
Word2Vec 是一種用於學習詞嵌入(word embeddings)的模型,透過 neural networks 將詞彙與其語義轉換為向量。Word2Vec 提供 CBOW 與 Skip-gram 兩種訓練方法,並透過 Negative Sampling 和 Subsampling 技術提升效率。本文章將介紹 Word2Vec 的基本原理與訓練方法。
Table of Contents
詞嵌入(Word Embeddings)
在自然語言處理(NLP)中,詞嵌入(word embeddings)是單詞的一種表示方式。這種表示方式是用某種方式將單詞及其語義編碼成一個實數向量(real-valued vector)。這使得在向量空間中相近的單詞,其語義也相似。因此,在這樣的向量空間中,假設已知德國與其首都柏林和法國的向量,我們可以利用下面的式子推導出法國的首都巴黎的向量。

每一個單詞會被表示成一個 vector;而一堆單詞則就會構成一個 word embedding matrix。在下面的 word embedding matrix 中,每一個單詞表示為一個 300 維度的 vector。
| Word | Feature 1 | Feature 2 | … | Feature 300 |
|---|---|---|---|---|
| cat | 0.12 | -0.45 | … | 1.24 |
| dog | 0.10 | -0.50 | … | 1.30 |
| king | 0.80 | -0.22 | … | 0.65 |
| queen | 0.85 | -0.20 | … | 0.70 |
Word2Vec 模型
Word2Vec 是由 Google 的 Tomas Mikolov et al. 在 2013 年提出的一種 word embeddings 學習模型。Word2Vec 模型可以從一個給定的語料庫(corpus)中學習一個 word embedding matrix。該模型包含兩種架構,分別為 Continuous Bad-of-Words model(CBOW)和 Continuous Skip-gram model。
Continuous Bag-of-Words Model (CBOW)
CBOW 的學習方法是,根據中心詞(center word)的上下文(context words)來預測 center word。如下圖中,center word 是 fox,而 context 的 window 大小為 2,所以 context 為 fox 的前面兩個字和後面兩個字。在訓練時,我們會計算 context words 的 average word embedding 作為 input,而 true label 是 center word fox。

前向傳播(Forward Propagation)
CBOW 使用只有一層 hidden layer 的 neural network 來學習 word embeddings。在訓練完成後,該 hidden layer 的 weight 就是 word embedding matrix。下圖是 CBOW 的 forward propagation。

CBOW 的 forward propagation 中的公式如下:

其中各個變數的維度如下:
 |  |  | 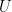 |  |  |
|---|---|---|---|---|---|
 |  |  | | | |
損失函數(Loss Function)
CBOW 的輸出是每一個 word 的機率,所以最後會使用 softmax 作為 output layer 的 activation function。因此,使用 cross-entropy loss 作為它的 loss function。

反向傳播(Backward Propagation)
CBOW 的 backpropagation 中的公式如下:

