
The gated recurrent unit (GRU) is a type of RNN specifically designed to process sequential data. Similar to the long short-term memory (LSTM), it is designed to solve the long-term dependency problem of the standard RNN.
The complete code for this chapter can be found in .
Table of Contents
GRU
Standard RNNs suffer from the problem of vanishing gradients. Therefore, if the sequence data is very long, the standard RNN cannot effectively learn the early input data. That is to say, the long-term memory capacity of standard RNN is quite weak. For more details about vanishing gradients, please refer to the following article. In addition, if you are not familiar with RNN, please refer to the following article first.

Compared with LSTM, its structure is simpler and its calculation is more efficient. For details about LSTM, please refer to the following article.

The figure below is a GRU cell. It is more complex than a standard RNN, but simpler than an LSTM. In addition to the hidden state  , GRU also needs to calculate the reset gate
, GRU also needs to calculate the reset gate  , update gate
, update gate  , and candidate hidden state
, and candidate hidden state  .
.

Here’s what each of them means.
- Reset gate
 : This gate determines whether to forget previous information.
: This gate determines whether to forget previous information. - Update gate : This gate determines how much previous information to remember.
- Candidate hidden state : Generates new candidate states by processing the current input and part of the past state.
Forward Propagation
The figure below shows GRU forward propagation. Each gate and candidate cell state has its corresponding parameters  and activation functions. It is worth noting that we will stack
and activation functions. It is worth noting that we will stack  and
and  vertically.
vertically.

The formula in the GRU cell is as follows:
![\Gamma_r=\sigma(W_r[a^{<t-1>},x^{<t>}]+b_r) \\\\ \Gamma_u=\sigma(W_u[a^{<t-1>},x^{<t>}]+b_u) \\\\ \tilde{c}^{<t>}=tanh(W_c[(\Gamma_r\odot a^{<t-1>}),x^{<t>}]+b_c) \\\\ a^{<t>}=\Gamma_u\odot\tilde{c}^{<t>}+(1-\Gamma_u)\odot a^{<t-1>} \\\\ \hat{y}^{<t>}=softmax(W_ya^{<t>}+b_y)](https://s0.wp.com/latex.php?latex=%5CGamma_r%3D%5Csigma%28W_r%5Ba%5E%7B%3Ct-1%3E%7D%2Cx%5E%7B%3Ct%3E%7D%5D%2Bb_r%29+%5C%5C%5C%5C+%5CGamma_u%3D%5Csigma%28W_u%5Ba%5E%7B%3Ct-1%3E%7D%2Cx%5E%7B%3Ct%3E%7D%5D%2Bb_u%29+%5C%5C%5C%5C+%5Ctilde%7Bc%7D%5E%7B%3Ct%3E%7D%3Dtanh%28W_c%5B%28%5CGamma_r%5Codot+a%5E%7B%3Ct-1%3E%7D%29%2Cx%5E%7B%3Ct%3E%7D%5D%2Bb_c%29+%5C%5C%5C%5C+a%5E%7B%3Ct%3E%7D%3D%5CGamma_u%5Codot%5Ctilde%7Bc%7D%5E%7B%3Ct%3E%7D%2B%281-%5CGamma_u%29%5Codot+a%5E%7B%3Ct-1%3E%7D+%5C%5C%5C%5C+%5Chat%7By%7D%5E%7B%3Ct%3E%7D%3Dsoftmax%28W_ya%5E%7B%3Ct%3E%7D%2Bb_y%29+&bg=ffffff&fg=000&s=1&c=20201002)
The dimensions of the GRU input  and true labels
and true labels  are as follows:
are as follows:

In the GRU cell, the dimensions of each variable are as follows:
|  | |  |
![[a^{<t-1>},x^{<t>}]](https://s0.wp.com/latex.php?latex=%5Ba%5E%7B%3Ct-1%3E%7D%2Cx%5E%7B%3Ct%3E%7D%5D&bg=ffffff&fg=000&s=0&c=20201002) |  |  |  |
 |  | 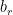 |  |
 | | 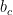 | |
 | |  | |
 |  |  |  |
The following is the implementation of GRU’s forward propagation.
class GRU:
def cell_forward(self, xt, at_prev, parameters):
"""
Implements a single forward step for the GRU-cell.
Parameters
----------
xt: (ndarray (n_x, m)) - input data for the current timestep
at_prev: (ndarray (n_a, m)) - hidden state from the previous timestep
parameters: (dict) - dictionary containing the weights and biases of the GRU network
Wu: (ndarray (n_a, n_a + n_x)) - weights of the update gate
bu: (ndarray (n_a, 1)) - biases of the update gate
Wr: (ndarray (n_a, n_a + n_x)) - weights of the reset gate
br: (ndarray (n_a, 1)) - biases of the reset gate
Wc: (ndarray (n_a, n_a + n_x)) - weights of the candidate value
bc: (ndarray (n_a, 1)) - biases of the candidate value
Wy: (ndarray (n_y, n_a)) - weights of the output layer
by: (ndarray (n_y, 1)) - biases of the output layer
Returns
-------
at: (ndarray (n_a, m)) - hidden state for the current timestep
y_hat_t: (ndarray (n_y, m)) - prediction for the current timestep
cache: (tuple) - values needed for the backward pass
"""
Wu, bu = parameters["Wu"], parameters["bu"] # update gate weights and biases
Wr, br = parameters["Wr"], parameters["br"] # reset gate weights and biases
Wc, bc = parameters["Wc"], parameters["bc"] # candidate value weights and biases
Wy, by = parameters["Wy"], parameters["by"] # prediction weights and biases
concat = np.concatenate((at_prev, xt), axis=0)
ut = sigmoid(Wu @ concat + bu) # update gate
rt = sigmoid(Wr @ concat + br) # reset gate
cct = tanh(Wc @ np.concatenate((rt * at_prev, xt), axis=0) + bc) # candidate value
at = ut * cct + (1 - ut) * at_prev # hidden state
zyt = Wy @ at + by
y_hat_t = softmax(zyt)
cache = (at, at_prev, ut, rt, cct, xt, y_hat_t, zyt)
return at, y_hat_t, cache
def forward(self, X, a0, parameters):
"""
Implements the forward pass of the GRU network.
Parameters
----------
X: (ndarray (n_x, m, T_x)) - input data for each time step
a0: (ndarray (n_a, m)) - initial hidden state
parameters: (dict) - dictionary containing the weights and biases of the GRU network
Wu: (ndarray (n_a, n_a + n_x)) - weights of the update gate
bu: (ndarray (n_a, 1)) - biases of the update gate
Wr: (ndarray (n_a, n_a + n_x)) - weights of the reset gate
br: (ndarray (n_a, 1)) - biases of the reset gate
Wc: (ndarray (n_a, n_a + n_x)) - weights of the candidate value
bc: (ndarray (n_a, 1)) - biases of the candidate value
Wy: (ndarray (n_y, n_a)) - weights of the output layer
by: (ndarray (n_y, 1)) - biases of the output layer
Returns
-------
A: (ndarray (n_a, m, T_x)) - hidden states for each timestep
Y_hat: (ndarray (n_y, m, T_x)) - predictions for each timestep
caches: (list) - values needed for the backward pass
"""
caches = []
Wy = parameters["Wy"]
x_x, m, T_x = X.shape
n_y, n_a = Wy.shape
A = np.zeros((n_a, m, T_x))
Y_hat = np.zeros((n_y, m, T_x))
at_prev = a0
for t in range(T_x):
at_prev, y_hat_t, cache = self.cell_forward(X[:, :, t], at_prev, parameters)
A[:, :, t] = at_prev
Y_hat[:, :, t] = y_hat_t
caches.append(cache)
return A, Y_hat, cachesLoss Function
In this article, we use softmax to output  , so we use cross-entropy loss as its loss function. For the formula and implementation of cross-entropy loss, please refer to the following article.
, so we use cross-entropy loss as its loss function. For the formula and implementation of cross-entropy loss, please refer to the following article.
Backward Propagation
The backpropagation of GRU is a bit complicated. We have to calculate the partial derivatives with respect to each parameter. In particular, when calculating  , we also need to consider its value at the previous timestep, that is, backpropagation through time (BPTT).
, we also need to consider its value at the previous timestep, that is, backpropagation through time (BPTT).

The following calculates the partial derivatives in the output layer.

The following is to calculate the partial derivatives of the reset gate, update gate, and candidate hidden state.

The following calculates the partial derivatives of all parameters .

The following calculates the remaining partial derivatives.

The above is how to calculate all partial derivatives at each time step. Finally, we have to sum up all the partial derivatives we have taken.

