
Transformer model was introduced by a team at Google Brain in 2017 and is a deep learning architecture that uses an attention mechanism. It solves significant challenges associated with traditional sequence namely capturing long-range dependencies and enabling more parallelizable computations.
The complete code for this chapter can be found in .
Table of Contents
Transformer Architecture
Like RNN models, the Transformer models process sequence data. Unlike RNN models, Transformer models can process all input data at once. Taking translation as an example, the RNN model only processes one word at a time, while the Transformer can process all words at once. This architecture allows parallel computing and therefore reduces training time.
Most of the best performing sequence models use an encoder-decoder architecture, which is also used by Transformer. The encoder converts the input sequence  into
into  , while the decoder gradually generates the output sequence
, while the decoder gradually generates the output sequence  . At each step of the decoder’s generation sequence, the model is auto-regressive, which means that when generating the next output, the previously generated output is used as an additional input.
. At each step of the decoder’s generation sequence, the model is auto-regressive, which means that when generating the next output, the previously generated output is used as an additional input.
The encoder is composed of a stack of N identical layers, and each layer contains two sub-layers. The first sub-layer is a multi-head self-attention mechanism. The second sub-layer is a position-wise fully connected feed-forward network. The output of each sub-layer is connected with residual connection and layer normalization.
The decoder is also composed of a stack of N identical layers, and each layer contains three sub-layers. In addition to the same two sub-layers as the encoder, the decoder adds a third sub-layer. This third sub-layer performs multi-head attention on the output of the encoder. Similar to the encoder, the output of each sub-layer is connected to the residual connection and layer normalization. In addition, in order to prevent a certain position from using information from subsequent positions when calculating attention, the decoder adds a masking mechanism to the multi-head attention. Through masking, and the design that the output embedding is offset by one position, it can be ensured that the prediction of position i can only depend on the information at the known (less than i) output positions.

Self-Attention
Attention is calculated from three values: query, keys, and values. When they all come from the same sequence, we call it self-attention. Attention has many calculation methods, and Transformer uses scaled dot-product attention, as shown below.

The function of scaled dot-product attention is as follows:

Self-attention dynamically weighs the importance of words in a sentence to each other, allowing the Transformer to capture context from all parts of the sentence simultaneously, build richer contextual representations, and capture long-distance dependencies without recurrent connections.
The following is the implementation of self-attention.
class MultiHeadAttention(nn.Module):
def scaled_dot_product_attention(self, Q, K, V, mask=None):
"""
Scaled dot-product attention.
Args
Q: (batch_size, h_heads, Q_len, d_k)
K: (batch_size, h_heads, K_len, d_k)
V: (batch_size, h_heads, V_len, d_v)
mask: (batch_size, 1, Q_len, K_len)
Returns
attention: (batch_size, h_heads, Q_len, d_v)
attention_weights: (batch_size, h_heads, Q_len, K_len)
"""
scores = Q @ K.transpose(-2, -1) / math.sqrt(self.d_k) # (batch_size, h_heads, Q_len, K_len)
if mask is not None:
scores = scores.masked_fill(mask == 0, float("-inf"))
attention_weights = torch.softmax(scores, dim=-1) # (batch_size, h_heads, Q_len, K_len)
attention = attention_weights @ V # (batch_size, h_heads, Q_len, d_v)
return attention, attention_weightsMulti-Head Attention
Multi-head attention is to project the query, keys, and values to  through different groups of linear projections of
through different groups of linear projections of  , and then perform attention function operations in parallel. Each attention function produces an output of dimension
, and then perform attention function operations in parallel. Each attention function produces an output of dimension  . Then, the output results of all heads are concatenated and subjected to a linear projection to obtain the final output result, as shown in the following figure.
. Then, the output results of all heads are concatenated and subjected to a linear projection to obtain the final output result, as shown in the following figure.

The function of multi-head attention is as follows:

Multi-head attention can capture different semantic levels in the input sequence at the same time, allowing Transformer to more accurately capture semantic and syntactic details, greatly improving the accuracy and expressiveness of the model.
