
Linear regression is a data analysis technique that uses linear functions to predict data. Although the linear regression model is relatively simple, it is a mature statistical technique.
The complete code for this chapter can be found in .
Table of Contents
Linear Regression
Linear Regression Model
The model function of linear regression is as follows, where w and b are parameters. When we substitute x with the value, the function fw,b returns a predicted value ŷ (y hat).

It should be noted that what fw,b returns is a prediction value ŷ, not the real value y (target value), as shown in the figure below. When the predictions ŷ are very close y, we can say that the accuracy is very high. We improve the accuracy of fw,b by adjusting w and b.

In the following code, f_wb() implements the linear regression model.
def f_wb(x, w, b):
"""
Linear regression model
Parameters
----------
x: (ndarray (m,)) or (scalar)
m is the number of samples
w: (scalar)
b: (scalar)
Returns
-------
(ndarray (m,)) or (scalar)
"""
return w * x + bCost Function
Before introducing how to calculate w and b, we must first understand what cost function is. Cost function is used to measure the residual between the prediction values and target values, that is, the difference between them. With the cost function, we can measure whether the adjusted w and b are better than the original.
The cost function of linear regression is squared error, as follows.
We ultimately want to find a w and b such that J(w,b) is minimum.

In the following code, compute_cost() implements cost function J(w,b).
import numpy as np
def compute_cost(x, y, w, b):
"""
Compute cost
Parameters
----------
x: (ndarray (m,))
m is the number of samples
y: (ndarray (m,))
w: (scalar)
b: (scalar)
Returns
-------
(scalar)
"""
m = x.shape[0]
y_hat = f_wb(x, w, b)
return 1 / (2 * m) * np.sum((y_hat - y) ** 2)Solving Parameters w and b
The model function of linear regression is very simple. However, the question is how to solve w and b and make J(w,b) minimum? In machine learning, we use gradient descent to solve w and b. However, we will first introduce the other two methods to help readers understand the advantages of gradient descent.
When introducing each method, we will use the following examples to explain.
import matplotlib.pyplot as plt
import numpy as np
x_train = np.array([10, 20, 32, 44, 66])
y_train = np.array([10, 30, 40, 44, 54])
plt.scatter(x_train, y_train, 60, marker='o', c='c', label='y_train')
plt.xlabel('x_train')
plt.ylabel('y_train')
plt.legend()
Simultaneous Equations
We all know that any two points on the plane can form a straight line. We pick (10, 10) and (66, 54) to calculate w and b.

We substitute the calculated w and b into the model function, and draw the model function and prediction values calculated using simultaneous equations on the coordinate graph.
# simultaneous equations
w_se = 11 / 14 # 0.7857
b_se = 30 / 14 # 2.1428
y_hat_se = f_wb(x_train, w_se, b_se)
plt.scatter(x_train, y_train, 60, marker='o', c='c', label='y_train')
plt.plot(x_train, y_hat_se, 'ro-', label='y_hat_se')
plt.xlabel('x_train')
plt.ylabel('y_train and y_hat_se')
plt.legend()
The following shows the cost of the model. Using the 5 points in the example, we can calculate 10 groups of w and b, and then calculate their costs. Finally, select w and b with the smallest cost.
cost_se = compute_cost(x_train, y_train, w_se, b_se) cost_se # Output: # np.float64(36.21836734693877)
It seems simple to use simultaneous equations to solve w and b. However, when there are many training examples, the calculation will become complicated. In addition, if the optimal line of w and b does not pass through any training example, then we will not be able to find this w and b.
Least Squares
Least squares is a statistical optimization modeling method. The w and b it solves can minimize the sum of squares of residual, that is, minimize the cost. The concept of least squares is to add an error value ε (epsilon) to the model function so that the prediction value can be equal to the target value. Moreover, try to minimize ε.
Substitute all training examples into the model function. It can be seen that ε of each training example may be different.

Next, calculate the square of each ε.

Calculate the sum of all squares of ε. Then, we hope to solve for a set of w and b such that the sum of the squares of all ε is minimum, that is, the closer to zero, the better.

Use completing the square to simplify the expression.

If we hope that the error can be minimized, the value of w should be as follows:

In this case, the previous part will be equal to zero. We continue to use the matching method to simplify the remaining parts.

