
In Reinforcement Learning (RL), Dynamic Programming (DP) is the earliest and most complete solution framework. Although DP is almost impossible to apply directly to practical high-dimensional or continuous environments, it reveals the mathematical foundations of all core concepts in modern RL. At a fundamental level, the convergence objectives and update rules of all RL algorithms are derived from the Bellman Equations and the Generalized Policy Iteration (GPI) framework used in DP.
The complete code for this chapter can be found in .
Table of Contents
Reinforcement Learning Method Classification
Before introducing Dynamic Programming algorithms, it is necessary to first outline three common classifications in Reinforcement Learning (RL). These classifications are used to describe the form and properties of algorithms themselves. They characterize the scenarios in which different algorithms are applicable, rather than implying any inherent superiority among them.
Model-Based vs. Model-Free
Model-based methods assume that the agent knows the complete environment model, or is able to learn it. In other words, the agent can predict the reward and transition dynamics associated with each action.

The main characteristics of model-based methods are:
- They can directly use the exact expectation form of the Bellman equation.
- They can perform planning, meaning that future outcomes can be simulated without actual interaction with the environment.
In contrast, model-free methods do not require the agent to know the environment model and rely entirely on samples collected through interaction for learning.
The main characteristics of model-free methods are:
- More closely aligned with real-world settings.
- No need to know the transition dynamics.
Bootstrapping vs. Non-Bootstrapping
Bootstrapping refers to methods that, when updating a value function, use other estimated values rather than the complete return  . In the following equation,
. In the following equation,  is updated using the estimated value
is updated using the estimated value  , and is therefore a bootstrapping method.
, and is therefore a bootstrapping method.
![\displaystyle v_{\pi^\prime}(s) \leftarrow \sum_a \pi(a \mid s) \sum_{s^\prime, r} p(s^\prime, r \mid s, a) \left[ r + \gamma v_\pi(s^\prime) \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+v_%7B%5Cpi%5E%5Cprime%7D%28s%29+%5Cleftarrow+%5Csum_a+%5Cpi%28a+%5Cmid+s%29+%5Csum_%7Bs%5E%5Cprime%2C+r%7D+p%28s%5E%5Cprime%2C+r+%5Cmid+s%2C+a%29+%5Cleft%5B+r+%2B+%5Cgamma+v_%5Cpi%28s%5E%5Cprime%29+%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)
The main characteristics of bootstrapping methods are:
- Fast updates.
- Potential bias, because the update relies on estimates that may not yet be accurate, causing the update to deviate from the true expectation.
Non-bootstrapping methods, in contrast, update the value function using the complete return without relying on any estimated values.

The main characteristics of non-bootstrapping methods are:
- Unbiased estimates.
- High variance, because the complete return is strongly influenced by the random noise accumulated over an entire trajectory.
On-Policy vs. Off-Policy
In RL, there are always two distinct aspects to consider:
- Which policy to learn.
- This is called the target policy, denoted by
 .
. - You aim to obtain its value functions and , or to directly optimize its parameters.
- This is called the target policy, denoted by
- Which policy actually interacts with the environment and generates data.
- This is called the behavior policy, denoted by .
- It determines which action the agent actually selects in each state.
- This is called the behavior policy, denoted by
 , or to directly optimize its parameters.
, or to directly optimize its parameters.On-policy methods refer to the case where  . That is, the policy being learned is the same policy used for interaction and sampling.
. That is, the policy being learned is the same policy used for interaction and sampling.
For example, suppose we interact with the environment using an $ policy
policy  and collect samples and returns generated during interaction. All of these data are generated under . We then use these data to update the value functions
and collect samples and returns generated during interaction. All of these data are generated under . We then use these data to update the value functions  .
.
Off-policy methods refer to the case where  . That is, the policy being learned is different from the policy used for interaction and sampling.
. That is, the policy being learned is different from the policy used for interaction and sampling.
For example, we may interact with the environment using a behavior policy  and collect samples and returns generated during interaction.
and collect samples and returns generated during interaction.
