
Transformer 模型於 2017 年由谷歌大腦的一個團隊推出,是一種使用注意力機制(attention)的深度學習架構。它解決了傳統序列模型(sequential model)難以捕捉長距離依賴性和無法高效並行計算的問題。
Table of Contents
Transformer 架構
與 RNN 模型一樣,Transformer 模型處理序列資料。與 RNN 模型不同的是,Transformer 模型能夠一次性地處理所有輸入資料。以翻譯為例,RNN 模型一次只處理一個單詞,而 Transformer 則可以一次處理所有單詞。這種架構允許平行計算,因此可以減少訓練時間。
大部分表現優異的序列模型皆採用編碼器-解碼器(encoder-decoder)的架構,Transformer 也採用此架構。Encoder 將輸入序列  轉換為
轉換為  ,而 decoder 會逐步生成輸出序列
,而 decoder 會逐步生成輸出序列  。在 decoder 的生成序列的每一個步驟中,模型都是自回歸(auto-regressive)的,也就是在生成下一個輸出時,會將之前已生成的輸出作為額外的輸入使用。
。在 decoder 的生成序列的每一個步驟中,模型都是自回歸(auto-regressive)的,也就是在生成下一個輸出時,會將之前已生成的輸出作為額外的輸入使用。
Encoder 由 N 個相同 layer 所堆疊而成,而每一個 layer 包含兩個 sub-layers。第一個 sub-layer 是多頭自注意力機制(multi-head self-attention mechanism)。第二個 sub-layer 是逐位置全連接前饋網路(position-wise fully connected feed-forward network)。每個 sub-layer 的輸出會連接殘差連接(residual connection)和層正規化(layer normalization)。
Decoder 也是由 N 個相同 layer 所堆疊而成,而每一個 layer 包含三個 sub-layers。除了和 encoder 相同的兩個 sub-layers 之外,decoder 還加上了第三個 sub-layer。這個第三個 sub-layer 會對 encoder 的輸出進行 multi-head attention。與 encoder 相同,每一個 sub-layer 的輸出會連接 residual connection 和 layer normalization。此外,以避免某個位置在計算 attention 時使用到後續位置的資訊,decoder 在 multi-head attention 上加上 masking 機制。透過 masking,加上輸出的 embedding 是往後偏移一個位置的設計,可確保位置 i 的預測僅能依賴於已知的(小於 i)輸出位置上的資訊。

自注意力(Self-Attention)
注意力(attention)是由三個值 query、keys、和 values 計算出來的。當它們都來自於同一個序列時,我們稱為自注意力(self-attention)。Attention 有許多種計算方法,而 Transformer 使用
縮放點積注意力(scaled dot-product attention),如下圖。

Scaled dot-product attention 的函式如下:

Self-attention 動態地衡量句子中單詞間彼此的重要性,使 Transformer 同時從句子的所有部分捕捉上下文,建立更豐富的上下文表示,且無需循環連接即可捕捉長距離依賴。
以下是 self-attention 的實作。
class MultiHeadAttention(nn.Module):
def scaled_dot_product_attention(self, Q, K, V, mask=None):
"""
Scaled dot-product attention.
