
Over the past decade in the field of Natural Language Processing (NLP), the Generative Pre-trained Transformer (GPT) has undoubtedly been one of the most iconic technologies. GPT has not only redefined the approach to language modeling but also sparked a revolution centered around pre-training, leading to the rise of general-purpose language models. This article begins with an overview of the GPT architecture and delves into the design principles and technological evolution from GPT-1 to GPT-3.
The complete code for this chapter can be found in .
Table of Contents
GPT Architecture
GPT stands for Generative Pre-trained Transformers. As the name suggests, it is based on the Transformer architecture. If you are not familiar with Transformers, please refer the following article first.

However, GPT only uses the decoder portion of the Transformer, as shown in the diagram below. Since the encoder is not used, the design for cross multi-head attention is also removed.
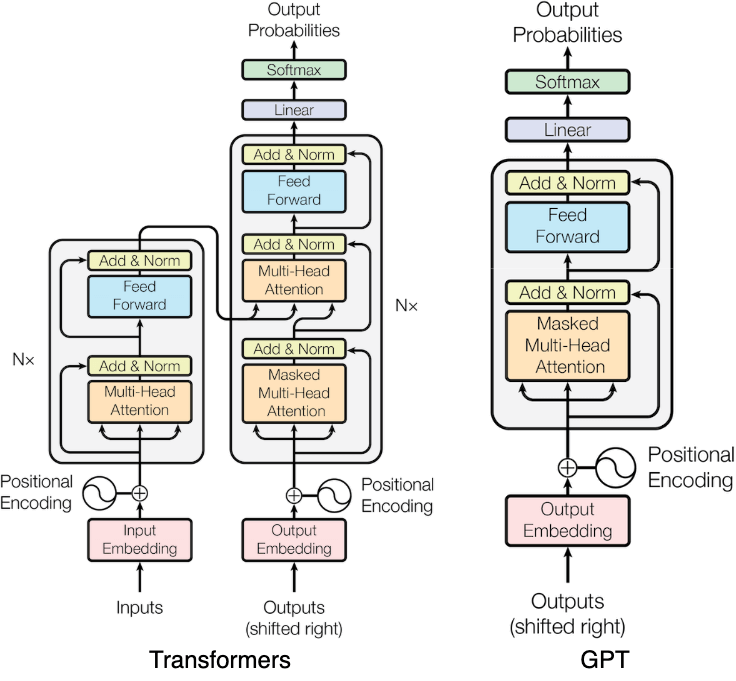
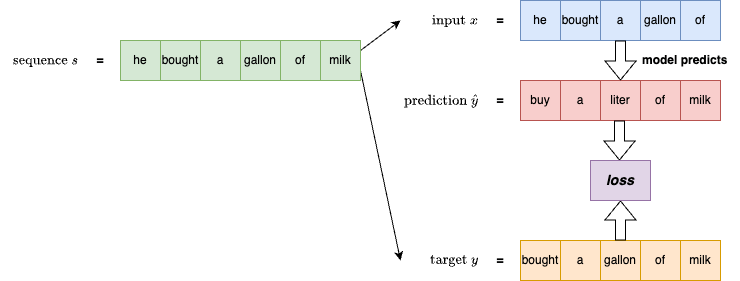
The language modeling objective adopted by GPT is to predict the next token, a method known as causal language modeling. As illustrated in the figure below, the left side shows a pre-training sequence  . The first n-1 tokens of the sequence (s[:-1]) are used as input to the model, and the subsequent n-1 tokens (s[1:]) are used as targets. The model learns to predict the next token from the input, computes the loss based on prediction errors, and updates its parameters accordingly. This type of model is also referred to as a next-token language model.
. The first n-1 tokens of the sequence (s[:-1]) are used as input to the model, and the subsequent n-1 tokens (s[1:]) are used as targets. The model learns to predict the next token from the input, computes the loss based on prediction errors, and updates its parameters accordingly. This type of model is also referred to as a next-token language model.
This training approach is categorized as unsupervised pre-training because it does not require labeled data. It addresses the common issue of limited annotated corpora by allowing us to train the model using large-scale unlabeled text. This not only enables the model to learn the statistical patterns of language but also equips it with a foundational understanding of world knowledge.
