
馬可夫決策過程(Markov Decision Process, MDP)為強化學習(Reinforcement Learning, RL)中所有策略評估(policy evaluation)與策略改善(policy improvement)方法提供了嚴謹的數學框架。藉由 MDP,我們得以形式化地描述代理人(agent)與環境(environment)之間的互動,也能在回報(return)的觀點下定義策略的價值。
Table of Contents
馬可夫決策過程(Markov Decision Process, MDP)
馬可夫決策過程(Markov Decision Process, MDP)是在結果具有不確定性時,用於序列決策的模型。MDP 起源於 1950 年代的作業研究領域,此後在多個領域獲得重視。其名稱源於與馬可夫鏈(Markov chains)之間的關聯,而 Markov chains 是由俄國數學家 Andrey Markov 所提出。
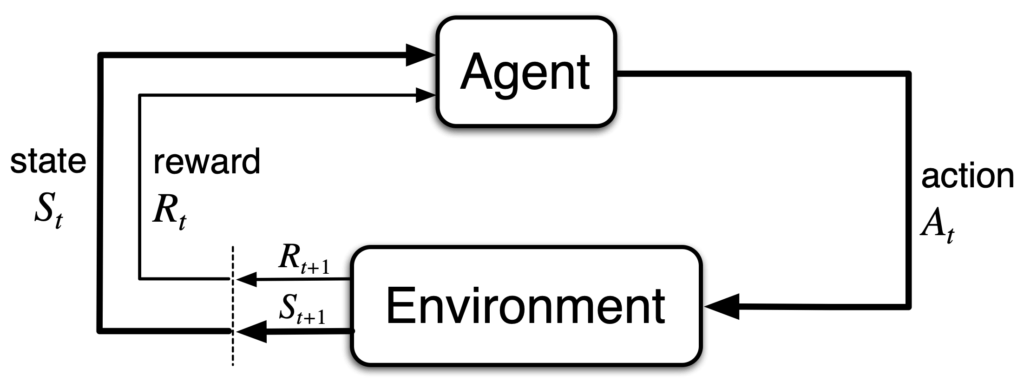
MDP 是強化學習(Reinforcement Learning, RL)的正式數學模型。它是從交互作用中學習以實現目標的一個簡單框架。這個交互作用(interactions)是指代理人(agent)與環境(environment)之間的交互作用,如下圖。
Agent 和 environment 在一系列的時步(time steps), ,進行 interaction。在每個 time step
,進行 interaction。在每個 time step  ,agent 會接收到來自環境的狀態(state),
,agent 會接收到來自環境的狀態(state), ,的一些表徵(representation)。在這基礎上,agent 會選擇一個動作(action),
,的一些表徵(representation)。在這基礎上,agent 會選擇一個動作(action), 。在下一個 time step
。在下一個 time step  ,agent 會從 environment 收到一個獎勵(reward),
,agent 會從 environment 收到一個獎勵(reward), ,並同時發現自己處在一個新的狀態
,並同時發現自己處在一個新的狀態  。
。
因此,MDP 和 agent 會一起產生一個軌跡(trajectory),如下。

完整的 MDP 由五個元素構成:

狀態空間(State Space)
狀態空間(State space)記作 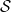 。在每個 time step ,agent 位於某個state 。當下的 state
。在每個 time step ,agent 位於某個state 。當下的 state  是 agent 在 time step 所能觀察的資訊,用來決定下一個 action
是 agent 在 time step 所能觀察的資訊,用來決定下一個 action 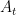 。因此,state 必須包括有關過去 agent 與 environment 互動的所有可能對未來有影響的資訊。若符合此條件,則表示該 state 具有馬可夫性質(Markov Property):
。因此,state 必須包括有關過去 agent 與 environment 互動的所有可能對未來有影響的資訊。若符合此條件,則表示該 state 具有馬可夫性質(Markov Property):

