
Multiple classification neural network can classify more than one category. Compared with
binary classification, it is more commonly used in practice. This article will introduce the theory of multiple classification neural network in detail.
The complete code for this chapter can be found in .
Table of Contents
Neural Network
Before starting this article, readers must understand neural network and binary classification. Many of the concepts in this article are similar to binary classification. We will not repeat these similarities in this article. Therefore, whether readers understand binary classification or not, it is recommended to read the following article first.

Softmax Function
Softmax Function
Compared with binary classification, multiple classification uses softmax function as the activation function of the output layer.
Softmax function is defined as follows. Each  is greater than zero, and both are divided by the sum. So
is greater than zero, and both are divided by the sum. So  will be a probability distribution that sums to 1.
will be a probability distribution that sums to 1.

The following code implements the softmax function.
def softmax(Z):
"""
Implements the softmax activation.
Parameters
----------
Z: (ndarray of any shape) - input to the activation function
Returns
-------
A: (ndarray of same shape as Z) - output of the activation function
"""
# Subtracting the maximum value in each column for numerical stability to avoid overflow
Z_stable = Z - np.max(Z, axis=0, keepdims=True)
exp_Z = np.exp(Z_stable)
A = exp_Z / np.sum(exp_Z, axis=0, keepdims=True)
return ADerivative of Softmax Function
Solving for the derivative of the softmax function is a bit complicated. First, the k-th term of the output of the softmax function is as follows.

 differentiates
differentiates 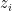 , as follows.
, as follows.

First, let’s think about it  . At this time, there are two situations.
. At this time, there are two situations.
- When
 , then .
, then . - When , then .
 .
. .
.We can merge these two situations using kronecker delta.

Now to deal with  .
.

Substituting the above two parts back, we can get the following.

After factoring, finally differentiating is as follows.

has K items. Each item must differentiate  separately. Therefore, the derivative of softmax is a
separately. Therefore, the derivative of softmax is a  jacobian matrix , as follows.
jacobian matrix , as follows.

And when  or
or  ,
,  will be different values. Because
will be different values. Because J is a matrix, are items on the diagonal.

In the following code, the input value z is the output value of the softmax function. softmax_jacobian() implements the derivative of the softmax function, and its derivative will be a jacobian matrix.
def softmax_jacobian(z):
"""
Computes the Jacobian matrix for the softmax function.
Parameters
----------
Z: (ndarray (K,1)) - the input to the softmax function
Returns
-------
dZ: (ndarray (K,K)) - the Jacobian matrix
"""
z_stable = z - np.max(z, axis=0, keepdims=True)
exp_Z = np.exp(z_stable)
g = exp_z / np.sum(exp_z, axis=0, keepdims=True)
return np.diag(g) - np.outer(g, g)Multiple Classification Neural Network
The figure below is a neural network of multiple classification. Compared with binary classification, the activation function in its output layer is softmax  .
.

