
循環神經網路(Recurrent Neural Networks, RNN)是一個專門處理序列資料(sequential data)的神經網路架構。RNN 利用循環連結(recurrent connections)來保留先前的輸出資訊,使網路在處理當前步驟時,能同時考慮過去的狀態。本文章將介紹 RNN 的基本原理。
Table of Contents
RNN 架構
循環神經網路(Recurrent Neural Networks, RNN)在每個 time step 都有一個 hidden state,並將它作為下一個 time step 的輸入。這使得 RNN 能夠 capture 先前 time steps 的一些資訊。所以,相對於傳統的 neural network,它更適合於處理序列型或依賴上下文的問題。
下圖是基礎 RNN(vanilla RNN)的架構。左邊是未展開時的表示法,而右邊是展開時的表示法。所以,右邊中每一個 time step 裡的 neural network 架構都是一樣的。
在本文章中,我們將用一個 character-level 的 RNN 模型來講解 RNN 的原理。每一個 time step 的輸入  是輸入文本中的一個字元。將 傳入 RNN cell,該 RNN cell 會產出一個 hidden state
是輸入文本中的一個字元。將 傳入 RNN cell,該 RNN cell 會產出一個 hidden state  。一方面將 輸出為
。一方面將 輸出為  ,另一方面將它傳給下一個 time step 的 RNN cell。
,另一方面將它傳給下一個 time step 的 RNN cell。
每一個 time step 裡的 都會影響到下一個 time step 的  。也就是說, 有 capture 上一個 time step 的一些資訊。因此,每個 time step 之間有依賴的關係。
。也就是說, 有 capture 上一個 time step 的一些資訊。因此,每個 time step 之間有依賴的關係。

RNN 類型
RNN 的輸入個數 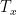 和輸出個數
和輸出個數  不總是相同的,所以有以下五種不同類型的 RNN。每一種類型的 RNN 適合於不同的應用,如下。本文章中的 vanilla RNN 是左下方的 many-to-many 類型。
不總是相同的,所以有以下五種不同類型的 RNN。每一種類型的 RNN 適合於不同的應用,如下。本文章中的 vanilla RNN 是左下方的 many-to-many 類型。

前向傳播(Forward Propagation)
如果你還不熟悉 neural networks 的 forward propagation,請先參考以下文章。

下圖顯示我們的 RNN cell。輸入為 以及上一個 time step 的 hidden state  。它將這兩個輸入與參數
。它將這兩個輸入與參數  做運算,將其結果帶入 activation function tanh,最後輸出 作為下一個 time step 裡的 RNN cell 的輸入。另外,再將 與參數
做運算,將其結果帶入 activation function tanh,最後輸出 作為下一個 time step 裡的 RNN cell 的輸入。另外,再將 與參數  做運算,將其結果帶入 activation function softmax,最後輸出
做運算,將其結果帶入 activation function softmax,最後輸出  作為當前 time step 的輸出。
作為當前 time step 的輸出。
值得注意的是,參數  是 shared parameters。也就是說,每一個 time step 裡的 RNN cell 都使用同一組參數。
是 shared parameters。也就是說,每一個 time step 裡的 RNN cell 都使用同一組參數。

RNN cell 中的公式如下:

RNN 的輸入  和 true labels
和 true labels  的維度如下:
的維度如下:

在 RNN cell 中,各個變數的維度如下:
 | |  | |  |  |  | |
|---|---|---|---|---|---|---|---|
 |  |  |  |  |  |  |  |
以下是 vanilla RNN 的 forward propagation 的實作。
class VanillaRNN:
def cell_forward(self, xt, at_prev, parameters):
"""
Implements a single forward step of the RNN-cell.
Parameters
----------
xt: (ndarray (n_x, m)) - input data at timestep "t"
at_prev: (ndarray (n_a, m)) - hidden state at timestep "t-1"
parameters:
Waa: (ndarray (n_a, n_a)) - weight matrix multiplying the hidden state at_prev
Wax: (ndarray (n_a, n_x)) - weight matrix multiplying the input xt
Wya: (ndarray (n_y, n_a)) - weight matrix relating the hidden-state to the output
ba: (ndarray (n_a, 1)) - bias
by: (ndarray (n_y, 1)) - bias
Returns
-------
at: (ndarray (n_a, m)) - hidden state at timestep "t"
yt: (ndarray (n_y, m)) - prediction at timestep "t"
cache: (tuple) - returning (at, at_prev, xt, zxt, y_hat_t, zyt) for the backpropagation
"""
Wax, Waa, ba = parameters["Wax"], parameters["Waa"], parameters["ba"]
Wyx, by = parameters["Wya"], parameters["by"]
zxt = Waa @ at_prev + Wax @ xt + ba
at = np.tanh(zxt)
zyt = Wyx @ at + by
y_hat_t = softmax(zyt)
cache = (at, at_prev, xt, zxt, y_hat_t, zyt)
return at, y_hat_t, cache
def forward(self, X, a0, parameters):
"""
Implements the forward propagation of the RNN.
Parameters
----------
X: (ndarray (n_x, m, T_x)) - input data for each timestep
a0: (ndarray (n_a, m)) - initial hidden state
parameters:
Waa: (ndarray (n_a, n_a)) - weight matrix multiplying the hidden state at_prev
Wax: (ndarray (n_a, n_x)) - weight matrix multiplying the input xt
Wyx: (ndarray (n_y, n_a)) - weight matrix relating the hidden-state to the output
ba: (ndarray (n_a, 1)) - bias
by: (ndarray (n_y, 1)) - bias
Returns
-------
a: (ndarray (n_a, m, T_x)) - hidden states for each timestep
Y_hat: (ndarray (n_y, m, T_x)) - predictions for each timestep
caches: (tuple) - returning (list of cache, x) for the backpropagation
"""
caches = []
n_x, m, T_x = X.shape
n_y, n_a = parameters["Wya"].shape
A = np.zeros((n_a, m, T_x))
Y_hat = np.zeros((n_y, m, T_x))
at_prev = a0
for t in range(T_x):
at_prev, y_hat_t, cache = self.cell_forward(X[:, :, t], at_prev, parameters)
A[:, :, t] = at_prev
Y_hat[:, :, t] = y_hat_t
caches.append(cache)
return A, Y_hat, caches損失函數(Loss Function)
由於我們的 vanilla RNN 是 many-to-many,也就是有多個 outputs,因此在計算 loss 時,必須要將每個 time step 的 loss 加總起來,如下圖。

我們的 vanilla RNN 使用 softmax 來輸出  ,因此使用 cross-entropy loss 作為它的 loss function。
,因此使用 cross-entropy loss 作為它的 loss function。

以下是 loss function 的實作。
class VanillaRNN:
def compute_loss(self, Y_hat, Y):
"""
Computes the cross-entropy loss.
Parameters
----------
Y_hat: (ndarray (n_y, m, T_x)) - predictions for each timestep
Y: (ndarray (n_y, m, T_x)) - true labels
Returns
-------
loss: (float) - the cross-entropy loss
"""
return -np.sum(Y * np.log(Y_hat))反向傳播(Backward Propagation)
相較於傳統的 neural networks,RNN 的 backpropagation 比較複雜一些。從下圖中顯示,對每個 time step,我們必須要求取這些的偏導數。

此外,每一個 time step 都受到前一個 time step 的 hidden state 的影響。所以,在求取 gradients 時,必須加總在每個 time step 中求取到的偏導數,這就是 backprogation through time(BPTT)。如果我們只在最後一個 time step 求取 gradient 的話,就會忽略中間各個 time step 對最終結果的影響,權重就無法學習到整個時間序列中的正確調整。

以下是在一個 time step,求取 output layer 裡的偏導數。

以下是在一個 time step,求取剩餘的偏導數。

值得注意的是,在計算 hidden state 的偏導數時,我們要先計算在 output layer 中對 的偏導數。然後,再加上上一個 time step 算出的 的偏導數,如下圖。

