
In Reinforcement Learning (RL), many algorithms may appear different in form, yet their core update mechanisms are highly similar. At the implementation level, they all rely on a common numerical estimation approach. This approach is not an independent algorithm, but rather a computational technique for gradually approximating an expectation. Understanding this mechanism helps clarify the fundamental differences among various reinforcement learning methods.
Table of Contents
Incremental Implementation
In Reinforcement Learning (RL), incremental implementation are not independent algorithms, but numerical techniques for estimating expectations. The key idea is to avoid recomputing an expectation from scratch using all available data. Instead, the estimate is adjusted by a small amount each time a new sample is observed.

The difference between the target and the old estimate can be interpreted as the error of the current estimate. The essence of an incremental update is to adjust the estimate in the direction of this error.

The Mathematical Essence of Incremental
Given samples  , the sample mean can be computed as follows. This is the batch form of the sample mean.
, the sample mean can be computed as follows. This is the batch form of the sample mean.

However, the sample mean can also be computed in an incremental form, as shown below. This is a typical incremental update.

In this formulation, the step size is  , and the target is
, and the target is 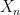 . In the incremental form, each update can be viewed as using the newly observed sample as the current sample target.
. In the incremental form, each update can be viewed as using the newly observed sample as the current sample target.
It is worth noting that as more samples are collected, the step size  becomes smaller and smaller. As a result, even if new data indicate a significant change in the mean, the estimate may become sluggish and fail to track this change because the step size is too small. Under a non-stationary data distribution, as approaches zero, the estimate gradually loses its ability to adapt to new data. In this setting, if we wish the estimate to remain sensitive to recent samples, we can instead use a constant step size
becomes smaller and smaller. As a result, even if new data indicate a significant change in the mean, the estimate may become sluggish and fail to track this change because the step size is too small. Under a non-stationary data distribution, as approaches zero, the estimate gradually loses its ability to adapt to new data. In this setting, if we wish the estimate to remain sensitive to recent samples, we can instead use a constant step size  . The incremental update with a constant step size is given as follows:
. The incremental update with a constant step size is given as follows:

By expanding the above equation, we can see that older samples have progressively less influence on the estimate.

Conclusion
Incremental implementation provides a unified perspective for understanding how value estimates are updated across different reinforcement learning methods. By choosing appropriate step sizes and targets, an algorithm can continuously refine its estimate of an expectation under constraints of limited memory and online interaction. When the step size decreases with the number of samples, the estimate converges to the conventional sample mean; when a constant step size is used, the estimate retains the ability to adapt to new data in non-stationary environments. As will be seen later, different reinforcement learning methods arise primarily from defining different targets while applying the same incremental update framework.
References
- Richard S. Sutton and Andrew G. Barto. 2020. Reinforcement Learning: An Introduction, 2nd. The MIT Press.