After completing the first stage of pre-training, the second stage involves fine-tuning the model for specific tasks, such as classification, question answering, and other downstream tasks. This two-stage design—first pre-training, then fine-tuning—not only provides the model with flexibility but also serves as a key factor behind the success of the GPT series.
Next, we will introduce the design principles and developmental progress of GPT-1, GPT-2, and GPT-3 respectively. Since the full details of GPT-3.5, GPT-4, and subsequent versions have not been publicly released (only technical reports and system cards are available), they will not be discussed here.
GPT-1
Many natural language understanding (NLU) tasks, such as textual entailment, question answering, semantic similarity assessment, and document classification, heavily rely on labeled data. However, such data is often scarce, making it difficult to train effective models. In contrast, unlabeled data is abundantly available.
Radford et al. in OpenAI therefore proposed a hypothesis: Is it possible to pre-train a large language model and achieve strong performance on downstream tasks with only minimal fine-tuning?
They proposed a semi-supervised learning framework consisting of two stages:
- Unsupervised Pre-training: A generative pre-training phase using large-scale unlabeled text data, allowing the language model to learn syntactic and semantic structures autonomously and to build universal representations of language.
- Supervised Fine-tuning: For each specific task, the pre-trained model is fine-tuned using a small amount of labeled data. This approach enables task transfer with minimal architectural modifications.
The advantage of this approach lies in its simplicity: unlike traditional methods that require a custom model for each task, GPT-1 can be broadly applied using only a standard language modeling structure. It was the first empirical study to demonstrate that a single language model can be transferred to various tasks through minimal fine-tuning, standing in clear contrast to the masked language modeling approach introduced by BERT around the same time.
GPT-1 adopts a decoder-only Transformer architecture with masked self-attention. Compared to the original Transformer architecture, the main differences are:
- It uses learned positional embeddings instead of sinusoidal position encoding.
- It employs GELU (Gaussian Error Linear Unit) as the activation function instead of ReLU.
The model specifications for GPT-1 are as follows, with approximately 117 million parameters:
- vocab_size: A vocabulary of around 40,000 tokens using Byte Pair Encoding (BPE).
- layers: 12-layer decoder-only Transformer.
- d_model: 768-dimensional hidden states per layer.
- heads: 12 attention heads per layer.
- d_ff: The position-wise feedforward networks are 3072-dimensional.
- context length: 512 tokens.
The training corpus was BooksCorpus, consisting of over 7000 unpublished books covering a wide range of topics and writing styles, totaling around 5GB. Such long-form, contiguous text is particularly beneficial for teaching the model long-range dependencies and contextual understanding.
Contributions of GPT-1:
- Proposed a language model training pipeline based on generative pre-training followed by discriminative fine-tuning.
- Demonstrated that the Transformer is effective at capturing long-range dependencies and can be applied to various downstream tasks.
- Established the architectural template and transfer learning paradigm for subsequent GPT models.
- Provided the first empirical evidence that language modeling can serve as a unified framework for multi-task transfer.
GPT-2
Although GPT-1 demonstrated strong performance, it still relied heavily on supervised fine-tuning for most tasks, limiting its ability to generalize across different tasks and domains. At the time, most systems were still “narrow specialists”, each trained for a specific task and unable to function across tasks.
Radford et al. in OpenAI further posed the question: Can a model solve downstream tasks using only pre-training, without any fine-tuning?
This became the core research objective of GPT-2, ushering in the era of unsupervised multitask learning. GPT-2 embeds task information directly into the training corpus instead of relying on downstream fine-tuning. Additionally, task instructions are treated as part of the input, using natural language prompts. This ensures alignment between training and inference, where both aim to predict the next token. GPT-2 integrates the task, input, and output into a single text sequence, fully aligned with the language modeling objective.
Radford et al. argued that the inability of traditional systems to generalize stemmed from limited training data that failed to capture diverse task formats. In response, they built a new dataset called WebText, comprising pages linked from Reddit posts with at least 3 karma points (used as a quality filter). This resulted in approximately 45 million web pages, totaling 40GB of text, emphasizing the authentic and diverse representation of task descriptions in natural language.
