
本章聚焦於函數近似的 On-Policy 預測(on-policy prediction with approximation),系統性地整理在此設定下,價值估計的學習目標、可行的學習方法,以及它們實際收斂到的解。透過 Gradient Monte Carlo 與 Semi-Gradient TD(0) 的對照,我們將看到,理論上的正確目標與實務上的可行方法之間,究竟存在著何種不可避免的取捨。
Table of Contents
預測問題(Prediction Problem)
在 prediction 問題中,我們的目標並非尋找或改進 policy,而是在給定一個固定 policy  的前提下,評估該 policy 的長期表現。更具體地說,prediction 問題關心的是在此 policy 下,各個 state 所對應的 state-value function,其定義如下:
的前提下,評估該 policy 的長期表現。更具體地說,prediction 問題關心的是在此 policy 下,各個 state 所對應的 state-value function,其定義如下:
![v_\pi(s) \doteq \mathbb{E}_\pi [ G_t \mid S_t=s ]](https://s0.wp.com/latex.php?latex=v_%5Cpi%28s%29+%5Cdoteq+%5Cmathbb%7BE%7D_%5Cpi+%5B+G_t+%5Cmid+S_t%3Ds+%5D+&bg=ffffff&fg=000&s=1&c=20201002)
此一量測代表的是,在遵循 policy 的情況下,從 state  出發,未來所能獲得的 expected return。
出發,未來所能獲得的 expected return。
在這類問題中,policy 被視為已知且固定,整個學習過程不涉及任何形式的 policy improvement,而是專注於如何更準確地估計該 policy 所誘發的 value-function。也因此,prediction 問題可視為一個純粹的價值估計問題,其核心挑戰在於如何有效地利用經驗資料,逼近真實的  。
。
從更宏觀的角度來看,prediction 問題構成了強化學習中所有 control 方法的基礎。無論後續如何設計 policy improvement 機制,或採用 on-policy 與 off-policy 的控制策略,都必須仰賴對「當前 policy 的價值」具有可靠且穩定的估計作為依據。
價值函數近似(Value-Function Approximation)
當 state space 龐大,甚至為連續空間時,為每一個 state 分別儲存一個獨立的價值估計(例如:tabular 方法)便不再可行。在這樣的情境下,我們必須引入函數近似(function approximation),以一個具有限制表示能力的函數來描述 value function。
在此架構中,我們不再嘗試直接表示或儲存真實的 state-value function ,而是使用一個參數化的近似函數  ,來逼近其行為,其中 為可微分的函數,而
,來逼近其行為,其中 為可微分的函數,而 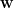 為可學習的參數向量。形式上,我們希望滿足:
為可學習的參數向量。形式上,我們希望滿足:

透過這樣的表示方式,價值估計得以在不同 state 之間產生泛化(generalization),使 agent 能夠從有限的互動經驗中,學習到整體性的價值結構,而非僅限於曾經明確造訪過的 states。
然而,引入 function approximation 也同時帶來一個不可避免的現實限制,即在有限的函數空間中,通常無法在所有 states 上精確重現真實的 。因此,學習的目標不再是對所有 state 完全正確,而是轉化為在 policy 實際誘發的 state distribution 下,尋找一個在整體意義上最合理、誤差最小的近似解。
On-Policy
在 on-policy 的設定中,負責產生資料的 behavior policy,與我們欲評估的 target policy 為同一個 policy 。也就是說,agent 與 environment 互動所蒐集到的所有經驗軌跡,皆是在遵循 policy 的前提下產生。
由於資料分佈與評估對象完全一致,學習過程中不涉及任何策略分佈(policy distribution)的轉換,也不需要額外的校正機制(如 importance sampling)。在此設定下,agent 只需專注於如何利用在 policy 下實際觀測到的經驗,來估計該 policy 所對應的 value function。
這樣的假設在理論分析與演算法設計上相對單純,特別是在結合函數近似時,on-policy 的資料分佈將直接決定哪些 states 對學習結果具有主要影響。這一點,將在後續定義學習目標與誤差函數時,扮演關鍵角色。
預測目標(Prediction Objective)
在引入 function approximation 之後,價值估計問題的核心,已不再是是否能精確計算 ,而是如何定義一個合理且可操作的準則,來衡量近似函數的好壞。
由於真實的 state-value function  通常不屬於我們所選擇的函數空間,因此必須接受,無法在所有 states 上完全重現其值。在這樣的限制下,學習目標自然轉化為,在 policy 實際造訪的 state distribution 下,尋找一個整體誤差最小的近似解。