以上是在每個 time step 中求取所有偏導數的方式。最後還要將所有求取的偏導數加總起來。

以下是 vanilla RNN 的 backward propagation 的實作。
class VanillaRNN:
def cell_backward(self, y, dat, cache, parameters):
"""
Implements a single backward step of the RNN-cell.
Parameters
----------
y: (ndarray (n_y, m)) - true labels at timestep "t"
dat: (ndarray (n_a, m)) - gradient of the hidden state at timestep "t"
cache: (tuple) - (at, at_prev, xt, zxt, y_hat_t, zyt)
parameters:
Waa: (ndarray (n_a, n_a)) - weight matrix multiplying the hidden state at_prev
Wax: (ndarray (n_a, n_x)) - weight matrix multiplying the input xt
Wya: (ndarray (n_y, n_a)) - weight matrix relating the hidden-state to the output
ba: (ndarray (n_a, 1)) - bias
by: (ndarray (n_y, 1)) - bias
Returns
-------
gradients: (dict) - the gradients
dWaa: (ndarray (n_a, n_a)) - gradient of the weight matrix multiplying the hidden state at_prev
dWax: (ndarray (n_a, n_x)) - gradient of the weight matrix multiplying the input xt
dWya: (ndarray (n_y, n_a)) - gradient of the weight matrix relating the hidden-state to the output
dba: (ndarray (n_a, 1)) - gradient of the bias
dby: (ndarray (n_y, 1)) - gradient of the bias
dat: (ndarray (n_a, m)) - gradient of the hidden state
"""
at, at_prev, xt, zt, y_hat_t, zyt = cache
dy = y_hat_t - y
gradients = {
"dWya": dy @ at.T,
"dby": np.sum(dy, axis=1, keepdims=True),
}
dat = parameters["Wya"].T @ dy + dat
dz = (1 - at ** 2) * dat
gradients["dba"] = np.sum(dz, axis=1, keepdims=True)
gradients["dWax"] = dz @ xt.T
gradients["dWaa"] = dz @ at_prev.T
gradients["dat"] = parameters["Waa"].T @ dz
return gradients
def backward(self, X, Y, parameters, caches):
"""
Implements the backward propagation of the RNN.
Parameters
----------
X: (ndarray (n_x, m, T_x)) - input data
Y: (ndarray (n_y, m, T_x)) - true labels
parameters:
Waa: (ndarray (n_a, n_a)) - weight matrix multiplying the hidden state at_prev
Wax: (ndarray (n_a, n_x)) - weight matrix multiplying the input xt
Wya: (ndarray (n_y, n_a)) - weight matrix relating the hidden-state to the output
ba: (ndarray (n_a, 1)) - bias
by: (ndarray (n_y, 1)) - bias
caches: (list) - list of caches from rnn_forward
Returns
-------
gradients: (dict) - the gradients
dWaa: (ndarray (n_a, n_a)) - gradient of the weight matrix multiplying the hidden state at_prev
dWax: (ndarray (n_a, n_x)) - gradient of the weight matrix multiplying the input xt
dWya: (ndarray (n_y, n_a)) - gradient of the weight matrix relating the hidden-state to the output
dba: (ndarray (n_a, 1)) - gradient of the bias
dby: (ndarray (n_y, 1)) - gradient of the bias
dat: (ndarray (n_a, m)) - gradient of the hidden state
"""
n_x, m, T_x = X.shape
a1, a0, x1, zx1, y_hat1, zy1 = caches[0]
Waa, Wax, ba = parameters['Waa'], parameters['Wax'], parameters['ba']
Wya, by = parameters['Wya'], parameters['by']
gradients = {
"dWaa": np.zeros_like(Waa), "dWax": np.zeros_like(Wax), "dba": np.zeros_like(ba),
"dWya": np.zeros_like(Wya), "dby": np.zeros_like(by),
}