實作
我們使用 Wikipedia 的 Oolong 文章作為 corpus 來訓練模型。在下面的程式碼中,我們從維基百科下載文章 Oolong,將其按句子拆分,然後將每個句子按單詞拆分。
wiki = wikipediaapi.Wikipedia(user_agent="waynestalk/1.0", language="en")
page = wiki.page("Oolong")
corpus = page.text
nltk.download("punkt")
sentences = nltk.sent_tokenize(corpus)
tokenized_corpus = [[word.lower() for word in nltk.word_tokenize(sentence) if word.isalpha()] for sentence in sentences]
vocab = set([word for sentence in tokenized_corpus for word in sentence])
word_to_index = {word: i for i, word in enumerate(vocab)}
index_to_word = {i: word for i, word in enumerate(vocab)}
len(vocab)
# Output
580我們使用 PyTorch 來實作 CBOW,可以看出其實作相當地簡單。其中 embedding 是 hidden layer,而 linear 是 output layer。在 foward() 中,我們將 input 轉換為向量,然後取這些向量的平均。最後,再將平均傳給 output layer。
class CBOW(nn.Module):
def __init__(self, vocab_size, embedding_size):
super(CBOW, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_size)
self.linear = nn.Linear(embedding_size, vocab_size)
def forward(self, context_words):
vectors = self.embedding(context_words)
average_vector = torch.mean(vectors, dim=0)
return self.linear(average_vector)再來,我們要準備訓練資料。對每個句子中的每個單詞和其前後各兩個單詞,我們可以將其視為一筆訓練資料。
window_size = 2
training_pairs = []
for sentence in tokenized_corpus:
for i in range(window_size, len(sentence) - window_size):
context = [sentence[j] for j in range(i - window_size, i + window_size + 1) if j != i]
training_pairs.append((context, sentence[i]))
training_pairs[:5]
# Output
[(['oolong', 'uk', 'simplified', 'chinese'], 'us'),
(['uk', 'us', 'chinese', '乌龙茶'], 'simplified'),
(['us', 'simplified', '乌龙茶', 'traditional'], 'chinese'),
(['simplified', 'chinese', 'traditional', 'chinese'], '乌龙茶'),
(['chinese', '乌龙茶', 'chinese', '烏龍茶'], 'traditional')]以下程式碼中,CBOW 模型將從訓練資料中學習 word embeddings。我們設定 embedding 的 dimension 為 1000。所以,embedding matrix 會是  。
。
model = CBOW(len(vocab), 1000)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
epochs = 500
start_time = time.time()
for epoch in range(epochs):
total_loss = 0
for context, target in training_pairs:
context_tensor = torch.tensor([word_to_index[word] for word in context], dtype=torch.long)
target_tensor = torch.tensor([word_to_index[target]], dtype=torch.long)
output = model(context_tensor)
loss = loss_function(output.unsqueeze(0), target_tensor)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if epoch == 0 or (epoch + 1) % 100 == 0:
print(f"Epoch: {epoch}, Loss: {total_loss}")
end_time = time.time()
print(f"Training time: {end_time - start_time} seconds")
# Output
Epoch: 0, Loss: 6856.648630566895
Epoch: 99, Loss: 65.55343400325
Epoch: 199, Loss: 58.981725521754925
Epoch: 299, Loss: 55.93582288858761
Epoch: 399, Loss: 53.808607134100384
Epoch: 499, Loss: 52.07664276908599
Training time: 304.94574093818665 seconds以下程式碼印出 oolong 的 word embedding。
word = "oolong"
word_index_tensor = torch.tensor(word_to_index[word], dtype=torch.long)
embedding_vector = model.embedding(word_index_tensor).detach().numpy()
print(f"Embedding {embedding_vector.shape} for '{word}': {embedding_vector}")
# Output
Embedding (1000,) for 'oolong': [ 1.41568875e+00 -3.54769737e-01 -1.37265265e+00 -6.58394694e-01
8.31549525e-01 -9.42143202e-01 9.70315874e-01 -5.99202693e-01
1.84273362e+00 9.20817614e-01 -5.58760583e-01 1.00353360e+00
-2.15644687e-01 -4.58650626e-02 -2.28673637e-01 1.86233068e+00
...以下程式碼顯示,我們可以用學習到的 embedding matrix,用 cosine similarity 來計算兩個句子的相似性。
sentence1 = "tea is popular in taiwan".split()
sentence2 = "oolong is famous in taiwan".split()
sentence1_embeddings = [model.embedding(torch.tensor(word_to_index[word], dtype=torch.long)).detach() for word in sentence1]
sentence2_embeddings = [model.embedding(torch.tensor(word_to_index[word], dtype=torch.long)).detach() for word in sentence2]
vector1 = torch.stack(sentence1_embeddings).mean(dim=0)
vector2 = torch.stack(sentence2_embeddings).mean(dim=0)
cosine_sim = nn.CosineSimilarity(dim=0)
similarity = cosine_sim(vector1, vector2).item()
print(f"Sentence 1: {sentence1}")
print(f"Sentence 2: {sentence2}")
print(f"Similarity between sentences: {similarity}")
# Output
Sentence 1: ['tea', 'is', 'popular', 'in', 'taiwan']
Sentence 2: ['oolong', 'is', 'famous', 'in', 'taiwan']
Similarity between sentences: 0.6053189635276794我們也可以自己計算 cosine similarity,如下。
sentence1_embeddings = [model.embedding(torch.tensor(word_to_index[word], dtype=torch.long)).detach().numpy() for word in sentence1] sentence2_embeddings = [model.embedding(torch.tensor(word_to_index[word], dtype=torch.long)).detach().numpy() for word in sentence2] vector1 = np.mean(sentence1_embeddings, axis=0) vector2 = np.mean(sentence2_embeddings, axis=0) similarity = (np.dot(vector1, vector2) / (np.linalg.norm(vector1) * np.linalg.norm(vector2)))
在以下程式碼裡,我們用 principal component analysis(PCA)來顯示 word embeddings 的分佈。
word_embeddings_tensor = model.embedding.weight.detach()
U, S, V = torch.pca_lowrank(word_embeddings_tensor, q=2)
reduced_embeddings = U.numpy()
plt.figure(figsize=(8, 6))
for word, index in word_to_index.items():
x, y = reduced_embeddings[index]
plt.scatter(x, y, marker='o', color='blue')
tea_index = word_to_index['tea']
x, y = reduced_embeddings[tea_index]
plt.scatter(x, y, marker='o', color='red')
plt.text(x, y, 'tea', fontsize=8)
oolong_index = word_to_index['oolong']
x, y = reduced_embeddings[oolong_index]
plt.scatter(x, y, marker='o', color='red')
plt.text(x, y, 'oolong', fontsize=8)
plt.xlabel("PCA Component 1")
plt.ylabel("PCA Component 2")
plt.title("CBOW Word Embeddings Visualization of Corpus 'Oolong`")
plt.grid(True)
plt.show()
Continuous Skip-gram Model
Skip-gram 的學習發法與 CBOW 相反。它是用 center word 來預測 context words。如下圖中,center word 是 fox,而 context 的 window 大小為 2,所以 context 為 fox 的前面兩個字和後面兩個字。這樣就會有四筆訓練資料,center word 作為 input,而每筆資料的 output 分別為 context words。