通常不屬於我們所選擇的函數空間,因此必須接受,無法在所有 states 上完全重現其值。在這樣的限制下,學習目標自然轉化為,在 policy 實際造訪的 state distribution 下,尋找一個整體誤差最小的近似解。
基於上述考量,我們可以將 prediction with approximation 的目標,明確定義為均方價值誤差(Mean Squared Value Error, MSVE):
![\displaystyle \sum_s \mu(s) = 1, \quad \mu(s) \ge 0 \\\\ \overline{VE} (\mathbf{w}) \doteq \sum_s \mu(s)\Big[ v_\pi(s) - \hat v(s, \mathbf{w}) \Big]^2 = \mathbb{E}_{S \sim \mu} \Big[ [v_\pi(S) - \hat{v}(S, \mathbf{w})]^2 \Big]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_s+%5Cmu%28s%29+%3D+1%2C+%5Cquad+%5Cmu%28s%29+%5Cge+0+%5C%5C%5C%5C+%5Coverline%7BVE%7D+%28%5Cmathbf%7Bw%7D%29+%5Cdoteq+%5Csum_s+%5Cmu%28s%29%5CBig%5B+v_%5Cpi%28s%29+-+%5Chat+v%28s%2C+%5Cmathbf%7Bw%7D%29+%5CBig%5D%5E2+%3D+%5Cmathbb%7BE%7D_%7BS+%5Csim+%5Cmu%7D+%5CBig%5B+%5Bv_%5Cpi%28S%29+-+%5Chat%7Bv%7D%28S%2C+%5Cmathbf%7Bw%7D%29%5D%5E2+%5CBig%5D+&bg=ffffff&fg=000&s=1&c=20201002)
其中  為 state distribution,表示在 policy 下,agent 於長期互動過程中實際造訪 state 的頻率分佈。此一目標函數透過 對不同 states 的誤差進行加權,反映出學習過程中哪些 states 對整體效能影響最大。
為 state distribution,表示在 policy 下,agent 於長期互動過程中實際造訪 state 的頻率分佈。此一目標函數透過 對不同 states 的誤差進行加權,反映出學習過程中哪些 states 對整體效能影響最大。
從形式上來看,這個目標函數與監督式學習(supervised learning)中的均方誤差(mean squared error, MSE)完全一致,其輸入為 state  ,而 label 則是對應的真實價值
,而 label 則是對應的真實價值  。因此,在理論上,我們可以直接對此目標函數進行 gradient descent,以逐步調整參數 。
。因此,在理論上,我們可以直接對此目標函數進行 gradient descent,以逐步調整參數 。
具體而言,考慮在單一樣本  下的 MSE 損失(loss):
下的 MSE 損失(loss):
![\Big[ v_\pi(S_t) - \hat{v}(S_t, \mathbf{w}_t) \Big] ^2](https://s0.wp.com/latex.php?latex=%5CBig%5B+v_%5Cpi%28S_t%29+-+%5Chat%7Bv%7D%28S_t%2C+%5Cmathbf%7Bw%7D_t%29+%5CBig%5D+%5E2+&bg=ffffff&fg=000&s=1&c=20201002)
對參數 進行梯度下降(gradient descent),得到更新式:
![\mathbf{w}_{t+1} \doteq \mathbf{w}_t - \frac{1}{2} \alpha \nabla \Big[ v_\pi(S_t) - \hat{v}(S_t, \mathbf{w}_t) \Big] ^2 \\\\ \hphantom{\mathbf{w}_{t+1}} = \mathbf{w}_t + \alpha \Big[ v_\pi(S_t) - \hat{v}(S_t, \mathbf{w}_t) \Big] \nabla \hat{v}(S_t, \mathbf{w}_t)](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bw%7D_%7Bt%2B1%7D+%5Cdoteq+%5Cmathbf%7Bw%7D_t+-+%5Cfrac%7B1%7D%7B2%7D+%5Calpha+%5Cnabla+%5CBig%5B+v_%5Cpi%28S_t%29+-+%5Chat%7Bv%7D%28S_t%2C+%5Cmathbf%7Bw%7D_t%29+%5CBig%5D+%5E2+%5C%5C%5C%5C+%5Chphantom%7B%5Cmathbf%7Bw%7D_%7Bt%2B1%7D%7D+%3D+%5Cmathbf%7Bw%7D_t+%2B+%5Calpha+%5CBig%5B+v_%5Cpi%28S_t%29+-+%5Chat%7Bv%7D%28S_t%2C+%5Cmathbf%7Bw%7D_t%29+%5CBig%5D+%5Cnabla+%5Chat%7Bv%7D%28S_t%2C+%5Cmathbf%7Bw%7D_t%29+&bg=ffffff&fg=000&s=1&c=20201002)
