
The performance of LLMs on reasoning tasks has undergone substantial change in recent years with the introduction of Chain-of-Thought (CoT) prompting. This technique guides an LLM to produce step-by-step intermediate reasoning, enabling the model to exhibit a human-like structure of thought. As task complexity increases, however, the limitations of traditional CoT have become more apparent, motivating a series of follow-up methods designed to address these issues. This article presents an overview of CoT and its extensions.
The complete code for this chapter can be found in .
Table of Contents
Chain-of-Thought Prompting, CoT
Chain-of-Thought (CoT), introduced by Wei et al. in 2022, is a prompting-based technique designed to guide LLMs through complex reasoning tasks by generating step-by-step intermediate reasoning. Its underlying idea derives from observations of human problem-solving behavior. When approaching multi-step problems, humans naturally decompose a task into smaller intermediate steps, solve them individually, and then integrate the results to form a final answer. For example, in a typical math word problem, one might think: “After giving 2 flowers to her mother, she has 10 left; after giving 3 more to her father, she has 7 left; therefore, the answer is 7.” CoT aims to instill this incremental, decompositional reasoning pattern in LLMs.
Wei et al. demonstrated that providing exemplars containing such structured reasoning enables LLMs to autonomously produce similar chains of thought in a few-shot setting, even without any task-specific fine-tuning. Empirical results show that sufficiently large LLMs can mimic this step-by-step reasoning style and achieve significant performance gains on reasoning tasks that they previously struggled to solve.
In the original formulation, CoT is purely a prompting-based method; the model’s behavior is controlled entirely through the prompt, without additional training or parameter updates. This characteristic makes CoT broadly applicable across different LLMs, provided that the model has adequate scale and linguistic capability.
The key properties of CoT are as follows:
- By incorporating exemplars with intermediate reasoning steps, CoT enables the model to decompose an original problem into smaller logical units.
- The reasoning process generated by CoT offers interpretability, allowing researchers to inspect whether the model’s reasoning is coherent and to identify where errors occur. An important asset for behavioral analysis, error diagnosis, and later methodological improvements.
- CoT is not restricted to any particular task type; it applies to any problem where step-by-step reasoning can be expressed in natural language.
- CoT requires no fine-tuning, no additional annotations, and no architectural modifications to the underlying model.
Example
The following is a one-shot prompt in which the initial example provides a direct answer without using CoT reasoning.
Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now? A: The answer is 11. Q: The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?
Under this setting, the LLM produces an incorrect answer.
A: The answer is 27.
When we modify the example’s answer to use a CoT-style explanation instead.
Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now? A: Roger started with 5 balls. 2 cans of 3 tennis balls each is 6 tennis balls. 5 + 6 = 11. The answer is 11. Q: The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?
The LLM subsequently responds using CoT reasoning and arrives at the correct answer.
A: The cafeteria had 23 apples originally. They used 20 to make lunch. So they had 23 - 20 = 3. They bought 6 more apples, so they have 3 + 6 = 9. The answer is 9.
Self-Consistency, SC
Self-Consistency (SC), proposed by Wang et al. in 2023, is an enhancement technique built on top of CoT prompting. Its primary goal is to address the instability that arises from CoT’s reliance on a single reasoning trajectory. In standard CoT, an LLM produces one chain of reasoning and derives an answer from it; however, this single trajectory is often fragile and may fail due to stochastic variation, contextual perturbation, or changes in prompt phrasing. The key idea behind SC is that if a problem possesses a stable underlying semantic structure, then even if the LLM generates different reasoning paths across multiple samples, the final answers should statistically converge toward the correct solution.
SC operates as follows:
- It employs high-temperature sampling, nucleus sampling, or top-k sampling to generate multiple reasoning chains, enabling the model to explore diverse directions of thought. In each sample, the LLM produces a complete CoT and outputs a final answer.
- After collecting these samples, SC does not judge the semantic quality of each reasoning path. Instead, it aggregates the final answers across all samples and selects the most frequently occurring answer as the final output.
