
在 RL 的 control 問題中,多數方法皆以 value function 作為學習核心,透過估計長期 return 來間接改善 policy。然而,當 state 或 action 空間變得連續、或 policy 本身必須保持隨機性時,這種方式便顯得不再直接。策略梯度(Policy Gradient)方法改採另一種觀點,將 policy 本身視為可最佳化的對象,直接對 expected return 進行梯度上升(gradient ascent)。
Table of Contents
策略梯度(Policy Gradient)
無論是動態規劃(Dynamic Programming, DP)、蒙地卡羅(Monte Carlo, MC),或時序差分(Temporal Difference, TD),在 control 問題中,我們所學習的對象始終是 state-value function  或 action-value function
或 action-value function  ,並透過這些 value function 來推導與改善 policy。
,並透過這些 value function 來推導與改善 policy。
策略梯度(Policy Gradient)方法則採取一種不同的觀點。當 policy 本身被表示為一個可微分的機率分佈  時,control 問題可以直接被視為一個策略參數最佳化問題。此時,與其先估計 value function,再透過 greedy 或近似 greedy 的方式間接地改善 policy,不如直接對 policy 的期望回報(expected return)進行梯度上升(gradient ascent)。
時,control 問題可以直接被視為一個策略參數最佳化問題。此時,與其先估計 value function,再透過 greedy 或近似 greedy 的方式間接地改善 policy,不如直接對 policy 的期望回報(expected return)進行梯度上升(gradient ascent)。
透過參數化策略(parameterized policy),agent 得以將 policy 本身作為主要的學習對象,而不再必須依賴 value function 作為 policy improvement 的中介。這種做法使學習目標與最終行為之間的關係更加直接,也為處理連續動作空間與隨機策略提供了自然的建模方式。
Policy gradient 方法並非否定 value-based 方法的價值,而是提供了一條不同的學習路徑。Value-based 方法透過估計長期回報(long-term return)來間接決定行為,而 policy gradient 則嘗試直接調整行為分佈本身,使高 return 的動作在 policy 中出現得更頻繁。這樣的差異,將在後續章節中體現在目標函數的定義方式、梯度估計的來源,以及學習穩定性與變異性之間的取捨。
參數化策略(Parameterized Policy)
我們以  表示 policy 的參數向量。當 agent 在 time step
表示 policy 的參數向量。當 agent 在 time step  處於 state
處於 state  ,且目前的策略參數為
,且目前的策略參數為  時,
時, 表示在該狀態下採取 action
表示在該狀態下採取 action  的機率。形式化地,可寫為:
的機率。形式化地,可寫為:

在引入 parameterized policy 之後,control 問題可被轉化為一個純粹的參數最佳化問題。我們不再直接尋找最優 policy,而是定義一個以策略參數為自變數的純量性能指標  ,並透過調整 來最大化該指標。
,並透過調整 來最大化該指標。
在此觀點下,policy 的學習可視為對 進行 gradient ascent,其參數更新形式可寫為:

其中, 表示對真實 gradient 的估計,而
表示對真實 gradient 的估計,而  則為 step size,用以控制每次參數更新的幅度。
則為 step size,用以控制每次參數更新的幅度。
目標函數(The Objective)
在 policy gradient 方法中,control 問題被重新表述為一個對策略參數進行最佳化的問題。因此,在推導任何參數更新規則之前,首先必須釐清一個問題,我們究竟希望最大化的是什麼量?
在 RL 中,無論採用的是 value-based 或 policy-based 方法,最終目標始終一致,即最大化 agent 在環境中所能獲得的長期 return。不同方法之間的差異,並不在於學習目標本身,而在於 return 被形式化與最佳化的方式。
由於 policy gradient 方法直接對策略參數進行調整,學習目標必須被表達為一個可對 微分的純量函數。這個函數通常記為 ,用以衡量在策略  下,agent 的整體表現。根據任務是否為 episodic 或 continuing,以及是否引入折扣因子, 的具體定義可能有所不同,但其意涵始終是,在當前policy 下,期望能累積多少 return。
下,agent 的整體表現。根據任務是否為 episodic 或 continuing,以及是否引入折扣因子, 的具體定義可能有所不同,但其意涵始終是,在當前policy 下,期望能累積多少 return。
在明確定義 之後,我們才能進一步討論其 gradient 形式,並推導出實際可用的策略更新規則。
分節任務(Episodic Tasks)
在分節任務(episodic tasks)中,agent 與 environment 的每一次互動都會在有限的 time steps 內結束。對於此類設定,我們可以將 return 定義為自 time step 起,直到 episode 終止為止所累積的折扣回報(discounted return):

