
在強化學習(Reinforcement Learning, RL)中,許多演算法在形式上看似不同,但其核心更新機制卻高度一致。它們在實作層面都依賴一種共同的數值估計方式。這種方式並不是一個獨立的演算法,而是一種用來逐步逼近期望值的計算技巧。理解這個機制,有助於看清不同強化學習方法之間真正的差異所在。
Table of Contents
增量式實作(Incremental Implementation)
在強化學習(Reinforcement Learning, RL)中,增量式實作(incremental implementation)不是一個獨立的演算法,而是一種估計期望值(expectation)的數值計算方法。它的想法是,不要一次用全部的資料來重新計算期望值,而是在每次得到新的樣本時,對估計值做小幅度的修正。

其中,目標(target)與舊估計值(old estimate)之差可視為當前估計的誤差(error)。Incremental update 的本質,便是沿著此 error 方向修正估計值。

增量式的數學本質(The Mathematical Essence of Incremental)
給定樣本  ,則樣本平均的計算如下。這是樣本平均的 batch 形式。
,則樣本平均的計算如下。這是樣本平均的 batch 形式。

然而,也可以用樣本平均的 incremental 形式來計算,如下。這是典型的 incremental update。

其中,step size  ,而 target 是
,而 target 是 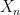 。在 incremental form 中,每次 update 皆可視為以新觀測到的樣本 作為當前的 sample target。
。在 incremental form 中,每次 update 皆可視為以新觀測到的樣本 作為當前的 sample target。
值得注意的是,隨著新的樣本不斷地獲得,step size  會越來越小。因此,就算新的資料顯示平均值已經改變很多,但是由於 step size 變得很小,於是估計值會僵住,跟不上變化。在非平穩(non-stationary)資料分佈下,隨著 趨近於 0,估計值將逐漸喪失對新資料的適應能力。在此情境下,若希望估計值對近期樣本保持敏感,則可改採常數步長(constant step size)
會越來越小。因此,就算新的資料顯示平均值已經改變很多,但是由於 step size 變得很小,於是估計值會僵住,跟不上變化。在非平穩(non-stationary)資料分佈下,隨著 趨近於 0,估計值將逐漸喪失對新資料的適應能力。在此情境下,若希望估計值對近期樣本保持敏感,則可改採常數步長(constant step size) 。使用 constant step size 的 incremental update 如下:
。使用 constant step size 的 incremental update 如下:

將上式展開後,我們可以看到越舊的樣本的影響會越小。

結語
Incremental implementation 提供了一個統一的視角,來理解 RL 中各種價值估計的更新方式。透過 step size 與 target 的設定,演算法得以在有限記憶與線上互動的情境下,持續修正對期望值的估計。當 step size 隨樣本數遞減時,估計值會趨近於傳統的樣本平均;而在使用 constant step size 時,則能在 non-stationary 環境中保有對新資料的適應能力。後續將會看到,不同的 RL 方法,正是透過定義不同的 target,並套用同一套 incremental update 框架,來形成各自的學習行為。
參考
- Richard S. Sutton and Andrew G. Barto. 2020. Reinforcement Learning: An Introduction, 2nd. The MIT Press.