Dynamic Programming, DP
Dynamic Programming (DP) is the earliest, most complete, and most mathematically grounded solution approach in Reinforcement Learning.
DP is a model-based method. It relies entirely on the environment model and assumes that the transition dynamics  are fully known. This means that for a given state
are fully known. This means that for a given state  and action
and action  , all possible next states
, all possible next states  and their corresponding rewards
and their corresponding rewards  are known. In other words, the probability distribution of state transitions is available. As a result, DP is a typical planning method. It does not require sampling from the environment but instead performs inference directly on the model.
are known. In other words, the probability distribution of state transitions is available. As a result, DP is a typical planning method. It does not require sampling from the environment but instead performs inference directly on the model.
DP is a bootstrapping method. Because the complete model is known, DP can perform full sweeps over all states and iteratively converge using the Bellman equations.
DP is an on-policy method. There is no sampling in DP. Policy evaluation uses the policy  itself, and policy improvement applies a greedy policy derived from
itself, and policy improvement applies a greedy policy derived from  , both of which are based on the current policy .
, both of which are based on the current policy .
Prediction
Iterative Policy Evaluation
In RL, policy evaluation is referred to as a prediction problem. A prediction problem asks, given a known policy , what is its state-value function  ?
?
Iterative Policy Evaluation is a prediction method within Dynamic Programming. It uses the Bellman equation as its update rule. Under the same conditions that guarantee the existence of , the sequence  converges to as
converges to as  .
.
![\displaystyle v_{k+1} \doteq \mathbb{E}_\pi \left[ R_{t+1} + \gamma v_k(S_{t+1}) \mid S_t=s \right] \\\\ \hphantom{v_{k+1}} = \sum_a \pi(a \mid s) \sum_{s^\prime, r} p(s^\prime, r \mid s, a) \left[ r + \gamma v_k(s^\prime) \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+v_%7Bk%2B1%7D+%5Cdoteq+%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+R_%7Bt%2B1%7D+%2B+%5Cgamma+v_k%28S_%7Bt%2B1%7D%29+%5Cmid+S_t%3Ds+%5Cright%5D+%5C%5C%5C%5C+%5Chphantom%7Bv_%7Bk%2B1%7D%7D+%3D+%5Csum_a+%5Cpi%28a+%5Cmid+s%29+%5Csum_%7Bs%5E%5Cprime%2C+r%7D+p%28s%5E%5Cprime%2C+r+%5Cmid+s%2C+a%29+%5Cleft%5B+r+%2B+%5Cgamma+v_k%28s%5E%5Cprime%29+%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)
The algorithm for iterative policy evaluation is as follows:

Control
In RL, the goal of a control problem is to find an optimal policy  by repeatedly performing policy evaluation and policy improvement, such that the expected return is maximized for all states.
by repeatedly performing policy evaluation and policy improvement, such that the expected return is maximized for all states.
Next, we introduce two control methods in Dynamic Programming.
Policy Iteration
The idea of policy iteration in DP is that once a policy is improved using its state-value function , yielding a better policy  , we can then evaluate
, we can then evaluate  and obtain a further improved policy
and obtain a further improved policy  . Since a finite MDP has only a finite number of policies, this process is guaranteed to eventually converge to the optimal policy and the optimal state-value function.
. Since a finite MDP has only a finite number of policies, this process is guaranteed to eventually converge to the optimal policy and the optimal state-value function.
The algorithm for policy iteration is as follows:

Value Iteration
One drawback of policy iteration is that each iteration involves policy evaluation, which requires multiple iterative updates over all states and can therefore be computationally expensive.
Value Iteration addresses this issue by combining policy evaluation and policy improvement into a single step, using the Bellman optimality equation for updates. For any initial value function  , under the same conditions that guarantee the existence of the optimal value function
, under the same conditions that guarantee the existence of the optimal value function  , the sequence can be shown to converge to .
, the sequence can be shown to converge to .