While GPT-2 pioneered prompt-based inference, its experiments primarily focused on zero-shot task performance. It did not yet explore one-shot or few-shot settings at scale—an effort later expanded and systematized by GPT-3. Thus, GPT-2 marked the beginning of the prompt paradigm, though it had not yet reached the full few-shot application stage.
The model specifications for GPT-2 are as follows, with approximately 1.5 billion parameters:
- vocab_size: 50,257 BPE tokens.
- layers: 48.
- d_model: 1600 dimensions.
- heads: 25 attention heads.
- d_ff: 6400 dimensions in the position-wise feedforward networks.
- context length: 1024 tokens.
GPT-2 adopts an architecture similar to GPT-1 but with several refinements. Notably, LayerNorm is moved to the beginning of each sub-block (pre-LM structure). It continues to use a decoder-only Transformer with self-attention only.
Contributions of GPT-2:
- Introduced the concept of prompt-based inference, where natural language prompts guide the model to perform tasks, replacing the need for fine-tuning.
- Framed language modeling as multitask learning, leveraging corpus design alone to expose the model to various task formats during training.
- Demonstrated that large models possess zero-shot capabilities. GPT-2 can perform tasks like question answering, translation, and summarization without any fine-tuning.
- Served as the precursor to GPT-3’s in-context learning architecture. Its experiments and design laid the groundwork for future few-shot learning models.
This generation of the model showcased the tremendous potential of language modeling as a general-purpose task framework, laying both the theoretical and empirical foundation for the emergence of GPT-3.
GPT-3
GPT-2 demonstrated the potential of performing various downstream tasks using pure language modeling training. However, it still had a limitation: when encountering entirely new tasks (those not present in the training data), additional fine-tuning was required for effective execution. Humans, on the other hand, can often understand and perform new tasks with just a few examples, or even through natural language instructions alone.
This led Brown et al. in OpenAI to propose a hypothesis: If a model is large enough and is exposed to sufficiently diverse task formats during training, could it learn new tasks at inference time using only prompts?
This became the core of GPT-3: in-context learning.
GPT-3’s architecture builds on GPT-2 but introduces interleaved dense and locally banded sparse attention, striking a balance between training efficiency and resource allocation. The training emphasized data diversity and quality, with a corpus totaling 570GB that includes Common Crawl (strictly filtered), WebText, Books1, Books2, and Wikipedia. Unlike traditional supervised fine-tuning, GPT-3 relies solely on massive text sequences to learn task logic and structure.
The model specifications for GPT-3 are as follows, with approximately 175 billion parameters:
- vocab_size: 50,257 BPE tokens.
- layers: 96.
- d_model: 12,288 dimensions.
- heads: 96 attention heads.
- d_ff: 49,152 dimensions in the feedforward network.
- context length: 2048 tokens.
GPT-3 conducted experiments on multiple tasks using three in-context learning settings:
- Zero-shot learning: Providing only a task description, with no examples.
- One-shot learning: Providing a single example.
- Few-shot learning: Providing multiple examples (typically between 10 and 100).
The diagram below illustrates these three settings in comparison to traditional fine-tuning.

The results showed that few-shot learning performed best on most tasks, although in certain domains—such as commonsense reasoning—it still slightly underperformed compared to supervised fine-tuning baselines. This limitation is clearly acknowledged in the paper, reminding users to manage expectations based on the application scenario.
Contributions of GPT-3:
- Introduced in-context learning as a new learning paradigm. It does not rely on fine-tuning or parameter updates, but instead learns task patterns purely through prompts.
- Demonstrated that scale is all you need. With a sufficiently large model, capabilities can emerge naturally.
- Transformed the way LLMs are used, shifting from model fine-tuning to prompt engineering, where users solve tasks by designing input formats instead of retraining models.
- Established a quantitative benchmark for few-shot learning, sparking a wave of systematic research into few-shot capabilities of large models, later carried forward by the ChatGPT.
This generation of models marked the realization of LLMs as general-purpose engines, making a profound impact on the advancement of LLM technology.