dat = np.zeros_like(a0)
for t in reversed(range(T_x)):
grads = self.cell_backward(Y[:, :, t], dat, caches[t], parameters)
gradients["dWaa"] += grads["dWaa"]
gradients["dWax"] += grads["dWax"]
gradients["dWya"] += grads["dWya"]
gradients["dba"] += grads["dba"]
gradients["dby"] += grads["dby"]
dat = grads["dat"]
return gradients梯度爆炸(Exploding Gradients)
在深層的 RNN 中,gradients 是在 backpropagation 時不斷相乘或相加得來的。因此,如果權重很大,那在計算偏導數時,即使略大於 1 的放大倍數,當層數一多,最終結果就可能爆增。這會使 loss 跑到很大的值或是 NaN。
因此,在更新參數之前,我們會做梯度裁剪(gradient clipping),其實作如下。
class VanillaRNN:
def clip(self, gradients, max_value):
"""
Clips the gradients to a maximum value.
Parameters
----------
gradients: (dict) - the gradients
dWaa: (ndarray (n_a, n_a)) - gradient of the weight matrix multiplying the hidden state at_prev
dWax: (ndarray (n_a, n_x)) - gradient of the weight matrix multiplying the input xt
dWya: (ndarray (n_y, n_a)) - gradient of the weight matrix relating the hidden-state to the output
dba: (ndarray (n_a, 1)) - gradient of the bias
dby: (ndarray (n_y, 1)) - gradient of the bias
max_value: (float) - the maximum value to clip the gradients
Returns
-------
gradients: (dict) - the clipped gradients
"""
dWaa, dWax, dWya = gradients["dWaa"], gradients["dWax"], gradients["dWya"]
dba, dby = gradients["dba"], gradients["dby"]
for gradient in [dWax, dWaa, dWya, dba, dby]:
np.clip(gradient, -max_value, max_value, out=gradient)
gradients = {"dWaa": dWaa, "dWax": dWax, "dWya": dWya, "dba": dba, "dby": dby}
return gradients參數初始化與更新
參數的初始化並不困難,但是要確保每個參數的維度是正確的。以下是參數初始化的實作。
class VanillaRNN:
def initialize_parameters(self, n_a, n_x, n_y):
"""
Initializes the parameters for the RNN.
Parameters
----------
n_a: (int) - number of units in the hidden state
n_x: (int) - number of units in the input data
n_y: (int) - number of units in the output data
Returns
-------
parameters: (dict) - initialized parameters
"Wax": (ndarray (n_a, n_x)) - weight matrix multiplying the input
"Waa": (ndarray (n_a, n_a)) - weight matrix multiplying the hidden state
"Wya": (ndarray (n_y, n_a)) - weight matrix relating the hidden-state to the output
"ba": (ndarray (n_a, 1)) - bias
"by": (ndarray (n_y, 1)) - bias
"""
Wax = np.random.randn(n_a, n_x) * 0.01
Waa = np.random.randn(n_a, n_a) * 0.01
Wya = np.random.randn(n_y, n_a) * 0.01
ba = np.zeros((n_a, 1))
by = np.zeros((n_y, 1))
parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "ba": ba, "by": by}
return parameters在求得 gradients 後,我們要用 gradients 來更新參數,其實作如下。
class VanillaRNN:
def update_parameters(self, parameters, gradients, learning_rate):
"""
Updates the parameters using the gradients.
Parameters
----------
parameters: (dict) - the parameters
Waa: (ndarray (n_a, n_a)) - weight matrix multiplying the hidden state at_prev
Wax: (ndarray (n_a, n_x)) - weight matrix multiplying the input xt
Wya: (ndarray (n_y, n_a)) - weight matrix relating the hidden-state to the output
ba: (ndarray (n_a, 1)) - bias
by: (ndarray (n_y, 1)) - bias