![\displaystyle v_{k+1} \doteq \max_a \mathbb{E} \left[ R_{t+1} + \gamma v_k(S_{t+1}) \mid S_t=s \right] \\\\ \hphantom{v_{k+1}} = \max_a \sum_{s^\prime, r} p(s^\prime, r \mid s, a) \left[ r + \gamma v_k(s^\prime) \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+v_%7Bk%2B1%7D+%5Cdoteq+%5Cmax_a+%5Cmathbb%7BE%7D+%5Cleft%5B+R_%7Bt%2B1%7D+%2B+%5Cgamma+v_k%28S_%7Bt%2B1%7D%29+%5Cmid+S_t%3Ds+%5Cright%5D+%5C%5C%5C%5C+%5Chphantom%7Bv_%7Bk%2B1%7D%7D+%3D+%5Cmax_a+%5Csum_%7Bs%5E%5Cprime%2C+r%7D+p%28s%5E%5Cprime%2C+r+%5Cmid+s%2C+a%29+%5Cleft%5B+r+%2B+%5Cgamma+v_k%28s%5E%5Cprime%29+%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)
Once 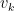 has sufficiently converged, the optimal policy is given by:
has sufficiently converged, the optimal policy is given by:
![\displaystyle \pi_*(s) = \text{argmax}_a \sum_{s^\prime, r} p(s^\prime, r \mid s, a) \left[ r + \gamma v_k(s^\prime) \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cpi_%2A%28s%29+%3D+%5Ctext%7Bargmax%7D_a+%5Csum_%7Bs%5E%5Cprime%2C+r%7D+p%28s%5E%5Cprime%2C+r+%5Cmid+s%2C+a%29+%5Cleft%5B+r+%2B+%5Cgamma+v_k%28s%5E%5Cprime%29+%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)
The algorithm for value iteration is as follows:

Efficiency and Limitations
DP directly uses the Bellman equations and requires no sampling, resulting in no estimation error. As a result, its convergence process is stable and predictable. However, the limitations of DP are severe, making it almost impossible to apply in practical RL settings. The main reasons are:
- It requires a complete environment model.
- It requires full sweeps over all states, leading to a very high computational cost.
- It cannot handle continuous or high-dimensional state spaces.
Although DP cannot be applied to large-scale problems, it remains an indispensable component of RL because it provides the conceptual foundation for all other methods. The Bellman equations in their DP form underpin every other RL algorithm.
Examples
Implementation
In the following code, we faithfully implement the two control methods of DP, policy iteration and value iteration.
The variable env is a Gymnasium Env object. Gymnasium is the successor to OpenAI Gym and provides a wide range of RL environments, allowing us to test reinforcement learning algorithms in simulated settings.
An environment contains env.observation_space.n states. Accordingly, states are indexed by integers from 0 to env.observation_space.n - 1. The variable V is a one-dimensional array of floating-point values, where each element represents the estimated state-value of a state. For example, V[0] is the estimated state-value of state 0.
Each state has env.action_space.n possible actions, indexed from 0 to env.action_space.n - 1. The policy pi is a two-dimensional floating-point array of shape [env.observation_space.n][env.action_space.n]. Each entry pi[s][a] is a probability in the range ![\left[ 0,1 \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+0%2C1+%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002) , and for each state , the probabilities over all actions sum to 1.
, and for each state , the probabilities over all actions sum to 1.
The environment’s env.unwrapped.P represents the transition dynamics. Each entry env.unwrapped.P[s][a] contains the next state, the reward, the transition probability, and an indicator of whether the next state is terminal.