這也就是說,當 agent 在 state 時,它可以丟棄以前的 states 和 actions,( )。未來只取決於現在,不取決於過去。
)。未來只取決於現在,不取決於過去。
動作空間(Action Space)
動作空間(Action space)記作 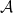 。每個 state
。每個 state  可選的動作集合記作
可選的動作集合記作  。
。
狀態轉移機率(State-Transition Probabilities)
在 state 下選擇 action  後,會有數個可轉移的 states,這會由狀態轉移機率(State-Transition Probabilities)
後,會有數個可轉移的 states,這會由狀態轉移機率(State-Transition Probabilities) 來決定下一個 state
來決定下一個 state  。
。
![\displaystyle p(s^\prime, r \mid s, a) \doteq \Pr\{S_t=s^\prime, R_t=r \mid S_{t-1}=s, A_{t-1}=a\} \\\\ \sum_{s^\prime \in \mathcal{S}} \sum_{r \in \mathcal{R}} p(s^\prime, r \mid s, a) = 1, \forall s \in \mathcal{S}, a \in \mathcal{A}(s) \\\\ p(s^\prime \mid s, a) \doteq \mathbb{E} \left[ R_t \mid S_{t-1}=s, A_{t-1}=a \right] = \sum_{r \in \mathcal{R}} p(s^\prime, r \mid s, a)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+p%28s%5E%5Cprime%2C+r+%5Cmid+s%2C+a%29+%5Cdoteq+%5CPr%5C%7BS_t%3Ds%5E%5Cprime%2C+R_t%3Dr+%5Cmid+S_%7Bt-1%7D%3Ds%2C+A_%7Bt-1%7D%3Da%5C%7D+%5C%5C%5C%5C+%5Csum_%7Bs%5E%5Cprime+%5Cin+%5Cmathcal%7BS%7D%7D+%5Csum_%7Br+%5Cin+%5Cmathcal%7BR%7D%7D+p%28s%5E%5Cprime%2C+r+%5Cmid+s%2C+a%29+%3D+1%2C+%5Cforall+s+%5Cin+%5Cmathcal%7BS%7D%2C+a+%5Cin+%5Cmathcal%7BA%7D%28s%29+%5C%5C%5C%5C+p%28s%5E%5Cprime+%5Cmid+s%2C+a%29+%5Cdoteq+%5Cmathbb%7BE%7D+%5Cleft%5B+R_t+%5Cmid+S_%7Bt-1%7D%3Ds%2C+A_%7Bt-1%7D%3Da+%5Cright%5D+%3D+%5Csum_%7Br+%5Cin+%5Cmathcal%7BR%7D%7D+p%28s%5E%5Cprime%2C+r+%5Cmid+s%2C+a%29+&bg=ffffff&fg=000&s=1&c=20201002)
獎勵(Reward)
獎勵(Reward)記作  。Reward 是即時回饋的。Reward
。Reward 是即時回饋的。Reward  發生在從 state 選擇 action 後,轉移至 state 的過程中。
發生在從 state 選擇 action 後,轉移至 state 的過程中。
![\displaystyle r(s, a, s^\prime) \doteq \mathbb{E} \left[ R_t \mid S_{t-1}=s, A_{t-1}=a, S_t=s^\prime \right] = \sum_{r \in \mathcal{R}} r \frac{p(s^\prime, r \mid s, a)}{p(s^\prime \mid s, a)} \\\\ r(s, a) \doteq \mathbb{E} \left[ R_t \mid S_{t-1}=s, A_{t-1}=a \right] = \sum_{r \in \mathcal{R}} r \sum_{s^\prime \in \mathcal{S}} p(s^\prime, r \mid s, a)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+r%28s%2C+a%2C+s%5E%5Cprime%29+%5Cdoteq+%5Cmathbb%7BE%7D+%5Cleft%5B+R_t+%5Cmid+S_%7Bt-1%7D%3Ds%2C+A_%7Bt-1%7D%3Da%2C+S_t%3Ds%5E%5Cprime+%5Cright%5D+%3D+%5Csum_%7Br+%5Cin+%5Cmathcal%7BR%7D%7D+r+%5Cfrac%7Bp%28s%5E%5Cprime%2C+r+%5Cmid+s%2C+a%29%7D%7Bp%28s%5E%5Cprime+%5Cmid+s%2C+a%29%7D+%5C%5C%5C%5C+r%28s%2C+a%29+%5Cdoteq+%5Cmathbb%7BE%7D+%5Cleft%5B+R_t+%5Cmid+S_%7Bt-1%7D%3Ds%2C+A_%7Bt-1%7D%3Da+%5Cright%5D+%3D+%5Csum_%7Br+%5Cin+%5Cmathcal%7BR%7D%7D+r+%5Csum_%7Bs%5E%5Cprime+%5Cin+%5Cmathcal%7BS%7D%7D+p%28s%5E%5Cprime%2C+r+%5Cmid+s%2C+a%29+&bg=ffffff&fg=000&s=1&c=20201002)
折扣因子(Discount Factor)
折扣因子(Discount factor)記作 ![\gamma \in \left[ 0,1 \right]](https://s0.wp.com/latex.php?latex=%5Cgamma+%5Cin+%5Cleft%5B+0%2C1+%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002) 。它是用來衡量未來 reward 的價值。當
。它是用來衡量未來 reward 的價值。當  時,表示只重視當下的 reward;當
時,表示只重視當下的 reward;當  時,表示未來的 reward 與現在的 reward 同等重要。
時,表示未來的 reward 與現在的 reward 同等重要。
回報(Returns)和分節(Episodes)
Agent 的目標,從長遠來看是最大化累積的 reward,也就是最大化在 time step 之後能接受到的 reward。我們稱為最大化預期回報(expected return)。在 time step 的 return 記作  。在最簡單的情況下,return 是 reward 的總和:
。在最簡單的情況下,return 是 reward 的總和:

其中  為最後一個 time step。
為最後一個 time step。
當 agent 和 environment 的 interaction 可以自然地被劃分為子序列時,我們將這樣的子序列稱為分節(episodes)。每個 episode 以一個稱為終端狀態(terminal state)的特殊狀態結束。每個 episode 與上一個 episode 是無關的。這種任務被稱為分節式任務(episodic tasks),如一局遊戲。
當 agent 和 environment 的 interaction 無法被自然地劃分為 episodes,而是不斷地持續進行時,這種任務被稱為連續性任務(continuing tasks),如生命週期相當長的機器人應用。因此,在 的公式裡,最後的 time step 將是  。當我們試圖最大化 return 時, 很輕易地成為無窮大。
。當我們試圖最大化 return 時, 很輕易地成為無窮大。
我們可以使用折扣(discounting)來解決這個問題。Agent 將最大化預期折扣回報(expected discounted return):

其中 為折扣因子(discounting factor)。
連續時步(Successive time steps)的 return 是相互關聯,這對 RL 的理論和演算法很重要:

雖然 discounted return 是由無窮多項組成,但如果 reward 是非零常數,且  ,則 return 仍是有限的值。例如,如果 reward 是
,則 return 仍是有限的值。例如,如果 reward 是  ,則 return 為:
,則 return 為:

策略(Policy)
每個 state 是使用策略(policy)來從動作集合 中,選擇 action  。Policy 記作
。Policy 記作  。正式地說,policy 是一個從 state 對可選的 actions 的機率分佈。
。正式地說,policy 是一個從 state 對可選的 actions 的機率分佈。
在 time step 時,當 agent 處於 state ,依據 policy 選擇 action 的機率為:

Policy 可以是決定性策略(deterministic policy)。也就是 policy 永遠只會選擇某一個 action。

Policy 也可以是隨機性策略(stochastic policy),則每個 action 都有被選中的機率。
價值函數(Value Function)
價值函數(Value function)是一個對 policy 的評估。評估,在 policy 下,評估未來能獲得的 expected return 是多少。
狀態價值函數(State-Value Function)
在 policy 下,從 state 開始,評估未來能獲得的 expected return 是多少?這個稱為 policy 的狀態價值函數(state-value function),記作  。
。
![\displaystyle v_\pi(s) \doteq \mathbb{E}_\pi \left[ G_t \mid S_t=s \right] = \mathbb{E}_\pi \left[ \sum_{k=0}^\infty \gamma^k R_{t+k+1} \mid S_t=s \right], \forall s \in \mathcal{S}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+v_%5Cpi%28s%29+%5Cdoteq+%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+G_t+%5Cmid+S_t%3Ds+%5Cright%5D+%3D+%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+%5Csum_%7Bk%3D0%7D%5E%5Cinfty+%5Cgamma%5Ek+R_%7Bt%2Bk%2B1%7D+%5Cmid+S_t%3Ds+%5Cright%5D%2C+%5Cforall+s+%5Cin+%5Cmathcal%7BS%7D+&bg=ffffff&fg=000&s=1&c=20201002)
動作價值函數(Action-Value Function)
在 policy 下,在 state 下並選擇 action 開始,評估未來能獲得的 expected return 是多少?這個稱為 policy 的動作價值函數(action-value function),記作  ,也因此又被稱為 q-function。
,也因此又被稱為 q-function。
![\displaystyle q_\pi(s,a) \doteq \mathbb{E}_\pi \left[ G_t \mid S_t=s, A_t=a \right] = \mathbb{E}_\pi \left[ \sum_{k=0}^\infty \gamma^k R_{t+k+1} \mid S_t=s, A_t=a \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+q_%5Cpi%28s%2Ca%29+%5Cdoteq+%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+G_t+%5Cmid+S_t%3Ds%2C+A_t%3Da+%5Cright%5D+%3D+%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+%5Csum_%7Bk%3D0%7D%5E%5Cinfty+%5Cgamma%5Ek+R_%7Bt%2Bk%2B1%7D+%5Cmid+S_t%3Ds%2C+A_t%3Da+%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)
狀態價值函數(State-Value Function)和動作價值函數(Action-Value Function)之間的關係
State-value function  和 action-value function
和 action-value function  之間的關係貫穿了整個 RL。因此,這小節中的公式將會在 RL 中一直被提及。
之間的關係貫穿了整個 RL。因此,這小節中的公式將會在 RL 中一直被提及。
以下是  的 backup diagram,其中空心圓是 states,而實心圓是 actions。這張圖總括我們至目前為止談論到的元素。在 state 下,依據 policy 來選擇 action 。然後,依據 state-transition dynamics 決定下一個 state 並且產生一個 reward 給 state 。
的 backup diagram,其中空心圓是 states,而實心圓是 actions。這張圖總括我們至目前為止談論到的元素。在 state 下,依據 policy 來選擇 action 。然後,依據 state-transition dynamics 決定下一個 state 並且產生一個 reward 給 state 。
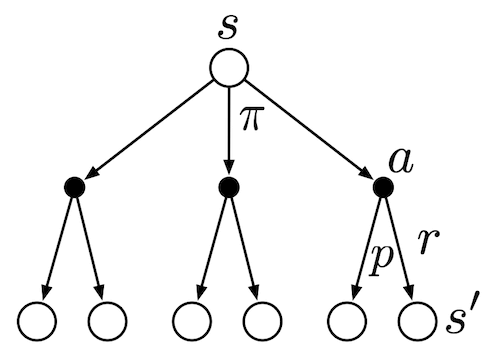
首先,我們來看 state-value function 對 action-value function 的關係。在一個給定的 state 下, 是對所有可能 action 的加權期望,而其加權的權重由 policy  所決定。換言之,state-value function 可以視為 action-value function 的期望值。
所決定。換言之,state-value function 可以視為 action-value function 的期望值。

