
門控循環單元(Gate recurrent unit, GRU)是一種 RNN,專門用來處理序列資料(sequential data)。與長短期記憶網路(long short-term memory)相似,它的設計目的是解決標準 RNN 長期依賴(long-term dependency)問題。
Table of Contents
GRU
標準的 RNN 有梯度消失(vanishing gradients)的問題。所以,若序列資料很長時,標準的 RNN 無法有效地學習早期的輸入資料。也就是說,標準的 RNN 在長期記憶的能力是相當微弱的。更多關於 vanishing gradients 的細節,請參考以下文章。此外,若還不熟悉 RNN 的話,也請先參考以下文章。

而與 LSTM 相比,它的結構更加簡單,計算更有效率。關於 LSTM 的細節,請參考以下文章。

下圖是 GRU cell。與標準的 RNN 相比複雜些,但也比 LSTM 簡單些。GRU 除了 hidden state  之外,還要計算 reset gate
之外,還要計算 reset gate  、update gate
、update gate  、和 candidate hidden state
、和 candidate hidden state  。
。

以下是它們各自代表的意義。
- Reset gate
 :此 gate 決定是否遺忘之前的資訊。
:此 gate 決定是否遺忘之前的資訊。 - Update gate :此 gate 決定要記住多少之前的資訊。
- Candidate hidden state :經由處理當前的輸入與部分過去的狀態,產生出新的候選狀態。
前向傳播(Forward Propagation)
下圖是 GRU forward propagation。每一個 gate 與 candidate cell state 都有其相對應的參數  和 activation functions。值得注意的是,我們會將
和 activation functions。值得注意的是,我們會將  和
和  垂直地堆疊起來。
垂直地堆疊起來。

GRU cell 中的公式如下:
![\Gamma_r=\sigma(W_r[a^{<t-1>},x^{<t>}]+b_r) \\\\ \Gamma_u=\sigma(W_u[a^{<t-1>},x^{<t>}]+b_u) \\\\ \tilde{c}^{<t>}=tanh(W_c[(\Gamma_r\odot a^{<t-1>}),x^{<t>}]+b_c) \\\\ a^{<t>}=\Gamma_u\odot\tilde{c}^{<t>}+(1-\Gamma_u)\odot a^{<t-1>} \\\\ \hat{y}^{<t>}=softmax(W_ya^{<t>}+b_y)](https://s0.wp.com/latex.php?latex=%5CGamma_r%3D%5Csigma%28W_r%5Ba%5E%7B%3Ct-1%3E%7D%2Cx%5E%7B%3Ct%3E%7D%5D%2Bb_r%29+%5C%5C%5C%5C+%5CGamma_u%3D%5Csigma%28W_u%5Ba%5E%7B%3Ct-1%3E%7D%2Cx%5E%7B%3Ct%3E%7D%5D%2Bb_u%29+%5C%5C%5C%5C+%5Ctilde%7Bc%7D%5E%7B%3Ct%3E%7D%3Dtanh%28W_c%5B%28%5CGamma_r%5Codot+a%5E%7B%3Ct-1%3E%7D%29%2Cx%5E%7B%3Ct%3E%7D%5D%2Bb_c%29+%5C%5C%5C%5C+a%5E%7B%3Ct%3E%7D%3D%5CGamma_u%5Codot%5Ctilde%7Bc%7D%5E%7B%3Ct%3E%7D%2B%281-%5CGamma_u%29%5Codot+a%5E%7B%3Ct-1%3E%7D+%5C%5C%5C%5C+%5Chat%7By%7D%5E%7B%3Ct%3E%7D%3Dsoftmax%28W_ya%5E%7B%3Ct%3E%7D%2Bb_y%29+&bg=ffffff&fg=000&s=1&c=20201002)
GRU 的輸入  和 true labels
和 true labels  的維度如下:
的維度如下:

在 GRU cell 中,各個變數的維度如下:
|  | |  |
![[a^{<t-1>},x^{<t>}]](https://s0.wp.com/latex.php?latex=%5Ba%5E%7B%3Ct-1%3E%7D%2Cx%5E%7B%3Ct%3E%7D%5D&bg=ffffff&fg=000&s=0&c=20201002) |  |  |  |
 |  | 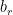 |  |
 | | 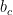 | |
 | |  | |
 |  |  |  |
以下是 GRU 的 forward propagation 的實作。
class GRU:
def cell_forward(self, xt, at_prev, parameters):
"""
Implements a single forward step for the GRU-cell.
Parameters
----------
xt: (ndarray (n_x, m)) - input data for the current timestep
at_prev: (ndarray (n_a, m)) - hidden state from the previous timestep
parameters: (dict) - dictionary containing the weights and biases of the GRU network
Wu: (ndarray (n_a, n_a + n_x)) - weights of the update gate
bu: (ndarray (n_a, 1)) - biases of the update gate
Wr: (ndarray (n_a, n_a + n_x)) - weights of the reset gate
br: (ndarray (n_a, 1)) - biases of the reset gate
Wc: (ndarray (n_a, n_a + n_x)) - weights of the candidate value
bc: (ndarray (n_a, 1)) - biases of the candidate value
Wy: (ndarray (n_y, n_a)) - weights of the output layer
by: (ndarray (n_y, 1)) - biases of the output layer
Returns
-------
at: (ndarray (n_a, m)) - hidden state for the current timestep
y_hat_t: (ndarray (n_y, m)) - prediction for the current timestep
cache: (tuple) - values needed for the backward pass
"""
Wu, bu = parameters["Wu"], parameters["bu"] # update gate weights and biases
Wr, br = parameters["Wr"], parameters["br"] # reset gate weights and biases
Wc, bc = parameters["Wc"], parameters["bc"] # candidate value weights and biases
Wy, by = parameters["Wy"], parameters["by"] # prediction weights and biases
concat = np.concatenate((at_prev, xt), axis=0)
ut = sigmoid(Wu @ concat + bu) # update gate
rt = sigmoid(Wr @ concat + br) # reset gate
cct = tanh(Wc @ np.concatenate((rt * at_prev, xt), axis=0) + bc) # candidate value
at = ut * cct + (1 - ut) * at_prev # hidden state
zyt = Wy @ at + by
y_hat_t = softmax(zyt)
cache = (at, at_prev, ut, rt, cct, xt, y_hat_t, zyt)
return at, y_hat_t, cache
def forward(self, X, a0, parameters):
"""
Implements the forward pass of the GRU network.
Parameters
----------
X: (ndarray (n_x, m, T_x)) - input data for each time step
a0: (ndarray (n_a, m)) - initial hidden state
parameters: (dict) - dictionary containing the weights and biases of the GRU network
Wu: (ndarray (n_a, n_a + n_x)) - weights of the update gate
bu: (ndarray (n_a, 1)) - biases of the update gate
Wr: (ndarray (n_a, n_a + n_x)) - weights of the reset gate
br: (ndarray (n_a, 1)) - biases of the reset gate
Wc: (ndarray (n_a, n_a + n_x)) - weights of the candidate value
bc: (ndarray (n_a, 1)) - biases of the candidate value
Wy: (ndarray (n_y, n_a)) - weights of the output layer
by: (ndarray (n_y, 1)) - biases of the output layer
Returns
-------
A: (ndarray (n_a, m, T_x)) - hidden states for each timestep
Y_hat: (ndarray (n_y, m, T_x)) - predictions for each timestep
caches: (list) - values needed for the backward pass
"""
caches = []
Wy = parameters["Wy"]
x_x, m, T_x = X.shape
n_y, n_a = Wy.shape
A = np.zeros((n_a, m, T_x))
Y_hat = np.zeros((n_y, m, T_x))
at_prev = a0
for t in range(T_x):
at_prev, y_hat_t, cache = self.cell_forward(X[:, :, t], at_prev, parameters)
A[:, :, t] = at_prev
Y_hat[:, :, t] = y_hat_t
caches.append(cache)
return A, Y_hat, caches損失函數(Loss Function)
此文章中,我們使用 softmax 來輸出  ,因此使用 cross-entropy loss 作為它的 loss function。關於 cross-entropy loss 的公式與實作,請參考以下文章。
,因此使用 cross-entropy loss 作為它的 loss function。關於 cross-entropy loss 的公式與實作,請參考以下文章。
反向傳播(Backward Propagation)
GRU 的 backpropagation 有點複雜。我們必須計算每一個參數的偏導數。尤其在計算  時,我們還要考慮它上一個 timestep 時的值,也就是 backpropagation through time(BPTT)。
時,我們還要考慮它上一個 timestep 時的值,也就是 backpropagation through time(BPTT)。