Gradient Descent
The gradient descent of multiple classification neural network is as follows. Since each layer has corresponding parameters W and b, we must calculate the partial derivative of J with respect to each layer W and b.
![\displaystyle L:\text{number of layers} \\\\ K:\text{number of classes} \\\\ m:\text{number of examples} \\\\ \text{Parameters}: W^{[\ell]},b^{[\ell]},\ell=1,...,L \\\\ \text{Loss function}: J(W,b)=-\frac{1}{m}\sum_{i=1}^m\sum_{k=1}^{K} Y_{k}^{(i)}\log A_{k}^{[L](i)} \\\\ \text{repeat until convergence \{} \\\\ \hphantom{xxxx}\text{Compute predict }(\hat{y}^{(i)},i=1,...,m) \\\\ \hphantom{xxxx}W^{[\ell]}:=W^{[\ell]}-\frac{\partial J}{\partial W^{[\ell]}}, \ell=1,...,L \\\\ \hphantom{xxxx}b^{[\ell]}:=b^{[\ell]}-\frac{\partial J}{\partial b^{[\ell]}}, \ell=1,...,L \\\\ \text{\}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+L%3A%5Ctext%7Bnumber+of+layers%7D+%5C%5C%5C%5C+K%3A%5Ctext%7Bnumber+of+classes%7D+%5C%5C%5C%5C+m%3A%5Ctext%7Bnumber+of+examples%7D+%5C%5C%5C%5C+%5Ctext%7BParameters%7D%3A+W%5E%7B%5B%5Cell%5D%7D%2Cb%5E%7B%5B%5Cell%5D%7D%2C%5Cell%3D1%2C...%2CL+%5C%5C%5C%5C+%5Ctext%7BLoss+function%7D%3A+J%28W%2Cb%29%3D-%5Cfrac%7B1%7D%7Bm%7D%5Csum_%7Bi%3D1%7D%5Em%5Csum_%7Bk%3D1%7D%5E%7BK%7D+Y_%7Bk%7D%5E%7B%28i%29%7D%5Clog+A_%7Bk%7D%5E%7B%5BL%5D%28i%29%7D+%5C%5C%5C%5C+%5Ctext%7Brepeat+until+convergence+%5C%7B%7D+%5C%5C%5C%5C+%5Chphantom%7Bxxxx%7D%5Ctext%7BCompute+predict+%7D%28%5Chat%7By%7D%5E%7B%28i%29%7D%2Ci%3D1%2C...%2Cm%29+%5C%5C%5C%5C+%5Chphantom%7Bxxxx%7DW%5E%7B%5B%5Cell%5D%7D%3A%3DW%5E%7B%5B%5Cell%5D%7D-%5Cfrac%7B%5Cpartial+J%7D%7B%5Cpartial+W%5E%7B%5B%5Cell%5D%7D%7D%2C+%5Cell%3D1%2C...%2CL+%5C%5C%5C%5C+%5Chphantom%7Bxxxx%7Db%5E%7B%5B%5Cell%5D%7D%3A%3Db%5E%7B%5B%5Cell%5D%7D-%5Cfrac%7B%5Cpartial+J%7D%7B%5Cpartial+b%5E%7B%5B%5Cell%5D%7D%7D%2C+%5Cell%3D1%2C...%2CL+%5C%5C%5C%5C+%5Ctext%7B%5C%7D%7D+&bg=ffffff&fg=000&s=1&c=20201002)
Loss Function
In the neural network of multiple classification, the activation function of the output layer is the softmax function. Therefore, we use cross-entropy loss as its loss function.
} \\\\ L:\text{number of layers} \\\\ K:\text{number of classes} \\\\ m:\text{number of examples} \\\\](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+J%28W%2Cb%29%3D-%5Cfrac%7B1%7D%7Bm%7D%5Csum_%7Bi%3D1%7D%5Em%5Csum_%7Bk%3D1%7D%5E%7BK%7D+Y_%7Bk%7D%5E%7B%28i%29%7D%5Clog+A_%7Bk%7D%5E%7B%5BL%5D%28i%29%7D+%5C%5C%5C%5C+L%3A%5Ctext%7Bnumber+of+layers%7D+%5C%5C%5C%5C+K%3A%5Ctext%7Bnumber+of+classes%7D+%5C%5C%5C%5C+m%3A%5Ctext%7Bnumber+of+examples%7D+%5C%5C%5C%5C+&bg=ffffff&fg=000&s=1&c=20201002)
The following code implements the loss function.
def compute_cost(AL, Y):
"""
Computes the cross-entropy cost.
Parameters
----------
AL: (ndarray (output size, number of examples)) - probability vector corresponding to the label predictions
Y: (ndarray (output size, number of examples)) - true label vector
Returns
-------
cost: (float) - the cross-entropy cost
"""
m = Y.shape[1]
cost = -(1 / m) * np.sum(Y * np.log(AL))
return costForward Propagation
In forward propagation, activation functions return Z to the caller, who stores it in caches. These caches will be used in backpropagation.
The following code implements the softmax activation function.
def softmax(Z):
"""
Implements the softmax activation.
Parameters
----------
Z: (ndarray of any shape) - input to the activation function
Returns
-------
A: (ndarray of same shape as Z) - output of the activation function
cache: (ndarray) - returning Z for backpropagation
"""
# Subtracting the maximum value in each column for numerical stability to avoid overflow
Z_stable = Z - np.max(Z, axis=0, keepdims=True)
exp_Z = np.exp(Z_stable)
A = exp_Z / np.sum(exp_Z, axis=0, keepdims=True)
cache = Z
return A, cacheBackpropagation or Backward Propagation
Backpropagation is actually the differential chain rule.