其中,gradient 算子定義為:

值得注意的是,雖然此一目標函數在概念上相當清楚,但在 RL 的情境下,它隱含了一個重要困難,即 本身是未知的。因此,實際可行的學習方法,必須以某種方式對此目標進行近似或替代。
這個結果清楚地顯示,只要能取得真實的  ,我們便能直接對 MSVE 進行標準的gradient descent 更新。然而,在 RL 的情境中, 本身正是我們欲估計的未知量,因此上述更新式在實務上並不可直接使用。這個根本困難,正是後續 MC方法與 TD 方法必須透過取樣與 bootstrap 來近似或替代學習目標的原因。
,我們便能直接對 MSVE 進行標準的gradient descent 更新。然而,在 RL 的情境中, 本身正是我們欲估計的未知量,因此上述更新式在實務上並不可直接使用。這個根本困難,正是後續 MC方法與 TD 方法必須透過取樣與 bootstrap 來近似或替代學習目標的原因。
梯度蒙地卡羅(Gradient Monte Carlo)
先前我們已將 prediction with approximation 的學習目標,明確定義為最小化在 state distribution 下加權的 MSVE。然而,這個目標在實務上立即面臨一個根本性的困難,真實的 state-value function 無法直接觀測,因此也無法直接計算對應的 gradient。
梯度蒙地卡羅(Gradient Monte Carlo)的想法是,將 prediction 問題視為一個標準的 supervised learning 問題,並利用 MC return 作為 value function 的學習訊號。回顧 state-value function 的定義:
![v_\pi(s) = \mathbb{E}_\pi [G_t \mid S_t=s]](https://s0.wp.com/latex.php?latex=v_%5Cpi%28s%29+%3D+%5Cmathbb%7BE%7D_%5Cpi+%5BG_t+%5Cmid+S_t%3Ds%5D+&bg=ffffff&fg=000&s=1&c=20201002)
可以注意到,在 on-policy 的設定下,實際觀察到的 return  正是一個對 的無偏差(unbiased)估計。也就是說,在給定
正是一個對 的無偏差(unbiased)估計。也就是說,在給定  的條件下,有
的條件下,有 ![\mathbb{E} [G_t \mid S_t=s] = v_\pi(s)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D+%5BG_t+%5Cmid+S_t%3Ds%5D+%3D+v_%5Cpi%28s%29&bg=ffffff&fg=000&s=0&c=20201002) 。
。
基於這一事實,Gradient MC 直接以實際觀察到的 ,取代未知的 ,並對 MSVE 目標函數進行 gradient descent。其對應的參數更新形式為:
![U_t \doteq G_t \\\\ \mathbf{w}_{t+1} = \mathbf{w}_t + \alpha \Big[ U_t - \hat{v}(S_t, \mathbf{w}_t) \Big] \nabla \hat{v}(S_t, \mathbf{w}_t)](https://s0.wp.com/latex.php?latex=U_t+%5Cdoteq+G_t+%5C%5C%5C%5C+%5Cmathbf%7Bw%7D_%7Bt%2B1%7D+%3D+%5Cmathbf%7Bw%7D_t+%2B+%5Calpha+%5CBig%5B+U_t+-+%5Chat%7Bv%7D%28S_t%2C+%5Cmathbf%7Bw%7D_t%29+%5CBig%5D+%5Cnabla+%5Chat%7Bv%7D%28S_t%2C+%5Cmathbf%7Bw%7D_t%29+&bg=ffffff&fg=000&s=1&c=20201002)
由於此一更新式來自於對 MSVE 的真實梯度(true gradient),Gradient MC 在理論上確實是在直接最小化我們一開始所定義的預測目標,而非某種近似或替代的誤差形式。
Gradient MC 的演算法流程如下所示。

然而,Gradient MC 的優點,同時也是它的主要限制。由於完整的 return 必須等到整個 episode 結束後才能計算,這種方法無法進行真正的 online 更新,對於持續型任務(continuing tasks)而言更是幾乎不可行。此外,MC return 本身具有高度變異性,特別是在 return 延遲較長或環境隨機性較高的情況下,學習過程往往不穩定,資料使用效率也相對偏低。
正因如此,Gradient MC 在實務應用中較少被直接採用。它的真正價值,在於提供了一個數學上乾淨、概念上清楚,且直接對應學習目標的理論基準。
半梯度 TD(0)(Semi-Gradient TD(0))
在 RL 的實際情境中, 本身正是我們欲估計的未知量,這使得先前所推導的 true gradient 更新在實務上無法直接實作。Gradient MC 透過以完整的 return 作為 的 unbiased 估計,提供了一條理論上正確、但計算代價高昂且不具即時性的途徑。