class DynamicProgramming:
def __init__(self, env: gym.Env, gamma=0.9, theta=1e-9):
self.env = env
self.gamma = gamma
self.theta = theta
def _policy_evaluation(self, pi: np.ndarray, V: np.ndarray) -> np.ndarray:
while True:
delta = 0
for s in range(self.env.observation_space.n):
v = 0
for a, pi_as in enumerate(pi[s]):
q_sa = 0
for p, s_prime, r, terminated in self.env.unwrapped.P[s][a]:
q_sa += p * (r + self.gamma * V[s_prime] * (not terminated))
v += pi_as * q_sa
delta = max(delta, np.abs(v - V[s]))
V[s] = v
if delta < self.theta:
break
return V
def _policy_improvement(self, pi: np.ndarray, V: np.ndarray) -> tuple[np.ndarray, bool]:
policy_stable = True
for s in range(self.env.observation_space.n):
old_a = np.argmax(pi[s])
pi[s] = self._greedify_policy(V, s)
new_a = np.argmax(pi[s])
if old_a != new_a:
policy_stable = False
return pi, policy_stable
def _greedify_policy(self, V: np.ndarray, s: int) -> np.ndarray:
q_s = np.zeros(self.env.action_space.n)
for a in range(self.env.action_space.n):
for p, s_prime, r, terminated in self.env.unwrapped.P[s][a]:
q_s[a] += p * (r + self.gamma * V[s_prime] * (not terminated))
new_a = np.argmax(q_s)
pi_s = np.eye(self.env.action_space.n)[new_a]
return pi_s
def policy_iteration(self) -> tuple[np.ndarray, np.ndarray]:
V = np.zeros(self.env.observation_space.n)
pi = np.ones((self.env.observation_space.n, self.env.action_space.n)) / self.env.action_space.n
policy_stable = False
while not policy_stable:
V = self._policy_evaluation(pi, V)
pi, policy_stable = self._policy_improvement(pi, V)
return pi, V
def value_iteration(self) -> tuple[np.ndarray, np.ndarray]:
V = np.zeros(self.env.observation_space.n)
while True:
delta = 0
for s in range(self.env.observation_space.n):
q_s = np.zeros(self.env.action_space.n)
for a in range(self.env.action_space.n):
for p, s_prime, r, terminated in self.env.unwrapped.P[s][a]:
q_s[a] += p * (r + self.gamma * V[s_prime] * (not terminated))
new_a = np.max(q_s)
delta = max(delta, np.abs(new_a - V[s]))
V[s] = new_a
if delta < self.theta:
break
pi = np.zeros((self.env.observation_space.n, self.env.action_space.n))
for s in range(self.env.observation_space.n):
pi[s] = self._greedify_policy(V, s)
return pi, VCliff Walking
Cliff Walking involves moving from a start position to a goal position in a grid world while avoiding falling off a cliff, as illustrated below.

In the Cliff Walking problem, each state corresponds to the player’s current position. There are a total of 36 states, consisting of the top three rows plus the bottom-left cell, giving  states. The current position is computed using the following formula:
states. The current position is computed using the following formula:

There are four available actions:
- 0: Move up
- 1: Move right
- 2: Move down
- 3: Move left
Each step yields a reward of −1. However, if the agent steps into the cliff, it receives a reward of −100.
import time
import gymnasium as gym
import numpy as np
from dp import DynamicProgramming
GYM_ID = "CliffWalking-v1"
def play_game(policy, episodes=1):
visual_env = gym.make(GYM_ID, render_mode="human")
for episode in range(episodes):
state, _ = visual_env.reset()
terminated = False
truncated = False
total_reward = 0
step_count = 0
print(f"Episode {episode + 1} starts")
while not terminated and not truncated:
action = np.argmax(policy[state])
state, reward, terminated, truncated, _ = visual_env.step(action)
total_reward += reward
step_count += 1
time.sleep(0.3)
print(f"Episode {episode + 1} is finished: Total reward is {total_reward}, steps = {step_count}")
time.sleep(1)
visual_env.close()
if __name__ == "__main__":
env = gym.make(GYM_ID)
dp = DynamicProgramming(env)
print(f"Gym environment: {GYM_ID}")
print("Start DP Policy Iteration")
pi_policy, pi_V = dp.policy_iteration()
play_game(pi_policy)
print("\n")
print("Start DP Value Iteration")
vi_policy, vi_V = dp.value_iteration()
play_game(vi_policy)
env.close()The following figure shows the execution result of the above program. After training, the agent learns a policy that moves along the edge of the cliff and reaches the goal through the shortest path, which corresponds to the optimal behavior in the Cliff Walking environment under the given reward structure.