The following is the implementation of multi-head attention.
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, h_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % h_heads == 0, "d_model must be divisible by h_heads"
self.d_model = d_model
self.h_heads = h_heads
self.d_k = d_model // h_heads
self.d_v = d_model // h_heads
self.W_q = nn.Linear(d_model, h_heads * self.d_k, bias=False) # (d_model, h_heads * d_k)
self.W_k = nn.Linear(d_model, h_heads * self.d_k, bias=False) # (d_model, h_heads * d_k)
self.W_v = nn.Linear(d_model, h_heads * self.d_v, bias=False) # (d_model, h_heads * d_v)
self.W_o = nn.Linear(h_heads * self.d_v, d_model, bias=False) # (h_heads * d_v, d_model)
def forward(self, q, k, v, mask=None):
"""
Multi-head attention forward pass.
Args
q: (batch_size, seq_len, d_model)
k: (batch_size, seq_len, d_model)
v: (batch_size, seq_len, d_model)
mask: (batch_size, 1, seq_len) or (1, seq_len, seq_len)
Returns
x: (batch_size, seq_len, d_model)
"""
batch_size, Q_len, _ = q.size()
batch_size, K_len, _ = k.size()
batch_size, V_len, _ = v.size()
# Linear projections
Q = self.W_q(q) # (batch_size, Q_len, h_heads * d_k)
K = self.W_k(k) # (batch_size, K_len, h_heads * d_k)
V = self.W_v(v) # (batch_size, V_len, h_heads * d_v)
Q = Q.view(batch_size, Q_len, self.h_heads, self.d_k).transpose(1, 2) # (batch_size, h_heads, Q_len, d_k)
K = K.view(batch_size, K_len, self.h_heads, self.d_k).transpose(1, 2) # (batch_size, h_heads, K_len, d_k)
V = V.view(batch_size, V_len, self.h_heads, self.d_v).transpose(1, 2) # (batch_size, h_heads, V_len, d_v)
# Scaled dot-product attention
if mask is not None:
mask = mask.unsqueeze(1)
attention, attention_weights = self.scaled_dot_product_attention(Q, K, V, mask=mask)
# Concatenate heads
attention = attention.transpose(1, 2).contiguous() # (batch_size, Q_len, h_heads, d_v)
attention = attention.view(batch_size, Q_len, self.d_model) # (batch_size, Q_len, d_model)
# Linear projection
output = self.W_o(attention) # (batch_size, Q_len, d_model)
return outputPositional Encoding
The Transformer model can process all input data at once. It does not use recurrence like RNN, nor does it use convolution. In order for the model to effectively utilize the sequential information in the sequence, we must inject some information about the relative or absolute position of each token in the sequence into the model. The Transformer model uses sine and cosine functions for positional encoding. It adds this positional encoding to the input word embeddings.
The positional encoding function is as follows:

Positional encoding introduces position information to words, allowing Transformer to effectively consider word order and context without relying on sequential processing.
The following is the implementation of positional encoding.
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model) # (max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # (max_len, 1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # (d_model // 2)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer("pe", pe)
def forward(self, x, start_pos=0):
"""
Add positional encoding to input tensor.
Args
x: (batch_size, seq_len, d_model)
start_pos: int
Returns
x: (batch_size, seq_len, d_model)
"""
seq_len = x.size(1)
x = x + self.pe[start_pos:start_pos + seq_len, :].unsqueeze(0)
return xPosition-wise Feed-Forward Neural Network
The position-wise feed-forward neural network is a fully connected feed-forward neural network. It performs the following linear transformations for each position. So each position uses the same parameters, but each layer uses different parameters.
The function of position-wise feed-forward neural network is as follows:

The position-wise feed-forward neural network performs nonlinear transformation on the attention output, enhancing the model’s ability to capture complex relationships in the data and improving the overall expressiveness and predictive capabilities of the model.
The following is an implementation of a position-wise feed-forward neural network.