The following is the implementation of GRU’s backward propagation.
class GRU:
def cell_backward(self, y, dat, cache, parameters):
"""
Implements a single backward step for the GRU-cell.
Parameters
----------
y: (ndarray (n_y, m)) - true labels for the current timestep
dat: (ndarray (n_a, m)) - gradient of the hidden state for the current timestep
cache: (tuple) - values needed for the backward pass
parameters: (dict) - dictionary containing the weights and biases of the GRU network
Wu: (ndarray (n_a, n_a + n_x)) - weights of the update gate
bu: (ndarray (n_a, 1)) - biases of the update gate
Wr: (ndarray (n_a, n_a + n_x)) - weights of the reset gate
br: (ndarray (n_a, 1)) - biases of the reset gate
Wc: (ndarray (n_a, n_a + n_x)) - weights of the candidate value
bc: (ndarray (n_a, 1)) - biases of the candidate value
Wy: (ndarray (n_y, n_a)) - weights of the output layer
by: (ndarray (n_y, 1)) - biases of the output layer
Returns
-------
gradients: (dict) - dictionary containing the gradients of the weights and biases of the GRU network
dWu: (ndarray (n_a, n_a + n_x)) - gradients of the weights of the update gate
dbu: (ndarray (n_a, 1)) - gradients of the biases of the update gate
dWr: (ndarray (n_a, n_a + n_x)) - gradients of the weights of the reset gate
dbr: (ndarray (n_a, 1)) - gradients of the biases of the reset gate
dWc: (ndarray (n_a, n_a + n_x)) - gradients of the weights of the candidate value
dbc: (ndarray (n_a, 1)) - gradients of the biases of the candidate value
dWy: (ndarray (n_y, n_a)) - gradients of the weights of the output layer
dby: (ndarray (n_y, 1)) - gradients of the biases of the output
"""
at, at_prev, ut, rt, cct, xt, y_hat_t, zyt = cache
n_a, m = at.shape
dzy = y_hat_t - y
dWy = dzy @ at.T
dby = np.sum(dzy, axis=1, keepdims=True)
dat = parameters["Wy"].T @ dzy + dat
dcct = dat * ut * (1 - cct ** 2) # dn_t
dut = dat * (cct - at_prev) * ut * (1 - ut)
dat_prev = dat * (1 - ut)
dcct_ra_x = parameters["Wc"].T @ dcct
dcct_r_at_prev = dcct_ra_x[:n_a, :]
dcct_xt = dcct_ra_x[n_a:, :]
drt = (dcct_r_at_prev * at_prev) * rt * (1 - rt)
concat = np.concatenate((at_prev, xt), axis=0)
dWc = dcct @ np.concatenate((rt * at_prev, xt), axis=0).T
dbc = np.sum(dcct, axis=1, keepdims=True)
dWr = drt @ concat.T
dbr = np.sum(drt, axis=1, keepdims=True)
dWu = dut @ concat.T
dbu = np.sum(dut, axis=1, keepdims=True)
dat_prev = (
dat_prev + dcct_r_at_prev * rt + parameters["Wr"][:, :n_a].T @ drt + parameters["Wu"][:, :n_a].T @ dut
)
dxt = (
dcct_xt + parameters["Wr"][:, n_a:].T @ drt + parameters["Wu"][:, n_a:].T @ dut
)
gradients = {
"dWu": dWu, "dbu": dbu, "dWr": dWr, "dbr": dbr, "dWc": dWc, "dbc": dbc, "dWy": dWy, "dby": dby,
"dat_prev": dat_prev, "dxt": dxt
}
return gradients
def backward(self, X, Y, parameters, caches):
"""
Implements the backward pass of the GRU network.
Parameters
----------
X: (ndarray (n_x, m, T_x)) - input data for each time step
Y: (ndarray (n_y, m, T_x)) - true labels for each time step
parameters: (dict) - dictionary containing the weights and biases of the GRU network
Wu: (ndarray (n_a, n_a + n_x)) - weights of the update gate
bu: (ndarray (n_a, 1)) - biases of the update gate
Wr: (ndarray (n_a, n_a + n_x)) - weights of the reset gate
br: (ndarray (n_a, 1)) - biases of the reset gate
Wc: (ndarray (n_a, n_a + n_x)) - weights of the candidate value
bc: (ndarray (n_a, 1)) - biases of the candidate value
Wy: (ndarray (n_y, n_a)) - weights of the output layer
by: (ndarray (n_y, 1)) - biases of the output layer
caches: (list) - values needed for the backward pass
Returns
-------
gradients: (dict) - dictionary containing the gradients of the weights and biases of the GRU network
dWu: (ndarray (n_a, n_a + n_x)) - gradients of the weights of the update gate
dbu: (ndarray (n_a, 1)) - gradients of the biases of the update gate
dWr: (ndarray (n_a, n_a + n_x)) - gradients of the weights of the reset gate
dbr: (ndarray (n_a, 1)) - gradients of the biases of the reset gate
dWc: (ndarray (n_a, n_a + n_x)) - gradients of the weights of the candidate value
dbc: (ndarray (n_a, 1)) - gradients of the biases of the candidate value
dWy: (ndarray (n_y, n_a)) - gradients of the weights of the output layer
dby: (ndarray (n_y, 1)) - gradients of the biases of the output layer
"""
n_x, m, T_x = X.shape
a1, a0, u0, r1, cc1, x1, y_hat_1, zyt1 = caches[0]
