
在影像辨識領域,多年來一直以卷積神經網路(Convolutional Neural Networks, CNNs)為主。近年,Transformer 在自然語言處理(Natural Language Processing, NLP)領域大放異彩,進而也有將 Transformer 架構應用於影像處理的想法。Vision Transformer 便是基於 Transformer 的影響處理模型。
Table of Contents
Vision Transformer(ViT)架構
Vision Transformer (ViT) 於 2020 年由 Google Research 提出。基於 NLP 中 Transformer 的成功經驗,將其套用至視覺領域。儘管 CNN 在圖像處理表現出色,但其設計本質是局部性的堆疊,對長距離特徵的建模能力有限。研究者希望以 Transformer 的全局注意力(global attention)機制,捕捉圖像中遠距離區塊間的依賴關係,進而提升模型的辨識能力。然而,由於 Transformer 原是為文字序列所設計,如何將一張圖像轉換成可供 Transformer 處理的序列資料,成為 ViT 所需解決的第一步挑戰。
ViT 的整體架構是 Transformer 的 encoder。如果你還不熟悉 Transformer 的話,請先參考以下文章。

作者們希望 ViT 可以使用 Transformer 的原始設計,而且盡可能地不要變動它。然而,傳統Transformer 的輸入是 tokens。所以,必須要將輸入圖像轉換成某種 Transformer 可以接受的輸入格式。
以圖是 ViT 模型的概覽。
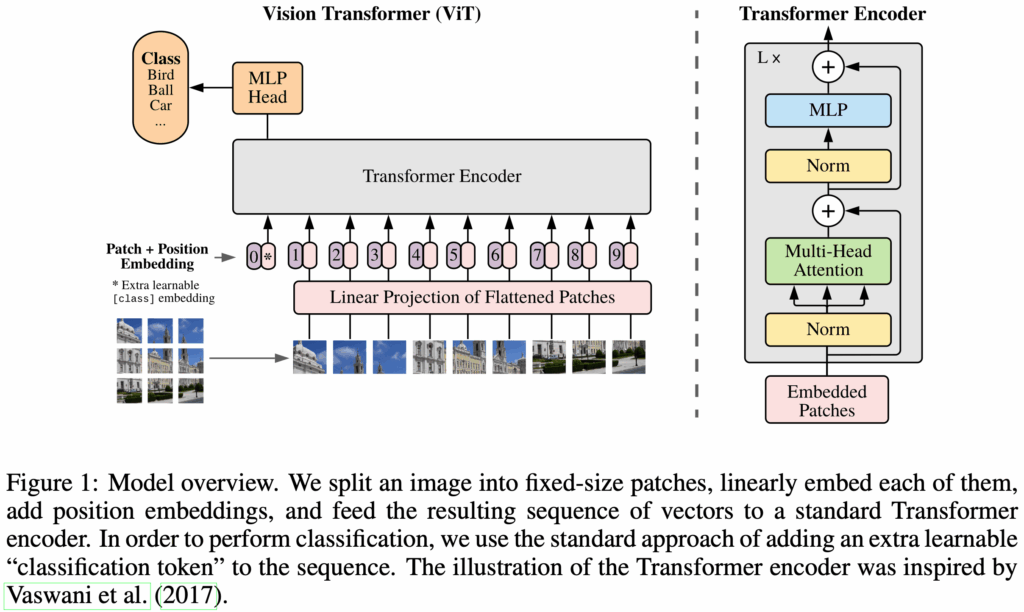
Patch Embeddings
輸入圖像為  ,其中
,其中  是高度,
是高度, 是寬度,
是寬度, 是 channel 數(如,RGB 為 3 channels)。將圖像
是 channel 數(如,RGB 為 3 channels)。將圖像  切割為固定大小的 patches,每一個 patch 的長寬是
切割為固定大小的 patches,每一個 patch 的長寬是  ,再算上 channel,每個 patch 是
,再算上 channel,每個 patch 是  。然後,再將每個 patch 展平成
。然後,再將每個 patch 展平成  的序列。也就是說,圖像 會被 resized 成
的序列。也就是說,圖像 會被 resized 成  ,其中
,其中  是 patches 的數量。
是 patches 的數量。
以傳統 Transformer 的角度來看,一個 patch 就像是一個 token。輸入圖像 有  個 patches,所以會有 的 tokens。
個 patches,所以會有 的 tokens。

接下來,就是要將所有的 patches 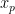 轉換成 Transformer 內部 hidden size 相同的維度
轉換成 Transformer 內部 hidden size 相同的維度  。透過一個可訓練線性投影(trainable linear projection)將維度
。透過一個可訓練線性投影(trainable linear projection)將維度  映射至 。這個 trainable linear projection 的輸出稱為 patch embeddings。
映射至 。這個 trainable linear projection 的輸出稱為 patch embeddings。
