
GloVe is a word embedding model that constructs word vectors based on global co-occurrence statistics. Unlike Word2Vec, which relies on local context windows, GloVe captures the overall statistical relationships between words through matrix factorization. This approach enables GloVe to generate high-quality word representations that effectively encode semantic and syntactic relationships. This article will introduce the principles and training methods of GloVe.
The complete code for this chapter can be found in .
Table of Contents
GloVe Model
GloVe is a word embeddings learning model proposed by J. Pennington et al. of Stanford in 2014. Unlike Word2Vec which uses the local context window method, GloVe uses the global matrix factorization method. It constructs word embeddings based on extracting statistical information from the word co-occurrence matrix. Therefore, GloVe can capture word relationships across the entire corpus through matrix factorization.
Building the Co-occurrence Matrix
A key idea in GloVe is that word meanings can be inferred from their co-occurrence probabilities.. Therefore, for GloVe, the co-occurrence matrix is very important. Co-occurrence refers to the number of times word j appears in the context of word i.
Suppose we have a corpus containing the following three sentences:
- I like deep learning.
- I like machine learning.
- Deep learning is powerful.
Assume that the size of the context window is 1, which means one word before and after. Then we can build the following co-occurrence matrix X. 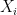 is row; is column.
is row; is column.  refers to the number of times word
refers to the number of times word j appears in the context of word i.
| I | like | deep | learning | machine | is | powerful | |
| I | – | 2 | 0 | 0 | 0 | 0 | 0 |
| like | 2 | – | 1 | 0 | 1 | 0 | 0 |
| deep | 0 | 1 | – | 2 | 0 | 0 | 0 |
| learning | 0 | 0 | 2 | – | 1 | 1 | 0 |
| machine | 0 | 1 | 0 | 1 | – | 0 | 0 |
| is | 0 | 0 | 0 | 1 | 0 | – | 1 |
| powerful | 0 | 0 | 0 | 0 | 0 | 1 | – |
We use the following notation to define the co-occurrence matrix.

Probability Ratios for Word Relationships
With the co-occurrence matrix, we can use it to define some word relationships. Let  be the probability that word
be the probability that word j appears in the context of word i.

For example, in the table above, the probability that “learning” appears in the context of “deep” is:

However, we cannot use to understand how word i and word j differ from other words when they appear together. Now we introduce another word k, then:
- When
kappears more frequently withithan withj, then .
. - When
kappears with similar frequency asiandj, then.
 .
. .
.Therefore, the ratio of co-occurrence probabilities  is a measure of how different
is a measure of how different i and j are relative to k. Therefore, GloVe’s word embeddings learn the ratio of co-occurrence probabilities rather than the co-occurrence probabilities themselves. Therefore, the ratio of co-occurrence probabilities can be expressed by the following model:

We want F to capture the ratio information of . The most natural way is to use the difference of vectors. Therefore, the above formula can be modified as follows:

Because the right side of the equation is a scalar, and the left side is a vector. Therefore, modify the formula to:

In the following formula, we set  as:
as:

Then, we can derive the following formula.

Finally, adding the additional bias, we get:

Loss Function
In the last equation above, we can see that it is very similar to the least squares method. GloVe proposes a new weighted least squares based on the above formula, as follows.

Where f is a weighting function, which is defined as follows:

J. Pennington et al. used  and
and  in the paper.
in the paper.
Final Word Embeddings
GloVe treats the co-occurrence matrix X as a symmetric matrix, that is  . Therefore, in theory, the information learned
. Therefore, in theory, the information learned  and
and  are equal. The two are slightly different in distribution space only because of different initialization. Therefore, the final output will be the average of the two.
are equal. The two are slightly different in distribution space only because of different initialization. Therefore, the final output will be the average of the two.
Implementation and Examples
We will use the Wikipedia article on Oolong as our corpus. In the following code, we crawl the article and split it into sentences and then into words.
wiki = wikipediaapi.Wikipedia(user_agent="waynestalk/1.0", language="en")
page = wiki.page("Oolong")
corpus = page.text
nltk.download("punkt")
sentences = nltk.sent_tokenize(corpus)
tokenized_corpus = [[word.lower() for word in nltk.word_tokenize(sentence) if word.isalpha()] for sentence in sentences]
vocab = set([word for sentence in tokenized_corpus for word in sentence])
word_to_index = {word: i for i, word in enumerate(vocab)}
index_to_word = {i: word for i, word in enumerate(vocab)}
len(vocab)
# Output
580Next, we build the co-occurrence matrix with the context window size set to 2.
window_size = 2
vocab_size = len(vocab)
co_occurrence_matrix = torch.zeros((vocab_size, vocab_size))
for sentence in tokenized_corpus:
for i, word in enumerate(sentence):
word_index = word_to_index[word]
for j in range(max(0, i - window_size), min(i + window_size + 1, len(sentence))):
if i != j:
context_index = word_to_index[sentence[j]]
co_occurrence_matrix[word_index, context_index] += 1Below is the implementation of the GloVe model.
class GloVe(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(GloVe, self).__init__()
self.word_embedding = nn.Embedding(vocab_size, embedding_dim)
self.context_embedding = nn.Embedding(vocab_size, embedding_dim)
self.word_bias = nn.Embedding(vocab_size, 1)
self.context_bias = nn.Embedding(vocab_size, 1)
nn.init.uniform_(self.word_embedding.weight, a=-0.5, b=0.5)
nn.init.uniform_(self.context_embedding.weight, a=-0.5, b=0.5)
nn.init.zeros_(self.word_bias.weight)
nn.init.zeros_(self.context_bias.weight)
def forward(self, word_index, context_index, co_occurrence):
word_emb = self.word_embedding(word_index)
context_emb = self.context_embedding(context_index)
word_b = self.word_bias(word_index).squeeze()
context_b = self.context_bias(context_index).squeeze()
weighting = self.weighting_function(co_occurrence)
log_co_occurrence = torch.log(co_occurrence)
dot = (word_emb * context_emb).sum(dim=1)
loss = weighting * (dot + word_b + context_b - log_co_occurrence) ** 2
return loss.sum()
def weighting_function(self, x, x_max=100, alpha=0.75):
return torch.where(x < x_max, (x / x_max) ** alpha, torch.ones_like(x))Before starting training, we flatten the training data.
word_indices = []
context_indices = []
co_occurrences = []
for i in range(vocab_size):
for j in range(vocab_size):
if co_occurrence_matrix[i, j] > 0:
word_indices.append(i)
context_indices.append(j)
co_occurrences.append(co_occurrence_matrix[i, j])
word_indices = torch.tensor(word_indices, dtype=torch.long)
context_indices = torch.tensor(context_indices, dtype=torch.long)
co_occurrences = torch.tensor(co_occurrences, dtype=torch.float)Now we can train the model as follows.
embedding_dim = 1000
model = GloVe(vocab_size, embedding_dim)
optimizer = optim.Adam(model.parameters(), lr=0.01)
epochs = 500
start_time = time.time()
for epoch in range(epochs):
loss = model(word_indices, context_indices, co_occurrences)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch == 0 or (epoch + 1) % 100 == 0:
print(f"Epoch: {epoch}, Loss: {loss.item()}")
end_time = time.time()
print(f"Training time: {end_time - start_time} seconds")
# Output
Epoch: 0, Loss: 1147.0933837890625
Epoch: 99, Loss: 0.01006692461669445
Epoch: 199, Loss: 0.0013765881303697824
Epoch: 299, Loss: 0.007692785933613777
Epoch: 399, Loss: 0.031206317245960236
Epoch: 499, Loss: 0.027982018887996674
Training time: 2.2056429386138916 secondsThe final word embeddings is the average of word_embedding and context_embedding.
def get_final_embedding(word):
word_index = torch.tensor(word_to_index[word], dtype=torch.long)
w_vec = model.word_embedding(word_index).detach()
c_vec = model.context_embedding(word_index).detach()
return (w_vec + c_vec) / 2.0In the following code, we use the trained word embeddings to calculate the similarity between two sentences.
sentence1 = "tea is popular in taiwan".split()
sentence2 = "oolong is famous in taiwan".split()
sentence1_embeddings = [get_final_embedding(word) for word in sentence1]
sentence2_embeddings = [get_final_embedding(word) for word in sentence2]
vector1 = torch.stack(sentence1_embeddings).mean(dim=0)
vector2 = torch.stack(sentence2_embeddings).mean(dim=0)
cosine_sim = nn.CosineSimilarity(dim=0)
similarity = cosine_sim(vector1, vector2).item()
print(f"Sentence 1: {sentence1}")
print(f"Sentence 2: {sentence2}")
print(f"Similarity between sentences: {similarity}")
# Output
Sentence 1: ['tea', 'is', 'popular', 'in', 'taiwan']
Sentence 2: ['oolong', 'is', 'famous', 'in', 'taiwan']
Similarity between sentences: 0.6013368964195251Conclusion
GloVe is a powerful word embedding model that can effectively capture global word relationships through statistical co-occurrence analysis. Its ability to produce meaningful vector representations makes it a valuable tool in NLP applications such as text classification, sentiment analysis, and machine translation.
References
- Andrew Ng, Deep Learning Specialization, Coursera.
- Jeffrey Pennington, Richard Socher, and Christopher D. Manning. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1532-1543.
- GloVe: Global Vectors for Word Representation.









