau attention encoder, except that it uses a different RNN internally.
class LuongAttentionEncoder(nn.Module):
def __init__(self, input_dim, embed_dim, encoder_hidden_dim, decoder_hidden_dim):
super(LuongAttentionEncoder, self).__init__()
self.embedding = nn.Embedding(input_dim, embed_dim)
self.lstm = nn.LSTM(embed_dim, encoder_hidden_dim, num_layers=1, batch_first=True, bidirectional=True)
self.fc = nn.Linear(encoder_hidden_dim * 2, decoder_hidden_dim)
def forward(self, src):
"""
Args
src: (batch_size, src_len)
Returns
all_hidden: (batch_size, src_len, decoder_hidden_dim)
decoder_hidden_init: (batch_size, decoder_hidden_dim)
decoder_cell_init: (batch_size, decoder_hidden_dim)
"""
embedded = self.embedding(src) # (batch_size, src_len, embed_dim)
# all_hidden: (batch_size, src_len, encoder_hidden_dim * 2)
# final_hidden, final_cell: (num_layers * 2, batch_size, encoder_hidden_dim)
all_hidden, (final_hidden, final_cell) = self.lstm(embedded)
# Map to decoder's initial hidden and cell states
final_forward_hidden = final_hidden[-2, :, :]
final_backward_hidden = final_hidden[-1, :, :]
final_hidden = torch.cat((final_forward_hidden, final_backward_hidden), dim=1)
final_forward_cell = final_cell[-2, :, :]
final_backward_cell = final_cell[-1, :, :]
final_cell = torch.cat((final_forward_cell, final_backward_cell), dim=1)
decoder_hidden_init = self.fc(final_hidden) # (batch_size, decoder_hidden_dim)
decoder_cell_init = self.fc(final_cell) # (batch_size, decoder_hidden_dim)
b, s, d = all_hidden.shape
all_hidden_2d = all_hidden.view(b * s, d)
all_hidden_2d = self.fc(all_hidden_2d)
all_hidden = all_hidden_2d.view(b, s, self.fc.out_features) # (batch_size, src_len, decoder_hidden_dim)
return all_hidden, decoder_hidden_init, decoder_cell_initThe following is the implementation of the dot score function.
class LuongDotAttention(nn.Module):
def __init__(self):
super(LuongDotAttention, self).__init__()
def forward(self, decoder_hidden, encoder_all_hidden):
"""
Args
decoder_hidden: (batch_size, decoder_hidden_dim)
encoder_all_hidden: (batch_size, src_len, decoder_hidden_dim)
Returns
alpha: (batch_size, src_len)
"""
decoder_hidden = decoder_hidden.unsqueeze(1) # (batch_size, 1, decoder_hidden_dim)
scores = torch.bmm(decoder_hidden, encoder_all_hidden.transpose(1, 2)) # (batch_size, 1, src_len)
scores = scores.squeeze(1) # (batch_size, src_len)
alpha = torch.softmax(scores, dim=1) # (batch_size, src_len)
return alphaThe following is the implementation of the general score function.
class LuongGeneralAttention(nn.Module):
def __init__(self, decoder_hidden_dim):
super(LuongGeneralAttention, self).__init__()
self.W_a = nn.Linear(decoder_hidden_dim, decoder_hidden_dim, bias=False)
def forward(self, decoder_hidden, encoder_all_hidden):
"""
Args
decoder_hidden: (batch_size, decoder_hidden_dim)
encoder_all_hidden: (batch_size, src_len, decoder_hidden_dim)
Returns
alpha: (batch_size, src_len)
"""
encoder_all_hidden_transformed = self.W_a(encoder_all_hidden) # (batch_size, src_len, decoder_hidden_dim)
decoder_hidden = decoder_hidden.unsqueeze(1) # (batch_size, 1, decoder_hidden_dim)
scores = torch.bmm(decoder_hidden, encoder_all_hidden_transformed.transpose(1, 2)) # (batch_size, 1, src_len)
scores = scores.squeeze(1) # (batch_size, src_len)
alpha = torch.softmax(scores, dim=1) # (batch_size, src_len)
return alphaFollowing is the implementation of concat score function.