Args
Q: (batch_size, h_heads, Q_len, d_k)
K: (batch_size, h_heads, K_len, d_k)
V: (batch_size, h_heads, V_len, d_v)
mask: (batch_size, 1, Q_len, K_len)
Returns
attention: (batch_size, h_heads, Q_len, d_v)
attention_weights: (batch_size, h_heads, Q_len, K_len)
"""
scores = Q @ K.transpose(-2, -1) / math.sqrt(self.d_k) # (batch_size, h_heads, Q_len, K_len)
if mask is not None:
scores = scores.masked_fill(mask == 0, float("-inf"))
attention_weights = torch.softmax(scores, dim=-1) # (batch_size, h_heads, Q_len, K_len)
attention = attention_weights @ V # (batch_size, h_heads, Q_len, d_v)
return attention, attention_weights多頭注意力(Multi-Head Attention)
多頭注意力(multi-head attention)是將 query、keys、和 values 經過  組不同的 linear projection,分別投影到
組不同的 linear projection,分別投影到  ,再平行地執行 attention function 運算。每個 attention function 產生
,再平行地執行 attention function 運算。每個 attention function 產生  維度的輸出。接著再將所有頭(heads)輸出的結果串接起來,再經過一次 linear projection,得到最終的輸出結果,如下圖。
維度的輸出。接著再將所有頭(heads)輸出的結果串接起來,再經過一次 linear projection,得到最終的輸出結果,如下圖。

Multi-head attention 的函式如下:

Multi-head attention 可以同時捕捉輸入序列中的不同語義層面,使 Transformer 能更精準地捕捉語意和句法細節,大幅提高模型的準確性與表現力。
以下是 multi-head attention 的實作。
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, h_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % h_heads == 0, "d_model must be divisible by h_heads"
self.d_model = d_model
self.h_heads = h_heads
self.d_k = d_model // h_heads
self.d_v = d_model // h_heads
self.W_q = nn.Linear(d_model, h_heads * self.d_k, bias=False) # (d_model, h_heads * d_k)
self.W_k = nn.Linear(d_model, h_heads * self.d_k, bias=False) # (d_model, h_heads * d_k)
self.W_v = nn.Linear(d_model, h_heads * self.d_v, bias=False) # (d_model, h_heads * d_v)
self.W_o = nn.Linear(h_heads * self.d_v, d_model, bias=False) # (h_heads * d_v, d_model)
def forward(self, q, k, v, mask=None):
"""
Multi-head attention forward pass.
Args
q: (batch_size, seq_len, d_model)
k: (batch_size, seq_len, d_model)
v: (batch_size, seq_len, d_model)
mask: (batch_size, 1, seq_len) or (1, seq_len, seq_len)
Returns
x: (batch_size, seq_len, d_model)
"""
batch_size, Q_len, _ = q.size()
batch_size, K_len, _ = k.size()
batch_size, V_len, _ = v.size()
# Linear projections
Q = self.W_q(q) # (batch_size, Q_len, h_heads * d_k)
K = self.W_k(k) # (batch_size, K_len, h_heads * d_k)
V = self.W_v(v) # (batch_size, V_len, h_heads * d_v)
Q = Q.view(batch_size, Q_len, self.h_heads, self.d_k).transpose(1, 2) # (batch_size, h_heads, Q_len, d_k)
K = K.view(batch_size, K_len, self.h_heads, self.d_k).transpose(1, 2) # (batch_size, h_heads, K_len, d_k)
V = V.view(batch_size, V_len, self.h_heads, self.d_v).transpose(1, 2) # (batch_size, h_heads, V_len, d_v)
# Scaled dot-product attention
if mask is not None:
mask = mask.unsqueeze(1)
attention, attention_weights = self.scaled_dot_product_attention(Q, K, V, mask=mask)
# Concatenate heads
attention = attention.transpose(1, 2).contiguous() # (batch_size, Q_len, h_heads, d_v)
attention = attention.view(batch_size, Q_len, self.d_model) # (batch_size, Q_len, d_model)
# Linear projection
output = self.W_o(attention) # (batch_size, Q_len, d_model)
return output位置編碼(Positional Encoding)
Transformer 模型可以一次性地處理所有輸入資料,它沒有使用像 RNN 的 recurrence,也沒有使用 convolution。為了讓模型能有效利用序列中的順序資訊,我們必須在模型中注入一些關於序列中各個標記相對或絕對位置的資訊。Transformer 模型使用正弦(sine)和餘弦(cosine)函式來進行位置編碼。它將這位置編碼加到輸入的詞嵌入(embeddings)上。
Positional encoding 的函式如下:

Positional encoding 為單詞引入位置信息,使 Transformer 能有效考量詞序和上下文,而不需依賴序列式處理。
以下是 positional encoding 的實作。
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model) # (max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # (max_len, 1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # (d_model // 2)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer("pe", pe)
def forward(self, x, start_pos=0):
"""
Add positional encoding to input tensor.