To minimize the above expression, the value of b should be as follows, so that the previous part will be equal to zero.

Substitute the value of b into the equation for w and find the value of w.

Substituting the calculated w and b into the model function, we can get the model we want.

In the following code, we draw the model function and prediction values calculated using least squares on the coordinate graph.
# least squares
w_ls = 0.788
b_ls = 7.674
y_hat_ls = f_wb(x_train, w_ls, b_ls)
plt.scatter(x_train, y_train, 60, marker='o', c='c', label='y_train')
plt.plot(x_train, y_hat_se, 'm^-', label='y_hat_se')
plt.plot(x_train, y_hat_ls, 'gs-', label='y_hat_ls')
plt.xlabel('x_train')
plt.ylabel('y_train, y_hat_se and y_hat_ls')
plt.legend()
The following shows the cost of the model.
cost_ls = compute_cost(x_train, y_train, w_ls, b_ls) cost_ls # Output # np.float64(15.953221200000002)
Compared with using simultaneous equations to calculate w and b, the least squares method can calculate better w and b. However, when there are many training examples, the entire calculation process will be extremely complicated.
Gradient Descent
Gradient descent is an optimization algorithm used to find the local value of a function. The basic principle is that first, randomly select a set of w and b, so it may be on the left or right side of the cost function, and then select the next set of w and b in the valley direction. Repeat this until J(w,b) can’t get any smaller.

The next question is how to know in which direction the bottom of the cost function is? We can differentiate the cost function J(w,b) and then get the current slope. With the slope, we know which way to move.

The following is the algorithm of gradient descent. First, randomly select a set of w and b, or set them to zero directly. The derivative of the cost function multiplied by a learning rate  will be the gradient for
will be the gradient for w and b to decrease. In addition, we will also give an iteration number, which represents the number of times gradient descent is performed. Therefore, we may not get the optimal w and b.

The partial derivative of J(w,b) with respect to w is:

The partial derivative of J(w,b) with respect to b is:

The following code implements the calculation of partial derivatives of J(w,b) with respect to w and b.
def compute_gradient(x, y, w, b):
"""
Compute the gradient for linear regression
Parameters
----------
x: (ndarray (m,))
m is the number of samples
y: (ndarray (m,))
w: (scalar)
b: (scalar)
Returns
-------
dj_dw: (scalar)
dj_db: (scalar)
"""
m = x.shape[0]
dj_dw = 1 / m * np.sum((f_wb(x, w, b) - y) * x)
dj_db = 1 / m * np.sum(f_wb(x, w, b) - y)
return dj_dw, dj_dbThe following code implements gradient descent. The parameter alpha is the learning rate, and epochs is the number of iterations.
def perform_gradient_descent(x, y, w_init, b_init, alpha, epochs):
"""
Perform gradient descent
Parameters
----------
x: (ndarray (m,))
m is the number of samples
y: (ndarray (m,))
w_init: (scalar)
b_init: (scalar)
alpha: (float)
epochs: (int)
Returns
-------
w: (scalar)
b: (scalar)
"""
w = w_init
b = b_init
for i in range(epochs):
dj_dw, dj_db = compute_gradient(x, y, w, b)
w -= alpha * dj_dw
b -= alpha * dj_db
return w, bIn the following code, we set the learning rate to 0.001 and the number of iterations to 3000. Then, draw the model function and prediction values calculated using gradient descent on the coordinate graph.
w_dg, b_dg = perform_gradient_descent(x_train, y_train, 0, 0, 0.001, 3000)
y_hat_gd = f_wb(x_train, w_dg, b_dg)
plt.scatter(x_train, y_train, 60, marker='o', c='c', label='y_train')
plt.plot(x_train, y_hat_se, 'm^-', label='y_hat_se')
plt.plot(x_train, y_hat_ls, 'gs-', label='y_hat_ls')
plt.plot(x_train, y_hat_gd, 'y*-', label='y_hat_gd')
plt.xlabel('x_train')
plt.ylabel('y_train, y_hat_se, y_hat_ls, and y_hat_gd')
plt.legend()
The following shows the cost of the model.
cost_gd = compute_cost(x_train, y_train, w_dg, b_dg) cost_gd # Output # np.float64(18.014426543403744)
Although the process of deriving the derivative of the cost function is somewhat complicated, the overall algorithm is not too complicated. When there are many training examples, the program code will not become complicated.
Some values calculated by the above three methods are listed below for readers’ comparison and reference.
(w_se, b_se), (w_ls, b_ls), (w_dg, b_dg) # Output ((0.7857142857142857, 2.142857142857143), (0.788, 7.674), (np.float64(0.8312661524754889), np.float64(5.714916639215474))) (y_train, y_hat_se, y_hat_ls, y_hat_gd) # Output (array([10, 30, 40, 44, 54]), array([10. , 17.85714286, 27.28571429, 36.71428571, 54. ]), array([15.554, 23.434, 32.89 , 42.346, 59.682]), array([14.02757816, 22.34023969, 32.31543352, 42.29062735, 60.5784827 ])) (cost_se, cost_ls, cost_gd) # Output (np.float64(36.21836734693877), np.float64(15.953221200000002), np.float64(18.014426543403744))
Learning Rate
In gradient descent, there is a learning rate called 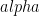 . It can be seen from the gradient descent algorithm that when is small, it takes more times to get close to the bottom, so the performance will be poor. On the contrary, it will reach the bottom more quickly. However, when is too large, it may not reach the bottom.
. It can be seen from the gradient descent algorithm that when is small, it takes more times to get close to the bottom, so the performance will be poor. On the contrary, it will reach the bottom more quickly. However, when is too large, it may not reach the bottom.