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super(PositionwiseFeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, d_ff, bias=True)
self.linear2 = nn.Linear(d_ff, d_model, bias=True)
def forward(self, x):
"""
Position-wise feed forward pass.
Args
x: (batch_size, seq_len, d_model)
Returns
x: (batch_size, seq_len, d_model)
"""
return self.linear2(torch.relu(self.linear1(x)))Residual Connection and Layer Normalization
The output of each sub-layer is followed by a set of residual connections and layer normalization.
Residual connection can alleviate the gradient vanishing problem and realize deeper network structure. By allowing the gradient to flow more directly through the network, it promotes the training of deeper Transformer networks and significantly improves model performance and convergence speed. The implementation of residual connection is quite simple, as follows.
linear1 = nn.Linear(dim1, dim2) linear2 = nn.Linear(dim2, dim1) output = linear1(x) output = torch.relu(output) output = linear2(output) output = output + x output = torch.relu(output)
Layer normalization can stabilize and accelerate the training process, ensure that the gradient is more stable, the training converges faster, and improve the stability and efficiency of the model. We can use PyTorch’s LayerNorm directly.
norm = nn.LayerNorm(dim) x = norm(x)
Embeddings
In Transformer, the input embedding layer, the output embedding layer, and the linear transformation before softmax share the same set of weight matrices. Additionally, in embedding layers, it multiplies the weight matrix by  for scaling.
for scaling.
The following is the implementation of the shared embedding.
class SharedEmbedding(nn.Module):
def __init__(self, vocab_size, d_model):
super(SharedEmbedding, self).__init__()
self.vocab_size = vocab_size
self.d_model = d_model
self.embedding = nn.Embedding(vocab_size, d_model) # (vocab_size, d_model)
def forward(self, x):
"""
Shared embedding layer.
Args
x: (batch_size, seq_len)
Returns
x: (batch_size, seq_len, d_model)
"""
return self.embedding(x) * math.sqrt(self.d_model)Encoder
The figure below shows the encoder part, which consists of an embedding layer, a position encoding, and N identical layers.

The following is the implementation of N identical layers. When performing multi-head attention, it sets the query, keys, and values as the parameter x. In addition, since the parameter x may contain <PAD>, the parameter mask will indicate which are valid tokens (mask[i]=1) and which are <PAD> (mask[i]=0). Multi-head attention uses the parameter mask to mask out (set to 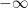 ) the tokens at these positions.
) the tokens at these positions.
class EncoderLayer(nn.Module):
def __init__(self, d_model, d_heads, d_ff):
super(EncoderLayer, self).__init__()
self.multi_head_attention = MultiHeadAttention(d_model, d_heads)
self.ffn = PositionwiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, x, mask=None):
"""
Encoder layer forward pass.
Args
x: (batch_size, src_len, d_model)
mask: (batch_size, 1, src_len)
Returns
x: (batch_size, src_len, d_model)
"""
# Multi-head attention
attention = self.multi_head_attention(x, x, x, mask=mask)
x = self.norm1(x + attention) # Residual connection and layer normalization
# Position-wise feed forward
ffn_output = self.ffn(x)
x = self.norm2(x + ffn_output) # Residual connection and layer normalization
return xThe following is the implementation of encoder. Where src is the entire input string.
class Encoder(nn.Module):
def __init__(self, shared_embedding, d_model, n_layers, h_heads, d_ff, max_len):
super(Encoder, self).__init__()
self.d_model = d_model
self.embedding = shared_embedding
self.positional_encoding = PositionalEncoding(d_model, max_len)
self.layers = nn.ModuleList([EncoderLayer(d_model, h_heads, d_ff) for _ in range(n_layers)])
def forward(self, src, src_mask=None):
"""
Encoder forward pass.
Args
src: (batch_size, src_len)
src_mask: (batch_size, 1, src_len)
Returns
x: (batch_size, src_len, d_model)
"""
x = self.embedding(src)
x = self.positional_encoding(x)
for layer in self.layers:
x = layer(x, mask=src_mask)
return xDecoder
The figure below shows the decoder part, which consists of an embedding layer, a position encoding, N identical layers, a linear transformation, and a softmax.