gradients: (dict) - the gradients
dWaa: (ndarray (n_a, n_a)) - gradient of the weight matrix multiplying the hidden state at_prev
dWax: (ndarray (n_a, n_x)) - gradient of the weight matrix multiplying the input xt
dWya: (ndarray (n_y, n_a)) - gradient of the weight matrix relating the hidden-state to the output
dba: (ndarray (n_a, 1)) - gradient of the bias
dby: (ndarray (n_y, 1)) - gradient of the bias
learning_rate: (float) - the learning rate
"""
parameters["Waa"] -= learning_rate * gradients["dWaa"]
parameters["Wax"] -= learning_rate * gradients["dWax"]
parameters["Wya"] -= learning_rate * gradients["dWya"]
parameters["ba"] -= learning_rate * gradients["dba"]
parameters["by"] -= learning_rate * gradients["dby"]整合全部
以下的程式碼實作了一次完整的訓練流程。首先,我們將訓練資料傳入 forward propagation,計算 loss,然後再傳入 backward propagation,最終得到 gradients。為了防止 exploding gradients 的發生,我們將對 gradients 做 clipping。然後,再用它來更新參數。這就是一次完整的訓練。
class VanillaRNN:
def optimize(self, X, Y, a_prev, parameters, learning_rate, clip_value):
"""
Implements the forward and backward propagation of the RNN.
Parameters
----------
X: (ndarray (n_x, m, T_x)) - the input data
Y: (ndarray (n_y, m, T_x)) - true labels
a_prev: (ndarray (n_a, m)) - the initial hidden state
parameters: (dict) - the initial parameters
Waa: (ndarray (n_a, n_a)) - weight matrix multiplying the hidden state A_prev
Wax: (ndarray (n_a, n_x)) - weight matrix multiplying the input Xt
Wya: (ndarray (n_y, n_a)) - weight matrix relating the hidden-state to the output
ba: (ndarray (n_a, 1)) - bias
by: (ndarray (n_y, 1)) - bias
learning_rate: (float) - the learning rate
Returns
-------
a: (ndarray (n_a, m)) - the hidden state at the last timestep
loss: (float) - the cross-entropy loss
"""
A, Y_hat, caches = self.forward(X, a_prev, parameters)
loss = self.compute_loss(Y_hat, Y)
gradients = self.backward(X, Y, parameters, caches)
gradients = self.clip(gradients, clip_value)
self.update_parameters(parameters, gradients, learning_rate)
at = A[:, :, -1]
return at, loss範例
至目前為止,我們已經在 VanillaRNN 裡面實作了optimize(),它會執行一次完整的訓練。接下來,我們將 VanillaRNN 設計為一個 character-level language model。訓練資料是一段莎士比亞的文章。它會一次訓練一個字元,所以 sequence length 就會是輸入字元的長度。所以,第一個字元就是 。然後,使用 one-hot encoding 來編碼每一個字元。
class VanillaRNN:
def preprocess_inputs(self, inputs, char_to_idx):
"""
Preprocess the input text data.
Parameters
----------
inputs: (str) - input text data
char_to_idx: (dict) - dictionary mapping characters to indices
Returns
-------
X: (ndarray (n_x, 1, T_x)) - input data for each time step
Y: (ndarray (n_y, 1, T_x)) - true labels for each time step
"""
n_x = n_y = len(char_to_idx)
T_x = T_y = len(inputs) - 1
X = np.zeros((n_x, 1, T_x))
Y = np.zeros((n_y, 1, T_y))
for t in range(T_x):
X[char_to_idx[inputs[t]], 0, t] = 1
Y[char_to_idx[inputs[t + 1]], 0, t] = 1
return X, Y
def train(self, inputs, char_to_idx, num_iterations=100, learning_rate=0.01, clip_value=5):
"""
Train the RNN model on the given text.