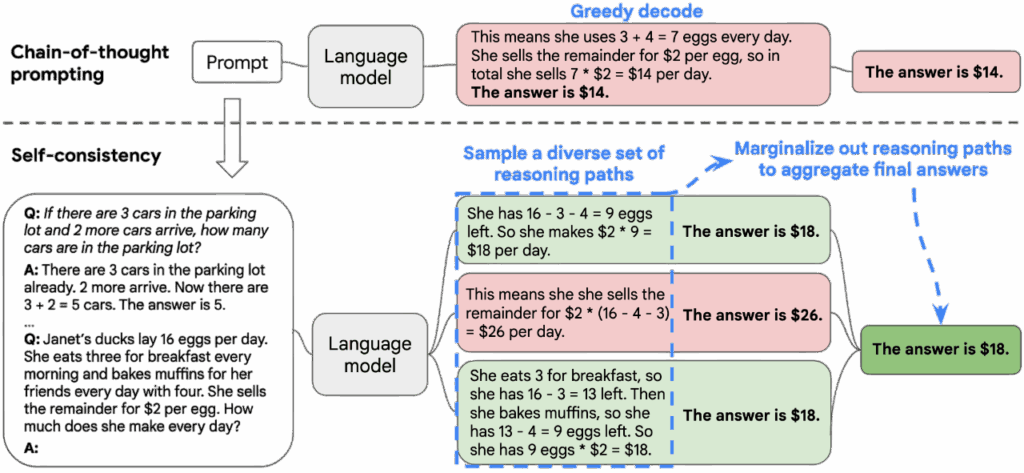
Example
Here is the implementation of SC. We use zero-shot prompting, but include the phrase “think step by step” to induce the LLM to answer using a CoT style. We then have the LLM answer the same question ten times with a relatively high temperature, so that each response is slightly different. Finally, we collect all the answers and select the one that appears most frequently as the final prediction.
from collections import Counter
import re
from question import QUESTION
from utilities import llm
PROMPT = """
Solve the following problem step by step.
{premise_block}
Let's think step by step.
{question_sentence}
""".strip()
def build_prompt(premise_sentences: list[str], question_sentence: str) -> str:
premise_block = "\n".join(premise_sentences)
return PROMPT.format(premise_block=premise_block, question_sentence=question_sentence)
def extract_final_answer(text) -> str | None:
numbers = re.findall(r"-?\d+", text)
if not numbers:
return None
return numbers[-1]
def split_sentences(text: str) -> list[str]:
sentences = re.split(r"(?<=[.?!])\s+", text.strip())
return [s.strip() for s in sentences if s.strip()]
def identify_question_index(sentences: list[str]) -> int:
numbered = []
for i, s in enumerate(sentences, 1):
numbered.append(f"{i}. {s}")
numbered_text = "\n".join(numbered)
prompt = f"""
Which sentence is the main question the user wants answered?
Return ONLY the number. Do not write anything else. Do not repeat the sentence.
{numbered_text}
Answer with a single number (1, 2, ..., or {len(numbered)}):
"""
output = llm(prompt)
match = re.search(r"\d+", output)
if not match:
raise ValueError(f"LLM failed to output a number: {output}")
return int(match.group())
def solve_problem(prompt, n=10) -> str:
answers = []
for i in range(n):
output = llm(prompt, temperature=0.8)
answer = extract_final_answer(output)
if answer is not None:
answers.append(answer)
if not answers:
raise ValueError("No valid answers from LLM.")
counts = Counter(answers)
final_answer = counts.most_common(1)[0][0]
return final_answer
def self_consistency(question: str) -> str:
sentences = split_sentences(question)
question_index = identify_question_index(sentences)
question_sentence = sentences[question_index - 1]
premise_sentences = [s for i, s in enumerate(sentences, 1) if i != question_index]
prompt = build_prompt(premise_sentences, question_sentence)
return solve_problem(prompt)
if __name__ == "__main__":
answer = self_consistency(QUESTION)
print(f"Self-Consistency\n\nQuestion:\n{QUESTION}\n\nAnswer:\n{answer}")
Least-to-Most Prompting, L2M
Least-to-Most Prompting (L2M), proposed by Zhou et al. in 2023, is a reasoning method built on the idea of problem decomposition. Zhou et al. argue that many complex reasoning problems can be broken down into a sequence of simpler subproblems, and that solving these subproblems step by step can effectively lead to the final solution. Humans naturally adopt a similar strategy when dealing with complex tasks: they first establish subgoals, then complete intermediate steps, and finally integrate these results to solve the overall problem. L2M adopts the same principle, using prompts to guide LLMs to reproduce this “from simple to complex” reasoning process.
In the original paper, L2M is positioned as a structured prompting technique. The LLM first generates a set of subproblems from the original question, then solves these subproblems one by one, and finally composes the final answer based on the solutions to the subproblems.