其中, 表示該 episode 的終止時間。
表示該 episode 的終止時間。
對於參數化策略 ,policy gradient 方法的目標函數(objective)可定義為起始狀態的 state-value:
![J(\theta) \doteq v_{\pi_\theta}(s_0) = \mathbb{E}_{\pi_\theta}[G_0]](https://s0.wp.com/latex.php?latex=J%28%5Ctheta%29+%5Cdoteq+v_%7B%5Cpi_%5Ctheta%7D%28s_0%29+%3D+%5Cmathbb%7BE%7D_%7B%5Cpi_%5Ctheta%7D%5BG_0%5D+&bg=ffffff&fg=000&s=1&c=20201002)
亦即,在 policy 下,agent 自起始 state 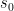 出發,所能獲得的期望累積回報(expected accumulated return)。
出發,所能獲得的期望累積回報(expected accumulated return)。
此一定義在概念上與 value-based 方法中的最大化起始狀態價值  是等價的。差別僅在於,policy gradient 方法將最佳化的對象從 value function 本身,轉換為 policy 的參數 。
是等價的。差別僅在於,policy gradient 方法將最佳化的對象從 value function 本身,轉換為 policy 的參數 。
連續任務(Continuing Tasks)與平均獎勵(Average Reward)
在連續任務(continuing tasks)中,agent 與 environment 的互動並不會自然終止,因此不存在明確的 episode 邊界。在此設定下,除了使用 discounted return 作為性能指標之外,另一種常見且更貼近長期行為表現的衡量方式,是平均獎勵(average reward)。
對於給定的 policy  ,其 average reward可定義為在無限時間範圍內,每個 time step 所能獲得的 expected return:
,其 average reward可定義為在無限時間範圍內,每個 time step 所能獲得的 expected return:
![\displaystyle r(\pi) \doteq \lim_{T \to \infty} \frac{1}{T} \mathbb{E} \Big[ \sum_{t=1}^{T} R_t \mid S_0, A_{0:t-1} \sim \pi \Big]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+r%28%5Cpi%29+%5Cdoteq+%5Clim_%7BT+%5Cto+%5Cinfty%7D+%5Cfrac%7B1%7D%7BT%7D+%5Cmathbb%7BE%7D+%5CBig%5B+%5Csum_%7Bt%3D1%7D%5E%7BT%7D+R_t+%5Cmid+S_0%2C+A_%7B0%3At-1%7D+%5Csim+%5Cpi+%5CBig%5D+&bg=ffffff&fg=000&s=1&c=20201002)
此定義刻畫的是 agent 在長時間運作下的穩定行為表現,而非單一 episode 的累積結果。
若進一步假設在 policy 下,系統存在一個穩態分佈(stationary distribution) ,則 average reward 可等價地寫為 state 與 action 的期望形式:
,則 average reward 可等價地寫為 state 與 action 的期望形式:

在 continuing tasks 中,policy gradient 方法的目標函數即被定義為此長期 average reward,亦即:

策略學習的目的,便是透過調整參數 ,使得在穩態行為下的 average reward 達到最大。
相較於 discounted return,average reward 不依賴折扣因子  ,因此更直接地反映policy 在長期運作下的穩定表現。這使其特別適合用於持續運行、且不存在自然終止條件的任務。然而,average reward 的分析通常仰賴穩態分佈的存在,這也使得其理論推導與實作相對複雜。後續在推導 policy gradient 時,這兩種目標函數形式將分別導出不同的梯度表達,但其主要思想仍然一致,調整 policy ,使高 return 的行為在長期中出現得更頻繁。
,因此更直接地反映policy 在長期運作下的穩定表現。這使其特別適合用於持續運行、且不存在自然終止條件的任務。然而,average reward 的分析通常仰賴穩態分佈的存在,這也使得其理論推導與實作相對複雜。後續在推導 policy gradient 時,這兩種目標函數形式將分別導出不同的梯度表達,但其主要思想仍然一致,調整 policy ,使高 return 的行為在長期中出現得更頻繁。
策略梯度定理(Policy Gradient Theorem)
Policy gradient 方法在 episodic 與 continuing tasks 兩種設定下,具有高度一致的數學結構,其差異僅體現在是否存在一個與時間尺度相關的比例常數,而不影響 gradient 的方向。
對於 episodic tasks,policy gradient 可寫為下列形式:

其中, 表示在目前 policy 下,state 在一個 episode 中被造訪的期望次數。換言之, 反映了該 state 對整體 return 的相對重要性。比例符號
表示在目前 policy 下,state 在一個 episode 中被造訪的期望次數。換言之, 反映了該 state 對整體 return 的相對重要性。比例符號 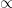 則表示,在 episodic 設定中,policy gradient 的方向由上式所決定,而常數尺度並不影響 gradient ascent 的更新方向。
則表示,在 episodic 設定中,policy gradient 的方向由上式所決定,而常數尺度並不影響 gradient ascent 的更新方向。
對於 continuing tasks,policy gradient theorem 則可以寫成一個精確的等式:

此時, 表示在 policy 下的 state 造訪權重。在 discounted 設定中,它對應於折扣後的 state visitation measure。在 average-reward 設定 中,則對應於系統的穩態分佈。與 episodic 情況相同,策略更新的機制仍是在每個 state 中,依照其重要性,調整 action 的選擇機率。
從操作層面來理解,上述公式表示,policy gradient 是由所有 state 的貢獻所加總而成,而每個 state 的權重正是其在目前 policy 下出現的頻率 。在特定 state 中,對 action 的策略機率變動  ,會依照該 action 的價值 進行加權。價值越高的動作,其對梯度的貢獻也越大。
,會依照該 action 的價值 進行加權。價值越高的動作,其對梯度的貢獻也越大。
不論是在 episodic 或 continuing tasks 中,policy gradient theorem 皆揭示了以下幾個事實:
- Policy improvement 是逐狀態進行的。
- Policy 的整體改變,可分解為在各個 state 中,對 action 機率所做的局部調整。
- 改善方向只依賴動作價值
 。
。- 高價值 action 的機率被提升,低價值 action 的機率被降低。
- State 的重要性由 自然加權。
- 越常被造訪、或對長期表現影響越大的 state,對整體 gradient 的貢獻也越大。
- 不需要對 environment dynamics 求導。
- Policy gradient 的計算不涉及 state transition probabilities 或環境模型的 gradient。
Policy gradient theorem 為  提供了一個解析形式。將此結果代回參數化策略的更新規則後,即可得到策略參數的學習方式:
提供了一個解析形式。將此結果代回參數化策略的更新規則後,即可得到策略參數的學習方式:

Policy gradient theorem 的意義在於,它將對整體 expected return 的 gredient 轉換為一個僅依賴policy 本身與動作價值的形式。雖然式中仍包含未知的 與 ,但這個結構已經明確指出,只要能從取樣資料中近似這些量,就能在不建模 environment dynamics 的情況下進行策略學習。後續章節將進一步說明,如何透過對數導數技巧,將上述表達式轉換為可由 trajectory 直接估計的更新規則。
估計策略梯度(Estimating the Policy Gradient)
雖然 policy gradient theorem 為我們提供了 policy gradient 的解析形式,但在實際問題中,該公式仍然無法直接計算,原因在於其中包含多個未知或不可得的量:
- :在目前 policy 下,各個 state 的造訪機率(或造訪權重)通常未知。
- :每個 state-action pair 的真實 expected return 亦無法事先取得。
- 式子本身需要對所有 state-action pair 進行加總,在大型或連續狀態空間中更是不切實際。
為了克服上述困難,policy gradient 方法利用實際互動所產生的 trajectory samples,同時近似 與 ,並據此構造出對 的無偏差(unbiased)或低偏差(low bias)估計量。
我們首先從 policy gradient theorem 出發,將其中的 gradient 項重新整理。對於任一 state 與 action ,有:

這個步驟利用了對數導數恆等式(log-derivative identity):

其意義在於,policy 的 gradient 可以被轉換為對策略機率對數的 gradient,而這個量只依賴於 policy 本身。
將上述雙重加總視為在分佈  下的期望,可得:
下的期望,可得:
![\nabla J(\theta) = \mathbb{E}_{S \sim \mu, A \sim \pi} \Big[ \nabla \ln \pi(A \mid S) q_\pi(S, A) \Big]](https://s0.wp.com/latex.php?latex=%5Cnabla+J%28%5Ctheta%29+%3D+%5Cmathbb%7BE%7D_%7BS+%5Csim+%5Cmu%2C+A+%5Csim+%5Cpi%7D+%5CBig%5B+%5Cnabla+%5Cln+%5Cpi%28A+%5Cmid+S%29+q_%5Cpi%28S%2C+A%29+%5CBig%5D+&bg=ffffff&fg=000&s=1&c=20201002)
此表達式揭示,我們並不需要顯式地計算 或枚舉所有 state。只要依照目前的 policy 與 environment 互動,state 便會自然地依  的分佈出現,action 也會依 的機率被選擇。換言之,取樣過程本身已隱含地完成了對
的分佈出現,action 也會依 的機率被選擇。換言之,取樣過程本身已隱含地完成了對  的計算。
的計算。
基於上述期望形式,策略參數 的更新即可改寫為以下取樣近似的形式:

其中, 為對真實 action-value
為對真實 action-value  的估計,實務上可由 MC return、TD 估計,或其他近似方式取得。
的估計,實務上可由 MC return、TD 估計,或其他近似方式取得。
上述推導顯示,policy gradient 的估計誤差主要來自於兩個來源,一是有限取樣所造成的隨機變異,二是對  的近似誤差。後續方法(例如 REINFORCE 與 Actor-Critic)正是透過不同方式來估計或近似這個 return 項,並在偏差與變異之間取得權衡。
的近似誤差。後續方法(例如 REINFORCE 與 Actor-Critic)正是透過不同方式來估計或近似這個 return 項,並在偏差與變異之間取得權衡。
REINFORCE:Monte Carlo Policy Gradient
REINFORCE 指的是在 policy gradient 架構中,使用 MC return 來直接估計 action-value function 的方法。其想法是,以完整軌跡(trajectory)中實際觀察到的 return,作為 policy gradient 中 return 項的近似。
考慮一個在 time step 發生的 state–action pair  。沿著 policy 繼續執行直到 episode 結束,MC 方法透過累積後續所有 rewards 來定義 return:
。沿著 policy 繼續執行直到 episode 結束,MC 方法透過累積後續所有 rewards 來定義 return:

在 episodic 設定下,對於給定的 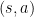 ,action-value function 可寫為:
,action-value function 可寫為:
![q_\pi(s, a) = \mathbb{E}_\pi [ G_t \mid S_t=s, A_t=a ]](https://s0.wp.com/latex.php?latex=q_%5Cpi%28s%2C+a%29+%3D+%5Cmathbb%7BE%7D_%5Cpi+%5B+G_t+%5Cmid+S_t%3Ds%2C+A_t%3Da+%5D+&bg=ffffff&fg=000&s=1&c=20201002)
因此,由實際互動所得到的 return  ,可視為對 的一個無偏差(unbiased)樣本。
,可視為對 的一個無偏差(unbiased)樣本。
在實作層面上,MC 方法透過實際產生的 trajectory,同時完成兩件事情。其一,利用跑出來的 近似在 policy 下的 state–action 分佈。其二,以實際觀察到的 作為對 的估計。這使得 policy gradient 中的期望形式,能夠直接以樣本平均來近似。
綜合前一節對 policy gradient 估計的推導,REINFORCE 的 policy gradient ascent 更新式可寫為:

REINFORCE 因此成為一種直接以 MC return 作為 無偏差估計量的 policy gradient 方法。由於它完全避免 bootstrapping,理論結構相當乾淨且直觀。然而,正因為使用整段 trajectory 的 return 作為學習訊號,其 policy gradient 估計通常具有極高的變異,這在實務上會造成學習不穩定或收斂緩慢。
以下將給出 REINFORCE 的完整演算法流程。

Actor-Critic
REINFORCE 的主要限制在於其 gradient 估計的變異過大,且必須等待整個 episode 結束後才能進行更新,因此無法進行真正的 online 學習。Actor–Critic 方法則引入一個可即時學習的 TD 方法作為 Critic,用以估計狀態價值,並透過每一個 time step 所產生的 TD 訊號來更新策略(Actor),而不必等待 episode 終止。
這樣的設計使 Actor–Critic 以 bootstrapping 換取較低的變異與 online 更新能力,但也因此引入了相對於 REINFORCE 的偏差。這正是 Actor–Critic 方法在偏差與變異之間所做出的取捨。
Actor–Critic 方法由兩個同時學習的元件所組成:
- Actor 表示並更新策略 ,其學習目標是最大化 policy 的性能指標 。
- Critic 則負責學習在當前 policy 下的 state-value function ,並提供一個對當前行為品質的即時評價訊號,作為 Actor 更新策略的依據。
 ,並提供一個對當前行為品質的即時評價訊號,作為 Actor 更新策略的依據。
,並提供一個對當前行為品質的即時評價訊號,作為 Actor 更新策略的依據。Critic 通常透過 TD learning 來進行學習。在最簡單的一步(one-step)設定中,Critic 使用 TD(0) 來更新其 value function 估計:

其中, 為 TD error,反映了當前價值估計與一步 bootstrapped target 之間的差異。
為 TD error,反映了當前價值估計與一步 bootstrapped target 之間的差異。
Actor 則利用 Critic 所提供的 TD error,來近似 policy gradient 中的 return 項,並即時更新策略參數:

從 policy gradient 的角度來看,TD error 在此扮演的是一個即時 return 訊號的角色。當實際 return 與價值預期相比好於預期時( ),Actor 會提高當前 action 的選擇機率;反之,則降低其機率。
),Actor 會提高當前 action 的選擇機率;反之,則降低其機率。
在 policy gradient theorem 的統一框架下,Actor–Critic 與 REINFORCE 的差異可被清楚地理解為對 的估計方式不同:
- REINFORCE 使用完整的 MC return 作為 的無偏差估計,但具有高變異,且無法 online 更新。
- Actor–Critic 使用以 TD learning 訓練的 value function,並透過 TD error 進行 bootstrapping,以引入偏差換取較低變異與即時更新能力。
正因如此,Actor–Critic 方法使 policy gradient 能夠實際應用於長期或連續任務中,而不再受限於 episodic 設定。
以下將給出 One-Step Actor–Critic 的完整演算法流程。