The following is the implementation of N identical layers. When performing multi-head attention, it sets the query, keys, and values as the parameter x. The parameter encoder_output is the final output of the encoder. Similar to EncoderLayer, the parameters tgt_mask and memory_mask are used to tell the multi-head attention which tokens to mask. The second multi-head attention is called cross multi-head attention because it sets the keys and values to encoder_output.
class DecoderLayer(nn.Module):
def __init__(self, d_model, d_heads, d_ff):
super(DecoderLayer, self).__init__()
self.masked_multi_head_attention = MultiHeadAttention(d_model, d_heads)
self.cross_multi_head_attention = MultiHeadAttention(d_model, d_heads)
self.ffn = PositionwiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
def forward(self, x, encoder_output, tgt_mask=None, memory_mask=None):
"""
Decoder layer forward pass.
Args
x: (batch_size, tgt_len, d_model)
encoder_output: (batch_size, src_len, d_model)
tgt_mask: (1, tgt_len, tgt_len)
memory_mask: (batch_size, 1, src_len)
Returns
x: (batch_size, tgt_len, d_model)
"""
# Mask multi-head attention
masked_attention = self.masked_multi_head_attention(x, x, x, mask=tgt_mask)
x = self.norm1(x + masked_attention)
# Cross multi-head attention
cross_attention = self.cross_multi_head_attention(x, encoder_output, encoder_output, mask=memory_mask)
x = self.norm2(x + cross_attention)
# Position-wise feed forward
ffn_output = self.ffn(x)
x = self.norm3(x + ffn_output)
return xThe following is the implementation of the decoder. Each time the decoder is called, it predicts a token, so it keeps being called until it outputs <EOS>. The parameter tgt is the total number of tokens that have been predicted. The parameter tgt_mask tells the multi-head attention which positions in the parameter tgt are predicted tokens. Previously, when calling encoder, there will be some in its parameter x, so it uses the parameter mask to mask out those <PAD>.
The parameter encoder_output is the output of the encoder, also called memory. The parameter memory_mask is used to tell cross multi-head attention how to use this memory. The input string of the encoder may contain <PAD>, so memory_mask is used to tell the cross multi-head attention which tokens in the memory to mask out.
class Decoder(nn.Module):
def __init__(self, shared_embedding, d_model, n_layers, h_heads, d_ff, vocab_size, max_len):
super(Decoder, self).__init__()
self.d_model = d_model
self.embedding = shared_embedding
self.positional_encoding = PositionalEncoding(d_model, max_len)
self.layers = nn.ModuleList([DecoderLayer(d_model, h_heads, d_ff) for _ in range(n_layers)])
self.output_linear = nn.Linear(d_model, vocab_size, bias=False)
self.output_linear.weight = self.embedding.embedding.weight
def forward(self, tgt, encoder_output, tgt_mask=None, memory_mask=None):
"""
Decoder forward pass.
Args
tgt: (batch_size, tgt_len)
encoder_output: (batch_size, src_len, d_model)
tgt_mask: (1, tgt_len, tgt_len)
memory_mask: (batch_size, 1, src_len)
Returns
logits: (batch_size, tgt_len, vocab_size)
"""
x = self.embedding(tgt)
x = self.positional_encoding(x)
for layer in self.layers:
x = layer(x, encoder_output, tgt_mask=tgt_mask, memory_mask=memory_mask)
logits = self.output_linear(x)
return logitsExample
We have implemented the encoder and decoder, and combining them is the Transformer model, as shown below.
class Transformer(nn.Module):
def __init__(self, vocab_size, d_model, n_layers, h_heads, d_ff, max_len):
super(Transformer, self).__init__()
shared_embedding = SharedEmbedding(vocab_size, d_model)
self.encoder = Encoder(shared_embedding, d_model, n_layers, h_heads, d_ff, max_len)
self.decoder = Decoder(shared_embedding, d_model, n_layers, h_heads, d_ff, vocab_size, max_len)
def forward(self, src, tgt, src_mask=None, tgt_mask=None, memory_mask=None):
"""
Transformer forward pass.