Args
x: (batch_size, seq_len, d_model)
start_pos: int
Returns
x: (batch_size, seq_len, d_model)
"""
seq_len = x.size(1)
x = x + self.pe[start_pos:start_pos + seq_len, :].unsqueeze(0)
return x逐位置前饋網路(Position-wise Feed-Forward Neural Network)
逐位置前饋網路(position-wise feed-forward neural network)是一個全連接前饋神經網路(fully connected feed-forward network)。它會針對每個位置執行以下的 linear transformations。所以每個位置都是使用相同的參數,但是每個 layer 使用不同的參數。
Position-wise feed-forward neural network 的函式如下:

Position-wise feed-forward neural network 將 attention 輸出進行非線性轉換,增強模型捕捉資料中複雜關係的能力,提高模型整體的表現力和預測能力。
以下是 position-wise feed-forward neural network 的實作。
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super(PositionwiseFeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, d_ff, bias=True)
self.linear2 = nn.Linear(d_ff, d_model, bias=True)
def forward(self, x):
"""
Position-wise feed forward pass.
Args
x: (batch_size, seq_len, d_model)
Returns
x: (batch_size, seq_len, d_model)
"""
return self.linear2(torch.relu(self.linear1(x)))殘差連接(Residual Connection)和層正規化(Layer Normalization)
在每一個 sub-layer 的輸出都會跟隨著一組殘差連接(residual connection)和層正規化(Layer Normalization)。
Residual connection 可以緩解梯度消失(gradient vanishing)問題並實現更深的網路結構,透過允許梯度更直接地流過網絡,促進更深層的 Transformer 網路的訓練,顯著提高模型效能和收斂速度。Residual connection 的實作相當簡單,如下。
linear1 = nn.Linear(dim1, dim2) linear2 = nn.Linear(dim2, dim1) output = linear1(x) output = torch.relu(output) output = linear2(output) output = output + x output = torch.relu(output)
Layer normalization 可以穩定並加速訓練過程,確保梯度更穩定,訓練更快速收斂,提升模型穩定性和效率。我們可以直接使用 PyTorch 的 LayerNorm。
norm = nn.LayerNorm(dim) x = norm(x)
詞遷入(Embeddings)
在 Transformer 中,輸入的 embedding layer、輸出的 embedding layer、和 softmax 前的 linear transformation,共用同一組權重矩陣。此外,在 embedding layers 中,它會將該權重矩陣乘上  以進行縮放。
以進行縮放。
以下是該 shared embedding 的實作。
class SharedEmbedding(nn.Module):
def __init__(self, vocab_size, d_model):
super(SharedEmbedding, self).__init__()
self.vocab_size = vocab_size
self.d_model = d_model
self.embedding = nn.Embedding(vocab_size, d_model) # (vocab_size, d_model)
def forward(self, x):
"""
Shared embedding layer.
Args
x: (batch_size, seq_len)
Returns
x: (batch_size, seq_len, d_model)
"""
return self.embedding(x) * math.sqrt(self.d_model)編碼器(Encoder)
下圖是 encoder 的部分,它是由一個 embedding layer、一個 position encoding、和 N 個相同的 layers 所組成。

以下是 N 個相同的 layer 的實作。在執行 multi-head attention 時,它將 query、keys、和 values 設為參數 x。另外,由於參數 x 中可能會有 <PAD>,參數 mask 會標示出哪些是 valid tokens(mask[i]=1),哪些是 <PAD>(mask[i]=0)。Multi-head attention 會利用參數 mask 來遮蔽(設為 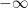 )這些位置的 tokens。
)這些位置的 tokens。
class EncoderLayer(nn.Module):
def __init__(self, d_model, d_heads, d_ff):
super(EncoderLayer, self).__init__()
self.multi_head_attention = MultiHeadAttention(d_model, d_heads)
self.ffn = PositionwiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, x, mask=None):
"""
Encoder layer forward pass.
Args
x: (batch_size, src_len, d_model)
mask: (batch_size, 1, src_len)
Returns
x: (batch_size, src_len, d_model)
"""
# Multi-head attention
attention = self.multi_head_attention(x, x, x, mask=mask)
x = self.norm1(x + attention) # Residual connection and layer normalization
# Position-wise feed forward
ffn_output = self.ffn(x)
x = self.norm2(x + ffn_output) # Residual connection and layer normalization
return x以下是 encoder 的實作。其中 src 是一整個輸入的字串。
class Encoder(nn.Module):
def __init__(self, shared_embedding, d_model, n_layers, h_heads, d_ff, max_len):
super(Encoder, self).__init__()
self.d_model = d_model
self.embedding = shared_embedding
self.positional_encoding = PositionalEncoding(d_model, max_len)
self.layers = nn.ModuleList([EncoderLayer(d_model, h_heads, d_ff) for _ in range(n_layers)])
def forward(self, src, src_mask=None):
"""
Encoder forward pass.