Model Comparison
The table below summarizes the model configurations and training corpus sizes for GPT-1, GPT-2, and GPT-3. As shown, from GPT-1 to GPT-3, both parameter count and data scale grew exponentially, leading to leapfrog improvements in model capabilities. However, training such models incurs extremely high costs, making it unaffordable for individuals or most organizations.
| Model | Model Size | Corpus Size | vocab_size | layers | d_model | heads | d_ff | ctx_len |
|---|---|---|---|---|---|---|---|---|
| GPT-1 | 117 M | 5 G | 40,000 | 12 | 768 | 12 | 3,072 | 512 |
| GPT-2 | 1.5 B | 40 G | 50,257 | 48 | 1,600 | 25 | 6,400 | 1,024 |
| GPT-3 | 175 B | 570 G | 50,257 | 96 | 12,288 | 96 | 49,152 | 2,048 |
Implementation
Although GPT-3 is not open-sourced, OpenAI did release the source code for GPT-2, which serves as an excellent reference for learning its architecture. The official implementation of GPT-2 uses TensorFlow, but in this section, we will reimplement it in PyTorch and explain its key components.
Model Architecture
GPT is a decoder-only Transformer model. Its basic structure is similar to the decoder in the standard Transformer architecture. Therefore, if you’re not yet familiar with Transformers, please refer to the following articles first.
Below is the implementation of GPT-2. The input consists of a sequence of token IDs, combined with learned position embeddings. Each layer performs attention and feedforward network (FFN) operations, followed by LayerNorm and residual connections.
class CausalSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
assert config.d_model % config.n_head == 0
self.n_head = config.n_head
self.d_head = config.d_model // config.n_head
self.W_q = nn.Linear(config.d_model, config.d_model)
self.W_k = nn.Linear(config.d_model, config.d_model)
self.W_v = nn.Linear(config.d_model, config.d_model)
self.W_o = nn.Linear(config.d_model, config.d_model)
self.attention_dropout = nn.Dropout(config.attention_dropout_prob)
self.residual_dropout = nn.Dropout(config.residual_dropout_prob)
attention_mask = (torch.tril(torch.ones(config.n_positions, config.n_positions))
.view(1, 1, config.n_positions, config.n_positions))
self.register_buffer("attention_mask", attention_mask, persistent=False)
def forward(self, x):
"""
Causal self-attention forward pass.
Args
----
x: (batch_size, seq_len, d_model)
Returns
-------
output: (batch_size, seq_len, d_model)
"""
batch_size, seq_len, _ = x.shape
# (batch_size, seq_len, d_model) for Q, K, V
Q = self.W_q(x)
K = self.W_k(x)
V = self.W_v(x)
# (batch_size, n_head, seq_len, d_head) for Q, K, V
Q = Q.view(batch_size, seq_len, self.n_head, self.d_head).transpose(1, 2)
K = K.view(batch_size, seq_len, self.n_head, self.d_head).transpose(1, 2)
V = V.view(batch_size, seq_len, self.n_head, self.d_head).transpose(1, 2)
# Causal mask: we only allow attention to current and previous positions
mask = self.attention_mask[:, :, :seq_len, :seq_len]
attention, attention_weights = self.scaled_dot_product_attention(Q, K, V, mask)
attention = attention.transpose(1, 2).contiguous() # (batch_size, seq_len, n_head * d_head)
attention = attention.view(batch_size, seq_len, -1) # (batch_size, seq_len, d_model)
# Linear projection
output = self.W_o(attention)
output = self.residual_dropout(output)
return output
def scaled_dot_product_attention(self, Q, K, V, mask):
scores = Q @ K.transpose(-2, -1) / math.sqrt(self.d_head) # (batch_size, n_head, seq_len, seq_len)
scores = scores.masked_fill(mask == 0, float('-inf'))
weights = torch.softmax(scores, dim=-1) # (batch_size, n_head, seq_len, seq_len)
weights = self.attention_dropout(weights)
attention = weights @ V # (batch_size, n_head, seq_len, d_head)
return attention, weights
class FeedForward(nn.Module):
def __init__(self, config):
super().__init__()
self.linear1 = nn.Linear(config.d_model, config.d_ff)
self.activation = nn.GELU()
self.linear2 = nn.Linear(config.d_ff, config.d_model)
self.dropout = nn.Dropout(config.residual_dropout_prob)
def forward(self, x):
"""
Feed-forward network forward pass.
