
在動態規劃(Dynamic Programming, DP)中,完整的 environment model 是進行精確計算的前提,但這樣的假設在多數真實問題中並不成立。蒙地卡羅方法(Monte Carlo Methods, MC)選擇放棄對 model 的依賴,轉而直接從與 environment 互動所產生的完整經驗中進行學習。透過對 episode 回報的取樣與平均,MC 建立了一條從實際經驗出發估計 value function 的路徑。
Table of Contents
蒙地卡羅(Monte Carlo, MC)
動態規劃(Dynamic Programming, DP)需要完整的 environment model。在真實的環境中,這幾乎不可能。蒙地卡羅方法(Monte Carlo Methods, MC)則是一類不依賴 environment model 的方法,而是透過與 environment 實際互動所產生的完整 episode,直接以 return 樣本來估計 value function,因此不需要 model。換言之,MC 是 model-free 方法。
為了能夠明確定義 return,我們所介紹的基於 episodic task 的 MC。也就是,假設經驗被分為多個 episodes,且所有 episodes 都會終止。因此 MC 對 episodes 採樣,然後平均這些樣本來估計 value-function,因此它是 non-bootstrapping 方法。
On-Policy 蒙地卡羅(On-Policy Monte Carlo)
On-policy 是指,在 MC 中,用來產生資料的 policy 和正在被評估與改善的 policy 是同一個 policy。換言之,行為策略(behavior policy) 和目標策略(target policy)
和目標策略(target policy) 是同一個。
是同一個。
On-Policy Monte Carlo 預測(On-Policy Monte Carlo Prediction)
某一 state 的 value 是,從該 state 出發所能獲得的 expected return,也就是未來折扣後累積 reward 的期望值。
![\displaystyle v_\pi(s) \doteq \mathbb{E}_\pi \left[ G_t \mid S_t=s \right] \\\\ G_t = \sum_{k=0}^{T-t-1} \gamma^k R_{t+k+1}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+v_%5Cpi%28s%29+%5Cdoteq+%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+G_t+%5Cmid+S_t%3Ds+%5Cright%5D+%5C%5C%5C%5C+G_t+%3D+%5Csum_%7Bk%3D0%7D%5E%7BT-t-1%7D+%5Cgamma%5Ek+R_%7Bt%2Bk%2B1%7D+&bg=ffffff&fg=000&s=1&c=20201002)
既然 value 本質上是 expected return,那麼便可以透過實際觀察到的 return 取樣並加以平均來估計。隨著觀察到的 return 次數增加,這個平均值應當會收斂到其期望值。這個想法構成了所有 Monte Carlo 方法的基礎。

我們將介紹兩種 MC on-policy prediction 方法。它們的差異主要在於採樣方法的不同,但兩者都會收斂到  。
。
首次訪問蒙地卡羅預測(First-Visit Monte Carlo Prediction)
首次訪問蒙地卡羅預測(First-Visit MC Prediction)是,在每一個 episode 中,一個 state 只有第一次出現時才更新。在每個迴圈中的一開始,它會與環境做 interaction 來產生一個 episode。再來就開始對這個 episode 做採樣。

每次訪問蒙地卡羅預測(Every-Visit Monte Carlo Prediction)
每次訪問蒙地卡羅預測(Every-Visit MC Prediction)是,只要 state 出現就更新,不管是不是第一次。Every-visit MC prediction 演算法與 first-visit MC prediction 幾乎一樣,差別在於,在採樣時,不會檢查 “Unless  appears in
appears in  “。
“。
On-Policy Monte Carlo 控制(On-Policy Monte Carlo Control)
DP 可以用  來做 control,是因為它有 model
來做 control,是因為它有 model  ,因此可以對 action 計算 expectation。
,因此可以對 action 計算 expectation。
但是 MC 是 model-free,因此沒有 transition dynamics ,所以無法對 action 計算 expectation。但是,與 environment 做 interaction 產生出來的經驗中,會有真正執行過的 action 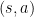 資料,而我們可以使用它們來計算 return。
資料,而我們可以使用它們來計算 return。
因此,在 MC 下,control 問題必須轉而學習 action-value function  ,以取代對 的直接操作。然後,對每個 state 用貪婪的方式,確定性地選擇最大動作值的 action。策略改善(policy improvement)可以透過將每一個
,以取代對 的直接操作。然後,對每個 state 用貪婪的方式,確定性地選擇最大動作值的 action。策略改善(policy improvement)可以透過將每一個  建構為相對於
建構為相對於  的貪婪策略(greedy policy)來完成。此時,策略改善定理(policy improvement theorem)即可應用於
的貪婪策略(greedy policy)來完成。此時,策略改善定理(policy improvement theorem)即可應用於 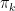 與 。
與 。