前向傳播(Forward Propagation)
Skip-gram 使用只有一層 hidden layer 的 neural network 來學習 word embeddings。在訓練完成後,該 hidden layer 的 weight 就是 word embedding matrix。下圖是 Skip-gram 的 forward propagation。

Skip-gram 的 forward propagation 中的公式如下:

其中各個變數的維度如下:
|  | | | | |
|---|---|---|---|---|---|
| | | | | |
損失函數(Loss Function)
Skip-gram 的輸出是每一個 word 的機率,所以最後會使用 softmax 作為 output layer 的 activation function。因此,使用 cross-entropy loss 作為它的 loss function。

反向傳播(Backward Propagation)
Skip-gram 的 backpropagation 中的公式如下:

實作
我們使用 PyTorch 來實作 Skip-gram,如下。
class SkipGram(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(SkipGram, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.linear = nn.Linear(embedding_dim, vocab_size)
def forward(self, word):
vector = self.embedding(word)
return self.linear(vector)我們同樣使用 Wikipedia 的 Oolong 文章作為 corpus。每個句子中的每個單詞的 context 是其前後各兩個單詞,因此每個單詞有多個 context words。我們可以將每個單詞和其一個 context word 視為一筆訓練資料。
window_size = 2
training_pairs = []
for sentence in tokenized_corpus:
for i, target_word in enumerate(sentence):
context_indices = (list(range(max(i - window_size, 0), i)) +
list(range(i + 1, min(i + window_size + 1, len(sentence)))))
for context_index in context_indices:
training_pairs.append((target_word, sentence[context_index]))
training_pairs[:5]以下程式碼中,Skip-gram 模型將從訓練資料中學習 word embeddings。我們設定 embedding 的 dimension 為 1000。所以,embedding matrix 會是 。
model = SkipGram(len(vocab), 1000)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
epochs = 500
start_time = time.time()
for epoch in range(epochs):
total_loss = 0
for target, context in training_pairs:
target_tensor = torch.tensor([word_to_index[target]], dtype=torch.long)
context_tensor = torch.tensor([word_to_index[context]], dtype=torch.long)
output = model(target_tensor)
loss = loss_function(output, context_tensor)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if epoch == 0 or (epoch + 1) % 100 == 0:
print(f"Epoch: {epoch}, Loss: {total_loss}")
end_time = time.time()
print(f"Training time: {end_time - start_time} seconds")
# Output
Epoch: 0, Loss: 39987.801153186476
Epoch: 99, Loss: 30384.4197357425
Epoch: 199, Loss: 26906.040692283364
Epoch: 299, Loss: 24592.846442646056
Epoch: 399, Loss: 22867.418499057472
Epoch: 499, Loss: 21502.15208007075
Training time: 1074.5490338802338 seconds在下圖中,我們用 principal component analysis(PCA)來顯示 word embeddings 的分佈。