範例
Actor-Critic 實作
在本實作中,Actor 與 Critic 皆以多層感知器(Multi-Layer Perceptron, MLP)作為 function approximator。Actor 網路輸出各個動作的 logits,並透過 Categorical 分佈進行取樣,以形成一個隨機策略 。Critic 則負責估計狀態價值  ,作為 TD 學習的基準。
,作為 TD 學習的基準。
在每一個 time step 的互動中,訓練流程依序如下進行。首先,由 Critic 根據當前狀態與下一狀態計算 TD target,並進而得到 TD error。Critic 以平方 TD error 作為 loss,更新其 value function 參數,使 能逐步逼近在目前 policy 下的真實 state-value。
Actor 則使用同一個 TD error 作為策略更新的學習訊號,並將其與對應動作的對數機率  相乘,形成 policy gradient 的估計。實作上,TD error 在用於 Actor 更新時會進行
相乘,形成 policy gradient 的估計。實作上,TD error 在用於 Actor 更新時會進行 detach(),以避免梯度經由 Actor 的 loss 回傳至 Critic,確保 Critic 的更新僅依賴其自身的 TD learning。這樣的處理方式,實質上對應於 policy gradient theorem 中的 semi-gradient 設定。
為了提升整體訓練的穩定性,Actor 與 Critic 採用不同的 learning rate,以反映兩者在學習動態上的差異;同時,對兩個網路的 gradient 皆進行裁剪(gradient clipping),以避免因梯度爆炸而導致訓練不穩定。
import numpy as np
import torch
import torch.nn as nn
from torch import optim
class Actor(nn.Module):
def __init__(self, observation_dim: int, n_actions: int, hidden_dim: int = 256):
super().__init__()
self.network = nn.Sequential(
nn.Linear(observation_dim, hidden_dim),
nn.Tanh(),
nn.Linear(hidden_dim, hidden_dim),
nn.Tanh(),
nn.Linear(hidden_dim, n_actions),
)
def forward(self, obs: torch.Tensor):
logits = self.network(obs)
return torch.distributions.Categorical(logits=logits)
class Critic(nn.Module):
def __init__(self, observation_dim: int, hidden_dim: int = 256):
super().__init__()
self.critic = nn.Sequential(
nn.Linear(observation_dim, hidden_dim),
nn.Tanh(),
nn.Linear(hidden_dim, hidden_dim),
nn.Tanh(),
nn.Linear(hidden_dim, 1),
)
def forward(self, obs: torch.Tensor):
return self.critic(obs).squeeze(-1)
class ActorCritic(nn.Module):
def __init__(
self,
observation_dim: int,
n_actions: int,
*,
hidden_dim: int,
actor_lr: float = 1e-4,
critic_lr: float = 1e-3,
grad_clip=2.0,
gamma: float = 0.99,
):
super().__init__()
self.actor = Actor(observation_dim, n_actions, hidden_dim)
self.critic = Critic(observation_dim, hidden_dim)
self.grad_clip = grad_clip
self.gamma = gamma
self.actor_optimizer = optim.Adam(self.actor.parameters(), lr=actor_lr)
self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=critic_lr)
def act(self, s: np.ndarray):