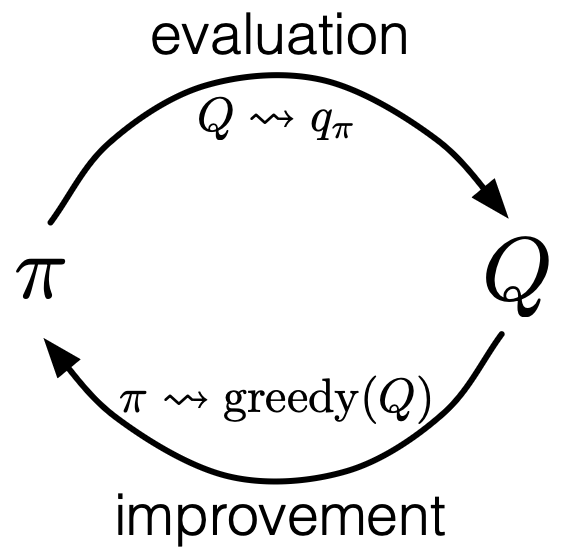
從 GPI 的角度來看,MC control 即是不斷以 MC 方法估計  ,並透過 policy improvement 將 policy 推向更佳解。
,並透過 policy improvement 將 policy 推向更佳解。
Monte Carlo with Exploring Starts, MCES
MC control 要學習的是  。但 MC 只能學到實際走過的 state-action 。因此,沒走過的 就永遠不會學到。
。但 MC 只能學到實際走過的 state-action 。因此,沒走過的 就永遠不會學到。

所以,Monte Carlo with Exploring Starts, MCES 是,每一個 state-action ,都有非零的機率作為某個 episode 的起始點,以保證所有 都能被無限次訪問到。
在產生 episode 之前,MCES 先隨機挑選一組 作為此 episode 的起點,再依據這個起點來產生此 episode。

On-Policy First-Visit Monte Carlo (ε-soft policies)
MCES 的 exploring starts 假設是不切實際的。在實務上,我們幾乎無法指定任意起始點。因此,我們需要一個不依賴起始點假設,但仍然能保證 exploring 的方法。
 -soft policy 是指,對於任一個 state s,其所有可能的 action a 皆具有非零的被選擇機率,因此不會因為 policy improvement 而永久被排除。
-soft policy 是指,對於任一個 state s,其所有可能的 action a 皆具有非零的被選擇機率,因此不會因為 policy improvement 而永久被排除。

在演算法中最下面,MCES 是使用確定性貪婪 policy 更新  ,因此,只有最大動作價值的 action
,因此,只有最大動作價值的 action  的機率被更新為 1,而其餘的 actions 的機率變為 0。然而,使用
的機率被更新為 1,而其餘的 actions 的機率變為 0。然而,使用  -soft policy 更新
-soft policy 更新  時,最大動作價值的 action 的機率被更新為
時,最大動作價值的 action 的機率被更新為  ,而其餘的 actions 的機率為
,而其餘的 actions 的機率為  。
。