時序差分(Temporal-Difference, TD)的想法則是,利用 Bellman expectation equation 所隱含的遞迴結構,構造一個在每一個 time step 即可取得的學習目標。回顧在 policy 下,state-value function 所滿足的 Bellman expectation equation:
![v_\pi(s) = \mathbb{E}_\pi \big[ R_{t+1} + \gamma v_\pi(S_{t+1}) \mid S_t = s \big]](https://s0.wp.com/latex.php?latex=v_%5Cpi%28s%29+%3D+%5Cmathbb%7BE%7D_%5Cpi+%5Cbig%5B+R_%7Bt%2B1%7D+%2B+%5Cgamma+v_%5Cpi%28S_%7Bt%2B1%7D%29+%5Cmid+S_t+%3D+s+%5Cbig%5D+&bg=ffffff&fg=000&s=1&c=20201002)
若以目前的近似函數  來取代未知的 ,即可得到一個基於 bootstrapping 的即時 target:
來取代未知的 ,即可得到一個基於 bootstrapping 的即時 target:

此一 target 在每一個 time step 都可立即計算,無需等待整個 episode 結束,從而使得線上學習成為可能。
在此基礎上,Semi-Gradient TD(0) 沿著當前 state 的參數 gradient 方向,利用 TD error  來更新近似函數,其更新規則如下:
來更新近似函數,其更新規則如下:
![U_t \doteq R_{t+1} + \gamma \hat v(S_{t+1}, \mathbf{w}) \\\\ \delta_t \doteq R_{t+1} + \gamma \hat{v}(S_{t+1}, \mathbf{w}_t) - \hat{v}(S_t, \mathbf{w}_t) \\\\ \mathbf{w}_{t+1} = \mathbf{w}_t + \alpha \Big[ U_t - \hat{v}(S_t, \mathbf{w}_t) \Big] \nabla \hat{v}(S_t, \mathbf{w}_t) \\\\ \hphantom{\mathbf{w}_{t+1}} = \mathbf{w}_t + \alpha \delta_t \nabla \hat{v}(S_t, \mathbf{w}_t)](https://s0.wp.com/latex.php?latex=U_t+%5Cdoteq+R_%7Bt%2B1%7D+%2B+%5Cgamma+%5Chat+v%28S_%7Bt%2B1%7D%2C+%5Cmathbf%7Bw%7D%29+%5C%5C%5C%5C+%5Cdelta_t+%5Cdoteq+R_%7Bt%2B1%7D+%2B+%5Cgamma+%5Chat%7Bv%7D%28S_%7Bt%2B1%7D%2C+%5Cmathbf%7Bw%7D_t%29+-+%5Chat%7Bv%7D%28S_t%2C+%5Cmathbf%7Bw%7D_t%29++%5C%5C%5C%5C+%5Cmathbf%7Bw%7D_%7Bt%2B1%7D+%3D+%5Cmathbf%7Bw%7D_t+%2B+%5Calpha+%5CBig%5B+U_t+-+%5Chat%7Bv%7D%28S_t%2C+%5Cmathbf%7Bw%7D_t%29+%5CBig%5D+%5Cnabla+%5Chat%7Bv%7D%28S_t%2C+%5Cmathbf%7Bw%7D_t%29+%5C%5C%5C%5C+%5Chphantom%7B%5Cmathbf%7Bw%7D_%7Bt%2B1%7D%7D+%3D+%5Cmathbf%7Bw%7D_t+%2B+%5Calpha+%5Cdelta_t+%5Cnabla+%5Chat%7Bv%7D%28S_t%2C+%5Cmathbf%7Bw%7D_t%29+&bg=ffffff&fg=000&s=1&c=20201002)
需要特別強調的是,這個更新式並非來自於對某個明確定義之 loss function 進行完整的 gradient descent。若將 TD target  視為 loss 的一部分,則該 target 本身也依賴於參數 。
視為 loss 的一部分,則該 target 本身也依賴於參數 。
然而,在 TD 方法中,我們刻意忽略了 target 對參數 的 gradeint,只保留對當前估計  的 gradient 項。正因如此,這類方法被稱為半梯度(semi-gradient)方法,以區別於先前對 MSVE 所進行的 true gradient 更新。
的 gradient 項。正因如此,這類方法被稱為半梯度(semi-gradient)方法,以區別於先前對 MSVE 所進行的 true gradient 更新。
這樣的設計選擇,體現了一個關鍵的取捨,即相較於 Gradient MC,Semi-Gradient TD(0) 不再保證直接最小化 MSVE,但作為交換,它能夠進行即時的 online 更新、顯著降低估計的變異性,並且在 on-policy 設定且搭配線性函數近似時,具備良好的理論收斂性質。
以下為 Semi-Gradient TD(0) 演算法。

線性方法(Linear Methods)