Multiple Linear Regression
So far, what we have introduced is simple linear regression, which has only one variable and may not be very practical. Next, we will introduce multiple linear regression.
Multiple Linear Regression Model
Multiple linear regression has more than one variable. The following is the model function of 4 variables.

Therefore, the model function of multiple linear regression is as follows.

The vectorized model function is as follows, where  are vectors.
are vectors.
![f_{\vec{w},b}(\vec{x}^{(i)})=\displaystyle\sum_{j=1}^nw_jx_j+b=\vec{w}\cdot \vec{x}^{(i)}+b \\\\ \vec{w}=[w_1,w_2,\cdots,w_n] \\\\ \vec{x}^{(i)}=[x_1^{(i)},x_2^{(i)},\cdots,x_n^{(i)}]](https://s0.wp.com/latex.php?latex=f_%7B%5Cvec%7Bw%7D%2Cb%7D%28%5Cvec%7Bx%7D%5E%7B%28i%29%7D%29%3D%5Cdisplaystyle%5Csum_%7Bj%3D1%7D%5Enw_jx_j%2Bb%3D%5Cvec%7Bw%7D%5Ccdot+%5Cvec%7Bx%7D%5E%7B%28i%29%7D%2Bb+%5C%5C%5C%5C+%5Cvec%7Bw%7D%3D%5Bw_1%2Cw_2%2C%5Ccdots%2Cw_n%5D+%5C%5C%5C%5C+%5Cvec%7Bx%7D%5E%7B%28i%29%7D%3D%5Bx_1%5E%7B%28i%29%7D%2Cx_2%5E%7B%28i%29%7D%2C%5Ccdots%2Cx_n%5E%7B%28i%29%7D%5D+&bg=ffffff&fg=000&s=1&c=20201002)
If we put all the training examples together, it will form a matrix. Generally, we use capital X to represent the matrix formed by training examples. Therefore, the model function can be written as follows:

The vectorized fw,b is very similar to the model function of simple linear regression, and their implementation is similar. The difference is that the vectorized fw,b uses the dot product to multiply X and w.
import numpy as np
def f_wb(X, w, b):
"""
Linear regression model
Parameters
----------
X: (ndarray (m, n))
m is the number of samples, n is the number of features
w: (ndarray (n,))
b: (scalar)
Returns
-------
(ndarray (m,))
"""
return np.dot(X, w) + bCost Function
The cost function of Multiple linear regression is as follows.

In the following code, compute_cost() implements the vectorized cost function.
import numpy as np
def compute_cost(X, y, w, b):
"""
Compute cost
Parameters
----------
X: (ndarray (m, n))
m is the number of samples, n is the number of features
y: (ndarray (m,))
w: (ndarray (n,))
b: (scalar)
Returns
-------
(scalar)
"""
m = X.shape[0]
y_hat = f_wb(X, w, b)
return 1 / (2 * m) * np.sum((y_hat - y) ** 2)Gradient Descent
The gradient descent of multiple linear regression is as follows. It can be understood from the formula that we need to calculate the parameter wj of each feature. Then, calculate the partial derivative of J(w,b) for each wj.

