
多元分類神經網路(multiple classification neural network)可以分類多於一種類別。相較於二元分類(binary classification),在實務上是比較常被使用的。本文章將詳細介紹 multiple classification neural network 的理論。
Table of Contents
神經網路(Neural Network)
在本文章開始之前,讀者必須要了解 neural network 和 binary classification。本文章中許多的觀念都與 binary classification 雷同。我們不會在本文章中重複這些雷同的部分。因此,不論讀者是否了解 binary classification,建立先閱讀以下文章。

Softmax 函數
Softmax 函數
相對於 binary classification,multiple classification 使用 softmax 函數作為 output layer 的 activation function。
Softmax 函數定義如下。每一個  都大於零,並且都除以總和。因此
都大於零,並且都除以總和。因此  會是一個總和為 1 的機率分佈。
會是一個總和為 1 的機率分佈。

以下程式碼實作了 softmax 函數。
def softmax(Z):
"""
Implements the softmax activation.
Parameters
----------
Z: (ndarray of any shape) - input to the activation function
Returns
-------
A: (ndarray of same shape as Z) - output of the activation function
"""
# Subtracting the maximum value in each column for numerical stability to avoid overflow
Z_stable = Z - np.max(Z, axis=0, keepdims=True)
exp_Z = np.exp(Z_stable)
A = exp_Z / np.sum(exp_Z, axis=0, keepdims=True)
return ASoftmax 函數的導數
Softmax 函數的導數求解有點複雜。首先,softmax 函數的輸出的第 k 項如下。

 對
對 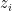 做微分,如下。
做微分,如下。

首先,我們先考慮  。此時,有兩種情況。
。此時,有兩種情況。
- 當
 ,則 。
,則 。 - 當 ,則 。
 。
。 。
。我們可以用 kronecker delta 將這兩種情況合併。

現在來處理  。
。

將以上的兩個部分代入回去,則我們可以得出以下。

化簡之後,最後 對 做微分如下。

有 K 項。每一項都要分別對  做微分。因此,softmax 的導數是一個
做微分。因此,softmax 的導數是一個  的 jacobian matrix,如下。
的 jacobian matrix,如下。

而當  或
或  時,
時, 會有不同的值。因為
會有不同的值。因為 J 是一個 的矩陣,因此 會是對角線上的項。

以下程式碼中,輸入值 z 是 softmax 函數的輸出值。softmax_jacobian() 實作了 softmax 函數的導數,而其導數會是一個 jacobian matrix。
def softmax_jacobian(z):
"""
Computes the Jacobian matrix for the softmax function.
Parameters
----------
Z: (ndarray (K,1)) - the input to the softmax function
Returns
-------
dZ: (ndarray (K,K)) - the Jacobian matrix
"""
z_stable = z - np.max(z, axis=0, keepdims=True)
exp_Z = np.exp(z_stable)
g = exp_z / np.sum(exp_z, axis=0, keepdims=True)
return np.diag(g) - np.outer(g, g)多元神經網路(Multiple Classification Neural Network)
下圖是一個 multiple classification 的 neural network。與 binary classification 相比,它的 output layer 裡的 activation function 是 softmax  。
。