class LuongConcatAttention(nn.Module):
def __init__(self, decoder_hidden_dim):
super(LuongConcatAttention, self).__init__()
self.W_a = nn.Linear(decoder_hidden_dim * 2, decoder_hidden_dim, bias=False)
self.v = nn.Linear(decoder_hidden_dim, 1, bias=False)
def forward(self, decoder_hidden, encoder_all_hidden):
"""
Args
decoder_hidden: (batch_size, decoder_hidden_dim)
encoder_all_hidden: (batch_size, src_len, decoder_hidden_dim)
Returns
alpha: (batch_size, src_len)
"""
b, s, d = encoder_all_hidden.shape
decoder_hidden_expanded = decoder_hidden.unsqueeze(1).expand(-1, s, -1) # (batch_size, src_len, hidden_dim)
concat_input = torch.cat((decoder_hidden_expanded, encoder_all_hidden), dim=2) # (batch_size, src_len, hidden_dim * 2)
concat_output = torch.tanh(self.W_a(concat_input)) # (batch_size, src_len, hidden_dim)
scores = self.v(concat_output) # (batch_size, src_len, 1)
scores = scores.squeeze(2) # (batch_size, src_len)
alpha = torch.softmax(scores, dim=1) # (batch_size, src_len)
return alphaThe following is the implementation of the decoder. It uses a uni-directional LSTM. The decoder design is quite different from Bahdanau attention. It first calculates the current hidden state before calculating the context vector .
class LuongAttentionDecoder(nn.Module):
def __init__(self, attention, output_dim, embed_dim, decoder_hidden_dim):
super(LuongAttentionDecoder, self).__init__()
self.embedding = nn.Embedding(output_dim, embed_dim)
self.lstm = nn.LSTM(embed_dim, decoder_hidden_dim, num_layers=1, batch_first=True)
self.attention = attention
self.W_c = nn.Linear(decoder_hidden_dim * 2, decoder_hidden_dim)
self.W_s = nn.Linear(decoder_hidden_dim, output_dim)
def forward(self, input_token, decoder_hidden, decoder_cell, encoder_all_hidden):
"""
Args
input_token: (batch_size)
decoder_hidden: (batch_size, decoder_hidden_dim)
decoder_cell: (batch_size, decoder_hidden_dim)
encoder_all_hidden: (batch_size, src_len, decoder_hidden_dim)
Returns
prediction: (batch_size, output_dim)
final_hidden: (batch_size, hidden_dim)
final_cell: (batch_size, hidden_dim)
"""
input_token = input_token.unsqueeze(1) # (batch_size, 1)
embedded = self.embedding(input_token) # (batch_size, 1, embed_dim)
decoder_hidden = decoder_hidden.unsqueeze(0) # (1, batch_size, hidden_dim)
decoder_cell = decoder_cell.unsqueeze(0) # (1, batch_size, hidden_dim)
# decoder_all_hidden: (batch_size, 1, hidden_dim)
# final_hidden, final_cell: (1, batch_size, hidden_dim)
decoder_all_hidden, (final_hidden, final_cell) = self.lstm(embedded, (decoder_hidden, decoder_cell))
final_hidden = final_hidden.squeeze(0) # (batch_size, hidden_dim)
final_cell = final_cell.squeeze(0) # (batch_size, hidden_dim)
alpha = self.attention(final_hidden, encoder_all_hidden) # (batch_size, src_len)
alpha = alpha.unsqueeze(1) # (batch_size, 1, src_len)
context = torch.bmm(alpha, encoder_all_hidden) # (batch_size, 1, hidden_dim)
context = context.squeeze(1) # (batch_size, hidden_dim)
hidden_cat = torch.cat((context, final_hidden), dim=1) # (batch_size, hidden_dim * 2)
luong_hidden = torch.tanh(self.W_c(hidden_cat)) # (batch_size, hidden_dim)
prediction = self.W_s(luong_hidden) # (batch_size, output_dim)
return prediction, final_hidden, final_cellThe following integrates the encoder, attention, and decoder.