L2M operates as follows:
- Decomposition: The LLM is first asked to decompose the original problem into multiple, mutually related subproblems of lower difficulty. This decomposition step is itself a form of reasoning: the LLM must understand the problem’s semantics, identify its implicit structure, and transform it into sub-tasks that can be answered independently.
- Subproblem solving: After decomposition, the LLM sequentially answers each subproblem, where the solution to one subproblem may serve as a necessary input for subsequent reasoning steps.
- Final integration: Once all subproblems have been solved, the LLM then integrates these intermediate results to produce the final answer.
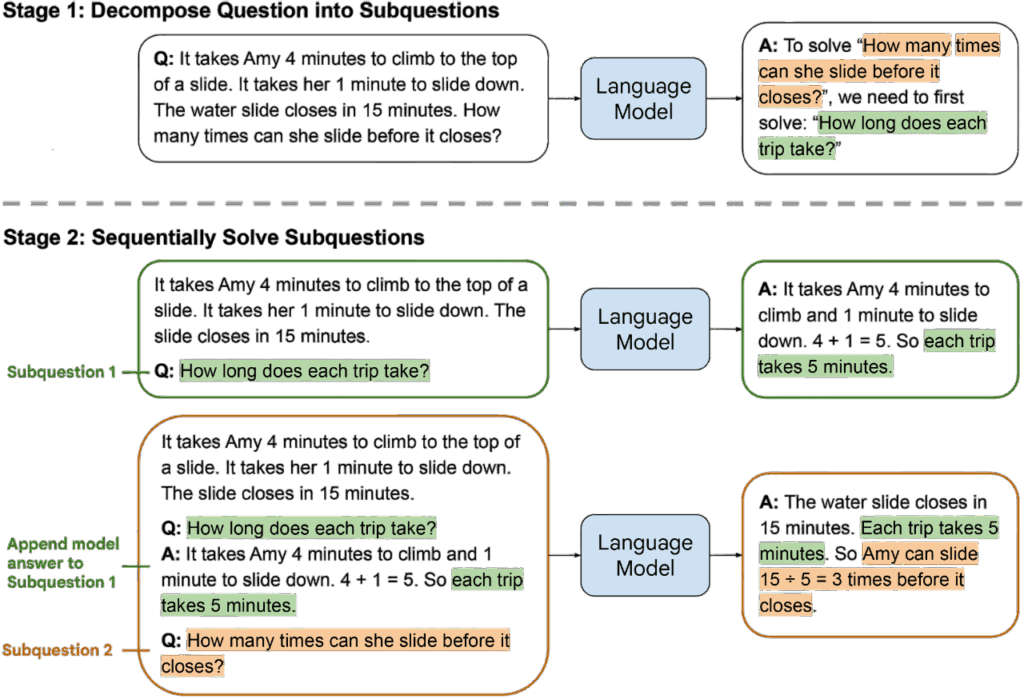
Example
Here is the implementation of L2M. We first prompt the LLM to decompose the input problem  into a sequence of subproblems (
into a sequence of subproblems ( ). We then have the LLM answer
). We then have the LLM answer  to obtain the answer
to obtain the answer  . Next, we let the LLM answer
. Next, we let the LLM answer  , which yields
, which yields  . This process repeats recursively until all subproblems have been answered. Finally, we prompt the LLM with
. This process repeats recursively until all subproblems have been answered. Finally, we prompt the LLM with  to obtain the final answer.
to obtain the final answer.
import re
from question import QUESTION
from utilities import llm
SUBPROBLEM_GENERATOR_PROMPT = """
Break the following problem into simple subproblems.
Each subproblem should be a small step required to solve the final question.
Return ONLY subproblems per each line. No explanation. Not solution.
Problem:
{input}
Output format:
SP 1: "subproblem 1"
SP 2: "subproblem 2"
...
"""
SUBPROBLEM_PROMPT = """
You are solving a complex problem by breaking it into smaller subproblems.
Original problem:
{input}
Previously solved subproblems:
{solved_subproblems}
Now solve the next subproblem:
{next_subproblem}
Return ONLY the short answer.
"""
FINAL_PROMPT = """
Use the solved subproblems to answer the final question.
Original problem:
{input}
Solved subproblems:
{solve_subproblems}
Based on the above, give the final answer to the original question.
Return ONLY the short answer.