梯度下降(Gradient Descent)
Multiple classification neural network 的 gradient descent 如下。由於每一層都有對應的參數 W 和 b,因此我們必須要計算 J 對每一層 W 和 b 的偏導數。
![\displaystyle L:\text{number of layers} \\\\ K:\text{number of classes} \\\\ m:\text{number of examples} \\\\ \text{Parameters}: W^{[\ell]},b^{[\ell]},\ell=1,...,L \\\\ \text{Loss function}: J(W,b)=-\frac{1}{m}\sum_{i=1}^m\sum_{k=1}^{K} Y_{k}^{(i)}\log A_{k}^{[L](i)} \\\\ \text{repeat until convergence \{} \\\\ \hphantom{xxxx}\text{Compute predict }(\hat{y}^{(i)},i=1,...,m) \\\\ \hphantom{xxxx}W^{[\ell]}:=W^{[\ell]}-\frac{\partial J}{\partial W^{[\ell]}}, \ell=1,...,L \\\\ \hphantom{xxxx}b^{[\ell]}:=b^{[\ell]}-\frac{\partial J}{\partial b^{[\ell]}}, \ell=1,...,L \\\\ \text{\}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+L%3A%5Ctext%7Bnumber+of+layers%7D+%5C%5C%5C%5C+K%3A%5Ctext%7Bnumber+of+classes%7D+%5C%5C%5C%5C+m%3A%5Ctext%7Bnumber+of+examples%7D+%5C%5C%5C%5C+%5Ctext%7BParameters%7D%3A+W%5E%7B%5B%5Cell%5D%7D%2Cb%5E%7B%5B%5Cell%5D%7D%2C%5Cell%3D1%2C...%2CL+%5C%5C%5C%5C+%5Ctext%7BLoss+function%7D%3A+J%28W%2Cb%29%3D-%5Cfrac%7B1%7D%7Bm%7D%5Csum_%7Bi%3D1%7D%5Em%5Csum_%7Bk%3D1%7D%5E%7BK%7D+Y_%7Bk%7D%5E%7B%28i%29%7D%5Clog+A_%7Bk%7D%5E%7B%5BL%5D%28i%29%7D+%5C%5C%5C%5C+%5Ctext%7Brepeat+until+convergence+%5C%7B%7D+%5C%5C%5C%5C+%5Chphantom%7Bxxxx%7D%5Ctext%7BCompute+predict+%7D%28%5Chat%7By%7D%5E%7B%28i%29%7D%2Ci%3D1%2C...%2Cm%29+%5C%5C%5C%5C+%5Chphantom%7Bxxxx%7DW%5E%7B%5B%5Cell%5D%7D%3A%3DW%5E%7B%5B%5Cell%5D%7D-%5Cfrac%7B%5Cpartial+J%7D%7B%5Cpartial+W%5E%7B%5B%5Cell%5D%7D%7D%2C+%5Cell%3D1%2C...%2CL+%5C%5C%5C%5C+%5Chphantom%7Bxxxx%7Db%5E%7B%5B%5Cell%5D%7D%3A%3Db%5E%7B%5B%5Cell%5D%7D-%5Cfrac%7B%5Cpartial+J%7D%7B%5Cpartial+b%5E%7B%5B%5Cell%5D%7D%7D%2C+%5Cell%3D1%2C...%2CL+%5C%5C%5C%5C+%5Ctext%7B%5C%7D%7D+&bg=ffffff&fg=000&s=1&c=20201002)
損失函式(Loss Function)
在 multiple classification 的 neural network 裡,output layer 的 activation function 是 softmax function。因此,我們使用 cross-entropy loss 作為它的 loss function。
} \\\\ L:\text{number of layers} \\\\ K:\text{number of classes} \\\\ m:\text{number of examples} \\\\](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+J%28W%2Cb%29%3D-%5Cfrac%7B1%7D%7Bm%7D%5Csum_%7Bi%3D1%7D%5Em%5Csum_%7Bk%3D1%7D%5E%7BK%7D+Y_%7Bk%7D%5E%7B%28i%29%7D%5Clog+A_%7Bk%7D%5E%7B%5BL%5D%28i%29%7D+%5C%5C%5C%5C+L%3A%5Ctext%7Bnumber+of+layers%7D+%5C%5C%5C%5C+K%3A%5Ctext%7Bnumber+of+classes%7D+%5C%5C%5C%5C+m%3A%5Ctext%7Bnumber+of+examples%7D+%5C%5C%5C%5C+&bg=ffffff&fg=000&s=1&c=20201002)
以下程式碼實作了 loss function。
def compute_cost(AL, Y):
"""
Computes the cross-entropy cost.
Parameters
----------
AL: (ndarray (output size, number of examples)) - probability vector corresponding to the label predictions
Y: (ndarray (output size, number of examples)) - true label vector
Returns
-------
cost: (float) - the cross-entropy cost
"""
m = Y.shape[1]
cost = -(1 / m) * np.sum(Y * np.log(AL))
return cost前向傳播(Forward Propagation)
在前向傳播(forward propagation)中,activation functions 要將 Z 回傳給呼叫者,而呼叫者會將它存入 caches 中。這些 caches 會在 backpropagation 中被使用。
以下的程式碼時實作了 softmax activation function。
def softmax(Z):
"""
Implements the softmax activation.
Parameters
----------
Z: (ndarray of any shape) - input to the activation function
Returns
-------
A: (ndarray of same shape as Z) - output of the activation function
cache: (ndarray) - returning Z for backpropagation
"""
# Subtracting the maximum value in each column for numerical stability to avoid overflow
Z_stable = Z - np.max(Z, axis=0, keepdims=True)
exp_Z = np.exp(Z_stable)
A = exp_Z / np.sum(exp_Z, axis=0, keepdims=True)
cache = Z
return A, cache反向傳播(Backpropagation or Backward Propagation)
反向傳播(backpropagation)其實就是微分的連鎖率(chain rule)。