Args
src: (batch_size, src_len)
tgt: (batch_size, tgt_len)
src_mask: (batch_size, 1, src_len)
tgt_mask: (1, tgt_len, tgt_len)
memory_mask: (batch_size, 1, src_len)
"""
encoder_output = self.encoder(src, src_mask)
logits = self.decoder(tgt, encoder_output, tgt_mask, memory_mask)
return logitsNext, we will demonstrate how to train a Transformer model. First, we will prepare the training data. Set the dimension of the embedding, the number of identical layers in the encoder and decoder, the number of heads in the multi-head attention, the dimension of the learnable parameters in the position-wise feed-forward networks, and the length of the input and output strings.
data = [
("hello world", "hola mundo"),
("i love you", "te amo"),
("the cat is black", "el gato es negro"),
("good morning", "buenos dias"),
("this is a book", "este es un libro"),
("what is your name", "como te llamas"),
]
PAD_INDEX = 0
SOS_INDEX = 1
EOS_INDEX = 2
def build_single_vocab(pairs):
words = set()
for (src, tgt) in pairs:
for w in src.lower().split():
words.add(w)
for w in tgt.lower().split():
words.add(w)
vocab = ["<pad>", "<sos>", "<eos>"] + sorted(list(words))
tkn2idx = {tkn: idx for idx, tkn in enumerate(vocab)}
idx2tkn = {idx: tkn for tkn, idx in tkn2idx.items()}
return vocab, tkn2idx, idx2tkn
vocab, tkn2idx, idx2tkn = build_single_vocab(data)
vocab_size = len(vocab)
D_MODEL = 512
N_LAYERS = 6
H_HEADS = 8
D_FF = 2048
MAX_LEN = 20
EPOCHS = 100In the following code, we use the above dataset to train the model.
def sentence_to_idx(sentence, tkn2idx):
return [tkn2idx[w] for w in sentence.lower().split()]
def encode_pair(src, tgt, tkn2idx, max_len):
src_idx = sentence_to_idx(src, tkn2idx)
tgt_idx = sentence_to_idx(tgt, tkn2idx)
tgt_in_idx = [SOS_INDEX] + tgt_idx
tgt_out_idx = tgt_idx + [EOS_INDEX]
src_idx = src_idx[:max_len]
tgt_in_idx = tgt_in_idx[:max_len]
tgt_out_idx = tgt_out_idx[:max_len]
src_idx += [PAD_INDEX] * (max_len - len(src_idx))
tgt_in_idx += [PAD_INDEX] * (max_len - len(tgt_in_idx))
tgt_out_idx += [PAD_INDEX] * (max_len - len(tgt_out_idx))
return src_idx, tgt_in_idx, tgt_out_idx
def create_dataset(pairs, tkn2idx, max_len):
src_data, tgt_in_data, tgt_out_data = [], [], []
for (src, tgt) in pairs:
src_idx, tgt_in_idx, tgt_out_idx = encode_pair(src, tgt, tkn2idx, max_len)
src_data.append(src_idx)
tgt_in_data.append(tgt_in_idx)
tgt_out_data.append(tgt_out_idx)
return (
torch.tensor(src_data, dtype=torch.long),
torch.tensor(tgt_in_data, dtype=torch.long),
torch.tensor(tgt_out_data, dtype=torch.long),
)
def create_padding_mask(seq):
"""
Args
seq: (batch_size, seq_len)
Returns
mask: (batch_size, 1, seq_len) - 1 for valid token, 0 for padding token
"""
return (seq != PAD_INDEX).unsqueeze(1).long()
def create_subsequence_mask(size):
"""
Args
size: int
Returns
mask: (1, size, size) - 1 for valid token, 0 for padding token
"""
return torch.tril(torch.ones((size, size))).unsqueeze(0)
def train():
model = Transformer(vocab_size, D_MODEL, N_LAYERS, H_HEADS, D_FF, MAX_LEN)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
criterion = nn.CrossEntropyLoss(ignore_index=PAD_INDEX)
src_data, tgt_in_data, tgt_out_data = create_dataset(data, tkn2idx, MAX_LEN)
model.train()
for epoch in range(EPOCHS):
