
Attention models have become a central concept in modern neural networks. Notably, popular architectures such as GPT models and Vision Transformers (ViT) are representative applications of attention models. This article will delve into the key attention mechanisms that underlie these models.
Table of Contents
Attention Mechanisms
Attention models were first introduced by Bahdanau et al. in 2015 for the task of machine translation. The attention mechanism proposed by Bahdanau is known as additive attention. In the same year, Luong et al. proposed three variants of attention mechanisms, among which dot product attention became the most widely used.
Later, in 2017, Vaswani et al. introduced the Transformer model. The self-attention and multi-head attention mechanisms in the Transformer are both based on scaled dot product attention.
In these three seminal papers, while the authors proposed formulas for computing attention, they rarely explained the motivation or mathematical foundations behind them in detail. This article focuses on analyzing the design logic and underlying principles of these formulas. As such, readers are expected to have basic familiarity with Bahdanau attention, Luong attention, and the Transformer architecture. If not, it is recommended to review the following articles before proceeding.


Queries, Keys, and Values
Suppose we have a database 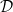 consisting of
consisting of  entries, where each entry is a pair of a key and a value. We define the database as:
entries, where each entry is a pair of a key and a value. We define the database as:

For example, consider a phone book as a database, represented as follows:
{("Smith","John"),("Johnson","Emily"),("Williams","David"),
("Brown","Sarah"),("Jones","Michael"),("Miller","Laura")}Now, if we issue a query to this phone book with the input  , the system returns the corresponding value “Michael.” If the system allows fuzzy matching (e.g., prefix matching), a query like
, the system returns the corresponding value “Michael.” If the system allows fuzzy matching (e.g., prefix matching), a query like  may return “David.”
may return “David.”
In other words, our goal is to predict a target value 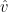 given a query
given a query  . A naïve estimator would be to simply take the average of all target values in the training data:
. A naïve estimator would be to simply take the average of all target values in the training data:

Nadaraya-Watson Estimator
In 1964, Nadaraya and Watson proposed a non-parametric regression model that estimates conditional expectations by performing a weighted average over sample data, without requiring knowledge of the underlying data distribution or model form:
![\hat{y}(x) \approx \mathbb{E}[Y \mid X = x]](https://s0.wp.com/latex.php?latex=%5Chat%7By%7D%28x%29+%5Capprox+%5Cmathbb%7BE%7D%5BY+%5Cmid+X+%3D+x%5D+&bg=ffffff&fg=000&s=1&c=20201002)
The corresponding estimator is given as follows, where  is a kernel function that measures the similarity between the query point
is a kernel function that measures the similarity between the query point  and the sample point
and the sample point  , thereby determining the weight assigned to the corresponding
, thereby determining the weight assigned to the corresponding  :
:

A common choice for the kernel function is the Gaussian kernel, defined as:

By using the Gaussian kernel as , sample points closer to the query receive higher weights, enabling a smooth and localized weighted estimation. Substituting this into the Nadaraya-Watson estimator gives the following formula:

Foundations of Attention
Attention mechanisms borrow the core idea from the Nadaraya-Watson estimator: using a weighted average to estimate a target value. We can incorporate this idea into a basic estimator as follows:

Here, the weighting function  encodes the relevance between the query and each sample key
encodes the relevance between the query and each sample key 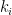 , and then uses that to compute a weighted combination of the corresponding values
, and then uses that to compute a weighted combination of the corresponding values 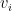 .
.
This forms the central intuition behind attention mechanisms: given a set of input Key-Value pairs, the model selectively attends to different keys based on a given Query (i.e., the current token of focus), and aggregates the values according to the resulting attention weights, producing a new semantic representation through weighted averaging.
We can therefore define attention over a database as:

Here,  represents the scalar attention weight assigned to the value . This operation is also known as attention pooling, where the term “attention” reflects the model’s focus on items with higher weights
represents the scalar attention weight assigned to the value . This operation is also known as attention pooling, where the term “attention” reflects the model’s focus on items with higher weights  . In other words, attention is a weighted linear combination over all the value vectors in the database .
. In other words, attention is a weighted linear combination over all the value vectors in the database .
In the earlier phone book example, a traditional query would assign a weight of 1 to a single entry and 0 to all others. However, in deep learning, it is more common to allow all weights to be non-negative and sum to 1:

To achieve such normalization, we introduce a scoring function  that computes unnormalized relevance scores, and a distribution function
that computes unnormalized relevance scores, and a distribution function  that normalizes these scores to produce the final attention weights:
that normalizes these scores to produce the final attention weights:

In deep learning, both the scoring function  and distribution function are typically chosen to be differentiable, so the entire model can be trained via backpropagation. One of the most common choices for is the softmax function, defined as:
and distribution function are typically chosen to be differentiable, so the entire model can be trained via backpropagation. One of the most common choices for is the softmax function, defined as:

Substituting this weighting function into the attention pooling formula yields the standard attention expression:

Since the database consists of Key-Value pairs, this is often written more explicitly as:

Most attention mechanisms in current use are variations of this formulation, differing mainly in the choice of attention scoring function . That is, the method used to measure the relevance between the query and each key  .
.
Additive Attention
In 2015, Bahdanau et al. proposed additive attention, in which the attention scoring function  is defined as follows. Here,
is defined as follows. Here, 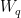 ,
,  , and
, and  are learnable parameters:
are learnable parameters:

The purpose of this scoring function is to measure the relevance (or more precisely, the compatibility) between a query and a key . In the context of Bahdanau attention, the key corresponds to the encoder hidden state  , while the query corresponds to the decoder’s previous hidden state
, while the query corresponds to the decoder’s previous hidden state  . This yields the following formulation:
. This yields the following formulation:

The resulting score  represents the compatibility between the decoder’s previous hidden state (at time step
represents the compatibility between the decoder’s previous hidden state (at time step  ) and the encoder hidden state .
) and the encoder hidden state .
Notably, this form of attention is conditional on the decoder’s prior hidden state , and aggregates representations across all positions in the encoder output.
It is important to observe that additive attention allows the model to learn the attention scoring function directly through its learnable parameters.
Additionally, although the terms relevance and compatibility are closely related, there is a subtle distinction in usage. When discussing the overall process involving queries, keys, and values, the term relevance is often used to describe whether a piece of information matches the query intent. In contrast, within the context of attention scoring functions, compatibility is more commonly used to describe the degree of alignment between the query and the key .
Dot Product Attention
Following additive attention, Luong et al. (2015) proposed dot product attention, where the attention scoring function is defined as:

In Luong attention, the key corresponds to the encoder hidden state , while the query corresponds to the decoder hidden state 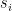 . Thus, the general form of dot product attention is:
. Thus, the general form of dot product attention is:

Unlike Bahdanau attention, dot product attention removes all learnable parameters and directly uses the dot product between the query and the key as the compatibility score. This design greatly simplifies computation and leads to significantly improved training efficiency.
However, a natural question arises: Why is  a valid measure of compatibility between and ? This design motivation can be understood from two perspectives:
a valid measure of compatibility between and ? This design motivation can be understood from two perspectives:
- The connection between dot product and the Gaussian kernel.
- The connection between dot product and cosine similarity.
Dot Product and Gaussian Kernel
Suppose we adopt a Gaussian kernel as the attention scoring function , and expand the squared distance term  as follows:
as follows:

The last term,  , depends only on the query , and is therefore constant across all
, depends only on the query , and is therefore constant across all  pairs. This constant term is canceled out during normalization (e.g., via softmax), and can be safely ignored.
pairs. This constant term is canceled out during normalization (e.g., via softmax), and can be safely ignored.
Additionally, layer normalization is often applied to the key vectors , which constrains their L2 norm  to a narrow range, often approximately constant. Hence, the second term
to a narrow range, often approximately constant. Hence, the second term  can also be neglected with minimal impact on the final attention scores.
can also be neglected with minimal impact on the final attention scores.
With both constant terms removed, the attention scoring function simplifies to:

This is precisely the formulation used in dot product attention. Therefore, dot product attention can be interpreted as a simplified version of Gaussian kernel attention.
For completeness, the L2 norm of a vector is defined as:

And layer normalization standardizes a feature vector to have zero mean and unit variance, via:

As a result, the output vectors have a stable distribution, and their L2 norms become nearly constant. This justifies the simplification of the Gaussian kernel into a dot product.
If you are not familiar with layer normalization, it is recommended to review the following article.