class LuongAttentionModel(nn.Module):
def __init__(self, encoder, decoder):
super(LuongAttentionModel, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, src, tgt, teacher_forcing_ratio=0.5):
"""
Args
src: (batch_size, src_len)
tgt: (batch_size, tgt_len)
teacher_forcing_ratio: float - probability to use teacher forcing
Returns
outputs: (batch_size, tgt_len, tgt_vocab_size)
"""
batch_size, tgt_len = tgt.shape
tgt_vocab_size = self.decoder.W_s.out_features
outputs = torch.zeros(batch_size, tgt_len, tgt_vocab_size)
encoder_all_hidden, hidden, cell = self.encoder(src)
input_token = tgt[:, 0]
for t in range(1, tgt_len):
output, hidden, cell = self.decoder(input_token, hidden, cell, encoder_all_hidden)
outputs[:, t] = output
teacher_force = torch.rand(1).item() < teacher_forcing_ratio
input_token = tgt[:, t] if teacher_force else output.argmax(1)
return outputsExample
The following code shows how to use the implementation of Bahdanau attention and Luong attention in this article. When using the Luong attention model, we can also choose the score function to use.
from bahdanau_attention import *
from luong_attention import *
SOS_TOKEN = 0
EOS_TOKEN = 1
PAD_TOKEN = 2
english_sentences = [
"hello world",
"good morning",
"i love you",
"cat",
"dog",
"go home",
]
spanish_sentences = [
"hola mundo",
"buenos dias",
"te amo",
"gato",
"perro",
"ve a casa",
]
def build_vocab(sentences):
vocab = list(set([word for sentence in sentences for word in sentence.split(" ")]))
vocab = ["<sos>", "<eos>", "<pad>"] + vocab
tkn2idx = {tkn: idx for idx, tkn in enumerate(vocab)}
idx2tkn = {idx: tkn for tkn, idx in tkn2idx.items()}
return vocab, tkn2idx, idx2tkn
def convert_sentence_to_idx(sentence, tkn2idx):
sentence_idx = [tkn2idx[tkn] for tkn in sentence.split(" ")]
sentence_idx.insert(0, SOS_TOKEN)
sentence_idx.append(EOS_TOKEN)
return sentence_idx
def pad_sentence(sentence, max_len):
return sentence + [PAD_TOKEN] * (max_len - len(sentence))
src_vocab, src_tkn2idx, src_idx2tkn = build_vocab(english_sentences)
tgt_vocab, tgt_tkn2idx, tgt_idx2tkn = build_vocab(spanish_sentences)
src_sentences = [convert_sentence_to_idx(sentence, src_tkn2idx) for sentence in english_sentences]
tgt_sentences = [convert_sentence_to_idx(sentence, tgt_tkn2idx) for sentence in spanish_sentences]
src_max_len = max([len(sentence) for sentence in src_sentences])
tgt_max_len = max([len(sentence) for sentence in tgt_sentences])
src_sentences = [pad_sentence(sentence, src_max_len) for sentence in src_sentences]
tgt_sentences = [pad_sentence(sentence, tgt_max_len) for sentence in tgt_sentences]
ENCODER_EMBEDDING_DIM = 16
ENCODER_HIDDEN_DIM = 32
DECODER_EMBEDDING_DIM = 16
DECODER_HIDDEN_DIM = 32
ATTENTION_HIDDEN_DIM = 32
LEARNING_RATE = 0.01
EPOCHS = 50
using = "luong" # "bahdanau" or "luong"
loung_attention = "concat" # "general", "concat", or "dot"
if using == "bahdanau":
encoder = BahdanauAttentionEncoder(len(src_tkn2idx), ENCODER_EMBEDDING_DIM, ENCODER_HIDDEN_DIM, DECODER_HIDDEN_DIM)
decoder = BahdanauAttentionDecoder(
len(tgt_tkn2idx), DECODER_EMBEDDING_DIM, DECODER_HIDDEN_DIM, ENCODER_HIDDEN_DIM, ATTENTION_HIDDEN_DIM
)
model = BahdanauAttentionModel(encoder, decoder)
else:
if loung_attention == "general":
attention = LuongGeneralAttention(DECODER_HIDDEN_DIM)
elif loung_attention == "concat":
attention = LuongConcatAttention(DECODER_HIDDEN_DIM)
else:
attention = LuongDotAttention()
encoder = LuongAttentionEncoder(len(src_vocab), ENCODER_EMBEDDING_DIM, ENCODER_HIDDEN_DIM, DECODER_HIDDEN_DIM)
decoder = LuongAttentionDecoder(attention, len(tgt_vocab), DECODER_EMBEDDING_DIM, DECODER_HIDDEN_DIM)
model = LuongAttentionModel(encoder, decoder)
optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
criterion = nn.CrossEntropyLoss(ignore_index=PAD_TOKEN)