src_mask = create_padding_mask(src_data) # (batch_size, 1, MAX_LEN)
tgt_mask = create_subsequence_mask(tgt_in_data.size(1)) # (1, MAX_LEN, MAX_LEN)
memory_mask = create_padding_mask(src_data) # (batch_size, 1, MAX_LEN)
# (batch_size, MAX_LEN, vocab_size)
logits = model(src_data, tgt_in_data, src_mask=src_mask, tgt_mask=tgt_mask, memory_mask=memory_mask)
logits = logits.reshape(-1, vocab_size) # (batch_size * MAX_LEN, vocab_size)
tgt_out = tgt_out_data.reshape(-1) # (batch_size * MAX_LEN)
loss = criterion(logits, tgt_out)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 10 == 0:
print(f"Epoch [{epoch + 1}/{EPOCHS}], Loss: {loss.item():.4f}")
return modelAfter training the model, we can use the following code to translate English into Spanish.
def translate_beam_search(model, sentence, beam_width=3):
model.eval()
src_idx, _, _ = encode_pair(sentence, "", tkn2idx, MAX_LEN)
src_tensor = torch.tensor([src_idx], dtype=torch.long)
src_mask = create_padding_mask(src_tensor)
with torch.no_grad():
encoder_output = model.encoder(src_tensor, src_mask) # (batch_size, src_len, d_model)
memory_mask = create_padding_mask(src_tensor)
beam = [([SOS_INDEX], 0.0)]
completed_sentences = []
for i in range(MAX_LEN):
new_beam = []
for tokens, score in beam:
if tokens[-1] == EOS_INDEX:
completed_sentences.append((tokens, score))
new_beam.append((tokens, score))
continue
ys = torch.tensor([tokens], dtype=torch.long)
tgt_mask = create_subsequence_mask(ys.size(1))
with torch.no_grad():
# (batch_size, tgt_len, vocab_size)
logits = model.decoder(ys, encoder_output, tgt_mask=tgt_mask, memory_mask=memory_mask)
next_token_logits = logits[:, -1, :] # (batch_size, vocab_size)
log_probs = torch.log_softmax(next_token_logits, dim=1).squeeze(0)
topk = torch.topk(log_probs, beam_width)
for tkn_idx, tkn_score in zip(topk.indices.tolist(), topk.values.tolist()):
new_tokens = tokens + [tkn_idx]
new_score = score + tkn_score
new_beam.append((new_tokens, new_score))
new_beam.sort(key=lambda x: x[1], reverse=True)
beam = new_beam[:beam_width]
for tokens, score in beam:
if tokens[-1] != EOS_INDEX:
completed_sentences.append((tokens, score))
completed_sentences.sort(key=lambda x: x[1], reverse=True)
best_tokens, best_score = completed_sentences[0]
if best_tokens[0] == SOS_INDEX:
best_tokens = best_tokens[1:]
if EOS_INDEX in best_tokens:
best_tokens = best_tokens[:best_tokens.index(EOS_INDEX)]
return " ".join([idx2tkn[idx] for idx in best_tokens])if __name__ == "__main__":
test_sentences = [
"hello world",
"the cat is black",
"good morning",
"what is your name",
"this is a book",
"i love you",
"i love cat",
"this is a cat",
]
model = train()
for sentence in test_sentences:
translation = translate_beam_search(model, sentence)
print(f"Input: {sentence}, Translation: {translation}")Conclusion
Transformers are widely used in NLP, such as the GPT model and BERT. It represents a powerful evolution of neural network architecture and has profoundly impacted the efficiency, scalability, and capabilities of deep learning.
References
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan Gomez,
Łukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. Advances in Neural Information Processing Systems 30.