CBOW 和 Skip-gram 的比較
在上述中,我們可以看到 CBOW 和 Skip-gram 對相同的 corpus 的訓練時間。CBOW 是 304 秒,而 Skip-gram 是 1074 秒。CBOW 的每一個 center word 和其 context words,成為一筆訓練資料。但是,Skip-gram 的每一個 center word 和其每一個 context word,都成為一筆訓練資料。因此 Skip-gram 的訓練資料比較大。
在 PCA 上可以看出,Skip-gram 學習的 word embeddings,相關的詞比較靠近一起,所以它能更細緻地學習詞與詞的關係。
提高 Word2Vec 訓練效率
Skip-gram 可以學習高質量的 word embeddings,它可以捕獲單詞在語法和語意上的關係。但是,在訓練大規模的 corpus 時,我們需要改進 skip-gram 的效能來加速訓練。
Negative Sampling
在 Skip-gram 中,給定一個 target word 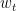 ,我們要預測它的 context word
,我們要預測它的 context word  。我們用
。我們用 softmax 計算以下的機率。在分母的地方,我們要加總所有單詞的機率。而當  很大時,它將會花費相當多的時間。
很大時,它將會花費相當多的時間。

與其計算整個字彙的機率,negative sampling 簡化問題,如下:
- 對於每個 (target word, context word),我們希望最大化它們的相似性。
- 對於每個 (target word, random word),我們希望最小化它們的相似性。
Negative sampling 對每一筆資料  ,從字彙中挑選
,從字彙中挑選  個不在 target word 的 context words 裡面的單詞。然後,使用以下的 loss function 來計算 loss。我們要最大化式子中的前半部,也就是 target word 和 context word 的機率。然後,最小化式子中的後半部,也就是 target word 和 negative words 的機率。
個不在 target word 的 context words 裡面的單詞。然後,使用以下的 loss function 來計算 loss。我們要最大化式子中的前半部,也就是 target word 和 context word 的機率。然後,最小化式子中的後半部,也就是 target word 和 negative words 的機率。
![\log\sigma((v^{\prime}_{w_c})^Tv_{w_t})+\displaystyle\sum_{i=1}^k\mathbb{E}_{w_i\sim P_n(w)}\Big[\log\sigma(-(v^{\prime}_{wi})^Tv_{w_t})\Big] \\\\ v_w:\text{the input vector representations of }w \\\\ v^{\prime}_w:\text{the output vector representations of }w \\\\ k:\text{the number negative words} \\\\ \hphantom{k:}\text{5-20 for small training dataset} \\\\ \hphantom{k:}\text{2-5 for large training dataset} \mathbb{E}:\text{the expectation operator} \\\\ w_i\sim P_n(w):\text{mean }w_i\text{ is sampled from the negative sampling distribution }P_n(w)](https://s0.wp.com/latex.php?latex=%5Clog%5Csigma%28%28v%5E%7B%5Cprime%7D_%7Bw_c%7D%29%5ETv_%7Bw_t%7D%29%2B%5Cdisplaystyle%5Csum_%7Bi%3D1%7D%5Ek%5Cmathbb%7BE%7D_%7Bw_i%5Csim+P_n%28w%29%7D%5CBig%5B%5Clog%5Csigma%28-%28v%5E%7B%5Cprime%7D_%7Bwi%7D%29%5ETv_%7Bw_t%7D%29%5CBig%5D+%5C%5C%5C%5C+v_w%3A%5Ctext%7Bthe+input+vector+representations+of+%7Dw+%5C%5C%5C%5C+v%5E%7B%5Cprime%7D_w%3A%5Ctext%7Bthe+output+vector+representations+of+%7Dw+%5C%5C%5C%5C+k%3A%5Ctext%7Bthe+number+negative+words%7D+%5C%5C%5C%5C+%5Chphantom%7Bk%3A%7D%5Ctext%7B5-20+for+small+training+dataset%7D+%5C%5C%5C%5C+%5Chphantom%7Bk%3A%7D%5Ctext%7B2-5+for+large+training+dataset%7D+%5Cmathbb%7BE%7D%3A%5Ctext%7Bthe+expectation+operator%7D+%5C%5C%5C%5C+w_i%5Csim+P_n%28w%29%3A%5Ctext%7Bmean+%7Dw_i%5Ctext%7B+is+sampled+from+the+negative+sampling+distribution+%7DP_n%28w%29+&bg=ffffff&fg=000&s=1&c=20201002)
那要如何挑選 negative words 呢?Negative sampling 是依據以下的分佈來挑選 negative samples。