s_t = torch.tensor(s, dtype=torch.float32).unsqueeze(0)
pi_s = self.actor(s_t)
a = pi_s.sample()
return int(a.item()), pi_s
def update(
self, s: np.ndarray, a: int, r: float, s_prime: np.ndarray, pi_s: torch.distributions.Categorical, terminated: bool
) -> tuple[float, float]:
s_t = torch.tensor(s, dtype=torch.float32).unsqueeze(0)
a_t = torch.tensor([a], dtype=torch.long).unsqueeze(0)
s_tp1 = torch.tensor(s_prime, dtype=torch.float32).unsqueeze(0)
v_t = self.critic(s_t)
with torch.no_grad():
if terminated:
v_prime = torch.tensor(0.0)
else:
v_prime = self.critic(s_tp1)
td_target = r + self.gamma * v_prime
td_error = td_target - v_t
critic_loss = 0.5 * td_error.pow(2)
self.critic_optimizer.zero_grad()
critic_loss.backward()
nn.utils.clip_grad_norm_(self.critic.parameters(), self.grad_clip)
self.critic_optimizer.step()
actor_loss = -(td_error.detach() * pi_s.log_prob(a_t))
self.actor_optimizer.zero_grad()
actor_loss.backward()
nn.utils.clip_grad_norm_(self.actor.parameters(), self.grad_clip)
self.actor_optimizer.step()
return float(actor_loss.item()), float(critic_loss.item())Lunar Lander
Lunar Lander 是一個經典的火箭軌跡最佳化問題。根據龐特里亞金最大值原理(Pontryagin’s maximum principle),在 optimal policy 下,引擎不是以全推力運作,就是完全關閉。因此,這個環境採用了離散動作空間,對應於引擎的開啟或關閉。
Action space 中共有四個 actions:
- 0:不執行任何動作。
- 1:啟動左側引擎。
- 2:啟動主引擎。
- 3:啟動右側引擎。
每一個 state 是一個 8 維向量,其內容依序包含:
- Lander 的 x 和 y 座標位置。
- Lander 在 x 和 y 的線性速度。
- Lander 的角度。
- Lander 的角速度。
- 兩個 boolean 值,分別表示 Lander 的左右腳是否與地面接觸。
對於每一個 time step,reward 為:
- Lander 越接近地面,reward 越高;反之,reward 越低。
- Lander 的移動速度越慢,reward 越高;反之,reward 越低。
- Lander 的傾斜角度越大,reward 越低。
- 每當有一隻腳與地面接觸時,reward 增加 10 分。
- 每一個 frame 中,只要側向的引擎啟動一次,reward 減少 0.03 分。
- 每一個 frame 中,只要主引擎啟動一次,reward 減少 0.3 分。
若 episode 以墜毀或安全著陸結束,則會額外給予一次性回饋:
- 墜毀:-100 分。
- 安全著陸:+100 分。
當一個 episode 的 total rewards 達到 200 分以上時,即被視為成功解(solution)。
以下的程式碼中,我們訓練 Actor-Critic 1000 episodes。
import time
import gymnasium as gym
from actor_critic import ActorCritic
GYM_ID = "LunarLander-v3"
N_EPISODES = 1000
MAX_STEPS = 1000
def play_game(agent: ActorCritic, episodes=1):
visual_env = gym.make(GYM_ID, render_mode="human") # UI window
for episode in range(episodes):