Args
src: (batch_size, src_len)
src_mask: (batch_size, 1, src_len)
Returns
x: (batch_size, src_len, d_model)
"""
x = self.embedding(src)
x = self.positional_encoding(x)
for layer in self.layers:
x = layer(x, mask=src_mask)
return x解碼器(Decoder)
下圖是 decoder 的部分,它是由一個 embedding layer、一個 position encoding、N 個相同的 layers、一個 linear transformation、和一個 softmax。

以下是 N 個相同的 layer 的實作。在執行 multi-head attention 時,它將 query、keys、和 values 設為參數 x。參數 encoder_output 就是 encoder 最後的輸出。與 EncoderLayer 相似,參數 tgt_mask 和 memory_mask 是用來告知 multi-head attention 要遮蔽哪些位置的 tokens。第二個 multi-head attention 稱為 cross multi-head attention,因為它將 keys 和 values 設為 encoder_output。
class DecoderLayer(nn.Module):
def __init__(self, d_model, d_heads, d_ff):
super(DecoderLayer, self).__init__()
self.masked_multi_head_attention = MultiHeadAttention(d_model, d_heads)
self.cross_multi_head_attention = MultiHeadAttention(d_model, d_heads)
self.ffn = PositionwiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
def forward(self, x, encoder_output, tgt_mask=None, memory_mask=None):
"""
Decoder layer forward pass.
Args
x: (batch_size, tgt_len, d_model)
encoder_output: (batch_size, src_len, d_model)
tgt_mask: (1, tgt_len, tgt_len)
memory_mask: (batch_size, 1, src_len)
Returns
x: (batch_size, tgt_len, d_model)
"""
# Mask multi-head attention
masked_attention = self.masked_multi_head_attention(x, x, x, mask=tgt_mask)
x = self.norm1(x + masked_attention)
# Cross multi-head attention
cross_attention = self.cross_multi_head_attention(x, encoder_output, encoder_output, mask=memory_mask)
x = self.norm2(x + cross_attention)
# Position-wise feed forward
ffn_output = self.ffn(x)
x = self.norm3(x + ffn_output)
return x以下是 decoder 的實作。Decoder 每次被呼叫後,會預測一個 token,因此它一直得呼叫,直到它輸出 <EOS>。參數 tgt 是已預測的所有 tokens。參數 tgt_mask 是告知 multi-head attention,參數 tgt 中的哪些位置是已預測的 tokens。先前談到在呼叫 encoder 時,它的參數 x 中會有一些 <PAD>,因此它使用參數 mask 來遮蔽那些 <PAD>。
參數 encoder_output 是 encoder 的輸出,也稱為 memory。參數 memory_mask 是用來告知 cross multi-head attention 要如何使用這個 memory。Encoder 的輸入字串中可能會有 <PAD>,因此 memory_mask 是用來告知 cross multi-head attention 要遮蔽 memory 中哪些位置的 tokens。
class Decoder(nn.Module):
def __init__(self, shared_embedding, d_model, n_layers, h_heads, d_ff, vocab_size, max_len):
super(Decoder, self).__init__()
self.d_model = d_model
self.embedding = shared_embedding
self.positional_encoding = PositionalEncoding(d_model, max_len)
self.layers = nn.ModuleList([DecoderLayer(d_model, h_heads, d_ff) for _ in range(n_layers)])
self.output_linear = nn.Linear(d_model, vocab_size, bias=False)
self.output_linear.weight = self.embedding.embedding.weight
def forward(self, tgt, encoder_output, tgt_mask=None, memory_mask=None):
"""
Decoder forward pass.