因此,後半段的式子為:
![\displaystyle\sum_{i=1}^k\mathbb{E}_{w_i\sim P_n(w)}\Big[\log\sigma(-(v^{\prime}_{wi})^Tv_{w_t})\Big]=\displaystyle\sum_{i=1}^k P_n(w_i)\Big[\log\sigma(-(v^{\prime}_{wi})^Tv_{w_t})\Big]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Csum_%7Bi%3D1%7D%5Ek%5Cmathbb%7BE%7D_%7Bw_i%5Csim+P_n%28w%29%7D%5CBig%5B%5Clog%5Csigma%28-%28v%5E%7B%5Cprime%7D_%7Bwi%7D%29%5ETv_%7Bw_t%7D%29%5CBig%5D%3D%5Cdisplaystyle%5Csum_%7Bi%3D1%7D%5Ek+P_n%28w_i%29%5CBig%5B%5Clog%5Csigma%28-%28v%5E%7B%5Cprime%7D_%7Bwi%7D%29%5ETv_%7Bw_t%7D%29%5CBig%5D+&bg=ffffff&fg=000&s=1&c=20201002)
實作
首先如同在 Skip-gram 章節中準備好訓練資料。然後,我們要計算 negative sampling distribution  。
。
word_frequency = np.zeros(len(vocab))
for sentence in tokenized_corpus:
for word in sentence:
word_frequency[word_to_index[word]] += 1
word_distribution = word_frequency / word_frequency.sum()
unigram_distribution = word_distribution ** (3 / 4)
unigram_distribution = unigram_distribution / unigram_distribution.sum()
print(f"Unigram distribution: {unigram_distribution[:5]}")
def get_negative_samples(num_samples, context_index):
negative_samples = []
while len(negative_samples) < num_samples:
sample_index = np.random.choice(len(vocab), p=unigram_distribution)
if sample_index != context_index:
negative_samples.append(sample_index)
return negative_samples接下來將 SkipGram 模型改為以下。程式碼中的 input_embedding 就是  ,而 output_embedding 就是
,而 output_embedding 就是  。
。
class SkipGramWithNegativeSampling(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(SkipGramWithNegativeSampling, self).__init__()
self.input_embedding = nn.Embedding(vocab_size, embedding_dim)
self.output_embedding = nn.Embedding(vocab_size, embedding_dim)
nn.init.uniform_(self.input_embedding.weight, a=-0.5, b=0.5)
nn.init.uniform_(self.output_embedding.weight, a=-0.5, b=0.5)
def forward(self, target_word, context_word, negative_samples):
target_embedding = self.input_embedding(target_word)
context_embedding = self.output_embedding(context_word)
negative_samples_embeddings = self.output_embedding(negative_samples)
pos_score = (target_embedding * context_embedding).sum(dim=1)
pos_loss = -torch.sigmoid(pos_score).log()
neg_score = torch.bmm(negative_samples_embeddings, target_embedding.unsqueeze(2)).squeeze(2)
neg_loss = -torch.sigmoid(-neg_score).log()
neg_loss = neg_loss.sum(dim=1)
return (pos_loss + neg_loss).mean()然後,我們用以下程式碼來訓練 Skip-gram 模型。
model = SkipGramWithNegativeSampling(len(vocab), 1000)
num_negative_samples = 5
optimizer = optim.SGD(model.parameters(), lr=0.01)
epochs = 500
start_time = time.time()
for epoch in range(epochs):
total_loss = 0
for target, context in training_pairs:
target_tensor = torch.tensor([word_to_index[target]], dtype=torch.long)
context_index = word_to_index[context]
context_tensor = torch.tensor([context_index], dtype=torch.long)
negative_samples_tensor = torch.tensor(
[get_negative_samples(num_negative_samples, context_index)], dtype=torch.long
)
loss = model(target_tensor, context_tensor, negative_samples_tensor)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if epoch == 0 or (epoch + 1) % 100 == 0:
print(f"Epoch: {epoch}, Loss: {total_loss}")
end_time = time.time()
print(f"Training time: {end_time - start_time} seconds")
# Output
Epoch: 0, Loss: 28936.812749773264
Epoch: 99, Loss: 3952.563685086556
Epoch: 199, Loss: 3894.3744740486145
Epoch: 299, Loss: 3726.271819884423
Epoch: 399, Loss: 3714.307072382886
Epoch: 499, Loss: 3639.7701731920242
Training time: 981.5462839603424 secondsSubsampling of Frequent Words
在大規模的 corpus 中,出現頻率最高的單詞很容易出現上百萬次,如 in、the、a 等。而這些單詞往往提供很少的資訊,反而是一些少見的單詞提供很多的資訊,相對於這些高頻率的單詞,由於出現次數太多,這也會拖慢訓練的速度。所以,subsampling of frequent words 是要減少極常出現的單詞在訓練時的影響。
Subsampling 對每個單詞計算以下的機率,來決定是否要忽略該單詞。