Args
----
x: (batch_size, seq_len, d_model)
Returns
-------
x: (batch_size, seq_len, d_model)
"""
return self.dropout(self.linear2(self.activation(self.linear1(x))))
class GPT2Block(nn.Module):
def __init__(self, config):
super().__init__()
self.layer_norm1 = nn.LayerNorm(config.d_model, eps=config.layer_norm_epsilon)
self.attention = CausalSelfAttention(config)
self.layer_norm2 = nn.LayerNorm(config.d_model, eps=config.layer_norm_epsilon)
self.ffn = FeedForward(config)
def forward(self, x):
"""
Transformer block forward pass.
Args
----
x: (batch_size, seq_len, d_model)
Returns
-------
x: (batch_size, seq_len, d_model)
"""
x = x + self.attention(self.layer_norm1(x))
x = x + self.ffn(self.layer_norm2(x))
return x
class GPT2Model(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.wte = nn.Embedding(config.vocab_size, config.d_model)
self.wpe = nn.Embedding(config.n_positions, config.d_model)
self.dropout = nn.Dropout(config.embedding_dropout_prob)
self.blocks = nn.ModuleList([GPT2Block(config) for _ in range(config.n_layer)])
self.layer_norm = nn.LayerNorm(config.d_model, eps=config.layer_norm_epsilon)
self.apply(self._init_weights)
def _init_weights(self, module):
if isinstance(module, nn.Linear):
nn.init.normal_(module.weight, std=self.config.initializer_range)
if module.bias is not None:
nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
nn.init.normal_(module.weight, std=self.config.initializer_range)
def forward(self, input_ids, position_ids=None):
"""
Model forward pass.
Args
----
input_ids: (batch_size, seq_len)
position_ids: (batch_size, seq_len)
Returns
-------
hidden_states: (batch_size, seq_len, d_model)
"""
batch_size, seq_len = input_ids.shape
if position_ids is None:
position_ids = torch.arange(seq_len, device=input_ids.device).unsqueeze(0).expand(batch_size, -1)
hidden_states = self.dropout(self.wte(input_ids) + self.wpe(position_ids))
for block in self.blocks:
hidden_states = block(hidden_states)
return self.layer_norm(hidden_states)The output from the final layer is passed through a linear projection to match the vocabulary size, which is used to predict the next token. When computing the loss, the logits are aligned with the labels, meaning the input is shifted one token to the right.
class GPT2LMHeadModel(nn.Module):
def __init__(self, config):
super().__init__()
self.transformer = GPT2Model(config)
self.lm_head = nn.Linear(config.d_model, config.vocab_size, bias=False)
self.lm_head.weight = self.transformer.wte.weight # weight tying
def forward(self, input_ids, labels=None):
"""
Language model forward pass.
Args
----
input_ids: (batch_size, seq_len)
labels: (batch_size, seq_len)
Returns
-------
logits: (batch_size, seq_len, vocab_size)
loss: (optional) cross-entropy loss
"""
hidden_states = self.transformer(input_ids)
logits = self.lm_head(hidden_states)
loss = None
if labels is not None:
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
loss = F.cross_entropy(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
return logits, lossIn the GPT-2 paper, Radford et al. compared several models with different configurations. The smallest configuration corresponds to the first set of parameters in the code snippet below. The largest configuration, also included below, is referred to as the GPT-2 model.
# Small config
@dataclass
class GPT2Config:
vocab_size: int = 50257
n_positions: int = 1024
d_model: int = 768
n_layer: int = 12
n_head: int = 12
d_ff: int = 3072
residual_dropout_prob: float = 0.1
embedding_dropout_prob: float = 0.1
attention_dropout_prob: float = 0.1
layer_norm_epsilon: float = 1e-5
initializer_range: float = 0.02
# Larget config
@dataclass
class GPT2Config:
vocab_size: int = 50257
n_positions: int = 1024
d_model: int = 1600
n_layer: int = 48
n_head: int = 25
d_ff: int = 6400
residual_dropout_prob: float = 0.1
embedding_dropout_prob: float = 0.1
attention_dropout_prob: float = 0.1
layer_norm_epsilon: float = 1e-5
initializer_range: float = 0.02Pre-training
Before implementing the pre-training phase of GPT, it is necessary to prepare a suitable training corpus. Given resource constraints, we chose to use the wikitext-2-raw-v1 dataset provided by Hugging Face, which is about 10MB in size. Although much smaller than the WebText dataset used in the GPT-2 paper, it is sufficient for observing the model’s behavior.