Args
tgt: (batch_size, tgt_len)
encoder_output: (batch_size, src_len, d_model)
tgt_mask: (1, tgt_len, tgt_len)
memory_mask: (batch_size, 1, src_len)
Returns
logits: (batch_size, tgt_len, vocab_size)
"""
x = self.embedding(tgt)
x = self.positional_encoding(x)
for layer in self.layers:
x = layer(x, encoder_output, tgt_mask=tgt_mask, memory_mask=memory_mask)
logits = self.output_linear(x)
return logits範例
我們已經實作了 encoder 和 decoder,將它們組合起來就是 Transformer 模型,如下。
class Transformer(nn.Module):
def __init__(self, vocab_size, d_model, n_layers, h_heads, d_ff, max_len):
super(Transformer, self).__init__()
shared_embedding = SharedEmbedding(vocab_size, d_model)
self.encoder = Encoder(shared_embedding, d_model, n_layers, h_heads, d_ff, max_len)
self.decoder = Decoder(shared_embedding, d_model, n_layers, h_heads, d_ff, vocab_size, max_len)
def forward(self, src, tgt, src_mask=None, tgt_mask=None, memory_mask=None):
"""
Transformer forward pass.
Args
src: (batch_size, src_len)
tgt: (batch_size, tgt_len)
src_mask: (batch_size, 1, src_len)
tgt_mask: (1, tgt_len, tgt_len)
memory_mask: (batch_size, 1, src_len)
"""
encoder_output = self.encoder(src, src_mask)
logits = self.decoder(tgt, encoder_output, tgt_mask, memory_mask)
return logits接下來,我們將示範如何用訓練 Transformer 模型。首先,我們將準備好訓練資料。設定 embedding 的維度、encoder 和 decoder 中相同的 layer 的層數、multi-head attention 的 head 數量、position-wise feed-forward networks 中可學習參數的維度、以及輸入與輸出的字串長度。
data = [
("hello world", "hola mundo"),
("i love you", "te amo"),
("the cat is black", "el gato es negro"),
("good morning", "buenos dias"),
("this is a book", "este es un libro"),
("what is your name", "como te llamas"),
]
PAD_INDEX = 0
SOS_INDEX = 1
EOS_INDEX = 2
def build_single_vocab(pairs):
words = set()
for (src, tgt) in pairs:
for w in src.lower().split():
words.add(w)
for w in tgt.lower().split():
words.add(w)
vocab = ["<pad>", "<sos>", "<eos>"] + sorted(list(words))
tkn2idx = {tkn: idx for idx, tkn in enumerate(vocab)}
idx2tkn = {idx: tkn for tkn, idx in tkn2idx.items()}
return vocab, tkn2idx, idx2tkn
vocab, tkn2idx, idx2tkn = build_single_vocab(data)
vocab_size = len(vocab)
D_MODEL = 512
N_LAYERS = 6
H_HEADS = 8
D_FF = 2048
MAX_LEN = 20
EPOCHS = 100以下程式碼中,我們用以上的 dataset 來訓練模型。
def sentence_to_idx(sentence, tkn2idx):
return [tkn2idx[w] for w in sentence.lower().split()]
def encode_pair(src, tgt, tkn2idx, max_len):
src_idx = sentence_to_idx(src, tkn2idx)
tgt_idx = sentence_to_idx(tgt, tkn2idx)
tgt_in_idx = [SOS_INDEX] + tgt_idx
tgt_out_idx = tgt_idx + [EOS_INDEX]
src_idx = src_idx[:max_len]
tgt_in_idx = tgt_in_idx[:max_len]
tgt_out_idx = tgt_out_idx[:max_len]
src_idx += [PAD_INDEX] * (max_len - len(src_idx))
tgt_in_idx += [PAD_INDEX] * (max_len - len(tgt_in_idx))
tgt_out_idx += [PAD_INDEX] * (max_len - len(tgt_out_idx))
return src_idx, tgt_in_idx, tgt_out_idx
def create_dataset(pairs, tkn2idx, max_len):
src_data, tgt_in_data, tgt_out_data = [], [], []
for (src, tgt) in pairs:
src_idx, tgt_in_idx, tgt_out_idx = encode_pair(src, tgt, tkn2idx, max_len)
src_data.append(src_idx)
tgt_in_data.append(tgt_in_idx)
tgt_out_data.append(tgt_out_idx)
return (
torch.tensor(src_data, dtype=torch.long),
torch.tensor(tgt_in_data, dtype=torch.long),
torch.tensor(tgt_out_data, dtype=torch.long),
)
def create_padding_mask(seq):
"""
Args
seq: (batch_size, seq_len)
Returns
mask: (batch_size, 1, seq_len) - 1 for valid token, 0 for padding token
"""
return (seq != PAD_INDEX).unsqueeze(1).long()
def create_subsequence_mask(size):