Dot Product and Cosine Similarity
We can also understand dot product attention through the lens of cosine similarity.
The angle  between two vectors and can be measured by the cosine of their angle:
between two vectors and can be measured by the cosine of their angle:

When the angle is close to 0°,  ; when the angle is 90°,
; when the angle is 90°,  ; when the angle is 180°,
; when the angle is 180°,  . This measure, known as cosine similarity, is commonly used to quantify the directional similarity between semantic vectors.
. This measure, known as cosine similarity, is commonly used to quantify the directional similarity between semantic vectors.
By multiplying both sides of the cosine similarity equation by the denominator  , we recover the dot product:
, we recover the dot product:

Thus, the dot product reflects both the directional similarity (through  ) and the magnitudes of the vectors. That is, when the vectors are aligned and have large magnitudes, the dot product becomes large.
) and the magnitudes of the vectors. That is, when the vectors are aligned and have large magnitudes, the dot product becomes large.
This raises a natural concern: Can vector magnitudes mislead the attention mechanism? In other words, does dot product sometimes assign higher attention weights due to larger magnitudes rather than true semantic similarity?
For instance, if the vector for orange is ![[1, 0]](https://s0.wp.com/latex.php?latex=%5B1%2C+0%5D&bg=ffffff&fg=000&s=0&c=20201002) and the vector for lemon is
and the vector for lemon is ![[2, 0]](https://s0.wp.com/latex.php?latex=%5B2%2C+0%5D&bg=ffffff&fg=000&s=0&c=20201002) , then:
, then:

Even though the meanings are similar, the difference in magnitude causes a skew in dot product attention.
In high-dimensional space, random vectors are nearly orthogonal, so it’s unlikely for two unrelated vectors to be perfectly aligned. In practice, embedding vectors are learned through a global loss function, and the model’s learnable parameters adjust both direction and magnitude to reflect semantic relationships more accurately. Moreover, many models apply layer normalization or project vectors onto the unit sphere to mitigate the effect of magnitude.
Scaled Dot Product Attention
In 2017, Vaswani et al. proposed scaled dot product attention, where the attention scoring function is defined as follows, with  denoting the dimensionality of the query vector :
denoting the dimensionality of the query vector :

Compared to the original dot product attention, this formulation introduces a scaling factor of  . The purpose of this scaling is to prevent the dot product values from becoming excessively large in high-dimensional spaces, which would cause the softmax output to become numerically unstable, leading to issues such as gradient explosion or vanishing gradients.
. The purpose of this scaling is to prevent the dot product values from becoming excessively large in high-dimensional spaces, which would cause the softmax output to become numerically unstable, leading to issues such as gradient explosion or vanishing gradients.
But why divide specifically by  ?
?
Suppose we have two -dimensional vectors  and
and 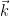 , and compute their dot product:
, and compute their dot product:

Assume that each element 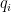 and is an independent random variable with mean zero and variance one (e.g., drawn from a Gaussian distribution
and is an independent random variable with mean zero and variance one (e.g., drawn from a Gaussian distribution  ). Then the product
). Then the product  has mean 0 and variance 1, since:
has mean 0 and variance 1, since:

Since the overall dot product is a sum of independent terms, its variance is:

In other words, the variance of  grows linearly with dimensionality . Without adjustment, this causes the inputs to the softmax function to have increasingly large magnitude in higher dimensions, which leads to sharp outputs. That is, the softmax becomes heavily peaked, assigning nearly all probability mass to a single element. This undermines gradient flow and impedes learning.
grows linearly with dimensionality . Without adjustment, this causes the inputs to the softmax function to have increasingly large magnitude in higher dimensions, which leads to sharp outputs. That is, the softmax becomes heavily peaked, assigning nearly all probability mass to a single element. This undermines gradient flow and impedes learning.
To stabilize the variance of the dot product to approximately 1, we simply divide by its standard deviation :

By scaling in this way, the values passed into the softmax function are normalized, which keeps the numerical range stable and improves the efficiency of learning the attention weights.
Therefore, the core motivation behind scaled dot product attention is to maintain a consistent variance of dot products across different dimensionalities, so that the softmax function remains effective and well-behaved during training.
Conclusion
Although the attention scoring functions in early research were often guided by intuition and lacked rigorous mathematical justification, revisiting their connections to kernel methods and similarity measures allows us to gain a deeper understanding of the underlying principles and rationale behind these formulations.
References
- Sneha Chaudhari, Varun Mithal, Gungor Polatkan, and Rohan Ramanath. 2021. An Attentive Survey of Attention Models. ACM Transactions on Intelligent Systems and Technology (TIST), Volume 12, Issue 5. No., 53, Pages 1 – 32. https://dl.acm.org/doi/10.1145/3465055.
- Aston Zhang, Zack C. Lipton, Mu Li, and Alex J. Smola. 2023, Dive into Deep Learning. Chapter 11: Attention Mechanisms and transformers.
- Dzmitry Bahdanau, KyungHyun Cho, and Yoshua Bengio. 2015. Neural Machine Translation by Jointly Learning to Align and Translate. In ICLR.
- Minh-Thang Luong, Hieu Pham, and Christopher Manning. 2015. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1412–1421.
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan Gomez,
Łukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. Advances in Neural Information Processing Systems 30.