在 binary classification neural network 中,我們提及到如何求取各參數的導數。在 multiple classification neural network 中,我們也是要求取各參數的導數。不同的是,在這邊我們使用的 loss function 和 output layer 裡的 activation function 是不相同的。
首先,我們先計算 ![\frac{\partial J}{\partial A^{[L]}}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cpartial+J%7D%7B%5Cpartial+A%5E%7B%5BL%5D%7D%7D&bg=ffffff&fg=000&s=0&c=20201002) 。
。
![\frac{\partial J}{\partial A^{[L]}}=-\frac{1}{m}\frac{Y}{A^{[L]}}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cpartial+J%7D%7B%5Cpartial+A%5E%7B%5BL%5D%7D%7D%3D-%5Cfrac%7B1%7D%7Bm%7D%5Cfrac%7BY%7D%7BA%5E%7B%5BL%5D%7D%7D+&bg=ffffff&fg=000&s=1&c=20201002)
對每一個 example 計算 }}{\partial Z^{[L](i)}}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cpartial+A%5E%7B%5BL%5D%28i%29%7D%7D%7B%5Cpartial+Z%5E%7B%5BL%5D%28i%29%7D%7D&bg=ffffff&fg=000&s=0&c=20201002) 。這邊要對每一個 example 分開計算是因為它會是一個 jacobian matrix。
。這邊要對每一個 example 分開計算是因為它會是一個 jacobian matrix。
}}{\partial Z_{k}^{[L](i)}}=A_{k}^{[L](i)}[\delta_{kj}-A_{j}^{[L](i)}] \\\\ \frac{\partial A^{[L](i)}}{\partial Z^{[L](i)}} \text{ is a K } \times \text{K jacobian matrix}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cpartial+A_%7Bk%7D%5E%7B%5BL%5D%28i%29%7D%7D%7B%5Cpartial+Z_%7Bk%7D%5E%7B%5BL%5D%28i%29%7D%7D%3DA_%7Bk%7D%5E%7B%5BL%5D%28i%29%7D%5B%5Cdelta_%7Bkj%7D-A_%7Bj%7D%5E%7B%5BL%5D%28i%29%7D%5D+%5C%5C%5C%5C+%5Cfrac%7B%5Cpartial+A%5E%7B%5BL%5D%28i%29%7D%7D%7B%5Cpartial+Z%5E%7B%5BL%5D%28i%29%7D%7D+%5Ctext%7B+is+a+K+%7D+%5Ctimes+%5Ctext%7BK+jacobian+matrix%7D+&bg=ffffff&fg=000&s=1&c=20201002)
對每一個 example 計算 }}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cpartial+J%7D%7B%5Cpartial+Z%5E%7B%5BL%5D%28i%29%7D%7D&bg=ffffff&fg=000&s=0&c=20201002) 後,再將它們合併起來。
後,再將它們合併起來。
![\frac{\partial J}{\partial Z^{[L]}}=\begin{bmatrix} \vdots & \cdots & \vdots \\ \frac{\partial A^{[L](1)}}{\partial Z^{[L](1)}}\frac{\partial J^{(1)}}{\partial A^{[L](1)}} & \cdots & \frac{\partial A^{[L](m)}}{\partial Z^{[L](m)}}\frac{\partial J^{(m)}}{\partial A^{[L](m)}} \\ \vdots & \cdots & \vdots \end{bmatrix}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cpartial+J%7D%7B%5Cpartial+Z%5E%7B%5BL%5D%7D%7D%3D%5Cbegin%7Bbmatrix%7D+%5Cvdots+%26+%5Ccdots+%26+%5Cvdots+%5C%5C+%5Cfrac%7B%5Cpartial+A%5E%7B%5BL%5D%281%29%7D%7D%7B%5Cpartial+Z%5E%7B%5BL%5D%281%29%7D%7D%5Cfrac%7B%5Cpartial+J%5E%7B%281%29%7D%7D%7B%5Cpartial+A%5E%7B%5BL%5D%281%29%7D%7D+%26+%5Ccdots+%26+%5Cfrac%7B%5Cpartial+A%5E%7B%5BL%5D%28m%29%7D%7D%7B%5Cpartial+Z%5E%7B%5BL%5D%28m%29%7D%7D%5Cfrac%7B%5Cpartial+J%5E%7B%28m%29%7D%7D%7B%5Cpartial+A%5E%7B%5BL%5D%28m%29%7D%7D+%5C%5C+%5Cvdots+%26+%5Ccdots+%26+%5Cvdots+%5Cend%7Bbmatrix%7D+&bg=ffffff&fg=000&s=1&c=20201002)
其他參數的偏導數計算,請參考 binary classification neural network。
以下程式碼實作 softmax activation function 的偏導數。