"""
Args
size: int
Returns
mask: (1, size, size) - 1 for valid token, 0 for padding token
"""
return torch.tril(torch.ones((size, size))).unsqueeze(0)
def train():
model = Transformer(vocab_size, D_MODEL, N_LAYERS, H_HEADS, D_FF, MAX_LEN)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
criterion = nn.CrossEntropyLoss(ignore_index=PAD_INDEX)
src_data, tgt_in_data, tgt_out_data = create_dataset(data, tkn2idx, MAX_LEN)
model.train()
for epoch in range(EPOCHS):
src_mask = create_padding_mask(src_data) # (batch_size, 1, MAX_LEN)
tgt_mask = create_subsequence_mask(tgt_in_data.size(1)) # (1, MAX_LEN, MAX_LEN)
memory_mask = create_padding_mask(src_data) # (batch_size, 1, MAX_LEN)
# (batch_size, MAX_LEN, vocab_size)
logits = model(src_data, tgt_in_data, src_mask=src_mask, tgt_mask=tgt_mask, memory_mask=memory_mask)
logits = logits.reshape(-1, vocab_size) # (batch_size * MAX_LEN, vocab_size)
tgt_out = tgt_out_data.reshape(-1) # (batch_size * MAX_LEN)
loss = criterion(logits, tgt_out)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 10 == 0:
print(f"Epoch [{epoch + 1}/{EPOCHS}], Loss: {loss.item():.4f}")
return model訓練好模型後,我們可以用以下程式碼來將英文翻譯成西班牙文。
def translate_beam_search(model, sentence, beam_width=3):
model.eval()
src_idx, _, _ = encode_pair(sentence, "", tkn2idx, MAX_LEN)
src_tensor = torch.tensor([src_idx], dtype=torch.long)
src_mask = create_padding_mask(src_tensor)
with torch.no_grad():
encoder_output = model.encoder(src_tensor, src_mask) # (batch_size, src_len, d_model)
memory_mask = create_padding_mask(src_tensor)
beam = [([SOS_INDEX], 0.0)]
completed_sentences = []
for i in range(MAX_LEN):
new_beam = []
for tokens, score in beam:
if tokens[-1] == EOS_INDEX:
completed_sentences.append((tokens, score))
new_beam.append((tokens, score))
continue
ys = torch.tensor([tokens], dtype=torch.long)
tgt_mask = create_subsequence_mask(ys.size(1))
with torch.no_grad():
# (batch_size, tgt_len, vocab_size)
logits = model.decoder(ys, encoder_output, tgt_mask=tgt_mask, memory_mask=memory_mask)
next_token_logits = logits[:, -1, :] # (batch_size, vocab_size)
log_probs = torch.log_softmax(next_token_logits, dim=1).squeeze(0)
topk = torch.topk(log_probs, beam_width)
for tkn_idx, tkn_score in zip(topk.indices.tolist(), topk.values.tolist()):
new_tokens = tokens + [tkn_idx]
new_score = score + tkn_score
new_beam.append((new_tokens, new_score))
new_beam.sort(key=lambda x: x[1], reverse=True)
beam = new_beam[:beam_width]
for tokens, score in beam:
if tokens[-1] != EOS_INDEX:
completed_sentences.append((tokens, score))
completed_sentences.sort(key=lambda x: x[1], reverse=True)
best_tokens, best_score = completed_sentences[0]
if best_tokens[0] == SOS_INDEX:
best_tokens = best_tokens[1:]
if EOS_INDEX in best_tokens:
best_tokens = best_tokens[:best_tokens.index(EOS_INDEX)]
return " ".join([idx2tkn[idx] for idx in best_tokens])if __name__ == "__main__":
test_sentences = [
"hello world",
"the cat is black",
"good morning",
"what is your name",
"this is a book",
"i love you",
"i love cat",
"this is a cat",
]
model = train()
for sentence in test_sentences:
translation = translate_beam_search(model, sentence)
print(f"Input: {sentence}, Translation: {translation}")結語
Transformer 廣泛用於 NLP,如 GPT 模型和 BERT。它代表了神經網路架構的強大演進,深刻影響了深度學習的效率、擴展性及能力。
參考
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan Gomez,
Łukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. Advances in Neural Information Processing Systems 30.









