
GloVe 是一種詞嵌入(word embedding)模型,透過 global co-occurence 統計來構建詞向量。與依賴 local context windows 的 Word2Vec 不同,GloVe 通過矩陣分解(matrix factorization)來捕捉詞語之間的整體統計關係。這種方法使 GloVe 能夠生成高質量的詞向量,有效地編碼語義和語法關係。本文將介紹 GloVe 的原理與訓練方法。
Table of Contents
GloVe 模型
GloVe 是由 Stanford 的 J. Pennington et al. 在 2014 年提出的一種 word embeddings 學習模型。不同於 Word2Vec 使用 local context window 方法,GloVe 使用 global matrix factorization 方法。它基於從詞共現矩陣(word co-occurrence matrix)中提取統計信息來建構 word embeddings。因此,GloVe 通過 matrix factorization 可以捕捉整個 corpus 範圍內的詞語關係。
建構 Co-occurrence Matrix
GloVe 的一個關鍵概念是,詞語的含義可以從它們的共現機率中推導出來。所以,對于 GloVe,co-occurrence matrix 是很重要的。Co-occurrence 是指,對於 word i,word j 出現在它的 context 裡的次數。
假設我們有一個包含以下三個句子的 corpus:
- I like deep learning.
- I like machine learning.
- Deep learning is powerful.
假設 context window 的大小是 1,也就是前後各一個詞。那我們可以建立以下的 co-occurrence matrix X。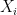 是 row;
是 row;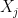 是 column。
是 column。 是指 word
是指 word j 出現在 word i 的 context 裡的次數。
| I | like | deep | learning | machine | is | powerful | |
| I | – | 2 | 0 | 0 | 0 | 0 | 0 |
| like | 2 | – | 1 | 0 | 1 | 0 | 0 |
| deep | 0 | 1 | – | 2 | 0 | 0 | 0 |
| learning | 0 | 0 | 2 | – | 1 | 1 | 0 |
| machine | 0 | 1 | 0 | 1 | – | 0 | 0 |
| is | 0 | 0 | 0 | 1 | 0 | – | 1 |
| powerful | 0 | 0 | 0 | 0 | 0 | 1 | – |
我們用以下的 notation 來定義 co-occurrence matrix。

詞關係的機率比
有了 co-occurrence matrix,我們可以利用它來定義一些 word relationships。令  為 word
為 word j 出現在 word i 的 context 的機率。

例如,在上述的表格中,”learning” 出現在 “deep” 的 context 的機率為:

然而,我們無法透過 來了解 word i 和 word j 與其他詞同時出現有何不同。現在我們引入另一個 word k,則:
- 當
k與i一起出現的頻率比與j一起出現的頻率更高時,則 。
。 - 當
k與i和j一起出現的頻率相似時,則。
 。
。 。
。因此,共現機率比(ratio of co-occurrence probabilities) 才是衡量
才是衡量 i 和 j 相對於 k 的差異程度。因此,GloVe 的 word embeddings 是學習 ratio of co-occurrence probabilities 而不是 co-occurrence probabilities 本身。因此,ratio of co-occurrence probabilities 可用以下模型表示:

我們想要 F 可以捕捉 比的信息。最自然的方式就是利用向量的差。因此,上面的式子可以修改為:

由於式子右邊是純量,而左邊是向量。因此,再將式子修改為:

下面的式子中,我們令  為:
為:

接著,我們可以推導出下面的式子。

最後,加上額外的 bias,我們可以得到:

損失函數(Loss Function)
在上面最後一個式子中,我們可以看出它很像最小平法(least squares)。GloVe 依據上面的式子提出新的 weighted least squares,如下。

其中,f 是 weighting function,其定義如下:

J. Pennington et al. 在論文中使用  和
和  。
。
最終的 Word Embeddings
GloVe 視 Co-occurrence matrix X 為對稱矩陣(symmetric matrix),也就是  。因此,理論上,學習到的
。因此,理論上,學習到的  和
和  代表的資訊是相等的。兩者在分布空間當中,只是因為初始化不同而略有差異。因此,最後的輸出會用兩者的平均。
代表的資訊是相等的。兩者在分布空間當中,只是因為初始化不同而略有差異。因此,最後的輸出會用兩者的平均。
實作與範例
我們將以 Wikipedia 的 Oolong 文章作為 corpus。在下面的程式碼中,我們抓取文章,並將它依句子分割,再依詞分割。
wiki = wikipediaapi.Wikipedia(user_agent="waynestalk/1.0", language="en")
page = wiki.page("Oolong")
corpus = page.text
nltk.download("punkt")
sentences = nltk.sent_tokenize(corpus)
tokenized_corpus = [[word.lower() for word in nltk.word_tokenize(sentence) if word.isalpha()] for sentence in sentences]
vocab = set([word for sentence in tokenized_corpus for word in sentence])
word_to_index = {word: i for i, word in enumerate(vocab)}
index_to_word = {i: word for i, word in enumerate(vocab)}
len(vocab)
# Output
580接下來,我們建立 co-occurrence matrix,其中 context window 大小設為 2。
window_size = 2
vocab_size = len(vocab)
co_occurrence_matrix = torch.zeros((vocab_size, vocab_size))
for sentence in tokenized_corpus:
for i, word in enumerate(sentence):
word_index = word_to_index[word]
for j in range(max(0, i - window_size), min(i + window_size + 1, len(sentence))):
if i != j:
context_index = word_to_index[sentence[j]]
co_occurrence_matrix[word_index, context_index] += 1以下是 GloVe 模型的實作。
class GloVe(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(GloVe, self).__init__()
self.word_embedding = nn.Embedding(vocab_size, embedding_dim)
self.context_embedding = nn.Embedding(vocab_size, embedding_dim)
self.word_bias = nn.Embedding(vocab_size, 1)
self.context_bias = nn.Embedding(vocab_size, 1)
nn.init.uniform_(self.word_embedding.weight, a=-0.5, b=0.5)
nn.init.uniform_(self.context_embedding.weight, a=-0.5, b=0.5)
nn.init.zeros_(self.word_bias.weight)
nn.init.zeros_(self.context_bias.weight)
def forward(self, word_index, context_index, co_occurrence):
word_emb = self.word_embedding(word_index)
context_emb = self.context_embedding(context_index)
word_b = self.word_bias(word_index).squeeze()
context_b = self.context_bias(context_index).squeeze()
weighting = self.weighting_function(co_occurrence)
log_co_occurrence = torch.log(co_occurrence)
dot = (word_emb * context_emb).sum(dim=1)
loss = weighting * (dot + word_b + context_b - log_co_occurrence) ** 2
return loss.sum()
def weighting_function(self, x, x_max=100, alpha=0.75):
return torch.where(x < x_max, (x / x_max) ** alpha, torch.ones_like(x))在開始訓練之前,我們先平坦化訓練資料。
word_indices = []
context_indices = []
co_occurrences = []
for i in range(vocab_size):
for j in range(vocab_size):
if co_occurrence_matrix[i, j] > 0:
word_indices.append(i)
context_indices.append(j)
co_occurrences.append(co_occurrence_matrix[i, j])
word_indices = torch.tensor(word_indices, dtype=torch.long)
context_indices = torch.tensor(context_indices, dtype=torch.long)
co_occurrences = torch.tensor(co_occurrences, dtype=torch.float)現在我們可以訓練模型,如下。
embedding_dim = 1000
model = GloVe(vocab_size, embedding_dim)
optimizer = optim.Adam(model.parameters(), lr=0.01)
epochs = 500
start_time = time.time()
for epoch in range(epochs):
loss = model(word_indices, context_indices, co_occurrences)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch == 0 or (epoch + 1) % 100 == 0:
print(f"Epoch: {epoch}, Loss: {loss.item()}")
end_time = time.time()
print(f"Training time: {end_time - start_time} seconds")
# Output
Epoch: 0, Loss: 1147.0933837890625
Epoch: 99, Loss: 0.01006692461669445
Epoch: 199, Loss: 0.0013765881303697824
Epoch: 299, Loss: 0.007692785933613777
Epoch: 399, Loss: 0.031206317245960236
Epoch: 499, Loss: 0.027982018887996674
Training time: 2.2056429386138916 seconds最後的 word embeddings 是取 word_embedding 和 context_embedding 的平均。
def get_final_embedding(word):
word_index = torch.tensor(word_to_index[word], dtype=torch.long)
w_vec = model.word_embedding(word_index).detach()
c_vec = model.context_embedding(word_index).detach()
return (w_vec + c_vec) / 2.0以下程式碼中,我們用訓練好的 word embeddings 來計算兩個句子的相似度。
sentence1 = "tea is popular in taiwan".split()
sentence2 = "oolong is famous in taiwan".split()
sentence1_embeddings = [get_final_embedding(word) for word in sentence1]
sentence2_embeddings = [get_final_embedding(word) for word in sentence2]
vector1 = torch.stack(sentence1_embeddings).mean(dim=0)
vector2 = torch.stack(sentence2_embeddings).mean(dim=0)
cosine_sim = nn.CosineSimilarity(dim=0)
similarity = cosine_sim(vector1, vector2).item()
print(f"Sentence 1: {sentence1}")
print(f"Sentence 2: {sentence2}")
print(f"Similarity between sentences: {similarity}")
# Output
Sentence 1: ['tea', 'is', 'popular', 'in', 'taiwan']
Sentence 2: ['oolong', 'is', 'famous', 'in', 'taiwan']
Similarity between sentences: 0.6013368964195251結語
GloVe 是一個強大的 word embedding 模型,可以透過統計 co-occurrence 分析有效捕捉全局詞關係。它產生有意義的向量表示的能力使其成為文字分類、情緒分析和機器翻譯等 NLP 應用中的寶貴工具。
參考
- Andrew Ng, Deep Learning Specialization, Coursera.
- Jeffrey Pennington, Richard Socher, and Christopher D. Manning. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1532-1543.
- GloVe: Global Vectors for Word Representation.