def softmax_backward(dA, cache):
"""
Implements the backward propagation for a single softmax unit.
Parameters
----------
dA: (ndarray of any shape) - post-activation gradient
cache: (ndarray) - Z from the forward propagation
Returns
-------
dZ: (ndarray of the same shape as A) - gradient of the cost with respect to Z
"""
def softmax_jacobian(Z):
Z_stable = Z - np.max(Z, axis=0, keepdims=True)
exp_Z = np.exp(Z_stable)
g = exp_Z / np.sum(exp_Z, axis=0, keepdims=True)
return np.diag(g) - np.outer(g, g)
Z = cache
m = Z.shape[1]
dZ = np.zeros_like(Z)
for k in range(m):
dZ[:, k] = softmax_jacobian(Z[:, k]) @ dA[:, k]
return dZ最後,以下程式碼中的 model_backward() 實作了整個 backpropagation。
def model_backward(AL, Y, caches, activation_functions):
"""
Implements the backward propagation for the entire network.
Parameters
----------
AL: (ndarray (output size, number of examples)) - the output of the last layer
Y: (ndarray (output size, number of examples)) - true labels
caches: (list of tuples) - containing linear_cache (A_prev, W, b) and activation_cache (Z) for each layer
activation_functions: (list) - the activation function for each layer. The first element is unused.
Returns
-------
gradients: (dict) with keys where 0 <= l <= len(activation_functions) - 1:
dA{l-1}: (ndarray (size of previous layer, number of examples)) - gradient of the cost with respect to the activation for previous layer l - 1
dWl: (ndarray (size of current layer, size of previous layer)) - gradient of the cost with respect to W for layer l
dbl: (ndarray (size of current layer, 1)) - gradient of the cost with respect to b for layer l
"""
gradients = {}
L = len(activation_functions)
m = AL.shape[1]
dAL = -(1 / m) * (Y / AL)
dA_prev = dAL
for l in reversed(range(1, L)):
current_cache = caches[l - 1]
dA_prev, dW, db = linear_activation_backward(dA_prev, current_cache, activation_functions[l])
gradients[f'dA{l - 1}'] = dA_prev
gradients[f'dW{l}'] = dW
gradients[f'db{l}'] = db
return gradients整合全部
以下程式碼中的 nn_model() 實作了整個模型。它先執行 forward propagation,然後執行 backpropagation,最後更新參數。
def nn_model(X, Y, init_parameters, layer_activation_functions, learning_rate, num_iterations):
"""
Implements a neural network.
Parameters
----------
X: (ndarray (input size, number of examples)) - input data
Y: (ndarray (output size, number of examples)) - true labels
init_parameters: (dict) - the initial parameters for the network
layer_activation_functions: (list) - the activation function for each layer. The first element is unused.
learning_rate: (float) - the learning rate
num_iterations: (int) - the number of iterations
Returns
-------
parameters: (dict) - the learned parameters
costs: (list) - the costs at every 100th iteration
"""
costs = []
parameters = init_parameters.copy()