from pathlib import Path
from datasets import load_dataset
ds = load_dataset("wikitext", "wikitext-2-raw-v1", split="train")
out_path = "wikitext2_train.txt"
out_path = Path(out_path); out_path.parent.mkdir(parents=True, exist_ok=True)
with out_path.open("w", encoding="utf‑8") as f:
for line in ds["text"]:
line = line.strip()
if line: # skip blank lines
f.write(line + "\n")
print("Wrote", out_path, "with", len(ds), "rows")The data processing pipeline involves first converting each line of text into a sequence of token IDs, then concatenating all token IDs into a single long sequence, and finally splitting it into fixed-length segments. Each segment serves as one training sample. This input setup is perfectly aligned with the training objective of causal language modeling. Using just CrossEntropyLoss, the model can learn to predict the next token.
class PretrainingDataset(Dataset):
def __init__(self, tokenizer, file_path: str, seq_len: int = 1024):
super().__init__()
self.seq_len = seq_len
all_ids: List[int] = []
with open(file_path, "r", encoding="utf-8") as f:
for line in f:
line = line.strip()
if not line:
continue
all_ids.extend(tokenizer.encode(line))
# drop the tail so we have an exact multiple of seq_len
total = len(all_ids) - (len(all_ids) % seq_len)
self.data = torch.tensor(all_ids[:total], dtype=torch.long).view(-1, seq_len)
def __len__(self):
return self.data.size(0)
def __getitem__(self, idx):
x = self.data[idx]
return x, xFinally, the following is the pre-training workflow. This pre-training process is also applicable to GPT-3. Although GPT-3 differs from GPT-2 in some architectural details, their overall structure and training methodology are fundamentally the same—both belong to the category of next-token language models.
def get_tokenizer():
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token # GPT‑2 has no pad token; reuse <EOS>
return tokenizer
def train_loop(model, dataloader, epochs: int, lr: float, save_dir: Path):
opt = torch.optim.AdamW(model.parameters(), lr=lr, betas=(0.9, 0.999), weight_decay=0.01)
scheduler = torch.optim.lr_scheduler.LinearLR(
opt, start_factor=1.0, end_factor=0.0, total_iters=len(dataloader) * epochs
)
global_step = 0
best_loss = float("inf")
save_dir.mkdir(parents=True, exist_ok=True)
for epoch in range(1, epochs + 1):
model.train()
running_loss = 0.0
for batch_idx, (input_ids, labels) in enumerate(dataloader):
sys.stdout.write(f"\rEpoch {epoch} Batch {batch_idx} / {len(dataloader)}")
sys.stdout.flush()
opt.zero_grad()
_, loss = model(input_ids, labels=labels)
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), 1.0)
opt.step()
scheduler.step()
running_loss += loss.item()
global_step += 1
avg_loss = running_loss / len(dataloader)
print(f",\ttrain_loss={avg_loss:.4f}")
# simple checkpointing
torch.save(model.state_dict(), save_dir / "last.pt")
if avg_loss < best_loss:
best_loss = avg_loss
torch.save(model.state_dict(), save_dir / "best.pt")
def pretrain():
tokenizer = get_tokenizer()
dataset = PretrainingDataset(tokenizer, "wikitext2_train.txt")
dataloader = DataLoader(dataset, batch_size=8, sampler=RandomSampler(dataset))
model = GPT2LMHeadModel(GPT2Config())
train_loop(model, dataloader, epochs=5, lr=2.5e-4, save_dir=Path("./model"))
pretrain()
# Output:
Epoch 1 Batch 286 / 287, train_loss=6.9670
Epoch 2 Batch 286 / 287, train_loss=6.1676
Epoch 3 Batch 286 / 287, train_loss=5.8620
Epoch 4 Batch 286 / 287, train_loss=5.6536
Epoch 5 Batch 286 / 287, train_loss=5.5112Sampling
After pre-training, we can use the model for text generation. This has a wide range of applications, such as dialogue systems, text completion, and article writing. In the code, we use commonly adopted techniques like temperature, top_k, and top_p, which function as follows:
- temperature: Adjusts the smoothness of the logits. Applied as logits / temperature before softmax.