接下來,我們來看 action-value function 對 state-value function 的遞迴關係。在 state 下選擇 action 後, 是對所有可能的下一個 state 與對應即時 reward 的加權期望,而其加權的權重由 state-transition probabilities
是對所有可能的下一個 state 與對應即時 reward 的加權期望,而其加權的權重由 state-transition probabilities  所決定。對每一個可能的
所決定。對每一個可能的  ,我們累加即時 reward 與折扣後的未來價值
,我們累加即時 reward 與折扣後的未來價值  。因此,action-value function 等於即時 reward 加上折扣後的 state-value function 的期望值。
。因此,action-value function 等於即時 reward 加上折扣後的 state-value function 的期望值。
![\displaystyle q_\pi(s, a) = \sum_{s^\prime, r} p(s^\prime, r \mid s, a) \left[ r + \gamma v_\pi(s^\prime) \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+q_%5Cpi%28s%2C+a%29+%3D+%5Csum_%7Bs%5E%5Cprime%2C+r%7D+p%28s%5E%5Cprime%2C+r+%5Cmid+s%2C+a%29+%5Cleft%5B+r+%2B+%5Cgamma+v_%5Cpi%28s%5E%5Cprime%29+%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)
貝爾曼期望方程(Bellman Expectation Equation)
貝爾曼方程(Bellman Equation),以 Richard E. Bellman 之名命名,是動態規劃(Dynamic Programming)中的一項技術。Bellman 所提出的最適性原則(principle of optimality)是指,一個最佳化問題可以被拆解為一個由子問題組成的遞迴結構。任何一個狀態的價值,都可以表達為某些初始選擇所帶來的即時報酬,加上因這些選擇所導致的後續子問題的價值。
因此,Bellman equation 的基本思想是,一個 state 的 value 可以表達為下一步的 reward 加上下一個 state 的 value 的期望值。
狀態價值函數(State-Value Function)的貝爾曼期望方程(Bellman Expectation Equation)
在 policy 下,state-value function 可以寫成如下的遞迴形式:
![\displaystyle v_\pi(s) \doteq \mathbb{E}_\pi \left[ G_t \mid S_t=s \right] \\\\ \hphantom{v_\pi(s)} = \mathbb{E}_\pi \left[ R_{t+1} + \gamma G_{t+1} \mid S_t=s \right] \\\\ \hphantom{v_\pi(s)} = \sum_a \pi(a \mid s) \sum_{s^\prime} \sum_r p(s^\prime, r \mid s, a) \Big[ r + \gamma \mathbb{E}_\pi \left[ G_{t+1} \mid S_{t+1} = s^\prime \right] \Big] \\\\ \hphantom{v_\pi(s)} = \sum_a \pi(a \mid s) \sum_{s^\prime} \sum_r p(s^\prime, r \mid s, a) \Big[ r + \gamma v_\pi(s^\prime) \Big], \forall s \in \mathcal{S}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+v_%5Cpi%28s%29+%5Cdoteq+%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+G_t+%5Cmid+S_t%3Ds+%5Cright%5D+%5C%5C%5C%5C+%5Chphantom%7Bv_%5Cpi%28s%29%7D+%3D+%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+R_%7Bt%2B1%7D+%2B+%5Cgamma+G_%7Bt%2B1%7D+%5Cmid+S_t%3Ds+%5Cright%5D+%5C%5C%5C%5C+%5Chphantom%7Bv_%5Cpi%28s%29%7D+%3D+%5Csum_a+%5Cpi%28a+%5Cmid+s%29+%5Csum_%7Bs%5E%5Cprime%7D+%5Csum_r+p%28s%5E%5Cprime%2C+r+%5Cmid+s%2C+a%29+%5CBig%5B+r+%2B+%5Cgamma+%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+G_%7Bt%2B1%7D+%5Cmid+S_%7Bt%2B1%7D+%3D+s%5E%5Cprime+%5Cright%5D+%5CBig%5D+%5C%5C%5C%5C+%5Chphantom%7Bv_%5Cpi%28s%29%7D+%3D+%5Csum_a+%5Cpi%28a+%5Cmid+s%29+%5Csum_%7Bs%5E%5Cprime%7D+%5Csum_r+p%28s%5E%5Cprime%2C+r+%5Cmid+s%2C+a%29+%5CBig%5B+r+%2B+%5Cgamma+v_%5Cpi%28s%5E%5Cprime%29+%5CBig%5D%2C+%5Cforall+s+%5Cin+%5Cmathcal%7BS%7D+&bg=ffffff&fg=000&s=1&c=20201002)