"""
def generate_subproblems(question: str) -> list[str]:
prompt = SUBPROBLEM_GENERATOR_PROMPT.format(input=question)
output = llm(prompt)
lines = output.strip().splitlines()
subproblems = []
for line in lines:
match = re.match(r"\s*SP\s*\d+\s*:\s*(.+)", line.strip())
if match:
subproblems.append(match.group(1).strip())
return subproblems
def solve_subproblem(question: str, next_subproblem: str, solved: list[tuple[str, str]]):
solved_block = "\n".join(f"{i + 1}. {p} -> {a}" for i, (p, a) in enumerate(solved)) if solved else "(none)"
prompt = SUBPROBLEM_PROMPT.format(input=question, solved_subproblems=solved_block, next_subproblem=next_subproblem)
return llm(prompt)
def solve_final_problem(question: str, subproblems, answers):
solved_subproblems = []
for i, (sp, ans) in enumerate(zip(subproblems, answers), 1):
solved_subproblems.append(f"{i}. Subproblem: {sp}")
solved_subproblems.append(f" Answer: {ans}")
sp_block = "\n".join(solved_subproblems)
prompt = FINAL_PROMPT.format(input=question, solve_subproblems=sp_block)
return llm(prompt)
def l2m(question: str) -> str:
subproblems = generate_subproblems(question)
solved_pairs = []
answers = []
for i in range(len(subproblems)):
answer_i = solve_subproblem(question, subproblems[i], solved_pairs)
solved_pairs.append((subproblems[i], answer_i))
answers.append(answer_i)
return solve_final_problem(question, subproblems, answers)
if __name__ == "__main__":
answer = l2m(QUESTION)
print(f"Least-To-Most Prompting, L2M\n\nQuestion:\n{QUESTION}\n\nAnswer:\n{answer}")
Program-Aided Language Models, PAL
Program-Aided Language Models (PAL), proposed by Gao et al. in 2023, is a reasoning technique that integrates the capabilities of LLMs with an external program execution environment. Its core idea is to delegate the parts of a reasoning task that are formalizable, computable, or explicitly solvable through procedural steps to a programming language, while the LLM is responsible for generating the code, planning the computational workflow, and determining how to use external tools to derive the correct answer.
Gao et al. point out that although LLMs possess strong semantic abilities in natural-language reasoning, they still exhibit clear limitations in arithmetic, symbolic manipulation, complex computation, and tasks requiring precise execution. For example, an LLM may produce numerically incorrect results that appear linguistically plausible, or accumulate generative errors throughout long chains of reasoning. PAL mitigates such issues by combining natural-language reasoning with program execution, yielding a more reliable hybrid reasoning framework.

Example
Here is the implementation of PAL. Instead of having the LLM answer the question directly, we prompt the model to produce executable Python code, and then we obtain the final answer by running that code.
import re
from question import QUESTION
from utilities import llm
PROMPT = """
Write a Python function solve() that solves the problem below.
The function must return ONLY the final answer as an integer.
Problem:
{input}
Return ONLY the python code.
The Python code must define a function:
def solve():
# compute the answer
return <integer>
"""
def generate_code(question: str) -> str:
prompt = PROMPT.format(input=question)
output = llm(prompt)
match = re.search(r"```(.*?)```", output, re.DOTALL)
return match.group(1).strip()
def execute_code(code: str) -> int:
local_vars = {}
global_vars = {"__builtins__": {"range": range, "len": len}}
exec(code, global_vars, local_vars)
if "solve" not in local_vars:
raise ValueError("solve() function not defined in code")
return local_vars["solve"]()
def pal(question: str) -> int:
code = generate_code(question)
return execute_code(code)
if __name__ == "__main__":
answer = pal(QUESTION)
print(f"Program-aided Language Model, PAL\n\nQuestion:\n{QUESTION}\n\nAnswer:\n{answer}")
Tree-of-Thought, ToT
Tree-of-Thought (ToT), proposed by Yao et al. in 2023, is a reasoning framework that extends an LLM’s capabilities from the single-path structure of CoT to a branching search process. Yao et al. argue that complex reasoning problems typically exhibit an inherent tree-like structure rather than a single linear sequence of logic. When relying solely on a one-shot CoT trajectory, an LLM may fail if an early step is incorrect, causing the entire reasoning chain to collapse. ToT was introduced to address this limitation by allowing the model to generate, evaluate, and explore multiple candidate reasoning paths, thereby achieving more stable and reliable reasoning performance.