以下求取 output layer 裡的偏導數。

以下是求取 reset gate、update gate、以及 candidate hidden state 的偏導數。

以下求取所有參數 的偏導數。

以下求取剩餘的偏導數。

以上是在每個 time step 中求取所有偏導數的方式。我們最後還要將所有求取的偏導數加總起來。

以下是 GRU 的 backward propagation 的實作。
class GRU:
def cell_backward(self, y, dat, cache, parameters):
"""
Implements a single backward step for the GRU-cell.
Parameters
----------
y: (ndarray (n_y, m)) - true labels for the current timestep
dat: (ndarray (n_a, m)) - gradient of the hidden state for the current timestep
cache: (tuple) - values needed for the backward pass
parameters: (dict) - dictionary containing the weights and biases of the GRU network
Wu: (ndarray (n_a, n_a + n_x)) - weights of the update gate
bu: (ndarray (n_a, 1)) - biases of the update gate
Wr: (ndarray (n_a, n_a + n_x)) - weights of the reset gate
br: (ndarray (n_a, 1)) - biases of the reset gate
Wc: (ndarray (n_a, n_a + n_x)) - weights of the candidate value
bc: (ndarray (n_a, 1)) - biases of the candidate value
Wy: (ndarray (n_y, n_a)) - weights of the output layer
by: (ndarray (n_y, 1)) - biases of the output layer
Returns
-------
gradients: (dict) - dictionary containing the gradients of the weights and biases of the GRU network
dWu: (ndarray (n_a, n_a + n_x)) - gradients of the weights of the update gate
dbu: (ndarray (n_a, 1)) - gradients of the biases of the update gate
dWr: (ndarray (n_a, n_a + n_x)) - gradients of the weights of the reset gate
dbr: (ndarray (n_a, 1)) - gradients of the biases of the reset gate
dWc: (ndarray (n_a, n_a + n_x)) - gradients of the weights of the candidate value
dbc: (ndarray (n_a, 1)) - gradients of the biases of the candidate value
dWy: (ndarray (n_y, n_a)) - gradients of the weights of the output layer
dby: (ndarray (n_y, 1)) - gradients of the biases of the output
"""
at, at_prev, ut, rt, cct, xt, y_hat_t, zyt = cache
n_a, m = at.shape
dzy = y_hat_t - y
dWy = dzy @ at.T
dby = np.sum(dzy, axis=1, keepdims=True)
dat = parameters["Wy"].T @ dzy + dat
dcct = dat * ut * (1 - cct ** 2) # dn_t
dut = dat * (cct - at_prev) * ut * (1 - ut)
dat_prev = dat * (1 - ut)
dcct_ra_x = parameters["Wc"].T @ dcct
dcct_r_at_prev = dcct_ra_x[:n_a, :]
dcct_xt = dcct_ra_x[n_a:, :]
drt = (dcct_r_at_prev * at_prev) * rt * (1 - rt)
concat = np.concatenate((at_prev, xt), axis=0)
dWc = dcct @ np.concatenate((rt * at_prev, xt), axis=0).T
dbc = np.sum(dcct, axis=1, keepdims=True)
dWr = drt @ concat.T
dbr = np.sum(drt, axis=1, keepdims=True)
dWu = dut @ concat.T
dbu = np.sum(dut, axis=1, keepdims=True)
dat_prev = (
dat_prev + dcct_r_at_prev * rt + parameters["Wr"][:, :n_a].T @ drt + parameters["Wu"][:, :n_a].T @ dut
)
dxt = (
dcct_xt + parameters["Wr"][:, n_a:].T @ drt + parameters["Wu"][:, n_a:].T @ dut
)
gradients = {
"dWu": dWu, "dbu": dbu, "dWr": dWr, "dbr": dbr, "dWc": dWc, "dbc": dbc, "dWy": dWy, "dby": dby,
"dat_prev": dat_prev, "dxt": dxt
}
return gradients
def backward(self, X, Y, parameters, caches):
"""
Implements the backward pass of the GRU network.
Parameters
----------
X: (ndarray (n_x, m, T_x)) - input data for each time step
Y: (ndarray (n_y, m, T_x)) - true labels for each time step
parameters: (dict) - dictionary containing the weights and biases of the GRU network
Wu: (ndarray (n_a, n_a + n_x)) - weights of the update gate
bu: (ndarray (n_a, 1)) - biases of the update gate
Wr: (ndarray (n_a, n_a + n_x)) - weights of the reset gate
br: (ndarray (n_a, 1)) - biases of the reset gate
Wc: (ndarray (n_a, n_a + n_x)) - weights of the candidate value
bc: (ndarray (n_a, 1)) - biases of the candidate value
Wy: (ndarray (n_y, n_a)) - weights of the output layer
by: (ndarray (n_y, 1)) - biases of the output layer
caches: (list) - values needed for the backward pass
Returns
-------
gradients: (dict) - dictionary containing the gradients of the weights and biases of the GRU network
dWu: (ndarray (n_a, n_a + n_x)) - gradients of the weights of the update gate
dbu: (ndarray (n_a, 1)) - gradients of the biases of the update gate