- temperature > 1: Increases randomness (flattens the distribution).
- temperature < 1: Reduces randomness (sharpens the distribution).
- top_k: Keeps only the top-k tokens with the highest probabilities and sets all others to −∞, preventing the selection of low-probability tokens.
- top_p: Selects the smallest subset of tokens whose cumulative probability exceeds p, and sets the rest to −∞.
These strategies help strike a balance between controlled output quality and creative generation.
def sample(
model: GPT2LMHeadModel, tokenizer, prompt: str, max_new_tokens: int = 100,
temperature: float = 1.0, top_k: int = 0, top_p: float = 0.9,
) -> str:
model.eval()
with torch.no_grad():
input_ids = torch.tensor([tokenizer.encode(prompt)])
for _ in range(max_new_tokens):
logits, _ = model(input_ids[:, -model.transformer.config.n_positions:])
logits = logits[:, -1, :] / max(temperature, 1e-5)
if top_k > 0:
top_k = min(top_k, logits.size(-1))
kth_vals = torch.topk(logits, top_k)[0][..., -1, None]
logits = logits.where(logits >= kth_vals, torch.full_like(logits, -float("inf")))
if top_p < 1.0:
sorted_logits, sorted_idx = torch.sort(logits, descending=True)
sorted_probs = torch.softmax(sorted_logits, dim=-1)
cumprobs = sorted_probs.cumsum(dim=-1)
keep_mask = cumprobs <= top_p
keep_mask[..., 0] = True # always keep the best token
remove_idx = sorted_idx[~keep_mask]
logits[0, remove_idx] = -float("inf")
probs = torch.softmax(logits, dim=-1)
if torch.isnan(probs).any() or torch.isinf(probs).any():
next_token = torch.argmax(logits, dim=-1, keepdim=True)
else:
next_token = torch.multinomial(probs, num_samples=1)
input_ids = torch.cat([input_ids, next_token], dim=-1)
if next_token.item() == tokenizer.eos_token_id:
break
return tokenizer.decode(input_ids[0], skip_special_tokens=True)
def generate(model_path):
model = GPT2LMHeadModel(GPT2Config())
model.load_state_dict(torch.load(model_path, map_location="cpu", weights_only=True))
tokenizer = get_tokenizer()
prompt = "Q: What is Valkyria Chronicles? A:"
output = sample(model, tokenizer, prompt, max_new_tokens=100, temperature=1.0, top_k=0, top_p=0.9)
print(f"Prompt=> {prompt}")
print(f"Output=> {output}")
generate("./model/best.pt")Fine-tuning
Although zero-shot and in-context learning are emphasized, the GPT architecture and training methodology still support the fine-tuning mechanism.
There are two main applications of fine-tuning:
- Continued Pre-training: Conducting additional pre-training on new unlabeled corpora to help the model learn domain-specific language patterns (e.g., medical or legal texts).
- Supervised Fine-tuning: Using labeled data to fine-tune the model for specific tasks such as sentiment analysis, question answering, or dialogue generation.
Both approaches are widely used in industry and play a crucial role in workflows such as instruction tuning and RLHF (reinforcement learning from human feedback).
In practice, it is sufficient to reformat a downstream task into a textual input (prompt) and target output (label) to fine-tune a pre-trained model.
The code below demonstrates how to fine-tune a pre-trained model.
fine_tuning_examples = [
{"prompt": "Q: Who wrote Frankenstein?", "response": "Mary Shelley."},
{"prompt": "Translate to Spanish: Hello!", "response": "Hola!"},
{"prompt": "Summarize: GPT‑2 is", "response": "GPT‑2 is a language model released by OpenAI."}
]
class PromptResponseDataset(Dataset):
def __init__(self, tokenizer, json: list[dict[str, str]], seq_len: int = 1024, eos_token: str = "\n"):
self.seq_len = seq_len
examples: List[torch.Tensor] = []
for obj in json:
text = obj["prompt"] + eos_token + obj["response"] + eos_token
tokens = tokenizer.encode(text)[: seq_len]
padding = [tokenizer.eos_token_id] * (seq_len - len(tokens))
examples.append(torch.tensor(tokens + padding, dtype=torch.long))
self.data = torch.stack(examples)
def __len__(self):
return self.data.size(0)
def __getitem__(self, idx):
x = self.data[idx]
return x, x
def fine_tune():
tokenizer = get_tokenizer()
dataset = PromptResponseDataset(tokenizer, fine_tuning_examples)
dataloader = DataLoader(dataset, batch_size=4, sampler=RandomSampler(dataset))
model = GPT2LMHeadModel(GPT2Config())
model.load_state_dict(torch.load("./model/best.pt", map_location="cpu", weights_only=True))
train_loop(model, dataloader, epochs=5, lr=2.5e-4, save_dir=Path("./model_fine_tuned"))
fine_tune()The following code uses a fine-tuned model to generate text.