這個方程描述,在 state 下, 是對所有可能 action 的加權期望,而加權方式由  所決定。每個 action 的價值又是其可能的下一個 state 與 reward 所帶來的即時報酬,以及折扣後的未來價值的期望。因此,我們稱此為貝爾曼期望方程(Bellman Expectation Equation)。
所決定。每個 action 的價值又是其可能的下一個 state 與 reward 所帶來的即時報酬,以及折扣後的未來價值的期望。因此,我們稱此為貝爾曼期望方程(Bellman Expectation Equation)。
動作價值函數(Action-Value Function)的貝爾曼期望方程(Bellman Expectation Equation)
對 action-value function 進行同樣的遞迴推導,可以得到:
![\displaystyle q_\pi(s, a) \doteq \mathbb{E}_\pi \left[ G_t \mid S_t=s, A_t=a \right] \\\\ \hphantom{v_\pi(s, a)} = \mathbb{E}_\pi \left[ R_{t+1} + \gamma G_{t+1} \mid S_t=s, A_t=a \right] \\\\ \hphantom{v_\pi(s, a)} = \sum_{s^\prime} \sum_r p(s^\prime, r \mid s, a) \Big[ r + \gamma \mathbb{E}_\pi \left[ G_{t+1} \mid S_{t+1} = s^\prime \right] \Big] \\\\ \hphantom{v_\pi(s, a)} = \sum_{s^\prime} \sum_r p(s^\prime, r \mid s, a) \Big[ r + \gamma v_\pi(s^\prime) \Big], \forall s \in \mathcal{S}, a \in \mathcal{A}(s)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+q_%5Cpi%28s%2C+a%29+%5Cdoteq+%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+G_t+%5Cmid+S_t%3Ds%2C+A_t%3Da+%5Cright%5D+%5C%5C%5C%5C+%5Chphantom%7Bv_%5Cpi%28s%2C+a%29%7D+%3D+%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+R_%7Bt%2B1%7D+%2B+%5Cgamma+G_%7Bt%2B1%7D+%5Cmid+S_t%3Ds%2C+A_t%3Da+%5Cright%5D+%5C%5C%5C%5C+%5Chphantom%7Bv_%5Cpi%28s%2C+a%29%7D+%3D+%5Csum_%7Bs%5E%5Cprime%7D+%5Csum_r+p%28s%5E%5Cprime%2C+r+%5Cmid+s%2C+a%29+%5CBig%5B+r+%2B+%5Cgamma+%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+G_%7Bt%2B1%7D+%5Cmid+S_%7Bt%2B1%7D+%3D+s%5E%5Cprime+%5Cright%5D+%5CBig%5D+%5C%5C%5C%5C+%5Chphantom%7Bv_%5Cpi%28s%2C+a%29%7D+%3D+%5Csum_%7Bs%5E%5Cprime%7D+%5Csum_r+p%28s%5E%5Cprime%2C+r+%5Cmid+s%2C+a%29+%5CBig%5B+r+%2B+%5Cgamma+v_%5Cpi%28s%5E%5Cprime%29+%5CBig%5D%2C+%5Cforall+s+%5Cin+%5Cmathcal%7BS%7D%2C+a+%5Cin+%5Cmathcal%7BA%7D%28s%29+&bg=ffffff&fg=000&s=1&c=20201002)
這的方程描述,在 state 下採取 action 的價值,是即時 reward 與折扣後未來 state-value 的加權期望,而加權方式由 environment 的 transition probabilities 所決定。
最佳策略(Optimal Policy)
解決 RL 任務是指,發現一個能長期獲得大量 reward 的 policy。對於 finite MDP,我們可以精確地定義一個最佳策略(optimal policy)。Value functions 對策略定義一個部分排序。若在所有的 states 下,一個 policy 的 expected return 都大於或等於另一個 policy  ,則policy 被定義為比 policy 較好或一樣好。
,則policy 被定義為比 policy 較好或一樣好。