for i in range(num_iterations):
AL, caches = model_forward(X, parameters, layer_activation_functions)
cost = compute_cost(AL, Y)
gradients = model_backward(AL, Y, caches, layer_activation_functions)
parameters = update_parameters(parameters, gradients, learning_rate)
if i % 100 == 0 or i == num_iterations:
costs.append(cost)
return parameters, costs當訓練好參數後,我們可以用以下的 nn_model_predict() 來做預測。
def nn_model_predict(X, parameters, activation_functions):
"""
Predicts the output of the neural network.
Parameters
----------
X: (ndarray (input size, number of examples)) - input data
parameters: (dict) - the learned parameters
activation_functions: (list) - the activation function for each layer. The first element is unused.
Returns
-------
predictions: (ndarray (number of classes, number of examples)) - the predicted labels
"""
probabilities, _ = model_forward(X, parameters, activation_functions)
pred = np.argmax(probabilities, axis=0)
predictions = np.zeros_like(probabilities)
for i in range(predictions.shape[1]):
predictions[pred[i], i] = 1
return predictions範例
我們將藉由一個範例來展示如何使用我們的模型。首先,我們先將訓練資料 x_orig 和 y 載入。x_orig 是一個包含 100 張圖片的陣列。每一張圖片的大小是 64 x 64,而且有三個 channels。y 是一個包含 0 或 1 的陣列,1 表示圖片裡是貓,0 表示不是貓。
x_orig, y_orig = load_data()
print(f'x_orig shape: {x_orig.shape}')
print(f'y_orig shape: {y_orig.shape}')
# Output
x_orig shape: ndarray(100, 64, 64, 3)
y_orig shape: ndarray(1, 100)之前我們有列出 X 的維度是 (nh, m),所以每一張圖片是一個行向量。以下我們將 x_orig 的維度,並將數值 0 至 255 轉換成 0 至 1 的值。將 y_orig 轉化成 one hot encoding。
x_flatten = x_orig.reshape(x_orig.shape[0], -1).T
x = train_x_flatten / 255.
y = np.zeros((2, y_orig.shape[1]))
y[0, y_orig[0, :] == 0] = 1
y[1, y_orig[0, :] == 1] = 1
print("x shape: " + str(x.shape))
print("y shape: " + str(y.shape))
# Output
x shape: ndarray(1228, 100)
y shape: ndarray(2, 200)首先,我們要先決定模型的層數,以及每一層 neurons 個數。以下我們設定模型有一個 input layer、hidden layer 裡有三層、以及一個 output layer。我們還要決定每一層的 activation function,其中 layer_activation_functions[0] 對應 input layer,所以不會被使用到。
這些決定好後,我們就可以初始化所有的參數 W 和 b,然後呼叫 nn_model() 來訓練模型。最後,取得訓練好的參數。
layer_dims = [12288, 20, 7, 10, 1] init_parameters = initialize_parameters(layer_dims) layer_activation_functions = ['none', 'relu', 'relu', 'relu', 'softmax'] learning_rate = 0.0075 parameters, costs = nn_model(x, y, init_parameters, layer_activation_functions, learning_rate, 3000)
有了訓練好的參數後,我們就可以用來預測其他的圖片。
x_new_orig = load_new_data() x_new_flatten = x_new_orig.reshape(x_new_orig.shape[0], -1).T x_new = x_new_flatten / 255. y_new = nn_model_predict(x_new, parameters, layer_activation_functions)
結語
求取 softmax 函數的偏導數是蠻複雜的,所幸現在我們不再需要自己實作這部分,而是使用像 PyTorch 和 TensorFlow 這類的函式庫來實作 neural network。不過了解它內部的細節,讓我們可以更加地了解它。
參考
- Andrew Ng, Deep Learning Specialization, Coursera.
- 西内啓,機器學習的數學基礎 : AI、深度學習打底必讀,旗標。