實作
在將 corpus 依句子再依單詞做分割後,我們用 subsampling 來將一些單詞直接移除,如下。
subsampling_threshold = 1e-5
subsampled_tokenized_corpus = []
for sentence in tokenized_corpus:
new_sentence = []
for word in sentence:
index = word_to_index[word]
frequency = word_frequency[index]
if frequency > subsampling_threshold:
drop_probability = 1 - np.sqrt(subsampling_threshold / frequency)
else:
drop_probability = 0
if np.random.rand() > drop_probability:
new_sentence.append(word)
if len(new_sentence) > 0:
subsampled_tokenized_corpus.append(new_sentence)
print(subsampled_tokenized_corpus[:5])Skip-gram 可以同時引入 negative sampling 和 subsampling。所以,模型與訓練的程式碼與 negative sampling 章節中的一樣。你可以從本文章的完整程式碼中,取得這部分的程式碼。
最後,我們用引入 negative sampling 和 subsampling 的 Skip-gram 來學習 word embeddings。在移除一些高頻率出現的單詞後,訓練的時間縮短很多。
model = SkipGramWithNegativeSamplingAndSubsamplingOfFrequentWords(len(vocab), 1000)
num_negative_samples = 5
optimizer = optim.SGD(model.parameters(), lr=0.01)
epochs = 500
start_time = time.time()
for epoch in range(epochs):
total_loss = 0
for target, context in training_pairs:
target_tensor = torch.tensor([word_to_index[target]], dtype=torch.long)
context_index = word_to_index[context]
context_tensor = torch.tensor([context_index], dtype=torch.long)
negative_samples_tensor = torch.tensor(
[get_negative_samples(num_negative_samples, context_index)], dtype=torch.long
)
loss = model(target_tensor, context_tensor, negative_samples_tensor)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if epoch == 0 or (epoch + 1) % 100 == 0:
print(f"Epoch: {epoch}, Loss: {total_loss}")
end_time = time.time()
print(f"Training time: {end_time - start_time} seconds")
# Output
Epoch: 0, Loss: 953.0108479261398
Epoch: 99, Loss: 56.98700549826026
Epoch: 199, Loss: 25.619574746116996
Epoch: 299, Loss: 28.435157721862197
Epoch: 399, Loss: 14.342244805768132
Epoch: 499, Loss: 15.597246480174363
Training time: 26.50890588760376 seconds結語
Word2Vec 是 NLP 中最具影響力的 word embeddings 學習技術之一,透過 CBOW 和 Skip-gram 訓練出語義豐富的 word embeddings。此外,Negative Sampling 和 Subsampling 等技術進一步提升了訓練效率,使得 Word2Vec 成為許多 NLP 應用的基礎。
參考
- Andrew Ng, Deep Learning Specialization, Coursera.
- Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient Estimation of Word Representations in Vector Space. ICLR.
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Distributed Representations of Words and Phrases and their Compositionality. NIPS.