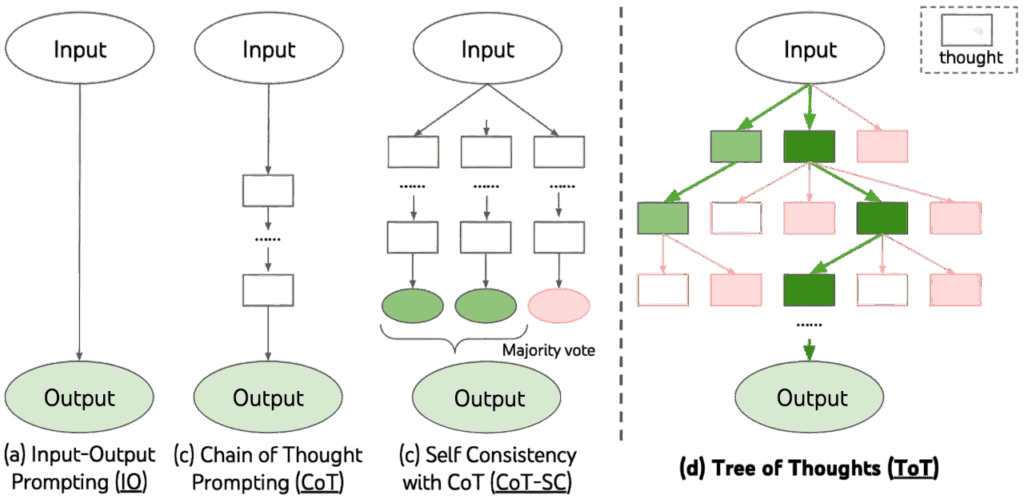
The architecture of ToT is as follows:
- Thought Decomposition: While CoT produces a single coherent reasoning sequence, it does not explicitly define the intermediate reasoning units (thoughts). ToT analyzes the nature of the problem and decomposes the reasoning process into multiple intermediate thought steps, each of which serves as a node in the reasoning tree.
- Thought Generator: At each state of the reasoning tree, the LLM must generate k candidate thoughts. Two strategies are used:
- Sample: The model independently generates k candidate thoughts using a CoT-style prompt. This strategy works well when the thought space is large and diverse (e.g., creative writing tasks).
- Propose: The model produces k different thoughts sequentially within the same prompt. This is useful when the thought space is smaller and more prone to duplication.
- State Evaluator: After generating candidate states at each level, ToT evaluates the quality of each state to provide heuristic guidance for the search algorithm. Two evaluation strategies are used:
- Value: The LLM assigns a score or category to each state using a value prompt.
- Vote: When assigning numerical values is difficult, ToT instead compares all candidate states through a voting prompt and selects the most promising one.
- Search Algorithm: The results from thought generation and state evaluation are fed into a search algorithm. ToT primarily uses two types of search:
- Breadth-first search (BFS)
- Depth-first search (DFS)

Example
Here is the implementation of ToT using BFS. Since ToT forms a tree structure, applying BFS means processing the tree level by level. For each level, and for each node (i.e., state) within that level, we generate k candidate thoughts. Each thought is then evaluated together with the original problem, and only the top breadth states with the highest scores are retained for the next layer. This procedure is repeated for a total of size layers. Finally, the state with the highest score is selected, and its associated thought is returned as the answer.
import json
import re
from question import QUESTION
from utilities import llm
COT_PROMPT = """
Here are some examples of input-output pairs for solving simple reasoning problems.
Input:
John has 4 apples. He buys 3 more. How many apples does he have?
Output:
John has a total of 7 apples.
Input:
Alice has 10 candies. She gives 4 to Bob. How many candies does Alice have left?
Output:
Alice has 6 candies left.
Input:
Tom has 8 pencils. He loses 3 and buys 2 more. How many pencils does he have now?
Output:
Tom has 7 pencils now.
Now solve the following problem.
Input:
{input}
""".strip()
PROPOSE_PROMPT = """
{input}
Please propose {k} different possible outputs (answers) for the last Input.
Return them as a JSON list of strings, for example:
["...", "...", ...]
""".strip()
PROPOSE_WITH_ATTEMPT_PROMPT = """
{input}
Here is the current attempt at solving the problem:
{current_attempt}
You may refine, correct, or provide alternative outputs based on this attempt.
Please propose {k} different possible outputs (answers) for the last Input.
Return them as a JSON list of strings, for example:
["...", "...", ...]
