
廣義策略迭代(Generalized Policy Iteration, GPI)並不是一個單一的演算法,而是所有強化學習(Reinforcement Learning, RL)方法背後的核心框架。它結合了策略評估(policy evaluation)與策略改善(policy improvement),使得在有限資訊的情況下,演算法仍能逐步逼近最佳策略(optimal policy)  與最佳狀態價值函數(optimal state-value function)
與最佳狀態價值函數(optimal state-value function) 。
。
Table of Contents
馬可夫決策過程(Markov Decision Process, MDP)
在閱讀本文章之前,讀者必須要先了解馬可夫決策過程(Markov Decision Process, MDP)。如果對 MDP 還不熟悉的話,可以先參考以下文章。

廣義策略迭代(Generalized Policy Iteration, GPI)
在一個 MDP 中,agent 的目標,從長遠來看是最大化期望回報(expected return)。換言之,MDP 的目標本質上就是,尋找一個能在所有 states 上達到最大 expected return 的 policy 。這個任務被稱為控制問題(control problem)。
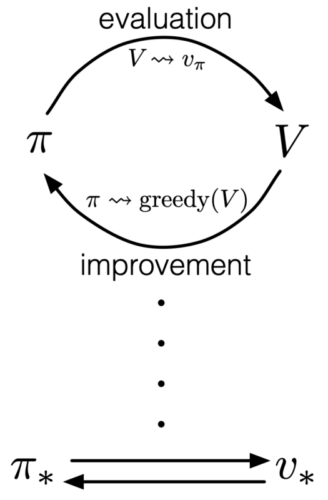
在實作 control problem 的過程中,所有演算法遵循一個共同的架構,策略評估(policy evaluation) 與 策略改善(policy improvement) 兩個過程彼此互相推動、交替進行。這種評估與改善互相作用的統一框架,被稱為廣義策略迭代(Generalized Policy Iteration, GPI)。
在實務上,我們通常一開始只有一個任意的或有限資訊下的 policy,其 value function 尚未精確;同時我們也不知道 optimal policy 會是什麼。GPI 提供了一個普遍適用的原則,使得任何演算法只要遵循兩個步驟便能逐步改善 policy:
- 策略評估(Policy Evaluation):估計目前 policy 的價值(即它的長期表現)。
- 策略改善(Policy Improvement):根據這個價值估計,更新 policy,使其更佳。
透過這兩個過程反覆作用,策略會逐步逼近 optimal policy 。
下圖顯示 GPI 反覆地重複 policy evaluation 和 policy improvement,最後收斂至 optimal policy  。
。
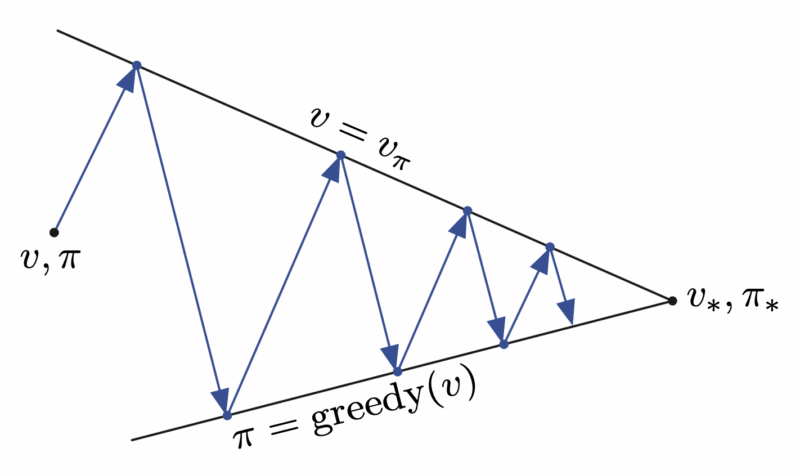
下圖以另一種視角顯示,在 GPI 反覆地重複 policy evaluation 和 policy improvement 時,policy evaluation 把上邊界  拉近,而 policy improvement 把下邊界
拉近,而 policy improvement 把下邊界  拉近,聯合的過程會越來越趨近整體最佳的目標。
拉近,聯合的過程會越來越趨近整體最佳的目標。
策略評估(Policy Evaluation)
給定一個任意 policy  ,求解 state-value function
,求解 state-value function  。這被稱為策略評估(policy evaluation)。我們將它視為預測問題(prediction problem)。
。這被稱為策略評估(policy evaluation)。我們將它視為預測問題(prediction problem)。
Policy evaluation 使用貝爾曼期望方程(Bellman expectation equation)來評估 state-value function。它可以告訴我們,現在的 policy 有多好。
![\displaystyle v_\pi(s) \doteq \mathbb{E}_\pi \left[ R_{t+1} + \gamma v_\pi(S_{t+1}) \mid S_t=s \right] \\\\ \hphantom{v_\pi(s)} = \sum_a \pi(a \mid s) \sum_{s^\prime, r} p(s^\prime, r \mid s, a) \left[ r + \gamma v_\pi(s^\prime) \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+v_%5Cpi%28s%29+%5Cdoteq+%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+R_%7Bt%2B1%7D+%2B+%5Cgamma+v_%5Cpi%28S_%7Bt%2B1%7D%29+%5Cmid+S_t%3Ds+%5Cright%5D+%5C%5C%5C%5C+%5Chphantom%7Bv_%5Cpi%28s%29%7D+%3D+%5Csum_a+%5Cpi%28a+%5Cmid+s%29+%5Csum_%7Bs%5E%5Cprime%2C+r%7D+p%28s%5E%5Cprime%2C+r+%5Cmid+s%2C+a%29+%5Cleft%5B+r+%2B+%5Cgamma+v_%5Cpi%28s%5E%5Cprime%29+%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)