在各種 function approximation 方法中,線性函數近似(linear function approximation)是最重要、也最常被分析的一種特殊情形。其 state-value function 被表示為:

其中  為 state 所對應的特徵向量(feature vector),而
為 state 所對應的特徵向量(feature vector),而  則為可學習的參數向量。這樣的表示方式隱含了一個重要假設,即 value function 可以由一組事先設計或學得的特徵,透過線性組合來近似。
則為可學習的參數向量。這樣的表示方式隱含了一個重要假設,即 value function 可以由一組事先設計或學得的特徵,透過線性組合來近似。
線性函數近似的一大優點,在於其 gradient 形式極為簡潔。由於

對參數 取 gradient,可直接得到:

也就是說,在 linear approximation 下,value function 對參數的 gradient,正好等於當前 state 的 feature vector 本身。這使得後續所有基於 gradient 的更新規則,都可以統一寫成 error 項乘上 feature vector 的形式:
![\delta_t = U_t - \hat{v}(S_t, \mathbf{w}_t) \\\\ \mathbf{w}_{t+1} = \mathbf{w}_t + \alpha \Big[ U_t - \hat{v}(S_t, \mathbf{w}_t) \Big] \nabla \hat{v}(S_t, \mathbf{w}_t) \\\\ \hphantom{\mathbf{w}_{t+1}} = \mathbf{w}_t + \alpha \delta_t \nabla \hat{v}(S_t, \mathbf{w}_t) \\\\ \hphantom{\mathbf{w}_{t+1}} = \mathbf{w}_t + \alpha \delta_t \mathbf{x}(S_t)](https://s0.wp.com/latex.php?latex=%5Cdelta_t+%3D+U_t+-+%5Chat%7Bv%7D%28S_t%2C+%5Cmathbf%7Bw%7D_t%29+%5C%5C%5C%5C+%5Cmathbf%7Bw%7D_%7Bt%2B1%7D+%3D+%5Cmathbf%7Bw%7D_t+%2B+%5Calpha+%5CBig%5B+U_t+-+%5Chat%7Bv%7D%28S_t%2C+%5Cmathbf%7Bw%7D_t%29+%5CBig%5D+%5Cnabla+%5Chat%7Bv%7D%28S_t%2C+%5Cmathbf%7Bw%7D_t%29+%5C%5C%5C%5C+%5Chphantom%7B%5Cmathbf%7Bw%7D_%7Bt%2B1%7D%7D+%3D+%5Cmathbf%7Bw%7D_t+%2B+%5Calpha+%5Cdelta_t+%5Cnabla+%5Chat%7Bv%7D%28S_t%2C+%5Cmathbf%7Bw%7D_t%29+%5C%5C%5C%5C+%5Chphantom%7B%5Cmathbf%7Bw%7D_%7Bt%2B1%7D%7D+%3D+%5Cmathbf%7Bw%7D_t+%2B+%5Calpha+%5Cdelta_t+%5Cmathbf%7Bx%7D%28S_t%29+&bg=ffffff&fg=000&s=1&c=20201002)
將此結果代入 Semi-Gradient TD(0) 的更新規則中,即可得到其在 linear function approximation 下的具體形式:

此一形式清楚顯示,在每一個 time step 中,參數 的更新方向永遠沿著當前 state 的 feature vector  ,而更新幅度則由 TD error 所控制。換言之,TD(0) 透過對下一個狀態價值的估計,將未來資訊以 bootstrapping 的方式回饋至當前參數更新中。
,而更新幅度則由 TD error 所控制。換言之,TD(0) 透過對下一個狀態價值的估計,將未來資訊以 bootstrapping 的方式回饋至當前參數更新中。
在 episodic 任務中,若  為 terminal state,慣例上定義
為 terminal state,慣例上定義  ,此時 TD error 退化為:
,此時 TD error 退化為:

透過 linear function approximation 的具體展開,我們可以清楚看到 Semi-Gradient TD(0) 的學習行為,已不再是抽象的對某個未知目標進行修正,而是對一個明確的參數向量,依據特徵表示與 bootstrapped 目標,進行可解釋且可分析的逐步調整。
TD 固定點(TD Fixed Point)
在引入 linear function approximation 之後,Semi-Gradient TD(0) 的學習行為,可以被理解為,尋找一個使參數更新在期望意義下為零的固定點(fixed point)。這個 fixed point,即為 TD 方法實際收斂的解,通常稱為 TD fixed point。
在 linear function approximation 下,Semi-Gradient TD(0) 的參數更新形式可寫為:

在學習過程進入穩定狀態後,我們可以考慮在給定目前權重向量  的情況下,更新量在期望意義下的行為。為此,定義以下兩個量:
的情況下,更新量在期望意義下的行為。為此,定義以下兩個量:
![\mathbf{b} \doteq \mathbb{E} [ R_{t+1} \mathbf{x}_t ] \in \mathbb{R}^d \\\\ \mathbf{A} \doteq \mathbb{E} [ \mathbf{x}_t (\mathbf{x}_t - \gamma \mathbf{x}_{t+1})^\top ] \in \mathbb{R}^d \times \mathbb{R}^d \\\\ \mathbb{E} [ \mathbf{w}_{t+1} \mid \mathbf{w}_t ] = \mathbf{w}_t + \alpha (\mathbf{b} - \mathbf{A} \mathbf{w}_t)](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bb%7D+%5Cdoteq+%5Cmathbb%7BE%7D+%5B+R_%7Bt%2B1%7D+%5Cmathbf%7Bx%7D_t+%5D+%5Cin+%5Cmathbb%7BR%7D%5Ed+%5C%5C%5C%5C+%5Cmathbf%7BA%7D+%5Cdoteq+%5Cmathbb%7BE%7D+%5B+%5Cmathbf%7Bx%7D_t+%28%5Cmathbf%7Bx%7D_t+-+%5Cgamma+%5Cmathbf%7Bx%7D_%7Bt%2B1%7D%29%5E%5Ctop+%5D+%5Cin+%5Cmathbb%7BR%7D%5Ed+%5Ctimes+%5Cmathbb%7BR%7D%5Ed+%5C%5C%5C%5C+%5Cmathbb%7BE%7D+%5B+%5Cmathbf%7Bw%7D_%7Bt%2B1%7D+%5Cmid+%5Cmathbf%7Bw%7D_t+%5D+%3D+%5Cmathbf%7Bw%7D_t+%2B+%5Calpha+%28%5Cmathbf%7Bb%7D+-+%5Cmathbf%7BA%7D+%5Cmathbf%7Bw%7D_t%29+&bg=ffffff&fg=000&s=1&c=20201002)
若演算法發生收斂,則必須存在一個權重向量  ,使得在該點上期望更新為零,即:
,使得在該點上期望更新為零,即:

此一解即為 TD fixed point。在 on-policy 且搭配 linear function approximation 的條件下,只要矩陣 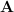 為非奇異(此條件通常可滿足),Semi-Gradient TD(0) 在適當的 step size 設定下,便會收斂至此 fixed point。
為非奇異(此條件通常可滿足),Semi-Gradient TD(0) 在適當的 step size 設定下,便會收斂至此 fixed point。
這個結果揭示了,Semi-Gradient TD(0) 並非在最小化 MSVE,而是等價於在解一組由環境動態(transition dynamics)與特徵表示共同決定的線性方程式。從另一個角度來看,TD fixed point 可被理解為,在特徵空間中,使近似 value function 在期望意義下滿足 Bellman 一致性(Bellman consistency)的解。
範例
Gradient Monte Carlo 實作
在以下的程式碼,我們忠實地實作 Gradient Monte Carlo 方法。
程式碼中的 env 是 Gymnasium 的 Env 物件。Gymnasium 的前身是 OpenAI Gym。它提供了眾多的 RL 環境的數據,讓我們可以在模擬的環境中,測試 RL 演算法。
程式碼中的 feature_fn 即是演算法中的  。
。
import gymnasium as gym
import numpy as np
class GradientMonteCarlo:
def __init__(self, feature_fn, alpha=0.1, gamma=1.0):
self.alpha = alpha
self.gamma = gamma
self.feature_fn = feature_fn
self.W = np.zeros(feature_fn.d, dtype=float)
def vhat(self, s: int) -> float:
x = self.feature_fn(s)
return float(self.W @ x)
def update(self, states: list[int], rewards: list[float]) -> None:
G = 0.0
for t in reversed(range(len(rewards))):
G = rewards[t] + self.gamma * G
s = states[t]
x = self.feature_fn(s)
v = self.vhat(s)
self.W = self.W + self.alpha * (G - v) * x
def run(self, env: gym.Env, policy, n_episodes=3000, max_steps=10_000) -> np.ndarray:
start_values = []
for i_episode in range(1, n_episodes + 1):