以傳統 Transformer 的角度來看,trainable linear projection 對應於 Transformer 中的 input embedding。

Classification Head
類似於 BERT 的 [CLS] token,在 patch embeddings 的第一個位置插入一個 learnable embedding  。在 Transformer encoder 輸出的 final hidden state 中,
。在 Transformer encoder 輸出的 final hidden state 中, 相對應的第一個 state 是
相對應的第一個 state 是  。 將作為整個圖像表徵(image representation)
。 將作為整個圖像表徵(image representation) 。
。
在預訓練(pre-training)和微調(fine-tuning)期間,都要在  的位置上插入這個分類頭(classification head)
的位置上插入這個分類頭(classification head) 。Classification head 在 pre-training 時是由一個具有一個隱藏層的多層感知器(a MLP with one hidden layer)實作;而在 fine-tuning 時,則是由一個單一的線性層(a single linear layer)實作。
。Classification head 在 pre-training 時是由一個具有一個隱藏層的多層感知器(a MLP with one hidden layer)實作;而在 fine-tuning 時,則是由一個單一的線性層(a single linear layer)實作。

Position Embeddings
為了保留位置資訊(position information),在 patch embeddings 後面加入 position embeddings  。ViT 使用標準的 learnable 1D position embeddings,因為作者們並未觀察到使用更進階的 2D-aware position embeddings 能帶來顯著的效能提升。最終所得到的 embedding vectors 序列會作為 Transformer encoder 的輸入。
。ViT 使用標準的 learnable 1D position embeddings,因為作者們並未觀察到使用更進階的 2D-aware position embeddings 能帶來顯著的效能提升。最終所得到的 embedding vectors 序列會作為 Transformer encoder 的輸入。

整合 Transformer Encoder
將圖像 切分成 個 patches ,並映射成 patch embeddings。然後,再前面插入一個 classification head $x_class$,再加上 position embedding 。最終得到的 embedding vectors 作為 Transformer encoder 的輸入。在 encoder 中最後一個 block 的輸出  中,第一個 hidden state 將作為輸入圖像的 image representation。
中,第一個 hidden state 將作為輸入圖像的 image representation。

歸納偏差(Inductive Bias)
在學習理論中,模型之所以能從有限資料中泛化到未見過的資料,必須依賴某些先驗假設(prior assumptions)。這些假設就構成了模型的歸納偏差(inductive bias)。它幫助模型在資料不足或雜訊很多時仍能收斂到合理的解。