Off-Policy 蒙地卡羅(Off-Policy Monte Carlo)
前述 on-policy 方法要求資料生成與學習 policy 一致;然而在實務中,這個假設往往難以滿足,因此需要引入 off-policy 的學習架構。
重要性抽樣(Importance Sampling)
在 off-policy learning 中,我們會遇到一個結構性的問題,就是資料是由 behavior policy 產生,但是我們想評估或學習的是 target policy 。
![\text{Sample}: x \sim b \\ \text{Estimate}: \mathbb{E}_\pi \left[ X \right]](https://s0.wp.com/latex.php?latex=%5Ctext%7BSample%7D%3A+x+%5Csim+b+%5C%5C+%5Ctext%7BEstimate%7D%3A+%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+X+%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)
然而,期望值是不能直接跨分佈使用。因此,我們需要使用重要性抽樣(importance sampling)來修正分佈不一致所造成的偏差。
Importance sampling 是一種在已知樣本來自另一個分佈的情況下,用來估計目標分佈期望值的通用技術。我們將 importance sampling 應用於 off-policy learning 中,做法是根據同一條軌跡(trajectory)在 target policy 與 behavior policy 下發生的相對機率,對 return 進行加權。這個相對機率的比值稱為重要性取樣比率(importance-sampling ratio) 。
。

以下的推導顯示如何 behavior policy 的期望值推導出 target policy 的期望值。
![\displaystyle \mathbb{E}_\pi \left[ X \right] \doteq \sum_{x \in X} x\pi(x) \\\\ \hphantom{\mathbb{E}_\pi \left[ X \right]} = \sum_{x \in X} x\pi(x) \frac{b(x)}{b(x)} \\\\ \hphantom{\mathbb{E}_\pi \left[ X \right]} = \sum_{x \in X} x \frac{\pi(x)}{b(x)} b(x) \\\\ \hphantom{\mathbb{E}_\pi \left[ X \right]} = \sum_{x \in X} x \rho(x) b(x) \\\\ \hphantom{\mathbb{E}_\pi \left[ X \right]} = \mathbb{E}_b \left[ X \rho(X) \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+X+%5Cright%5D+%5Cdoteq+%5Csum_%7Bx+%5Cin+X%7D+x%5Cpi%28x%29+%5C%5C%5C%5C+%5Chphantom%7B%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+X+%5Cright%5D%7D+%3D+%5Csum_%7Bx+%5Cin+X%7D+x%5Cpi%28x%29+%5Cfrac%7Bb%28x%29%7D%7Bb%28x%29%7D+%5C%5C%5C%5C+%5Chphantom%7B%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+X+%5Cright%5D%7D+%3D+%5Csum_%7Bx+%5Cin+X%7D+x+%5Cfrac%7B%5Cpi%28x%29%7D%7Bb%28x%29%7D+b%28x%29+%5C%5C%5C%5C+%5Chphantom%7B%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+X+%5Cright%5D%7D+%3D+%5Csum_%7Bx+%5Cin+X%7D+x+%5Crho%28x%29+b%28x%29+%5C%5C%5C%5C+%5Chphantom%7B%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+X+%5Cright%5D%7D+%3D+%5Cmathbb%7BE%7D_b+%5Cleft%5B+X+%5Crho%28X%29+%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)
接著,我們計算 ![\mathbb{E}_b \left[ X \rho(X) \right]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_b+%5Cleft%5B+X+%5Crho%28X%29+%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002) 的近似值:
的近似值:
![\displaystyle \mathbb{E} \left[ X \right] \approx \frac{1}{n} \sum_{i=1}^n x_i \\\\ \mathbb{E}_b \left[ X \rho(X) \right] \doteq \sum_{x \in X} x\rho(x)b(x) \\\\ \hphantom{\mathbb{E}_b \left[ X \rho(X) \right]} \approx \frac{1}{n} \sum_{i=1}^n x_i \rho_(x_i)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D+%5Cleft%5B+X+%5Cright%5D+%5Capprox+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5En+x_i+%5C%5C%5C%5C+%5Cmathbb%7BE%7D_b+%5Cleft%5B+X+%5Crho%28X%29+%5Cright%5D+%5Cdoteq+%5Csum_%7Bx+%5Cin+X%7D+x%5Crho%28x%29b%28x%29+%5C%5C%5C%5C+%5Chphantom%7B%5Cmathbb%7BE%7D_b+%5Cleft%5B+X+%5Crho%28X%29+%5Cright%5D%7D+%5Capprox+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5En+x_i+%5Crho_%28x_i%29+&bg=ffffff&fg=000&s=1&c=20201002)
最後,我們可以計算出 ![\mathbb{E}_\pi \left[ X \right]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+X+%5Cright%5D+&bg=ffffff&fg=000&s=0&c=20201002) 的近似值:
的近似值:
![\displaystyle \mathbb{E}_\pi \left[ X \right] \approx \frac{1}{n} \sum_{i=1}^n x_i \rho(x_i), \quad x_i \sim b](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+X+%5Cright%5D+%5Capprox+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5En+x_i+%5Crho%28x_i%29%2C+%5Cquad+x_i+%5Csim+b+&bg=ffffff&fg=000&s=1&c=20201002)
需要注意的是,importance sampling 雖然能校正分佈差異,但其變異數可能非常大,特別是在 trajectory 較長或兩個 policy 差異較大時。
Off-Policy Monte Carlo 預測(Off-Policy Monte Carlo Prediction)
Off-Policy Monte Carlo Prediction
給定起始 state ,其後續的 trajectory 為  。在任意 policy 下,該 trajectory 發生的機率可寫為:
。在任意 policy 下,該 trajectory 發生的機率可寫為:

因此,對應於從 time step  到 episode 結束的 importance-sampling ratio
到 episode 結束的 importance-sampling ratio  定義為:
定義為:

在 behavior policy 下,所有的 return  所形成的期望值,對應的是
所形成的期望值,對應的是  :
:
![\mathbb{E}_b \left[ G_t \mid S_t=s \right]=v_b(s)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_b+%5Cleft%5B+G_t+%5Cmid+S_t%3Ds+%5Cright%5D%3Dv_b%28s%29+&bg=ffffff&fg=000&s=1&c=20201002)
然而,我們不能直接使用 behavior policy 所產生的 return 來估計  。透過 importance-sampling ratio ,可以將 轉換為在 target policy 下的無偏估計:
。透過 importance-sampling ratio ,可以將 轉換為在 target policy 下的無偏估計:
![\mathbb{E} \left[\rho_{t:T-1} G_t \mid S_t=s \right] = v_\pi(s)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D+%5Cleft%5B%5Crho_%7Bt%3AT-1%7D+G_t+%5Cmid+S_t%3Ds+%5Cright%5D+%3D+v_%5Cpi%28s%29+&bg=ffffff&fg=000&s=1&c=20201002)
Importance sampling ratio 可以以增量式(incremental)的方式計算:

其中  可視為對應於 return 的權重。假設我們觀察到一系列從同一個 state 開始的 return
可視為對應於 return 的權重。假設我們觀察到一系列從同一個 state 開始的 return  ,且每個 return 皆具有對應的權重
,且每個 return 皆具有對應的權重  ,則 state-value 的估計值可寫為加權平均:
,則 state-value 的估計值可寫為加權平均:

當我們取得一個新的 return  時,會對
時,會對 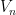 進行更新。為此,除了追蹤 外,還需同時維護權重的累積總和
進行更新。為此,除了追蹤 外,還需同時維護權重的累積總和  :
:

其對應的增量更新規則為:
![V_{n+1} \doteq V_n + \frac{W_n}{C_n} \left[ G_n - V_n \right], \quad n \ge 1](https://s0.wp.com/latex.php?latex=V_%7Bn%2B1%7D+%5Cdoteq+V_n+%2B+%5Cfrac%7BW_n%7D%7BC_n%7D+%5Cleft%5B+G_n+-+V_n+%5Cright%5D%2C+%5Cquad+n+%5Cge+1+&bg=ffffff&fg=000&s=1&c=20201002)
以上即為 off-policy MC prediction 演算法的推導與更新形式。