state, _ = visual_env.reset()
terminated = False
truncated = False
total_reward = 0.0
step_count = 0
input("Press Enter to play game")
print(f"Episode {episode + 1} starts")
while not terminated and not truncated:
action, _ = agent.act(state)
state, reward, terminated, truncated, _ = visual_env.step(action)
total_reward += reward
step_count += 1
visual_env.render()
print(f"Episode {episode + 1} is finished: Total reward is {total_reward}, steps = {step_count}")
time.sleep(1)
visual_env.close()
def train() -> ActorCritic:
env = gym.make(GYM_ID)
agent = ActorCritic(
observation_dim=env.observation_space.shape[0],
n_actions=env.action_space.n,
hidden_dim=256,
actor_lr=3e-4,
)
returns = 0.0
for i_episode in range(1, N_EPISODES + 1):
print(f"\rEpisode: {i_episode}/{N_EPISODES}", end="", flush=True)
s, _ = env.reset()
done = False
G = 0.0
steps = 0
while not done and steps < MAX_STEPS:
a, pi_s = agent.act(s)
s_prime, r, terminated, truncated, _ = env.step(a)
G += r
done = terminated or truncated
agent.update(s, a, r, s_prime, pi_s, done)
s = s_prime
steps += 1
returns += G
if i_episode % 50 == 0:
print(f"\nEpisode: {i_episode}/{N_EPISODES}, average return: {returns / 50:.2f}")
returns = 0.0
return agent
if __name__ == "__main__":
agent = train()
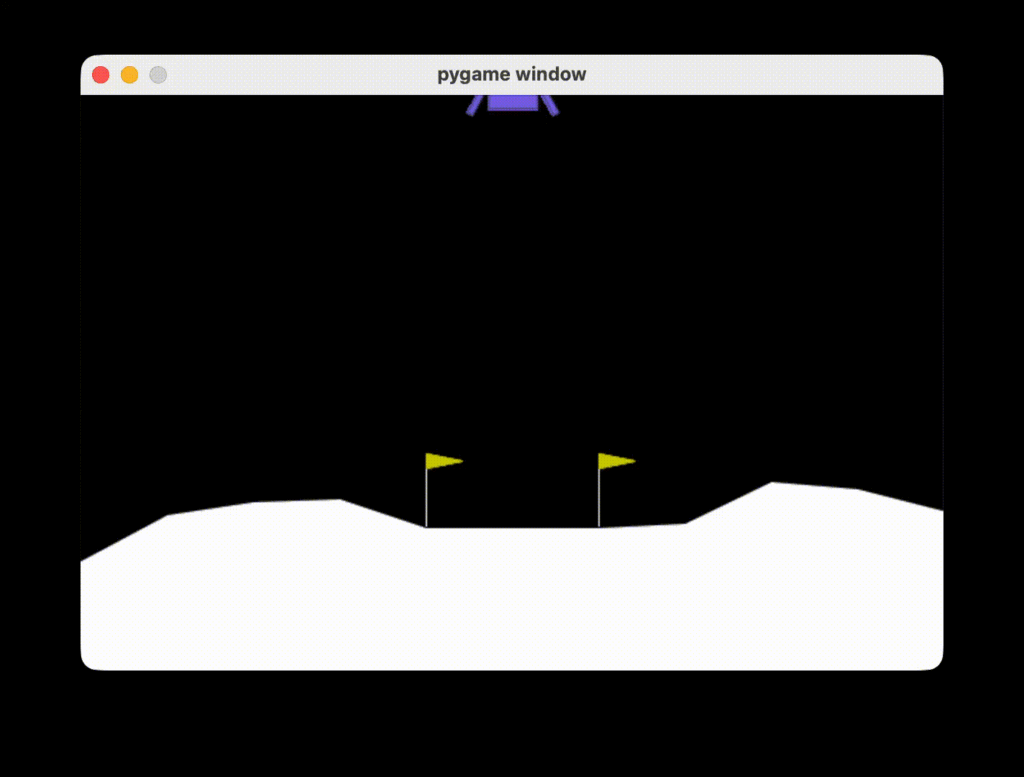
play_game(agent)在訓練約 1000 個 episodes 後,Actor–Critic agent 已能穩定完成著陸任務。實際執行時可觀察到,飛行器多半維持在著陸平台正上方,橫向位移明顯受控,並以平緩且連續的速度逐步下降,最終成功著陸。
此一行為表現顯示,透過 TD error 作為即時學習訊號,Actor–Critic 能夠學得平順且穩定的控制策略。相較於依賴整段 return、容易產生大幅修正的學習方式,Actor–Critic 的策略更新更具漸進性,傾向於在維持姿態與位置穩定的前提下進行調整。這也反映出 on-policy Actor–Critic 方法在連續控制問題中,對學習穩定性與安全行為的自然偏好。
結語
透過 REINFORCE 與 Actor–Critic 的對照,可以清楚看出 policy gradient 方法在偏差與變異之間的取捨,以及 bootstrapping 與 online 更新能力對控制穩定性的影響。實驗結果顯示,Actor–Critic 透過 TD error 作為即時學習訊號,能夠學得連續且平順的控制行為,使 policy gradient 方法得以實際應用於長期與連續控制任務。整體而言,Policy Gradient 不僅提供了一條不同於 value-based 方法的學習路徑,也為後續更進階的 control 與 deep RL 方法奠定了清楚且一致的理論基礎。
參考
- Adam White and Martha White. Reinforcement Learning Specialization. University of Alberta and Coursera.
- Richard S. Sutton and Andrew G. Barto. 2020. Reinforcement Learning: An Introduction, 2nd. The MIT Press.