CNN 假設圖像具有局部性(locality)與平移等變性(translation equivariance),並透過卷積核(kernel)進行區域特徵萃取、權重共享與空間結構保留。也就是說,鄰近像素組成區域特徵、物件在圖上可任意出現,所以 kernel 滑動整張圖即可捕捉模式。這些 inductive biases 幫助 CNN 在小資料下也能有效學習。
ViT 將圖像轉為 patch 序列後交給 Transformer 自行建模特徵間的關係。這樣的設計哲學是,給予足夠資料與模型容量,模型應該能自己學出最合適的表示方式,而不依賴人為先驗。在 ViT 中,只有 MLP layers 有 locality 和 translation equivariance,而 self-attention layers 是 global。ViT 缺乏 locality 與 translation equivariance,幾乎沒有 inductive bias。因此,需要大量資料來自行學會這些模式。這導致 ViT 在資料不足時表現不佳,但在大規模資料訓練下,能展現更高的靈活性與泛化能力。
實驗
模型變種(Model Variants)
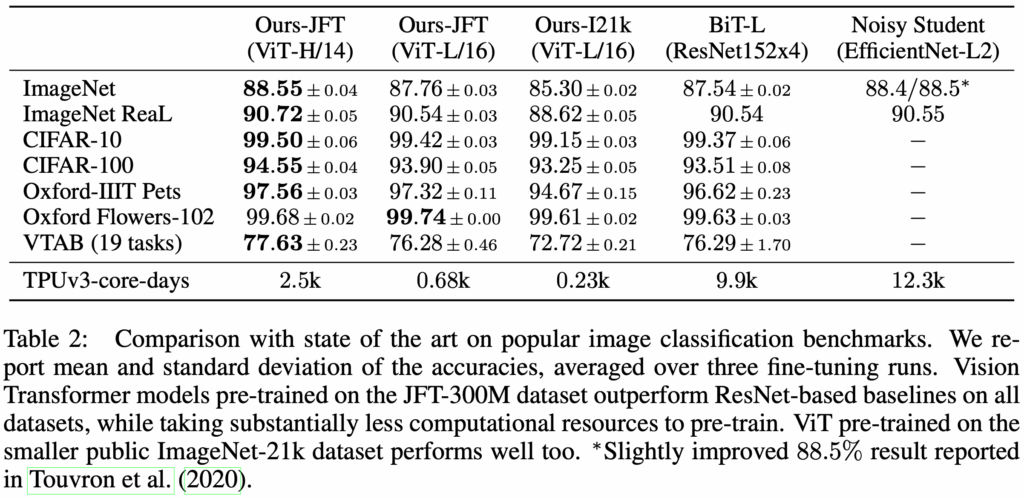
作者們訓練了數個個模型變種,其參數如下表所示。ViT 的模型名稱通常包含模型大小與 input patch size。例如,Vit-L/16 是指 Large variant 且  input patch size。
input patch size。
| Model | Layers | Hidden size D | MLP size | Heads | Params |
|---|---|---|---|---|---|
| ViT-Base | 12 | 768 | 3072 | 12 | 86M |
| ViT-Large | 24 | 1024 | 4096 | 16 | 307M |
| ViT-Huge | 32 | 1280 | 5120 | 16 | 632M |
效能表現
ViT 在中小型資料集 ImageNet-1k 上 pre-training 的模型,表現不如同等規模的 ResNet。這是因為 CNN 內建了強烈的 inductive bias,如 translation equivariance 與 locality 特徵萃取能力,使得它能在有限資料下有效學習。而 ViT 必須從資料中自行學會這些性質,導致其資料效率較差。
不過,當 ViT 在大型資料集 ImageNet-21k 或 JFT-300M 上 pre-training 的模型,再轉移學習到目標任務時,其表現便能超越 ResNet。
實作
Patch Embedding
這部分的輸入是一個圖像,而輸出是 patch embeddings。所以,我們要先將圖像切成 個 patches,再將每個 patch 展平成一維的相量,最後再應由一個 learnable linear projection 映射至維度 。
這個流程相當於 convolutional layer 所做的事情,如下。
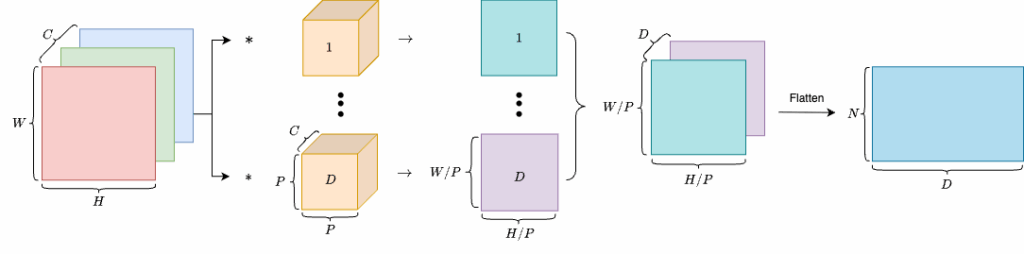
所以,我們可以使用 convolution layer 將圖像由  轉換成
轉換成  ,再展平成
,再展平成  ,也就是
,也就是  。最後,將兩個維度置換成
。最後,將兩個維度置換成  。
。
class PatchEmbedding(nn.Module):
def __init__(self, patch_size=16, in_channels=3, embed_dim=768):
"""
Patch Embedding Layer for Vision Transformer.