In the binary classification neural network, we mentioned how to obtain the derivatives of each parameter. In multiple classification neural network, we are also required to take the derivative of each parameter. The difference is that the loss function we use here is different from the activation function in the output layer.
First, let’s do the math ![\frac{\partial J}{\partial A^{[L]}}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cpartial+J%7D%7B%5Cpartial+A%5E%7B%5BL%5D%7D%7D&bg=ffffff&fg=000&s=0&c=20201002) .
.
![\frac{\partial J}{\partial A^{[L]}}=-\frac{1}{m}\frac{Y}{A^{[L]}}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cpartial+J%7D%7B%5Cpartial+A%5E%7B%5BL%5D%7D%7D%3D-%5Cfrac%7B1%7D%7Bm%7D%5Cfrac%7BY%7D%7BA%5E%7B%5BL%5D%7D%7D+&bg=ffffff&fg=000&s=1&c=20201002)
Calculate }}{\partial Z^{[L](i)}}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cpartial+A%5E%7B%5BL%5D%28i%29%7D%7D%7B%5Cpartial+Z%5E%7B%5BL%5D%28i%29%7D%7D&bg=ffffff&fg=000&s=0&c=20201002) for each example. Here, each example needs to be calculated separately because it will be a jacobian matrix.
for each example. Here, each example needs to be calculated separately because it will be a jacobian matrix.
}}{\partial Z_{k}^{[L](i)}}=A_{k}^{[L](i)}[\delta_{kj}-A_{j}^{[L](i)}] \\\\ \frac{\partial A^{[L](i)}}{\partial Z^{[L](i)}} \text{ is a K } \times \text{K jacobian matrix}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cpartial+A_%7Bk%7D%5E%7B%5BL%5D%28i%29%7D%7D%7B%5Cpartial+Z_%7Bk%7D%5E%7B%5BL%5D%28i%29%7D%7D%3DA_%7Bk%7D%5E%7B%5BL%5D%28i%29%7D%5B%5Cdelta_%7Bkj%7D-A_%7Bj%7D%5E%7B%5BL%5D%28i%29%7D%5D+%5C%5C%5C%5C+%5Cfrac%7B%5Cpartial+A%5E%7B%5BL%5D%28i%29%7D%7D%7B%5Cpartial+Z%5E%7B%5BL%5D%28i%29%7D%7D+%5Ctext%7B+is+a+K+%7D+%5Ctimes+%5Ctext%7BK+jacobian+matrix%7D+&bg=ffffff&fg=000&s=1&c=20201002)
After calculating }}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cpartial+J%7D%7B%5Cpartial+Z%5E%7B%5BL%5D%28i%29%7D%7D&bg=ffffff&fg=000&s=0&c=20201002) for each example, combine them.
for each example, combine them.
![\frac{\partial J}{\partial Z^{[L]}}=\begin{bmatrix} \vdots & \cdots & \vdots \\ \frac{\partial A^{[L](1)}}{\partial Z^{[L](1)}}\frac{\partial J^{(1)}}{\partial A^{[L](1)}} & \cdots & \frac{\partial A^{[L](m)}}{\partial Z^{[L](m)}}\frac{\partial J^{(m)}}{\partial A^{[L](m)}} \\ \vdots & \cdots & \vdots \end{bmatrix}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cpartial+J%7D%7B%5Cpartial+Z%5E%7B%5BL%5D%7D%7D%3D%5Cbegin%7Bbmatrix%7D+%5Cvdots+%26+%5Ccdots+%26+%5Cvdots+%5C%5C+%5Cfrac%7B%5Cpartial+A%5E%7B%5BL%5D%281%29%7D%7D%7B%5Cpartial+Z%5E%7B%5BL%5D%281%29%7D%7D%5Cfrac%7B%5Cpartial+J%5E%7B%281%29%7D%7D%7B%5Cpartial+A%5E%7B%5BL%5D%281%29%7D%7D+%26+%5Ccdots+%26+%5Cfrac%7B%5Cpartial+A%5E%7B%5BL%5D%28m%29%7D%7D%7B%5Cpartial+Z%5E%7B%5BL%5D%28m%29%7D%7D%5Cfrac%7B%5Cpartial+J%5E%7B%28m%29%7D%7D%7B%5Cpartial+A%5E%7B%5BL%5D%28m%29%7D%7D+%5C%5C+%5Cvdots+%26+%5Ccdots+%26+%5Cvdots+%5Cend%7Bbmatrix%7D+&bg=ffffff&fg=000&s=1&c=20201002)
For calculation of partial derivatives of other parameters, please refer to binary classification neural network.
The following code implements the partial derivative of the softmax activation function.
def softmax_backward(dA, cache):
"""