Wu, Wr, Wc, Wy = parameters["Wu"], parameters["Wr"], parameters["Wc"], parameters["Wy"]
bu, br, bc, by = parameters["bu"], parameters["br"], parameters["bc"], parameters["by"]
gradients = {
"dWu": np.zeros_like(Wu), "dbu": np.zeros_like(bu), "dWr": np.zeros_like(Wr), "dbr": np.zeros_like(br),
"dWc": np.zeros_like(Wc), "dbc": np.zeros_like(bc), "dWy": np.zeros_like(Wy), "dby": np.zeros_like(by),
}
dat = np.zeros_like(a0)
for t in reversed(range(T_x)):
grads = self.cell_backward(Y[:, :, t], dat, caches[t], parameters)
gradients["dWu"] += grads["dWu"]
gradients["dbu"] += grads["dbu"]
gradients["dWr"] += grads["dWr"]
gradients["dbr"] += grads["dbr"]
gradients["dWc"] += grads["dWc"]
gradients["dbc"] += grads["dbc"]
gradients["dWy"] += grads["dWy"]
gradients["dby"] += grads["dby"]
dat = grads["dat_prev"]
return gradientsPutting All Together
The following code implements a complete training process. First, we pass the training data into forward propagation, calculate the loss, and then pass it into backward propagation to finally get the gradients. To prevent exploding gradients from happening, we will clip the gradients. Then, use it to update the parameters. This is a complete training.
class GRU:
def optimize(self, X, Y, a_prev, parameters, learning_rate, clip_value):
"""
Implements the forward and backward pass of the GRU network.
Parameters
----------
X: (ndarray (n_x, m, T_x)) - input data for each time step
Y: (ndarray (n_y, m, T_x)) - true labels for each time step
a_prev: (ndarray (n_a, m)) - initial hidden state
parameters: (dict) - dictionary containing the weights and biases of the GRU network
Wu: (ndarray (n_a, n_a + n_x)) - weights of the update gate
bu: (ndarray (n_a, 1)) - biases of the update gate
Wr: (ndarray (n_a, n_a + n_x)) - weights of the reset gate
br: (ndarray (n_a, 1)) - biases of the reset gate
Wc: (ndarray (n_a, n_a + n_x)) - weights of the candidate value
bc: (ndarray (n_a, 1)) - biases of the candidate value
Wy: (ndarray (n_y, n_a)) - weights of the output layer
by: (ndarray (n_y, 1)) - biases of the output layer
learning_rate: (float) - learning rate
clip_value: (float) - maximum value to clip the gradients
Returns
-------
at: (ndarray (n_a, m)) hidden state for the last time step
loss: (float) - the cross-entropy
"""
A, Y_hat, caches = self.forward(X, a_prev, parameters)
loss = self.compute_loss(Y_hat, Y)
gradients = self.backward(X, Y, parameters, caches)
gradients = self.clip(gradients, clip_value)
self.update_parameters(parameters, gradients, learning_rate)
at = A[:, :, -1]
return at, lossExample
Next, we design GRU as a character-level language model. The training material is a passage from Shakespeare. It trains one character at a time, so the sequence length 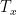 will be the length of the input character, and uses one-hot encoding to encode each character. Please refer to the following article for details of this part, because this article and the following article use the same example.
will be the length of the input character, and uses one-hot encoding to encode each character. Please refer to the following article for details of this part, because this article and the following article use the same example.
An example of using this GRU is as follows:
if __name__ == "__main__":
with open("shakespeare.txt", "r") as file:
text = file.read()
chars = sorted(list(set(text)))
vocab_size = len(chars)
char_to_idx = {ch: i for i, ch in enumerate(chars)}
idx_to_char = {i: ch for i, ch in enumerate(chars)}
gru = GRU(64, vocab_size, vocab_size)
losses = gru.train(text, char_to_idx, num_iterations=100, learning_rate=0.01, clip_value=5)
generated_text = gru.sample("T", char_to_idx, idx_to_char, num_chars=100)
print(generated_text)Conclusion
GRU is better at learning long-term dependencies than standard RNN, but has a simpler structure and is more computationally efficient than LSTM. However, due to the simpler structure of GRU, LSTM performs better in learning long-term dependencies. Therefore, we must decide whether to use LSTM or GRU based on the usage scenario and the length of the data.
References
- Junyoung Chung, Caglar Gulcehre, KyungHyum Cho, and Yoshua Bengio. 2014. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. CoRR, abs/1412.3555.
- Andrew Ng, Deep Learning Specialization , Coursera.