Parameters
----------
inputs: (str) - input text data
char_to_idx: (dict) - dictionary mapping characters to indices
num_iterations: (int) - number of iterations for the optimization loop
learning_rate: (float) - learning rate for the optimization algorithm
clip_value: (float) - maximum value for the gradients
Returns
-------
losses: (list) - cross-entropy loss at each iteration
"""
losses = []
a_prev = self.a0
X, Y = self.preprocess_inputs(inputs, char_to_idx)
for i in range(num_iterations):
a_prev, loss = self.optimize(X, Y, a_prev, self.parameters, learning_rate, clip_value)
losses.append(loss)
print(f"Iteration {i}, Loss: {loss}")
return losses訓練完成後,給定一個開始字元,VanillaRNN 就會生成類似莎士比亞的字串。
class VanillaRNN:
def sample(self, start_char, char_to_idx, idx_to_char, num_chars=100):
"""
Generate text using the RNN model.
Parameters
----------
start_char: (str) - starting character for the text generation
char_to_idx: (dict) - dictionary mapping characters to indices
idx_to_char: (dict) - dictionary mapping indices to characters
num_chars: (int) - number of characters to generate
Returns
-------
text: (str) - generated text
"""
x = np.zeros((len(char_to_idx), 1))
a_prev = np.zeros_like(self.a0)
idx = char_to_idx[start_char]
x[idx] = 1
indices = [idx]
while len(indices) < num_chars:
a_prev, y_hat, cache = self.cell_forward(x, a_prev, self.parameters)
idx = np.random.choice(range(len(char_to_idx)), p=y_hat.ravel())
indices.append(idx)
x = np.zeros_like(x)
x[idx] = 1
text = "".join([idx_to_char[idx] for idx in indices])
return text
以下是 VanillaRNN 的使用範例。
if __name__ == "__main__":
with open("shakespeare.txt", "r") as file:
text = file.read()
chars = sorted(list(set(text)))
vocab_size = len(chars)
char_to_idx = {ch: i for i, ch in enumerate(chars)}
idx_to_char = {i: ch for i, ch in enumerate(chars)}
rnn = VanillaRNN(64, vocab_size, vocab_size)
losses = rnn.train(text, char_to_idx, num_iterations=100, learning_rate=0.01, clip_value=5)
generated_text = rnn.sample("T", char_to_idx, idx_to_char, num_chars=100)
print(generated_text)梯度消失(Vanishing Gradients)
越深的網路會增加 backpropagation 的路徑,而每個 time step 都會有對應的偏導數。一路乘下來,大於 1 的會容易導致 exploding gradients;小於 1 的就容易造成 vanishing gradients。如果在序列早期的輸入對最終輸出有重要影響,但 gradients 在傳回來時早就變得非常微弱,那麼模型就無法學到這些早期資訊的關鍵。
假設有一篇文章,文章的第一句就已經說明了核心主題,例如:
「這篇文章要討論的是社群媒體對年輕人的心理影響,我們會先從使用時間和心理健康的關聯談起……」
接著,文章後面還有許多描述性的細節,可能包括案例分析、數據報告等,整篇文章可能有上千個詞。對於要做「主題歸類」或「情感分析」的模型來說,文章的開頭很可能就點出了文章的主旨或作者的態度。在理想情況下,模型應該牢記這個核心資訊,因為之後的所有內容都與這個主題有關。
當 RNN 在處理這篇文章時,會逐詞或逐句將資訊餵入模型,並更新 hidden state。在 backpropagation 回到文章前半時,gradients 已經被不斷縮小,幾乎趨近 0。模型等同不會去記文章一開頭提到的主題資訊。最後,當模型要輸出整篇文章的「主題分類」或「情感分析」結果時,對早期的關鍵提示沒有足夠的辨識能力,可能做出錯誤或與主題不符的判斷。
Long short-term memory(LSTM)或 Gated Recurrent Unit(GRU)等 RNN 模型,可以較好地保留序列前面的關鍵資訊。
結語
通過本篇文章的介紹,相信你已經對 RNN 的運作模式有了更全面的理解。我們看到了 RNN 在處理序列資料時的強大能力,也了解到它在長時間序列下可能面臨的挑戰,如 vanishing gradients。為了因應這個問題,可以採用 LSTM 與 GRU 等模型來有效地保留長期資訊。
參考
- Andrew Ng, Deep Learning Specialization, Coursera.