Implements the backward propagation for a single softmax unit.
Parameters
----------
dA: (ndarray of any shape) - post-activation gradient
cache: (ndarray) - Z from the forward propagation
Returns
-------
dZ: (ndarray of the same shape as A) - gradient of the cost with respect to Z
"""
def softmax_jacobian(Z):
Z_stable = Z - np.max(Z, axis=0, keepdims=True)
exp_Z = np.exp(Z_stable)
g = exp_Z / np.sum(exp_Z, axis=0, keepdims=True)
return np.diag(g) - np.outer(g, g)
Z = cache
m = Z.shape[1]
dZ = np.zeros_like(Z)
for k in range(m):
dZ[:, k] = softmax_jacobian(Z[:, k]) @ dA[:, k]
return dZFinally, model_backward() in the following code implements the entire backpropagation.
def model_backward(AL, Y, caches, activation_functions):
"""
Implements the backward propagation for the entire network.
Parameters
----------
AL: (ndarray (output size, number of examples)) - the output of the last layer
Y: (ndarray (output size, number of examples)) - true labels
caches: (list of tuples) - containing linear_cache (A_prev, W, b) and activation_cache (Z) for each layer
activation_functions: (list) - the activation function for each layer. The first element is unused.
Returns
-------
gradients: (dict) with keys where 0 <= l <= len(activation_functions) - 1:
dA{l-1}: (ndarray (size of previous layer, number of examples)) - gradient of the cost with respect to the activation for previous layer l - 1
dWl: (ndarray (size of current layer, size of previous layer)) - gradient of the cost with respect to W for layer l
dbl: (ndarray (size of current layer, 1)) - gradient of the cost with respect to b for layer l
"""
gradients = {}
L = len(activation_functions)
m = AL.shape[1]
dAL = -(1 / m) * (Y / AL)
dA_prev = dAL
for l in reversed(range(1, L)):
current_cache = caches[l - 1]
dA_prev, dW, db = linear_activation_backward(dA_prev, current_cache, activation_functions[l])
gradients[f'dA{l - 1}'] = dA_prev
gradients[f'dW{l}'] = dW
gradients[f'db{l}'] = db
return gradientsPutting All Together
nn_model() in the following code implements the entire model. It first performs forward propagation, then performs backpropagation, and finally updates the parameters.
def nn_model(X, Y, init_parameters, layer_activation_functions, learning_rate, num_iterations):
"""
Implements a neural network.
Parameters
----------
X: (ndarray (input size, number of examples)) - input data
Y: (ndarray (output size, number of examples)) - true labels
init_parameters: (dict) - the initial parameters for the network
layer_activation_functions: (list) - the activation function for each layer. The first element is unused.
learning_rate: (float) - the learning rate
num_iterations: (int) - the number of iterations
Returns
-------
parameters: (dict) - the learned parameters
costs: (list) - the costs at every 100th iteration
"""
costs = []
parameters = init_parameters.copy()
for i in range(num_iterations):
AL, caches = model_forward(X, parameters, layer_activation_functions)
cost = compute_cost(AL, Y)
gradients = model_backward(AL, Y, caches, layer_activation_functions)
parameters = update_parameters(parameters, gradients, learning_rate)
if i % 100 == 0 or i == num_iterations:
costs.append(cost)
return parameters, costsAfter training the parameters, we can use the following nn_model_predict() to make predictions.