Args:
patch_size (int): Size of the patches to be extracted from the input image.
in_channels (int): Number of input channels in the image (e.g., 3 for RGB).
embed_dim (int): Dimension of the embedding space to which each patch will be projected.
"""
super(PatchEmbedding, self).__init__()
self.patch_size = patch_size
self.proj = nn.Conv2d(
in_channels=in_channels,
out_channels=embed_dim,
kernel_size=patch_size,
stride=patch_size,
)
def forward(self, x):
"""
Forward pass of the Patch Embedding Layer.
Args:
x (torch.Tensor): Input tensor of shape (B, C, H, W) where
- B is batch size
- C is number of channels
- H is height
- W is width
Returns:
x (torch.Tensor): Output tensor of shape (B, D, H/P, W/P) where
- D is the embedding dimension
- H/P and W/P are the height and width of the patches.
"""
x = self.proj(x) # (B, D, H/P, W/P)
x = x.flatten(2) # (B, D, H/P * W/P)
x = x.transpose(1, 2) # (B, H/P * W/P, D)
return xTransformer Encoder
以下是 Transformer encoder 各部分的實作。
class MultiHeadSelfAttention(nn.Module):
def __init__(self, dim, num_heads=12, qkv_bias=True, dropout=0.1, attention_dropout=0.1):
"""
Multi-Head Self-Attention Layer.
Args:
dim (int): Dimension of the input features.
num_heads (int): Number of attention heads.
qkv_bias (bool): Whether to add a bias term to the query, key, and value projections.
dropout (float): Dropout rate applied to the output of the MLP and attention layers.
attention_dropout (float): Dropout rate applied to the attention weights.
"""
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.scale = self.head_dim ** -0.5 # Scaled Dot-Product Attention 中的 √d_k
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attention_dropout = nn.Dropout(attention_dropout)
self.projection = nn.Linear(dim, dim)
self.projection_dropout = nn.Dropout(dropout)
def forward(self, x):
"""
Forward pass of the Multi-Head Self-Attention Layer.
Args:
x (torch.Tensor): Input tensor of shape (B, N, D) where
- B is batch size
- N is the number of patches (or tokens)
- D is the embedding dimension
Returns:
out (torch.Tensor): Output tensor of shape (B, N, D) after applying multi-head self-attention.
"""
B, N, C = x.shape
qkv = self.qkv(x) # (B, N, 3C)
qkv = qkv.reshape(B, N, 3, self.num_heads, self.head_dim) # (B, N, 3, H, D)
qkv = qkv.permute(2, 0, 3, 1, 4) # (3, B, H, N, D)
q, k, v = qkv[0], qkv[1], qkv[2]
# Scaled Dot-Product Attention
attn = (q @ k.transpose(-2, -1)) * self.scale # (B, H, N, N)
attn = attn.softmax(dim=-1)
attn = self.attention_dropout(attn)
out = (attn @ v) # (B, H, N, D)
out = out.transpose(1, 2).reshape(B, N, C) # (B, N, D)
out = self.projection(out)
out = self.projection_dropout(out)
return outclass MLPBlock(nn.Module):
def __init__(self, in_dim, hidden_dim, dropout=0.1):
"""
MLP Block for Transformer Encoder.
Args:
in_dim (int): Input dimension of the features.
hidden_dim (int): Hidden dimension of the MLP.
dropout (float): Dropout rate applied to the output of the MLP.
"""
super().__init__()
self.fc1 = nn.Linear(in_dim, hidden_dim)
self.act = nn.GELU()
self.fc2 = nn.Linear(hidden_dim, in_dim)
self.drop = nn.Dropout(dropout)
def forward(self, x):
"""
Forward pass of the MLP Block.
Args:
x (torch.Tensor): Input tensor of shape (B, N, D) where
- B is batch size
- N is the number of patches (or tokens)
- D is the embedding dimension
Returns:
x (torch.Tensor): Output tensor of the same shape as input, after applying MLP.