dWr: (ndarray (n_a, n_a + n_x)) - gradients of the weights of the reset gate
dbr: (ndarray (n_a, 1)) - gradients of the biases of the reset gate
dWc: (ndarray (n_a, n_a + n_x)) - gradients of the weights of the candidate value
dbc: (ndarray (n_a, 1)) - gradients of the biases of the candidate value
dWy: (ndarray (n_y, n_a)) - gradients of the weights of the output layer
dby: (ndarray (n_y, 1)) - gradients of the biases of the output layer
"""
n_x, m, T_x = X.shape
a1, a0, u0, r1, cc1, x1, y_hat_1, zyt1 = caches[0]
Wu, Wr, Wc, Wy = parameters["Wu"], parameters["Wr"], parameters["Wc"], parameters["Wy"]
bu, br, bc, by = parameters["bu"], parameters["br"], parameters["bc"], parameters["by"]
gradients = {
"dWu": np.zeros_like(Wu), "dbu": np.zeros_like(bu), "dWr": np.zeros_like(Wr), "dbr": np.zeros_like(br),
"dWc": np.zeros_like(Wc), "dbc": np.zeros_like(bc), "dWy": np.zeros_like(Wy), "dby": np.zeros_like(by),
}
dat = np.zeros_like(a0)
for t in reversed(range(T_x)):
grads = self.cell_backward(Y[:, :, t], dat, caches[t], parameters)
gradients["dWu"] += grads["dWu"]
gradients["dbu"] += grads["dbu"]
gradients["dWr"] += grads["dWr"]
gradients["dbr"] += grads["dbr"]
gradients["dWc"] += grads["dWc"]
gradients["dbc"] += grads["dbc"]
gradients["dWy"] += grads["dWy"]
gradients["dby"] += grads["dby"]
dat = grads["dat_prev"]
return gradients整合全部
以下的程式碼實作了一次完整的訓練流程。首先,我們將訓練資料傳入 forward propagation,計算 loss,然後再傳入 backward propagation,最終得到 gradients。為了防止 exploding gradients 的發生,我們將對 gradients 做 clipping。然後,再用它來更新參數。這就是一次完整的訓練。
class GRU:
def optimize(self, X, Y, a_prev, parameters, learning_rate, clip_value):
"""
Implements the forward and backward pass of the GRU network.
Parameters
----------
X: (ndarray (n_x, m, T_x)) - input data for each time step
Y: (ndarray (n_y, m, T_x)) - true labels for each time step
a_prev: (ndarray (n_a, m)) - initial hidden state
parameters: (dict) - dictionary containing the weights and biases of the GRU network
Wu: (ndarray (n_a, n_a + n_x)) - weights of the update gate
bu: (ndarray (n_a, 1)) - biases of the update gate
Wr: (ndarray (n_a, n_a + n_x)) - weights of the reset gate
br: (ndarray (n_a, 1)) - biases of the reset gate
Wc: (ndarray (n_a, n_a + n_x)) - weights of the candidate value
bc: (ndarray (n_a, 1)) - biases of the candidate value
Wy: (ndarray (n_y, n_a)) - weights of the output layer
by: (ndarray (n_y, 1)) - biases of the output layer
learning_rate: (float) - learning rate
clip_value: (float) - maximum value to clip the gradients
Returns
-------
at: (ndarray (n_a, m)) hidden state for the last time step
loss: (float) - the cross-entropy
"""
A, Y_hat, caches = self.forward(X, a_prev, parameters)
loss = self.compute_loss(Y_hat, Y)
gradients = self.backward(X, Y, parameters, caches)
gradients = self.clip(gradients, clip_value)
self.update_parameters(parameters, gradients, learning_rate)
at = A[:, :, -1]
return at, loss範例
接下來,我們將 GRU 設計為一個 character-level language model。訓練資料是一段莎士比亞的文章。它會一次訓練一個字元,所以 sequence length 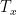 就會是輸入字元的長度,並且使用 one-hot encoding 來編碼每一個字元。這部分的細節請參考以下文章,因為本文章與已下文章使用相同的範例。
就會是輸入字元的長度,並且使用 one-hot encoding 來編碼每一個字元。這部分的細節請參考以下文章,因為本文章與已下文章使用相同的範例。
使用此 GRU 的範例如下:
if __name__ == "__main__":
with open("shakespeare.txt", "r") as file:
text = file.read()
chars = sorted(list(set(text)))
vocab_size = len(chars)
char_to_idx = {ch: i for i, ch in enumerate(chars)}
idx_to_char = {i: ch for i, ch in enumerate(chars)}
gru = GRU(64, vocab_size, vocab_size)
losses = gru.train(text, char_to_idx, num_iterations=100, learning_rate=0.01, clip_value=5)
generated_text = gru.sample("T", char_to_idx, idx_to_char, num_chars=100)
print(generated_text)結語
GRU 比標準 RNN 更能學習長期依賴關係,但比 LSTM 結構更簡單、計算更高效。但是,由於 GRU 的結構較為簡單,因此 LSTM 在學習長期依賴時,表現會更好。因此,我們必須要根據使用的場景和數據的長度,來決定該使用 LSTM 或 GRU。
參考
- Junyoung Chung, Caglar Gulcehre, KyungHyum Cho, and Yoshua Bengio. 2014. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. CoRR, abs/1412.3555.
- Andrew Ng, Deep Learning Specialization, Coursera.