def nn_model_predict(X, parameters, activation_functions):
"""
Predicts the output of the neural network.
Parameters
----------
X: (ndarray (input size, number of examples)) - input data
parameters: (dict) - the learned parameters
activation_functions: (list) - the activation function for each layer. The first element is unused.
Returns
-------
predictions: (ndarray (number of classes, number of examples)) - the predicted labels
"""
probabilities, _ = model_forward(X, parameters, activation_functions)
pred = np.argmax(probabilities, axis=0)
predictions = np.zeros_like(probabilities)
for i in range(predictions.shape[1]):
predictions[pred[i], i] = 1
return predictionsExample
We will use an example to show how to use our model. First, we load the training data x_orig and y. x_orig is an array containing 100 images. Each image is 64 x 64 in size and has three channels. y is an array containing 0 or 1, 1 means there is a cat in the picture, 0 means it is not a cat.
x_orig, y_orig = load_data()
print(f'x_orig shape: {x_orig.shape}')
print(f'y_orig shape: {y_orig.shape}')
# Output
x_orig shape: ndarray(100, 64, 64, 3)
y_orig shape: ndarray(1, 100)Previously we listed the dimensions of X as (nh, m), so each picture is a row vector. Below we take the dimensions of x_orig and convert the values 0 to 255 into values from 0 to 1. Convert y_orig to one hot encoding.
x_flatten = x_orig.reshape(x_orig.shape[0], -1).T
x = train_x_flatten / 255.
y = np.zeros((2, y_orig.shape[1]))
y[0, y_orig[0, :] == 0] = 1
y[1, y_orig[0, :] == 1] = 1
print("x shape: " + str(x.shape))
print("y shape: " + str(y.shape))
# Output
x shape: ndarray(1228, 100)
y shape: ndarray(2, 200)First, we need to decide the number of layers of the model and the number of neurons in each layer. Below we set the model to have an input layer, three layers in the hidden layer, and an output layer. We also need to decide the activation function of each layer, where layer_activation_functions[0] corresponds to the input layer, so it will not be used.
After these decisions are made, we can initialize all parameters W and b, and then call nn_model() to train the model. Finally, obtain the trained parameters.
layer_dims = [12288, 20, 7, 10, 1] init_parameters = initialize_parameters(layer_dims) layer_activation_functions = ['none', 'relu', 'relu', 'relu', 'softmax'] learning_rate = 0.0075 parameters, costs = nn_model(x, y, init_parameters, layer_activation_functions, learning_rate, 3000)
With the trained parameters, we can use them to predict other pictures.
x_new_orig = load_new_data() x_new_flatten = x_new_orig.reshape(x_new_orig.shape[0], -1).T x_new = x_new_flatten / 255. y_new = nn_model_predict(x_new, parameters, layer_activation_functions)
Conclusion
Obtaining the partial derivative of the softmax function is quite complicated. Fortunately, now we no longer need to implement this part ourselves, but use libraries like PyTorch and TensorFlow to implement the neural network. But understanding its internal details allows us to understand it better.
References
- Andrew Ng, Deep Learning Specialization, Coursera.
- 西内啓,統計学が最強の学問である[数学編]――データ分析と機械学習のための新しい教科書,ダイヤモンド社。