def generate(model_path):
model = GPT2LMHeadModel(GPT2Config())
model.load_state_dict(torch.load(model_path, map_location="cpu", weights_only=True))
tokenizer = get_tokenizer()
prompt = "Q: Who wrote Frankenstein? A:"
output = sample(model, tokenizer, prompt, max_new_tokens=100, temperature=1.0, top_k=0, top_p=0.9)
print(f"Prompt=> {prompt}")
print(f"Output=> {output}")
generate("./model_fine_tuned/best.pt")Calculating Model Size
Understanding the number of model parameters is crucial for estimating resource requirements and deployment costs.
The GPT-2 model uses the following configuration:
@dataclass
class GPT2Config:
vocab_size: int = 50257
n_positions: int = 1024
d_model: int = 1600
n_layer: int = 48
n_head: int = 25
d_ff: int = 6400
residual_dropout_prob: float = 0.1
embedding_dropout_prob: float = 0.1
attention_dropout_prob: float = 0.1
layer_norm_epsilon: float = 1e-5
initializer_range: float = 0.02By summing the parameters from each component of the model, we can estimate that the GPT-2 model contains approximately 156 million parameters, which corresponds to the 1.5B scale publicly disclosed by OpenAI. You can use a similar logic to estimate the parameter count of any Transformer model.
vocab_size = 50257
n_positions = 1024
d_model = 1600
d_ff = 6400
n_layer = 48
w_qkv = 3 * d_model * d_model
b_qkv = 3 * d_model
w_out, b_out = d_model * d_model, d_model
self_attention = w_qkv + b_qkv + w_out + b_out
print(f"self_attention={self_attention:,}") # 10,246,400
w1, b1 = d_model * d_ff, d_ff
w2, b2 = d_ff * d_model, d_model
feedforward = w1 + b1 + w2 + b2
print(f"feedforward={feedforward:,}") # 20,488,000
layer_norm_1_2 = 4 * d_model
block = self_attention + feedforward + layer_norm_1_2
print(f"block={block:,}") # 30,740,800
wte = vocab_size * d_model
wpe = n_positions * d_model
blocks = n_layer * block
layer_norm = 2 * d_model
model_params = wte + wpe + blocks + layer_norm
print(f"model_params = {model_params:,}") # 1,557,611,200 (~1.56 B)
Conclusion
Starting from GPT-1, which adopted a framework combining pre-training and fine-tuning, evolving into GPT-2, which relied solely on pre-training along with prompt-based inference, and further advancing to GPT-3, which realized a few-shot general-purpose model, the GPT series has fundamentally transformed the development direction of natural language processing.
Several key paradigm shifts have emerged:
- There is no longer a need to train separate models for each task. A unified architecture can handle a wide range of tasks.
- Language models now possess world knowledge and language understanding, making them directly applicable to both generation and reasoning.
- Prompt engineering has become the new programming paradigm. Humans have learned to communicate with models, rather than train them.
This evolution, from 117 million to 175 billion parameters, is not just about scaling up models; it reflects a deep exploration of language understanding and knowledge generalization. GPT has not only become the central engine of AI applications, but also challenges us to rethink the essence of learning itself.
References
- Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving Language Understanding by Generative Pre-Training. OpenAI.
- Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language Models are Unsupervised Multitask Learners. OpenAI.
- Tom B. Brown, Benjamin Mann, Nick Pyder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language Models are Few-Shot Learners. OpenAI.
- GPT-2 source code.