Taxi
The Taxi problem takes place in a grid world where the agent must navigate to the passenger’s location, pick up the passenger, and then deliver them to one of four designated destinations, as illustrated below.
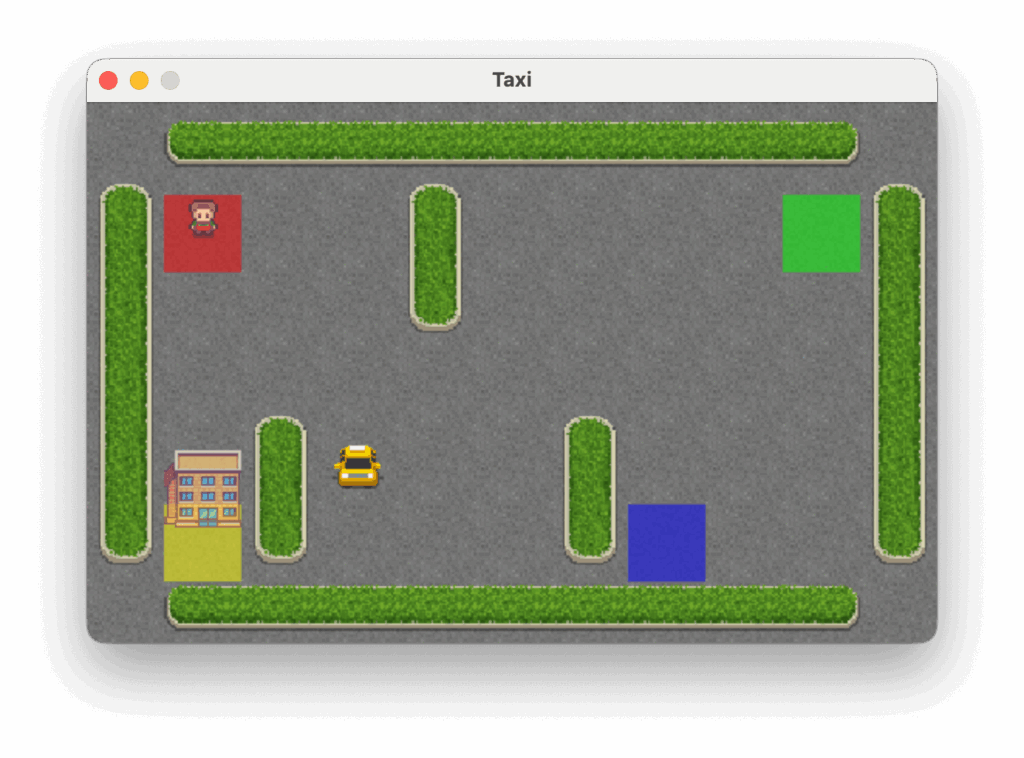
In the Taxi problem, there are 500 discrete states. Each state is encoded by the following formula:

Passenger locations are defined as:
- 0: Red
- 1: Green
- 2: Yellow
- 3: Blue
- 4: In taxi
Destinations are defined as:
- 0: Red
- 1: Green
- 2: Yellow
- 3: Blue
There are six available actions:
- 0: Move south (down)
- 1: Move north (up)
- 2: Move east (right)
- 3: Move west (left)
- 4: Pick up passenger
- 5: Drop off passenger
Each step yields a reward of −1 unless another reward is triggered. Successfully delivering the passenger to the destination yields a reward of +20. Executing an illegal pickup or drop-off action results in a reward of −10.