Off-Policy Monte Carlo 控制(Off-Policy Monte Carlo Control)
Off-Policy Monte Carlo Control
Off-policy MC control 的目標是學得:

而且,behavior policy 必須是 -soft policy;target policy 則是對  的 greedy policy,而 是對 的估計。
的 greedy policy,而 是對 的估計。

On-Policy Monte Carlo 範例
On-Policy First-Visit Monte Carlo Control(ε-soft policies)實作
在以下的程式碼,我們忠實地實作 MC 的 on-policy first-visit MC control(-soft policies)方法。
程式碼中的 env 是 Gymnasium 的 Env 物件。Gymnasium 的前身是 OpenAI Gym。它提供了眾多的 RL 環境的數據,讓我們可以在模擬的環境中,測試 RL 演算法。
Environment 中有 env.observation_space.n 個 states。因此,state 的編號就從整數 0 到 env.observation_space.n - 1。變數 Q 是一個浮點數的 2D-array,每一個 element 都是一對 state 和 action 的 action-value 的估計值。例如,Q[0][0] 是 state 0 的 action 0 的 action-value 估計值。
import gymnasium as gym
import numpy as np
class OnPolicyMonteCarlo:
def __init__(self, env: gym.Env, epsilon=0.1, gamma=1.0):
self.env = env
self.epsilon = epsilon
self.gamma = gamma
def _random_argmax(self, q_s: np.ndarray) -> int:
ties = np.flatnonzero(np.isclose(q_s, q_s.max()))
return np.random.choice(ties)
def _update_policy_for_state(self, pi: np.ndarray, Q: np.ndarray, s: int):
A = np.ones(self.env.action_space.n, dtype=float) * self.epsilon / self.env.action_space.n
A_start = self._random_argmax(Q[s])
A[A_start] += 1.0 - self.epsilon
pi[s] = A
def _update_policy_by_epsilon_greedy(self, pi: np.ndarray, Q: np.ndarray):
for s in range(self.env.observation_space.n):
A = np.ones(self.env.action_space.n, dtype=float) * self.epsilon / self.env.action_space.n
A_star = np.argmax(Q[s])
A[A_star] += 1.0 - self.epsilon
pi[s] = A
def _generate_episode(self, pi: np.ndarray) -> list[tuple[int, int, float]]:
episode = []
s, _ = self.env.reset()
while True:
a = np.random.choice(np.arange(self.env.action_space.n), p=pi[s])
s_prime, r, terminated, truncated, _ = self.env.step(a)
episode.append((s, a, r))
if terminated or truncated:
break
s = s_prime
return episode
def run_control(self, n_episodes=5000) -> tuple[np.ndarray, np.ndarray]:
Q = np.zeros((self.env.observation_space.n, self.env.action_space.n), dtype=float)
Returns_sum = np.zeros((self.env.observation_space.n, self.env.action_space.n), dtype=float)
Returns_count = np.zeros((self.env.observation_space.n, self.env.action_space.n), dtype=int)
pi = np.zeros((self.env.observation_space.n, self.env.action_space.n), dtype=float)
self._update_policy_by_epsilon_greedy(pi, Q)
for i_episode in range(1, n_episodes + 1):
print(f"\rEpisode: {i_episode}/{n_episodes}, generating a episode ...", end="", flush=True)
episode = self._generate_episode(pi)
print(f"\rEpisode: {i_episode}/{n_episodes}, episode length is {len(episode)})", end="", flush=True)
sa_first_visit = {}
for t, (s, a, _) in enumerate(episode):
if (s, a) not in sa_first_visit:
sa_first_visit[(s, a)] = t
G = 0.0
for t in range(len(episode) - 1, -1, -1):
s, a, r = episode[t]
G = self.gamma * G + r
if t == sa_first_visit[(s, a)]:
Returns_sum[s, a] += G
Returns_count[s, a] += 1
Q[s, a] = Returns_sum[s, a] / Returns_count[s, a]
self._update_policy_for_state(pi, Q, s)
print()
return pi, QCliff Walking
Cliff Walking 涉及在一個網格世界(grid world)中,從起始位置移動到目標位置,同時避免掉落懸崖,如下圖。