""".strip()
VALUE_PROMPT = """
Evaluate how correct the following output is for the given input.
Input:
{input}
Output:
{output}
Give a score between 0 and 1, where:
- 1 means "definitely correct and consistent with the input"
- 0 means "definitely incorrect or inconsistent"
Return ONLY this JSON:
{{"value": <number>}}
""".strip()
def propose_prompt_wrap(question: str, current_attempt: str | None, k: int) -> str:
cot_question = COT_PROMPT.format(input=question)
if current_attempt:
prompt = PROPOSE_WITH_ATTEMPT_PROMPT.format(input=cot_question, current_attempt=current_attempt, k=k)
else:
prompt = PROPOSE_PROMPT.format(input=cot_question, k=k)
return prompt
def propose_thoughts(question: str, current_attempt: str | None, k: int) -> list[str]:
prompt = propose_prompt_wrap(question, current_attempt, k)
output = llm(prompt)
match = re.search(r"\[.*]", output, re.DOTALL)
if not match:
raise ValueError("No JSON list found in LLM output:\n" + output)
json_array = json.loads(match.group())
return [thought.strip() for thought in json_array if isinstance(thought, str) and thought.strip()]
def evaluate_thought(question: str, thought: str) -> float:
prompt = VALUE_PROMPT.format(input=question, output=thought)
output = llm(prompt)
match = re.search(r"\{.*}", output, re.DOTALL)
if not match:
raise ValueError("No JSON object found in LLM output:\n" + output)
obj = json.loads(match.group())
value = float(obj["value"])
return max(0.0, min(1.0, value))
def tot_bfs(question: str, step: int = 3, size: int = 3, breadth: int = 3) -> str:
current_attempts: list[str | None] = [None]
for d in range(step):
next_attempts = []
for attempt in current_attempts:
thoughts = propose_thoughts(question=question, current_attempt=attempt, k=size)
scored = []
for thought in thoughts:
score = evaluate_thought(question, thought)
scored.append((score, thought))
scored.sort(key=lambda x: x[0], reverse=True)
next_attempts.extend([t for _, t in scored[:breadth]])
current_attempts = next_attempts[:breadth]
return current_attempts[0]
if __name__ == "__main__":
answer = tot_bfs(QUESTION)
print(f"Tree-of-Thought, ToT\n\nQuestion:\n{QUESTION}\n\nAnswer:\n{answer}")
Limitations
The methods discussed above, CoT, SC, L2M, PAL, and ToT, differ in form, ranging from single-path reasoning to multi-sample aggregation, from decomposition-based reasoning to tree-structured search, and from language-only reasoning to program-assisted computation. Yet they all share a fundamental characteristic that is each is a prompting-based technique. In other words, none of these methods changes the underlying reasoning capabilities of an LLM. Instead, they manipulate the model’s behavior through prompt design, enabling the model to display its existing reasoning abilities in a clearer, more interpretable, or more structured manner.
However, the inherent limitations of prompt-based reasoning are equally clear. Different reasoning tasks require different prompt formats, different exemplars, and different structured templates. Any change in task type often necessitates a complete redesign of the prompt. Consequently, these methods do not constitute a general-purpose reasoning mechanism that can reliably transfer across tasks. Rather, they function more like heuristic usage patterns tailored to specific categories of problems. The quality of reasoning produced by an LLM ultimately depends on the precision of the prompt, not on the existence of any internal mechanism for controlling or verifying the reasoning process.
Conclusion
The development of CoT-style methods has helped us recognize that effective reasoning involves not only the inherent abilities of an LLM, but also the frameworks that guide and structure the reasoning process. Future research on reasoning will need to move beyond prompt-based techniques and toward higher-level, model-based reasoning approaches that offer controllability, verifiability, and cross-task generalization. Nonetheless, these early prompting-based methods remain foundational for understanding how LLMs perform reasoning, and they continue to provide essential conceptual groundwork for subsequent advances in the field.
References
- Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS 2022.
- Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-Consistency Improves Chain of Thought Reasoning in Language Models. In International Conference on Learning Representations, ICLR 2023.
- Denny Zhou, Nathanael Scharli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, and Ed Chi. 2023. Least-to-Most Prompting Enables Complex Reasoning in Large Language Models. 2023. In International Conference on Learning Representations, ICLR 2023.
- Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. PAL: Program-aided Language Models. In Proceedings of the 40th International Conference on Machine Learning, ICML 2023.
- Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS 2023.