print(f"\rEpisode: {i_episode}/{n_episodes}", end="", flush=True)
s, _ = env.reset()
terminated = False
truncated = False
steps = 0
states = []
rewards = []
start_values.append(self.vhat(s))
while not terminated and not truncated and steps < max_steps:
states.append(s)
a = policy(s)
s_prime, r, terminated, truncated, _ = env.step(a)
rewards.append(r)
s = s_prime
steps += 1
self.update(states, rewards)
print()
return np.array(start_values)Semi-Gradient TD(0) 實作
在以下的程式碼,我們忠實地實作 Semi-Gradient TD(0) 方法。
import gymnasium as gym
import numpy as np
class SemiGradientTD0:
def __init__(self, feature_fn, alpha=0.1, gamma=1.0):
self.alpha = alpha
self.gamma = gamma
self.feature_fn = feature_fn
self.W = np.zeros(feature_fn.d, dtype=float)
def vhat(self, s: int) -> float:
x = self.feature_fn(s)
return float(self.W @ x)
def update(self, s: int, r: float, s_prime: int, terminated: bool) -> None:
v = self.vhat(s)
v_prime = self.vhat(s_prime) if not terminated else 0.0
delta = r + self.gamma * v_prime - v
x = self.feature_fn(s)
self.W = self.W + self.alpha * delta * x
def run(self, env: gym.Env, policy, n_episodes=3000, max_steps=10_000) -> np.ndarray:
start_values = []
for i_episode in range(1, n_episodes + 1):
print(f"\rEpisode: {i_episode}/{n_episodes}", end="", flush=True)
s, _ = env.reset()
terminated = False
truncated = False
steps = 0
start_values.append(self.vhat(s))
while not terminated and not truncated and steps < max_steps:
a = policy(s)
s_prime, r, terminated, truncated, _ = env.step(a)
self.update(s, r, s_prime, terminated)
s = s_prime
steps += 1
print()
return np.array(start_values)Cliff Walking
Cliff Walking 涉及在一個網格世界(grid world)中,從起始位置移動到目標位置,同時避免掉落懸崖,如下圖。

Cliff Walking 問題中每個 state 就是玩家的目前的 position。因此共有 36 個 states,分別是上面三排加上左下的格子, 。 目前的 position 由以下公式算出:
。 目前的 position 由以下公式算出:

有四個 actions,分別是:
- 0:Move up
- 1:Move right
- 2:Move down
- 3:Move left
每一步皆給予 −1 reward。但若玩家踏入懸崖(cliff),則會受到 −100 reward。
我們將用 state aggregation 將每 col_bin 個 states 合併成一個 state。
import numpy as np
class StateAggregationFeatures:
def __init__(self, n_rows=4, n_cols=12, col_bin=2):
self.n_rows = n_rows
self.n_cols = n_cols
self.col_bin = col_bin
self.n_col_bins = n_cols // col_bin
self.d = n_rows * self.n_col_bins
def __call__(self, s: int) -> np.ndarray:
row, col = divmod(s, self.n_cols)
col_group = col // self.col_bin
idx = row * self.n_col_bins + col_group