Cliff Walking 問題中每個 state 就是玩家的目前的 position。因此共有 36 個 states,分別是上面三排加上左下的格子, 。 目前的 position 由以下公式算出:
。 目前的 position 由以下公式算出:

有四個 actions,分別是:
- 0:Move up
- 1:Move right
- 2:Move down
- 3:Move left
每一步皆給予 −1 reward。但若玩家踏入懸崖(cliff),則會受到 −100 reward。
import numpy as np
from off_policy_mc import OffPolicyMonteCarlo
from on_policy_mc import OnPolicyMonteCarlo
GYM_ID = "CliffWalking-v1"
def play_game(policy, episodes=1):
visual_env = gym.make(GYM_ID, render_mode="human")
for episode in range(episodes):
state, _ = visual_env.reset()
terminated = False
truncated = False
total_reward = 0
step_count = 0
print(f"Episode {episode + 1} starts")
while not terminated and not truncated:
action = np.argmax(policy[state])
state, reward, terminated, truncated, _ = visual_env.step(action)
total_reward += reward
step_count += 1
time.sleep(0.3)
print(f"Episode {episode + 1} is finished: Total reward is {total_reward}, steps = {step_count}")
time.sleep(1)
visual_env.close()
if __name__ == "__main__":
env = gym.make(GYM_ID)
print(f"Gym environment: {GYM_ID}")
print("Start On-Policy First-Visit Monte Carlo (for epsilon-soft policies)")
on_policy_mc = OnPolicyMonteCarlo(env)
on_policy_pi, on_policy_Q = on_policy_mc.run_control(n_episodes=5000)
play_game(on_policy_pi)以下是上述程式的執行結果。可以觀察到,學到的 policy 通常會刻意遠離懸崖邊緣,選擇一條較為保守、但風險較低的路徑。即使在訓練後期,當 value function 已趨於穩定,agent 仍不傾向緊貼 cliff 前進。
這個現象並非實作問題,而是 on-policy MC control 的本質特性。由於 behavior policy 本身為 -soft,agent 在執行時始終存在採取非 greedy action 的機率。在靠近懸崖的狀態下,這樣的隨機偏移可能導致立即掉入 cliff 並承受巨大負回饋。因此,value estimation 自然地將探索風險一併納入考量。
換言之,On-policy MC Control 所學到的策略,並非在理想化執行下的最短路徑,而是在未來仍持續探索的前提下,expected return 最高的行為選擇。

Taxi
Taxi 問題是在一個 grid world 中移動,前往乘客所在的位置接送乘客,並將乘客送達四個指定地點之一,如下圖。
Taxi 問題中有 500 個 discrete states。每個 state 由以下公式算出:

Passenger 的 locations:
- 0:Red
- 1:Green
- 2:Yellow
- 3:Blue
- 4:In taxi
Destinations:
- 0:Red
- 1:Green
- 2:Yellow
- 3:Blue
有六個 actions,分別是:
- 0:Move south(down)
- 1:Move north(up)
- 2:Move east(right)
- 3:Move west(left)
- 4:Pickup passenger
- 5:Drop off passenger
每一步皆給予 −1 reward,除非觸發其他 reward。成功將乘客送達目的地可獲得 +20 reward。非法執行 pickup 或 drop-off 動作時,會受到 −10 reward。
import numpy as np
from off_policy_mc import OffPolicyMonteCarlo
from on_policy_mc import OnPolicyMonteCarlo
GYM_ID = "Taxi-v3"
def play_game(policy, episodes=1):
visual_env = gym.make(GYM_ID, render_mode="human")
for episode in range(episodes):
state, _ = visual_env.reset()
terminated = False
truncated = False
total_reward = 0
step_count = 0
print(f"Episode {episode + 1} starts")
while not terminated and not truncated:
action = np.argmax(policy[state])
state, reward, terminated, truncated, _ = visual_env.step(action)
total_reward += reward
step_count += 1
time.sleep(0.3)
print(f"Episode {episode + 1} is finished: Total reward is {total_reward}, steps = {step_count}")
time.sleep(1)
visual_env.close()
if __name__ == "__main__":
env = gym.make(GYM_ID)
print(f"Gym environment: {GYM_ID}")
print("Start On-Policy First-Visit Monte Carlo (for epsilon-soft policies)")
on_policy_mc = OnPolicyMonteCarlo(env)
on_policy_pi, on_policy_Q = on_policy_mc.run_control(n_episodes=5000)
play_game(on_policy_pi)以下是上面程式的執行結果。
Off-Policy Monte Carlo 範例
Off-Policy Monte Carlo Control 實作
在以下的程式碼,我們忠實地實作 MC 的 off-policy MC control 方法。
import gymnasium as gym
import numpy as np
class OffPolicyMonteCarlo:
def __init__(self, env: gym.Env, gamma=1.0, b_epsilon=0.1):
self.env = env
self.gamma = gamma
self.b_epsilon = b_epsilon
def _random_argmax(self, q_s: np.ndarray) -> int:
ties = np.flatnonzero(np.isclose(q_s, q_s.max()))
return np.random.choice(ties)
def _create_b(self, Q: np.ndarray, epsilon: float) -> np.ndarray:
pi = np.zeros((self.env.observation_space.n, self.env.action_space.n), dtype=float)
for s in range(self.env.observation_space.n):
A = np.ones(self.env.action_space.n, dtype=float) * epsilon / self.env.action_space.n
A_start = self._random_argmax(Q[s])
A[A_start] += 1.0 - epsilon
pi[s] = A
return pi
def _generate_episode(self, policy: np.ndarray) -> np.ndarray:
episode = []
s, _ = self.env.reset()
while True:
a = np.random.choice(np.arange(self.env.action_space.n), p=policy[s])
s_prime, r, terminated, truncated, _ = self.env.step(a)
episode.append((s, a, r))
if terminated or truncated:
break
s = s_prime
return episode
def _create_pi_by_Q(self, Q: np.ndarray) -> np.ndarray:
pi = np.zeros((self.env.observation_space.n, self.env.action_space.n), dtype=float)
for s in range(self.env.observation_space.n):
A_star = self._random_argmax(Q[s])
pi[s][A_star] = 1.0
return pi
def run_control(self, n_episodes=1000) -> tuple[np.ndarray, np.ndarray]:
Q = np.zeros((self.env.observation_space.n, self.env.action_space.n), dtype=float)
C = np.zeros((self.env.observation_space.n, self.env.action_space.n), dtype=float)
for i_episode in range(1, n_episodes + 1):
print(f"\rEpisode: {i_episode}/{n_episodes}, generating a episode ...", end="", flush=True)
b = self._create_b(Q, self.b_epsilon)
episode = self._generate_episode(b)
print(f"\rEpisode: {i_episode}/{n_episodes}, episode length is {len(episode)})", end="", flush=True)
G = 0.0
W = 1.0