"""
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return xclass EncoderBlock(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4.0, qkv_bias=True, dropout=0.1, attention_dropout=0.1):
"""
Transformer Encoder Block.
Args:
dim (int): Dimension of the input features.
num_heads (int): Number of attention heads.
mlp_ratio (float): Ratio of the hidden dimension in the MLP block to the embedding dimension.
qkv_bias (bool): Whether to add a bias term to the query, key, and value projections.
dropout (float): Dropout rate applied to the output of the MLP and attention layers.
attention_dropout (float): Dropout rate applied to the attention weights.
"""
super().__init__()
self.norm1 = nn.LayerNorm(dim)
self.self_attention = MultiHeadSelfAttention(
dim=dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
dropout=dropout,
attention_dropout=attention_dropout,
)
self.norm2 = nn.LayerNorm(dim)
self.mlp = MLPBlock(
in_dim=dim,
hidden_dim=int(dim * mlp_ratio),
dropout=dropout,
)
def forward(self, x):
"""
Forward pass of the Transformer Encoder Block.
Args:
x (torch.Tensor): Input tensor of shape (B, N, D) where
- B is batch size
- N is the number of patches (or tokens)
- D is the embedding dimension
Returns:
x (torch.Tensor): Output tensor of the same shape as input, after applying self-attention and MLP.
"""
x = x + self.self_attention(self.norm1(x))
x = x + self.mlp(self.norm2(x))
return xVision Transformer
以下是 Vision Transformer 的實作。它整合了以上的各個部件。它將影像輸入給 PatchEmbedding 後,得到 patch embeddings,並在其前面插入一個 classification head。最後,再加上 positional encoding。最後,cls_output 就是 ,也就是輸入圖像的 image representation。
我們在此實作的是一個分類圖像的 ViT,因此最後會再經由一個 linear projection 轉換成類別編號。如果要用於不同的任務的話,就需要替換這部分。
class VisionTransformer(nn.Module):
def __init__(
self,
img_size=224,
patch_size=16,
in_channels=3,
num_classes=1000,
embed_dim=768,
num_layers=12,
num_heads=12,
mlp_ratio=4.0,
qkv_bias=True,
dropout=0.1,
attention_dropout=0.1,
):
"""
Vision Transformer (ViT) model.
Args:
img_size (int): Size of the input image (assumed square).
patch_size (int): Size of the patches to be extracted from the input image.
in_channels (int): Number of input channels in the image (e.g., 3 for RGB).
num_classes (int): Number of output classes for classification. If None, the model outputs the class token representation.
embed_dim (int): Dimension of the embedding space to which each patch will be projected.
num_layers (int): Number of Transformer encoder blocks.
num_heads (int): Number of attention heads in the Multi-Head Self-Attention.
mlp_ratio (float): Ratio of the hidden dimension in the MLP block to the embedding dimension.
qkv_bias (bool): Whether to add a bias term to the query, key, and value projections.
dropout (float): Dropout rate applied to the output of the MLP and attention layers.
attention_dropout (float): Dropout rate applied to the attention weights.
"""
super().__init__()
self.patch_embedding = PatchEmbedding(patch_size, in_channels, embed_dim)
num_patches = (img_size // patch_size) ** 2
# Learnable Class Token
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
# Learnable Position Embedding: [cls_token, patch_1, ..., patch_N]
self.positional_encoding = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
self.pos_drop = nn.Dropout(p=dropout)
self.blocks = nn.Sequential(*[
EncoderBlock(
dim=embed_dim,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
dropout=dropout,
attention_dropout=attention_dropout,
)
for _ in range(num_layers)
])
self.norm = nn.LayerNorm(embed_dim)
self.head = nn.Identity() if num_classes is None else nn.Linear(embed_dim, num_classes)
# Initialize parameters
nn.init.trunc_normal_(self.positional_encoding, std=0.02)
nn.init.trunc_normal_(self.cls_token, std=0.02)
nn.init.trunc_normal_(self.head.weight, std=0.02)
nn.init.zeros_(self.head.bias)
def forward(self, x):
"""
Forward pass of the Vision Transformer.