總是至少有一個 policy 優於或等於所有其他 policies。這就是一個 optimal policy。雖然有可以多於一個 optimal policy,我們還是將所有的 optimal policies 記作  。
。
這些 optimal policies 有相同的 state-value function,稱為最佳狀態價值函數(optimal state-value function),記作  。
。

它們也有相同的 action-value function,稱為最佳動作價值函數(optimal action-value function),記作  。
。

貝爾曼最佳方程(Bellman Optimality Equation)
最佳狀態價值函數(Optimal State-Value Function)的貝爾曼最佳方程(Bellman Optimality Equation)
在 optimal policy 下,optimal state-value function 可以寫成如下的遞迴形式:
![\displaystyle v_*(s)=\max_{a \in \mathcal{A}(s)} q_* (s, a) \\\\ \hphantom{v_*(s)} = \max_a \mathbb{E}_{\pi_*} \left[ G_t \mid S_t=s, A_t=a \right] \\\\ \hphantom{v_*(s)} = \max_a \mathbb{E}_{\pi_*} \left[ R_{t+1} + \gamma G_{t+1} \mid S_t=s, A_t=a \right] \\\\ \hphantom{v_*(s)} = \max_a \mathbb{E} \left[ R_{t+1} + \gamma v_*(S_{t+1}) \mid S_t=s, A_t=a \right] \\\\ \hphantom{v_*(s)} = \max_a \sum_{s^\prime, r} p(s^\prime, r \mid s, a) \left[ r + \gamma v_*(s^\prime) \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+v_%2A%28s%29%3D%5Cmax_%7Ba+%5Cin+%5Cmathcal%7BA%7D%28s%29%7D+q_%2A+%28s%2C+a%29+%5C%5C%5C%5C+%5Chphantom%7Bv_%2A%28s%29%7D+%3D+%5Cmax_a+%5Cmathbb%7BE%7D_%7B%5Cpi_%2A%7D+%5Cleft%5B+G_t+%5Cmid+S_t%3Ds%2C+A_t%3Da+%5Cright%5D+%5C%5C%5C%5C+%5Chphantom%7Bv_%2A%28s%29%7D+%3D+%5Cmax_a+%5Cmathbb%7BE%7D_%7B%5Cpi_%2A%7D+%5Cleft%5B+R_%7Bt%2B1%7D+%2B+%5Cgamma+G_%7Bt%2B1%7D+%5Cmid+S_t%3Ds%2C+A_t%3Da+%5Cright%5D+%5C%5C%5C%5C+%5Chphantom%7Bv_%2A%28s%29%7D+%3D+%5Cmax_a+%5Cmathbb%7BE%7D+%5Cleft%5B+R_%7Bt%2B1%7D+%2B+%5Cgamma+v_%2A%28S_%7Bt%2B1%7D%29+%5Cmid+S_t%3Ds%2C+A_t%3Da+%5Cright%5D+%5C%5C%5C%5C+%5Chphantom%7Bv_%2A%28s%29%7D+%3D+%5Cmax_a+%5Csum_%7Bs%5E%5Cprime%2C+r%7D+p%28s%5E%5Cprime%2C+r+%5Cmid+s%2C+a%29+%5Cleft%5B+r+%2B+%5Cgamma+v_%2A%28s%5E%5Cprime%29+%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)
其中  表示,在每個 state 中,都挑選能使價值最大化的 action,這反映 optimal policy 的本質。這就是 的貝爾曼最佳方程(Bellman Optimality Equation)。
表示,在每個 state 中,都挑選能使價值最大化的 action,這反映 optimal policy 的本質。這就是 的貝爾曼最佳方程(Bellman Optimality Equation)。
最佳動作價值函數(Optimal Action-Value Function)的貝爾曼最佳方程(Bellman Optimality Equation)
在 optimal policy 下,optimal action-value function 可以寫成如下的遞迴形式
![\displaystyle q_*(s, a) = \mathbb{E} \left[ R_{t+1} + \gamma \max_{a^\prime} q_*(S_{t+1}, a^\prime) \mid S_t=s, A_t=a \right] \\\\ \hphantom{q_*(s, a)} = \sum_{s^\prime, r} p(s^\prime, r \mid s, a) \left[ r + \gamma \max_{a^\prime} q_*(s^\prime, a^\prime) \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+q_%2A%28s%2C+a%29+%3D+%5Cmathbb%7BE%7D+%5Cleft%5B+R_%7Bt%2B1%7D+%2B+%5Cgamma+%5Cmax_%7Ba%5E%5Cprime%7D+q_%2A%28S_%7Bt%2B1%7D%2C+a%5E%5Cprime%29+%5Cmid+S_t%3Ds%2C+A_t%3Da+%5Cright%5D+%5C%5C%5C%5C+%5Chphantom%7Bq_%2A%28s%2C+a%29%7D+%3D+%5Csum_%7Bs%5E%5Cprime%2C+r%7D+p%28s%5E%5Cprime%2C+r+%5Cmid+s%2C+a%29+%5Cleft%5B+r+%2B+%5Cgamma+%5Cmax_%7Ba%5E%5Cprime%7D+q_%2A%28s%5E%5Cprime%2C+a%5E%5Cprime%29+%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)
這就是 的 Bellman optimality equation。
結論
MDP 為 RL 中的決策問題提供了一套精確、可操作的數學描述,使我們得以定義 policies、衡量 policies 的長期表現,並進一步比較不同 policies 的優劣。後續的控制問題與最佳策略搜尋,所有方法最終都可追溯至 MDP 中的這一組核心定義。
參考
- Adam White and Martha White. Reinforcement Learning Specialization. University of Alberta and Coursera.
- Richard S. Sutton and Andrew G. Barto. 2020. Reinforcement Learning: An Introduction, 2nd. The MIT Press.









