
When training neural networks, choosing a good optimizer is critically important. Adam is one of the most commonly used optimizers, so that it has almost become the default choice. Adam is built upon the foundations of SGD, Momentum, and RMSprop. By revisiting the evolution of these methods, we can better understand the principles behind Adam.
Table of Contents
- What are Optimizers?
- Stochastic Gradient Descent (SGD) Optimizer
- Exponential Moving Average (EMA)
- Momentum Optimizer
- RMSprop (Root Mean Square Prop) Optimizer
- Adam (Adaptive Moment Estimation) Optimizer
- L2 Regularization and Weight Decay
- AdamW (Adam with Decoupled Weight Decay) Optimizer
- Hyperparameters of AdamW
- Conclusion
- References
What are Optimizers?
In machine learning, training a model is essentially an optimization problem. The goal is to:
Find a set of parameters  that minimizes the loss function
that minimizes the loss function  .
.
This is a classic minimization problem in mathematics:

While this is similar to many traditional optimization problems, the loss function in machine learning is often high-dimensional, nonlinear, and non-convex. Moreover, the parameter space is typically very large.
Since we cannot analytically solve for the minimum of such complex functions, we rely on iterative methods like gradient descent to approximate the solution. An optimizer is essentially an algorithm that determines how the parameters should be updated at each step. It plays a central role in the training process.
For gradient descent-based optimizers, the main tasks are:
- Compute the gradient: Based on the current parameters
 , calculate the gradient of the loss function .
, calculate the gradient of the loss function . - Compute the update: Use the gradient and internal strategies (such as Adam) to compute the direction and magnitude of the update.
- Update the parameters: Apply the new parameters back to the model and continue to the next step.
 , calculate the gradient of the loss function
, calculate the gradient of the loss function  .
. back to the model and continue to the next step.
back to the model and continue to the next step.The job of an optimizer is not to learn directly, but to provide an efficient mechanism for updating the model’s parameters during learning. Given this role, you might think of it as a learner or converger, but from a mathematical perspective, the core of the task is still minimizing a function, that is precisely the focus of the field of optimization.
Stochastic Gradient Descent (SGD) Optimizer
Stochastic Gradient Descent (SGD) is the most fundamental optimization method. The core idea is simple:
Use the gradient of the loss function with respect to the parameters to take a step in the opposite direction, thereby reducing the loss.
The update formula is as follows:

where:
- : the model parameters.
- : the learning rate.
- : the current gradient.
 : the current gradient.
: the current gradient.In large datasets, we typically don’t compute the gradient over the entire dataset each time. Instead, we use small batches (mini-batches) of data. This is where the term stochastic comes fro. It refers to the randomness introduced by using only a subset of data at each step.
Exponential Moving Average (EMA)
Before diving into Momentum and Adam, it’s important to first understand Exponential Moving Average (EMA). The formula is as follows:

where:
- : the current value.
- : the exponentially weighted moving average.
- : the smoothing parameter.
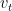 : the exponentially weighted moving average.
: the exponentially weighted moving average. : the smoothing parameter.
: the smoothing parameter.The influence of each value decays exponentially over time. More recent values have greater weight, while older values still contribute with diminishing influence. As a result, EMA can smooth out noise in data, such as occasional spikes in gradient, while still preserving overall trends.
Momentum Optimizer
The idea behind Momentum comes from the concept of momentum in physics. By combining EMA, it adds inertia to the gradient. The update formula is:

This method helps accelerate updates in directions where the gradient is consistently pointing the same way, and dampens oscillations in directions where the gradient fluctuates.
RMSprop (Root Mean Square Prop) Optimizer
Root Mean Square Prop (RMSprop) doesn’t focus on direction like Momentum does. Instead, it allows each parameter dimension to have its own adaptive learning rate. The update formula is:
![s_t = \beta s_{t-1} + (1 - \beta) [\nabla_\theta J(\theta)]^2 \\\\ \theta = \theta - \frac{\alpha}{\sqrt{s_t + \varepsilon}} \nabla_\theta J(\theta)](https://s0.wp.com/latex.php?latex=s_t+%3D+%5Cbeta+s_%7Bt-1%7D+%2B+%281+-+%5Cbeta%29+%5B%5Cnabla_%5Ctheta+J%28%5Ctheta%29%5D%5E2+%5C%5C%5C%5C+%5Ctheta+%3D+%5Ctheta+-+%5Cfrac%7B%5Calpha%7D%7B%5Csqrt%7Bs_t+%2B+%5Cvarepsilon%7D%7D+%5Cnabla_%5Ctheta+J%28%5Ctheta%29+&bg=ffffff&fg=000&s=1&c=20201002)
where:
- : the moving average of the squared gradients for each parameter dimension.
- : a small constant to avoid division by zero.
 : the moving average of the squared gradients for each parameter dimension.
: the moving average of the squared gradients for each parameter dimension.The square root operation causes updates to shrink automatically in dimensions with large gradients, while still allowing small gradient dimensions to update meaningfully. RMSprop enables the learning rate to adapt individually for each dimension, which helps reduce oscillations and improves convergence, especially when gradient magnitudes vary greatly across parameters.
Adam (Adaptive Moment Estimation) Optimizer
Adaptive Moment Estimation(Adam) combines the ideas of Momentum and RMSprop. It simultaneously tracks the exponentially weighted average of the gradient (like Momentum) and the squared gradient (like RMSprop):
![m_t = \beta_1 m_{t-1} + (1 - \beta_1) \nabla_\theta J(\theta) \\\\ v_t = \beta_2 v_{t-1} + (1 - \beta_2) [\nabla_\theta J(\theta)]^2](https://s0.wp.com/latex.php?latex=m_t+%3D+%5Cbeta_1+m_%7Bt-1%7D+%2B+%281+-+%5Cbeta_1%29+%5Cnabla_%5Ctheta+J%28%5Ctheta%29+%5C%5C%5C%5C+v_t+%3D+%5Cbeta_2+v_%7Bt-1%7D+%2B+%281+-+%5Cbeta_2%29+%5B%5Cnabla_%5Ctheta+J%28%5Ctheta%29%5D%5E2+&bg=ffffff&fg=000&s=1&c=20201002)
However, these estimates are biased toward zero in the early steps, especially when t is small. To correct for this, Adam applies bias correction:

This design allows Adam to automatically adjust the step size for each parameter, leading to fast and stable convergence.
L2 Regularization and Weight Decay
L2 Regularization
When training neural networks, we want the model to avoid memorizing the training data too closely, as known as overfitting. To encourage the model to learn smoother, more generalizable solutions, we often add a regularization term to the loss function. The most common form is L2 regularization.
L2 regularization penalizes the squared values of the parameters:

where:
- : the original loss function.
- : the regularization coefficient that controls the strength of the penalty.
- : the model parameters.
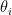 : the model parameters.
: the model parameters.This penalty encourages the model to find solutions with smaller weights, which reduces reliance on any single input feature and helps prevent overfitting.
Weight Decay
In practice, L2 regularization can be implemented either by modifying the loss function directly or by adjusting the parameter update rule. The latter is called weight decay:

This formula is mathematically equivalent to L2 regularization in SGD. The term  is added directly to the gradient, causing the weights to shrink slightly with each update. Hence, it is called weight decay.
is added directly to the gradient, causing the weights to shrink slightly with each update. Hence, it is called weight decay.
In Adam, L2 Regularization ≠ Weight Decay!
While L2 regularization and weight decay are equivalent in standard SGD, this is not the case with Adam.
Adam updates parameters not just based on the raw gradient but also by applying bias-corrected smoothing and per-parameter adaptive scaling. In other words, the learning rate is different for each dimension.
If you apply L2 regularization by adding to the loss function (or directly into the gradient), that penalty will also be subject to Adam’s adaptive scaling and momentum. As a result, the regularization effect gets distorted, and some parameters may be over-penalized, while others are barely affected. This unintended behavior breaks the original purpose of regularization.
AdamW (Adam with Decoupled Weight Decay) Optimizer
To address the issue described above, Adam with decoupled weight decay (AdamW) was proposed in 2017. It separates the weight decay term from the gradient computation and applies it directly to the parameters:

The benefit of this approach is that the regularization effect is no longer influenced by the gradient momentum or adaptive scaling. It also allows the strength of regularization to be controlled independently. This correction restores the intended behavior of weight decay. In practice, frameworks like PyTorch now include AdamW as a built-in optimizer, and it has gradually replaced the original Adam as the standard choice in modern training.
Hyperparameters of AdamW
The AdamW formula involves several hyperparameters, and it can be unclear how to set them when you’re just getting started. Below are some commonly used values:
| Parameters | Descriptions | Commonly used values |
|---|---|---|
 | Learning Rate | 0.001 |
 | Momentum | 0.9 |
 | RMSprop | 0.999 |
 | Prevent division by 0 |  |
 | Weight Decay | 0.01 |
Here is an example of initializing AdamW in PyTorch:
from torch.optim import AdamW
optimizer = AdamW(
model.parameters(),
lr=1e-3,
betas=(0.9, 0.999),
eps=1e-8,
weight_decay=0.01
)Conclusion
Adam is the result of several generations of optimizer evolution, combining the directional stability of Momentum with the adaptive learning rate mechanism of RMSprop. It has become a mainstream choice thanks to its fast convergence and strong adaptability. AdamW goes a step further by resolving the issue of ineffective L2 regularization in Adam, making it one of the most reliable optimizers for modern neural network training.
References
- Andrew Ng, Deep Learning Specialization, Coursera.