The partial derivatives of J(w,b) for each wj and b are as follows:

The following code implements the calculation of the partial derivatives of J(w,b) with respect to wj and b.
import numpy as np
def compute_gradient(X, y, w, b):
"""
Compute the gradient for linear regression
Parameters
----------
X: (ndarray (m, n))
m is the number of samples, n is the number of features
y: (ndarray (m,))
w: (ndarray (n,))
b: (scalar)
Returns
-------
dj_dw: (ndarray (n,))
dj_db: (scalar)
"""
m = X.shape[0]
y_hat = f_wb(X, w, b)
dj_dw = 1 / m * np.dot(X.T, y_hat - y)
dj_db = 1 / m * np.sum(y_hat - y)
return dj_dw, dj_dbThe following code implements gradient descent.
import numpy as np
def perform_gradient_descent(X, y, w_init, b_init, alpha, epochs):
"""
Perform gradient descent
Parameters
----------
X: (ndarray (m, n))
m is the number of samples, n is the number of features
y: (ndarray (m,))
w_init: (ndarray (n,))
b_init: (scalar)
alpha: (scalar)
epochs: (int)
Returns
-------
w: (ndarray (n,))
b: (scalar)
"""
w = w_init
b = b_init
for i in range(epochs):
dj_dw, dj_db = compute_gradient(X, y, w, b)
w -= alpha * dj_dw
b -= alpha * dj_db
print(f'Epoch {i + 1}, Cost: {compute_cost(X, y, w, b)}')
return w, bIn the following code, we set the learning rate to 0.0000001 and the number of iterations to 1000 times. Then, output the change in cost at each iteration. It can be seen that the cost decreases quickly at the beginning and then becomes slower and slower.
X_train = np.array([[2104, 5, 1, 45], [1416, 3, 2, 40], [852, 2, 1, 35]]) y_train = np.array([460, 232, 178]) w, b = perform_gradient_descent(X_train, y_train, np.zeros(X_train.shape[1]), 0., 0.0000001, 1000) (w, b) # Output # Epoch 1, Cost: 28989.111501449268 # Epoch 2, Cost: 17092.48916583246 # Epoch 3, Cost: 10198.319962562276 # Epoch 4, Cost: 6203.104159134617 # Epoch 5, Cost: 3887.8502848154976 # Epoch 6, Cost: 2546.145030983679 # Epoch 7, Cost: 1768.6173933475704 # Epoch 8, Cost: 1318.0342718091906 # Epoch 9, Cost: 1056.9175763423789 # Epoch 10, Cost: 905.59787958039 # Epoch 11, Cost: 817.9062417617257 # Epoch 12, Cost: 767.0874687152398 # Epoch 13, Cost: 737.6367552876493 # Epoch 14, Cost: 720.5689683005712 # Epoch 15, Cost: 710.6771659424062 # ... # Epoch 995, Cost: 694.9420356037724 # Epoch 996, Cost: 694.9399054268631 # Epoch 997, Cost: 694.9377752873567 # Epoch 998, Cost: 694.9356451852516 # Epoch 999, Cost: 694.9335151205503 # Epoch 1000, Cost: 694.9313850932496 # (array([ 0.20253263, 0.00112386, -0.00213202, -0.00933401]), np.float64(-0.0003572563919114557))
The following shows using the calculated w and b to predict ŷ and calculate the residual of ŷ and y.
y_hat = f_wb(X_train, w, b) (y_train, y_hat) # Output # (array([460, 232, 178]), array([425.71175692, 286.41159657, 172.23087045])) cost = compute_cost(X_train, y_train, w, b) cost # Output # np.float64(694.9313850932496)
Conclusion
Linear regression is a relatively simple model. Great for explaining the mathematics behind the model. However, it is still very practical. Simple linear regression has only one variable and may not be very practical. In practice, we use vectorized multiple linear regression because usually the variable will be larger than one, and there may be many.
References
- Andrew Ng, Machine Learning Specialization, Coursera.
- 西内啓,統計学が最強の学問である[数学編]――データ分析と機械学習のための新しい教科書,ダイヤモンド社。