策略改善(Policy Improvement)
給定一個任意 policy 與其以估計的 state-value function  ,尋找另一個更好的 policy
,尋找另一個更好的 policy  ,使得
,使得  。這被稱為策略改善(policy improvement)。
。這被稱為策略改善(policy improvement)。
Policy improvement 的想法是,我們已知一個任意確定性策略(deterministic policy),對於某些 state  ,我們想知道是否需要改變 policy 來確定性地(deterministically)選擇另一個 action
,我們想知道是否需要改變 policy 來確定性地(deterministically)選擇另一個 action  。若另一個 action 比較好的話,則我們更新(改善) policy。
。若另一個 action 比較好的話,則我們更新(改善) policy。

具體而言,在 policy 且 state 下,我們可以使用 action-value function 的 Bellman expectation equation 來評估,另外一個 action 是不是比原本選擇的 action 好。
![\displaystyle q_\pi(s, a) \doteq \mathbb{E}_\pi \left[ R_{t+1} + \gamma v_\pi(S_{t+1}) \mid S_t=s, A_t=a \right] \\\\ \hphantom{q_\pi(s, a)} = \sum_{s^\prime, r} p(s^\prime, r \mid s, a) \left[ r + \gamma v_\pi(s^\prime) \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+q_%5Cpi%28s%2C+a%29+%5Cdoteq+%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+R_%7Bt%2B1%7D+%2B+%5Cgamma+v_%5Cpi%28S_%7Bt%2B1%7D%29+%5Cmid+S_t%3Ds%2C+A_t%3Da+%5Cright%5D+%5C%5C%5C%5C+%5Chphantom%7Bq_%5Cpi%28s%2C+a%29%7D+%3D+%5Csum_%7Bs%5E%5Cprime%2C+r%7D+p%28s%5E%5Cprime%2C+r+%5Cmid+s%2C+a%29+%5Cleft%5B+r+%2B+%5Cgamma+v_%5Cpi%28s%5E%5Cprime%29+%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)
策略改善定理(Policy Improvement Theorem)是指,如果:

那麼 policy 必須與 policy 相同或更好。也就是說,policy 必須從所有的 state 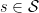 取得更好或相等的 expected return。
取得更好或相等的 expected return。

Policy improvement theorem 證明任何一次 policy improvement,都不會讓 policy 變差,只會變好或一樣。這給了 GPI 保證 policy evaluation 和 policy improvement 不會發散,而是持續朝 optimal policy 收斂。
因此,根據 policy improvement theorem,我們在每個 state,挑選能帶來更高期望回報的 action。我們可以用這個貪婪策略(greedy policy)來進行單步搜尋並採取短期內看起來最好的 action。所以,我們可以用 greedy policy 取得新的 policy 。因此,policy improvement 一定會獲得一個更好的 policy,除非原本的 policy 就是 optimal policy。