import time
import gymnasium as gym
import numpy as np
from dp import DynamicProgramming
GYM_ID = "Taxi-v3"
def play_game(policy, episodes=1):
visual_env = gym.make(GYM_ID, render_mode="human")
for episode in range(episodes):
state, _ = visual_env.reset()
terminated = False
truncated = False
total_reward = 0
step_count = 0
print(f"Episode {episode + 1} starts")
while not terminated and not truncated:
action = np.argmax(policy[state])
state, reward, terminated, truncated, _ = visual_env.step(action)
total_reward += reward
step_count += 1
time.sleep(0.3)
print(f"Episode {episode + 1} is finished: Total reward is {total_reward}, steps = {step_count}")
time.sleep(1)
visual_env.close()
if __name__ == "__main__":
env = gym.make(GYM_ID)
dp = DynamicProgramming(env)
print(f"Gym environment: {GYM_ID}")
print("Start DP Policy Iteration")
pi_policy, pi_V = dp.policy_iteration()
play_game(pi_policy)
print("\n")
print("Start DP Value Iteration")
vi_policy, vi_V = dp.value_iteration()
play_game(vi_policy)
env.close()Below are the execution results of the above program.
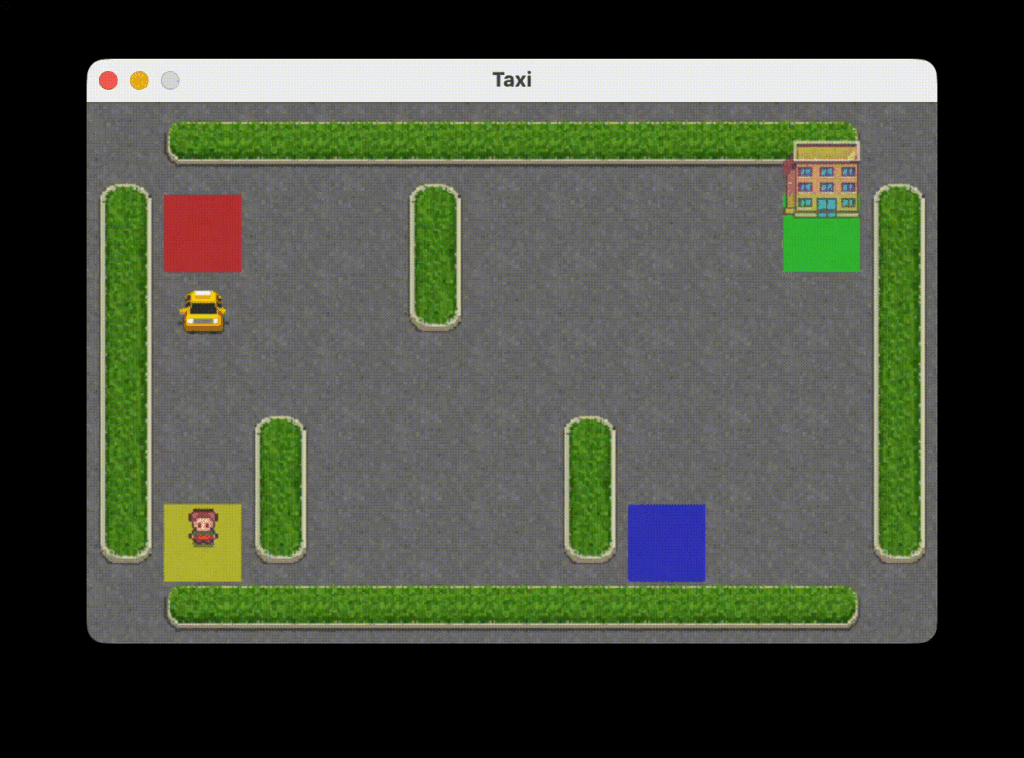
Conclusion
DP, through explicit Bellman equations, complete model information, and systematic sweeps, provides the purest and most mathematically grounded approach to policy evaluation and policy improvement. Although DP requires a complete environment model and exhaustive traversal of the entire state space, making it impractical for direct application in complex real-world environments—its value lies not in implementation, but in the conceptual foundation it establishes. Consequently, even though DP itself is unsuitable for large-scale problems, it remains the basis for understanding all subsequent RL algorithms.
References
- Adam White and Martha White. Reinforcement Learning Specialization. University of Alberta and Coursera.
- Richard S. Sutton and Andrew G. Barto. 2020. Reinforcement Learning: An Introduction, 2nd. The MIT Press.