def train():
training_pairs = []
for src, tgt in zip(src_sentences, tgt_sentences):
src_tensor = torch.tensor(src, dtype=torch.long)
tgt_tensor = torch.tensor(tgt, dtype=torch.long)
training_pairs.append((src_tensor, tgt_tensor))
for epoch in range(EPOCHS):
total_loss = 0
for src_tensor, tgt_tensor in training_pairs:
src_tensor = src_tensor.unsqueeze(0)
tgt_tensor = tgt_tensor.unsqueeze(0)
optimizer.zero_grad()
outputs = model(src_tensor, tgt_tensor)
outputs_dim = outputs.shape[-1]
outputs = outputs[:, 1:, :].reshape(-1, outputs_dim)
tgt = tgt_tensor[:, 1:].reshape(-1)
loss = criterion(outputs, tgt)
loss.backward()
optimizer.step()
total_loss += loss.item()
if (epoch + 1) % 10 == 0:
print(f"Epoch: {epoch + 1}, Loss: {total_loss}")
def translate_beam_search(sentence, beam_width=3, max_length=10):
model.eval()
src_idx = convert_sentence_to_idx(sentence, src_tkn2idx)
src_idx = pad_sentence(src_idx, src_max_len)
src_tensor = torch.tensor(src_idx, dtype=torch.long)
with torch.no_grad():
src_tensor = src_tensor.unsqueeze(0)
if using == "bahdanau":
encoder_all_hidden, decoder_hidden = model.encoder(src_tensor)
else:
encoder_all_hidden, decoder_hidden, decoder_cell = model.encoder(src_tensor)
if using == "bahdanau":
beam = [([SOS_TOKEN], decoder_hidden, None, 0.0)]
else:
beam = [([SOS_TOKEN], decoder_hidden, decoder_cell, 0.0)]
completed_sentences = []
for _ in range(max_length):
new_beam = []
for tokens, decoder_hidden, decoder_cell, score in beam:
if tokens[-1] == EOS_TOKEN:
completed_sentences.append((tokens, score))
new_beam.append((tokens, decoder_hidden, decoder_cell, score))
continue
input_index = torch.tensor([tokens[-1]], dtype=torch.long)
with torch.no_grad():
if using == "bahdanau":
prediction, decoder_hidden = model.decoder(input_index, decoder_hidden, encoder_all_hidden)
else:
prediction, decoder_hidden, decoder_cell = model.decoder(
input_index, decoder_hidden, decoder_cell, encoder_all_hidden
)
log_probs = torch.log_softmax(prediction, dim=1).squeeze(0)
topk = torch.topk(log_probs, beam_width)
for tkn_idx, tkn_score in zip(topk.indices.tolist(), topk.values.tolist()):
new_tokens = tokens + [tkn_idx]
new_score = score + tkn_score
new_beam.append((new_tokens, decoder_hidden, decoder_cell, new_score))
new_beam.sort(key=lambda x: x[3], reverse=True)
beam = new_beam[:beam_width]
for tokens, decoder_hidden, decoder_cell, score in beam:
if tokens[-1] != EOS_TOKEN:
completed_sentences.append((tokens, score))
completed_sentences.sort(key=lambda x: x[1], reverse=True)
best_tokens, best_score = completed_sentences[0]
if best_tokens[0] == SOS_TOKEN:
best_tokens = best_tokens[1:]
if EOS_TOKEN in best_tokens:
best_tokens = best_tokens[:best_tokens.index(EOS_TOKEN)]
return " ".join([tgt_idx2tkn[idx] for idx in best_tokens])
def test():
test_sentences = [
"hello world",
"i love you",
"cat",
"go home",
]
for sentence in test_sentences:
translation = translate_beam_search(sentence)
print(f"src: {sentence}, tgt: {translation}")
if __name__ == '__main__':
train()
test()Conclusion
The alignment model used by Bahdanau is an additive calculation method, so it is computationally intensive but generally more expressive, so it is suitable for situations where complex and subtle alignment relationships need to be captured. The multiplicative method used by Luong is computationally simpler, faster, and more scalable, making it more suitable when fast training and inference are required or when computing resources are limited.
References
- Dzmitry Bahdanau, KyungHyun Cho, and Yoshua Bengio. 2015. Neural Machine Translation by Jointly Learning to Align and Translate. In ICLR.
- Minh-Thang Luong, Hieu Pham, and Christopher Manning. 2015. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1412–1421.