![\displaystyle \pi^\prime(s) \doteq \text{argmax}_a q_\pi(s, a) \\\\ \hphantom{pi^\prime(s)} = \text{argmax}_a \mathbb{E}_\pi \left[ R_{t+1} + \gamma v_\pi(S_{t+1}) \mid S_t=s, A_t=a \right] \\\\ \hphantom{pi^\prime(s)} = \text{argmax}_a \sum_{s^\prime, r} p(s^\prime, r \mid s, a) \left[ r + \gamma v_\pi(s^\prime) \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cpi%5E%5Cprime%28s%29+%5Cdoteq+%5Ctext%7Bargmax%7D_a+q_%5Cpi%28s%2C+a%29+%5C%5C%5C%5C+%5Chphantom%7Bpi%5E%5Cprime%28s%29%7D+%3D+%5Ctext%7Bargmax%7D_a+%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+R_%7Bt%2B1%7D+%2B+%5Cgamma+v_%5Cpi%28S_%7Bt%2B1%7D%29+%5Cmid+S_t%3Ds%2C+A_t%3Da+%5Cright%5D+%5C%5C%5C%5C+%5Chphantom%7Bpi%5E%5Cprime%28s%29%7D+%3D+%5Ctext%7Bargmax%7D_a+%5Csum_%7Bs%5E%5Cprime%2C+r%7D+p%28s%5E%5Cprime%2C+r+%5Cmid+s%2C+a%29+%5Cleft%5B+r+%2B+%5Cgamma+v_%5Cpi%28s%5E%5Cprime%29+%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)
其中  表示,所擇使表達式最大化的
表示,所擇使表達式最大化的  。
。
因此,我們用新的  來更新舊的 。
來更新舊的 。
![\displaystyle v_{\pi^\prime}(s) = \max_a \mathbb{E}_\pi \left[ R_{t+1} + \gamma v_\pi(S_{t+1}) \mid S_t=s, A_t=a \right] \\\\ \hphantom{v_{\pi^\prime}(s)} = \max_a \sum_{s^\prime, r} p(s^\prime, r \mid s, a) \left[ r + \gamma v_\pi (s^\prime) \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+v_%7B%5Cpi%5E%5Cprime%7D%28s%29+%3D+%5Cmax_a+%5Cmathbb%7BE%7D_%5Cpi+%5Cleft%5B+R_%7Bt%2B1%7D+%2B+%5Cgamma+v_%5Cpi%28S_%7Bt%2B1%7D%29+%5Cmid+S_t%3Ds%2C+A_t%3Da+%5Cright%5D+%5C%5C%5C%5C+%5Chphantom%7Bv_%7B%5Cpi%5E%5Cprime%7D%28s%29%7D+%3D+%5Cmax_a+%5Csum_%7Bs%5E%5Cprime%2C+r%7D+p%28s%5E%5Cprime%2C+r+%5Cmid+s%2C+a%29+%5Cleft%5B+r+%2B+%5Cgamma+v_%5Cpi+%28s%5E%5Cprime%29+%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)
結語
RL 中的各種演算法,皆可視為 GPI 的具體實例。其差異只在於如何估計 value function 和如何改善 policy,但框架始終一致。GPI 最重要的洞見在於,policy evaluation 不必完全收斂,policy improvement 也不必一次做到最優。兩者只要持續互相推動,就能穩定地朝最優解收斂。這使得 RL 在無法完全掌握 model 或無法精確計算時,仍能透過反覆互動而找到最有效率的 policy。
參考
- Adam White and Martha White. Reinforcement Learning Specialization. University of Alberta and Coursera.
- Richard S. Sutton and Andrew G. Barto. 2020. Reinforcement Learning: An Introduction, 2nd. The MIT Press.