x = np.zeros(self.d, dtype=float)
x[idx] = 1.0
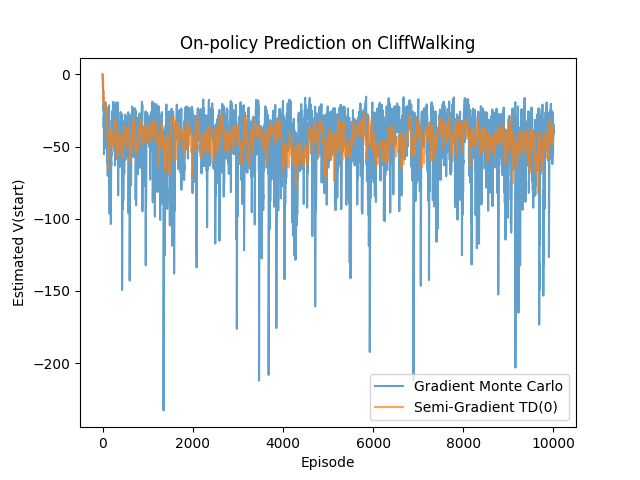
return x我們在以下程式碼中,訓練了 Gradient MC 和 Semi-Gradient TD(0)。
import gymnasium as gym
import numpy as np
from gradient_monte_carlo import GradientMonteCarlo
from semi_gradient_td0 import SemiGradientTD0
from state_aggregation_features import StateAggregationFeatures
UP, RIGHT, DOWN, LEFT = 0, 1, 2, 3
def epsilon_soft_policy(s: int, epsilon: float) -> int:
if np.random.random() < epsilon:
return np.random.randint(4)
else:
row, col = divmod(s, 12)
if row == 3 and col < 11:
return UP
if col < 11:
return RIGHT
if row < 3:
return DOWN
return RIGHT
if __name__ == "__main__":
env = gym.make("CliffWalking-v1")
features = StateAggregationFeatures(n_rows=4, n_cols=12, col_bin=2)
policy = lambda s: epsilon_soft_policy(s, epsilon=0.1)
print("Start Gradient Monte Carlo")
gradient_monte_carlo = GradientMonteCarlo(features)
values1 = gradient_monte_carlo.run(env, policy, n_episodes=10000, max_steps=100)
print("Start Semi-Gradient TD(0)")
semi_gradient_td0 = SemiGradientTD0(features)
values2 = semi_gradient_td0.run(env, policy, n_episodes=10000, max_steps=100)
plt.plot(values1, label="Gradient Monte Carlo", alpha=0.7)
plt.plot(values2, label="Semi-Gradient TD(0)", alpha=0.7)
plt.xlabel("Episode")
plt.ylabel("Estimated V(start)")
plt.legend()
plt.title("On-policy Prediction on CliffWalking")
plt.show()在相同的 on-policy 設定與相同的特徵表示下,Gradient MC 與 Semi-Gradient TD(0) 會展現出截然不同的學習行為。Gradient MC 由於以完整的 return 作為學習訊號,其更新方向對 MSVE 而言是無偏的。然而,MC return 所伴隨的高變異性,往往使得學習過程不穩定,收斂速度也相對緩慢。
相較之下,Semi-Gradient TD(0) 透過 bootstrapping 的方式引入系統性的偏差,不再直接最小化 MSVE,但作為交換,其估計變異性大幅降低,並在學習初期展現出更快且更平穩的收斂行為。這樣的差異,具體呈現了強化學習中典型的 bias–variance trade-off,也清楚說明了為何在多數實務應用中,TD 方法往往比 Gradient MC 更具吸引力。
結語
本文章中,我們從一個清楚但不可直接實作的最小化 MSVE 日標出發,依序檢視了 Gradient MC 與 Semi-Gradient TD(0) 這兩條不同的學習路徑。Gradient MC 提供了一個數學上乾淨、直接對應學習目標的基準,但其高變異性與非線上特性,使其難以應用於實際問題。Semi-Gradient TD(0) 則透過 bootstrapping 引入偏差,換得即時更新與較低變異性,成為實務上更可行的選擇。
在引入 linear function approximation 後,TD 的學習行為得以被明確刻畫為一個 fixed point 問題,並顯示其實際收斂到的,並非 MSVE 的最小解,而是一個在特徵空間中滿足 Bellman 一致性的解。這個結果不僅解釋了 TD 方法為何在 on-policy 與線性設定下具有良好的收斂性,也同時揭示了其理論上的侷限。
參考
- Adam White and Martha White. Reinforcement Learning Specialization. University of Alberta and Coursera.
- Richard S. Sutton and Andrew G. Barto. 2020. Reinforcement Learning: An Introduction, 2nd. The MIT Press.