Args:
x (torch.Tensor): Input tensor of shape (B, C, H, W) where
- B is batch size
- C is number of channels
- H is height
- W is width
Returns:
logits (torch.Tensor): Output tensor of shape (B, num_classes) if num_classes is specified,
otherwise the output is the class token representation of shape (B, D).
"""
B = x.shape[0]
x = self.patch_embedding(x) # shape: (B, N, D)
# Prepend a class token
cls_tokens = self.cls_token.expand(B, -1, -1) # (B, 1, D)
x = torch.cat((cls_tokens, x), dim=1) # (B, 1+N, D)
x = x + self.positional_encoding # (B, 1+N, D)
x = self.pos_drop(x) # (B, 1+N, D)
x = self.blocks(x) # (B, 1+N, D)
x = self.norm(x) # (B, 1+N, D)
cls_output = x[:, 0] # (B, D)
logits = self.head(cls_output) # (B, num_classes) or (B, D) if num_classes is None
return logitsPre-training 和 Inference
我們利用剛剛實作的 VisionTransformer 來做一個狗貓圖像分類器。以下是 pre-training 的程式碼。
class DogCatDataset(Dataset):
def __init__(self, data_dir: Path, image_size=224):
self.num_classes = 2 # 0 for dog, 1 for cat
self.image_paths = list(data_dir.glob("*.png"))
self.transform = T.Compose([
T.ToTensor(),
T.Resize((image_size, image_size))
])
def __len__(self):
return len(self.image_paths) * 2
def __getitem__(self, idx):
base_idx = idx // 2
flip = idx % 2 == 1
image_path = self.image_paths[base_idx]
image = Image.open(image_path).convert("RGB")
if flip:
image = ImageOps.mirror(image)
image = self.transform(image)
label = 0 if "dog" in image_path.name.lower() else 1
return image, label
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def pretrain():
model = VisionTransformer(embed_dim=768, num_classes=1000).to(device)
dataset = DogCatDataset(data_dir=Path(__file__).parent.parent / "data" / "train")
dataloader = DataLoader(dataset, batch_size=20, shuffle=True)
EPOCHS = 50
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3, weight_decay=0.01)
criterion = torch.nn.CrossEntropyLoss()
model.train()
for epoch in range(EPOCHS):
for images, labels in dataloader:
images, labels = images.to(device), labels.to(device)
logits = model(images)
loss = criterion(logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch} Loss: {loss.item():.4f}")
return modelPre-training 好了之後,我們就可以用它來分類圖像,如下。
def inference(model):
model.eval()
transform = T.Compose([
T.Resize((224, 224)),
T.ToTensor(),
])
cat_image = Image.open(Path(__file__).parent.parent / "data" / "val" / "cat-val.png").convert("RGB")
cat_image_tensor = transform(cat_image).unsqueeze(0).to(device)
dog_image = Image.open(Path(__file__).parent.parent / "data" / "val" / "dog-val.png").convert("RGB")
dog_image_tensor = transform(dog_image).unsqueeze(0).to(device)
with torch.no_grad():
logits = model(cat_image_tensor)
probs = F.softmax(logits, dim=-1)
pred = probs.argmax(dim=-1).item()
print(f"Predicted class index for cat: {pred} (should be 1)")
logits = model(dog_image_tensor)
probs = F.softmax(logits, dim=-1)
pred = probs.argmax(dim=-1).item()
print(f"Predicted class index for dog: {pred} (should be 0)")
if __name__ == "__main__":
model = pretrain()
inference(model)
torch.save(model.state_dict(), "vit_dog_cat.pth")
print("Model saved as vit_dog_cat.pth")結語
Vision Transformer 為視覺領域帶來一種全新的建模方式,其優雅、模組化的設計挑戰了過去 CNN 為主的思維。雖然在資料與算力不足的場景下仍有局限,但 ViT 的成功證明了 Transformer 架構的普適性,也為後續的多模態學習與自監督視覺模型(如 DINO, BEiT, CLIP 等)奠定了重要基礎。未來的視覺模型,可能不再是卷積的疊加,而是以注意力為核心的結構性學習。
參考
- Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An Image Is Worth 16×16 Words: Transformers For Image Recognition at Scale. In 9th International Conference on Learning Representations, ICLR 2021.
- Source code, GitHub.