for t in range(len(episode) - 1, -1, -1):
s, a, r = episode[t]
G = self.gamma * G + r
C[s, a] += W
Q[s, a] += (W / C[s, a]) * (G - Q[s, a])
if a not in np.flatnonzero(np.isclose(Q[s], Q[s].max())):
break
W *= 1.0 / b[s, a]
pi = self._create_pi_by_Q(Q)
print()
return pi, QCliff Walking
以下我們用 off-policy MC control 來解決 Cliff Walking 問題。
import time
import gymnasium as gym
import numpy as np
from off_policy_mc import OffPolicyMonteCarlo
from on_policy_mc import OnPolicyMonteCarlo
GYM_ID = "CliffWalking-v1"
def play_game(policy, episodes=1):
visual_env = gym.make(GYM_ID, render_mode="human")
for episode in range(episodes):
state, _ = visual_env.reset()
terminated = False
truncated = False
total_reward = 0
step_count = 0
print(f"Episode {episode + 1} starts")
while not terminated and not truncated:
action = np.argmax(policy[state])
state, reward, terminated, truncated, _ = visual_env.step(action)
total_reward += reward
step_count += 1
time.sleep(0.3)
print(f"Episode {episode + 1} is finished: Total reward is {total_reward}, steps = {step_count}")
time.sleep(1)
visual_env.close()
if __name__ == "__main__":
env = gym.make(GYM_ID)
print(f"Gym environment: {GYM_ID}")
print("Start Off-Policy Monte Carlo")
off_policy_mc = OffPolicyMonteCarlo(env)
off_policy_pi, off_policy_Q = off_policy_mc.run_control(n_episodes=5000)
play_game(off_policy_pi)
env.close()雖然我們未實際呈現 Off-policy MC control 的完整執行結果,但其預期學得的 policy 行為是明確的。在理論上,off-policy MC control 估計的是在完全依照 greedy target policy 執行時的 expected return,因此最終 policy 會傾向於選擇緊貼懸崖邊緣的最短路徑,這正是問題的最優解。
然而,由於學習過程中需透過 importance sampling 修正分佈差異,實際訓練時有效更新極為稀少,導致收斂速度非常緩慢。也因此,off-policy MC control 本身多半僅作為理論對照,而不適合直接用於實際訓練。
Taxi
以下我們用 off-policy MC control 來解決 Taxi 問題。
import time
import gymnasium as gym
import numpy as np
from off_policy_mc import OffPolicyMonteCarlo
from on_policy_mc import OnPolicyMonteCarlo
GYM_ID = "Taxi-v3"
def play_game(policy, episodes=1):
visual_env = gym.make(GYM_ID, render_mode="human")
for episode in range(episodes):
state, _ = visual_env.reset()
terminated = False
truncated = False
total_reward = 0
step_count = 0
print(f"Episode {episode + 1} starts")
while not terminated and not truncated:
action = np.argmax(policy[state])
state, reward, terminated, truncated, _ = visual_env.step(action)
total_reward += reward
step_count += 1
time.sleep(0.3)
print(f"Episode {episode + 1} is finished: Total reward is {total_reward}, steps = {step_count}")
time.sleep(1)
visual_env.close()
if __name__ == "__main__":
env = gym.make(GYM_ID)
print(f"Gym environment: {GYM_ID}")
print("Start Off-Policy Monte Carlo")
off_policy_mc = OffPolicyMonteCarlo(env)
off_policy_pi, off_policy_Q = off_policy_mc.run_control(n_episodes=5000)
play_game(off_policy_pi)
env.close()以下是上面程式的執行結果。
結語
MC 以從完整經驗中學習為核心,提供了一種不依賴 environment model 的價值估計與控制途徑。相較於 DP,MC 不進行 bootstrapping,而是直接以實際 return 作為學習訊號,這使其在概念上更為直觀,但也受限於 episodic 設定與資料效率。透過 exploring starts 或 $\varepsilon$-soft policy,MC control 得以在 model-free 的情況下實現 policy improvement;而在 off-policy 架構中,importance sampling 則成為連結不同行為分佈的關鍵工具。從更宏觀的角度來看,MC 方法不僅是強化學習早期的重要基石,也為後續的近代 control 演算法奠定了理解 return、取樣與 policy improvement 之間關係的基礎。
參考
- Adam White and Martha White. Reinforcement Learning Specialization. University of Alberta and Coursera.
- Richard S. Sutton and Andrew G. Barto. 2020. Reinforcement Learning: An Introduction, 2nd. The MIT Press.









