
在機率模型與機器學習中,熵(entropy)是用來量化不確定性的核心概念。它不僅描述資料本身的隨機性,也隱含了在預測與建模過程中所必須付出的最低資訊成本。許多看似不同的學習目標,例如對數概似(log-likelihood)最大化或損失函數(loss function)的設計,其實都可以回溯到 entropy 的觀點來理解。
Table of Contents
資訊本體(Self-Information)
在資訊理論中(information theory),資訊本體(self-information)是指當一個特定事件發生時,依其發生機率所對應的資訊量,也常被稱為 information content。此概念源自 Claude Shannon 於 1948 年所建立的資訊理論框架,是整個理論體系中最基礎的定義之一。
假設事件  的發生機率為
的發生機率為 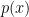 ,則其 self-information
,則其 self-information  定義為:
定義為:

其中對數的基底決定資訊量的單位。若使用以 2 為底的對數,資訊量的單位為 bit;若使用自然對數,則單位為 nat。本文後續皆以  為例。
為例。
我們來看一個直觀的例子。假設 David 考試及格的機率為  ,而 Wayne 考試及格的機率為
,而 Wayne 考試及格的機率為  。當 David 考試及格時,這是一個相對少見的事件,因此會帶來較高的驚訝感。相反地,當 Wayne 考試及格時,由於其發生機率很高,我們幾乎不會感到意外。這種直覺上的驚訝程度,正是 self-information 所試圖量化的對象。對應的資訊量如下:
。當 David 考試及格時,這是一個相對少見的事件,因此會帶來較高的驚訝感。相反地,當 Wayne 考試及格時,由於其發生機率很高,我們幾乎不會感到意外。這種直覺上的驚訝程度,正是 self-information 所試圖量化的對象。對應的資訊量如下:

可以看到,發生機率較低的事件,具有較高的 self-information;反之,發生機率越高,其資訊量越低。換言之,self-information 量化了事件發生時所帶來的驚訝程度,因此在許多文獻中也被稱為驚訝度(surprisal)。
我們也可以對一個事件的資訊量編碼。假設一個集合有 8 個等機率的事件  ,對於每一個事件,我們需要用 3 bits 來編碼。
,對於每一個事件,我們需要用 3 bits 來編碼。
除了作為驚訝程度的度量之外,self-information 也與編碼(coding)有直接關係。假設我們有一個由 8 個等機率事件所組成的集合 ,則每一個事件都可以用 3 個 bits 來表示:

由於這些事件是等機率的,因此  ,每個事件的 self-information 為:
,每個事件的 self-information 為:

也就是說,在此情況下,每一個事件所攜帶的資訊量正好對應到其最短的固定長度編碼,為 3 bits。
若事件的發生機率並不相同,則固定長度編碼將不再是理想選擇。根據資訊理論的結果,最佳的編碼策略應該讓高機率事件使用較短的 bit 表示,而低機率事件使用較長的 bit 表示。在這樣的理想編碼(optimal coding)設定下,self-information  可以被視為該事件在最佳平均意義下所需的最小編碼長度。
可以被視為該事件在最佳平均意義下所需的最小編碼長度。
熵(Entropy)
考慮一個由事件集合  所構成的隨機來源,其中每個事件
所構成的隨機來源,其中每個事件  的發生機率為
的發生機率為 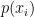 。在此設定下,我們已知整體的機率分佈
。在此設定下,我們已知整體的機率分佈  ,但在事件實際發生之前,無法預先得知究竟是哪一個事件 會出現,因此也無法事前確定將會對應到哪一個特定的 self-information。
,但在事件實際發生之前,無法預先得知究竟是哪一個事件 會出現,因此也無法事前確定將會對應到哪一個特定的 self-information。
換言之,在事件發生之前,系統所呈現的是一種不確定狀態,而我們關心的並非單一事件的資訊量,而是這個隨機來源整體而言,平均會帶來多少資訊。在已知機率分佈的前提下,唯一合理且一致的量化方式,便是對所有可能事件的 self-information 依其發生機率取期望值。
基於上述動機,熵(entropy)被定義為隨機變數之 self-information 的期望值:
![\displaystyle H(X) = \mathbb{E}_{x \sim p} [I(x)] = \sum_{x \in X} p(x) (- \log p(x)) = - \sum_{x \in X} p(x) \log p(x)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+H%28X%29+%3D+%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%7D+%5BI%28x%29%5D+%3D+%5Csum_%7Bx+%5Cin+X%7D+p%28x%29+%28-+%5Clog+p%28x%29%29+%3D+-+%5Csum_%7Bx+%5Cin+X%7D+p%28x%29+%5Clog+p%28x%29+&bg=ffffff&fg=000&s=1&c=20201002)
因此,entropy 衡量的是,在事件尚未發生之前,從該機率分佈中隨機抽取一個結果時,平均而言所需的資訊量。此一量由 Claude Shannon 於 1948 年提出,作為資訊理論的基礎概念之一。為了與其他廣義 entropy 形式加以區別,後來通常稱為 Shannon entropy。
從定義上可以清楚看出 entropy 與 self-information 之間的關係:
- Self-information 描述的是,某一個特定事件一旦發生時,所帶來的資訊量。
- Entropy 描述的是,整個隨機來源在事件發生之前的平均資訊量,亦即其不確定性的程度。
我們再回到先前 David 與 Wayne 考試的例子。令隨機變數  表示考試結果,其事件集合為:
表示考試結果,其事件集合為:

則 David 與 Wayne 的考試結果 entropy 分別為:
![H_{\text{D}}(X) = \mathbb{E}_{x \sim p(x)} [I(x)] \\\\ \phantom{H_{\text{D}}(X)} = \sum_{x \in X} p(x) (- \log_2 p(x)) \\\\ \phantom{H_{\text{D}}(X)} = 0.3 (-\log_2 0.3) + 0.7 (-\log_2 0.7) \approx 0.88 \\\\ H_{\text{W}}(X) = 0.9 (-\log_2 0.9) + 0.1 (-\log_2 0.1) \approx 0.47](https://s0.wp.com/latex.php?latex=H_%7B%5Ctext%7BD%7D%7D%28X%29+%3D+%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%28x%29%7D+%5BI%28x%29%5D+%5C%5C%5C%5C+%5Cphantom%7BH_%7B%5Ctext%7BD%7D%7D%28X%29%7D+%3D+%5Csum_%7Bx+%5Cin+X%7D+p%28x%29+%28-+%5Clog_2+p%28x%29%29+%5C%5C%5C%5C+%5Cphantom%7BH_%7B%5Ctext%7BD%7D%7D%28X%29%7D+%3D+0.3+%28-%5Clog_2+0.3%29+%2B+0.7+%28-%5Clog_2+0.7%29+%5Capprox+0.88+%5C%5C%5C%5C+H_%7B%5Ctext%7BW%7D%7D%28X%29+%3D+0.9+%28-%5Clog_2+0.9%29+%2B+0.1+%28-%5Clog_2+0.1%29+%5Capprox+0.47+&bg=ffffff&fg=000&s=1&c=20201002)
可以看到,Wayne 的考試結果 entropy 明顯較低。這表示其結果高度可預測,事件的機率質量大多集中於及格,因此在事件發生前所面臨的不確定性也相對較小。相較之下,David 的考試結果較為分散,其 entropy 較高,反映出結果的不確定性較大。
條件熵(Conditional Entropy)
考慮兩個離散隨機變數  。在沒有任何額外資訊的情況下,隨機變數
。在沒有任何額外資訊的情況下,隨機變數  的不確定性可由其 entropy
的不確定性可由其 entropy  來衡量。然而,若我們事先已經觀察到 的取值,則對 的機率分佈將由原本的邊際分佈
來衡量。然而,若我們事先已經觀察到 的取值,則對 的機率分佈將由原本的邊際分佈  ,更新為條件分佈
,更新為條件分佈  。在此情況下, 的不確定性理應重新評估。
。在此情況下, 的不確定性理應重新評估。
若已知  ,則在此條件下, 的 self-information 與 entropy 分別定義為:
,則在此條件下, 的 self-information 與 entropy 分別定義為:
![I(y \mid x) = -\log p(y \mid x) \\\\ \displaystyle H(Y \mid X=x) = \mathbb{E}_{y \sim p(\cdot \mid x)} [I(y \mid x)] = \sum_{y \in Y} p(y \mid x) (-\log p(y \mid x))](https://s0.wp.com/latex.php?latex=I%28y+%5Cmid+x%29+%3D+-%5Clog+p%28y+%5Cmid+x%29+%5C%5C%5C%5C+%5Cdisplaystyle+H%28Y+%5Cmid+X%3Dx%29+%3D+%5Cmathbb%7BE%7D_%7By+%5Csim+p%28%5Ccdot+%5Cmid+x%29%7D+%5BI%28y+%5Cmid+x%29%5D+%3D+%5Csum_%7By+%5Cin+Y%7D+p%28y+%5Cmid+x%29+%28-%5Clog+p%28y+%5Cmid+x%29%29+&bg=ffffff&fg=000&s=1&c=20201002)
由於在事前我們並不知道 會取哪一個值,因此還需要再對 的所有可能取值取期望。由此,條件熵(conditional entropy)被定義為:
然而,在事件發生之前,我們並不知道 將會取哪一個值。因此,若要衡量,在已知 的前提下, 的整體平均不確定性,還需要再對 的所有可能取值依其機率加權取期望。基於此動機,條件熵(conditional entropy)被定義為:
![\displaystyle H(Y \mid X) = \mathbb{E}_{x \sim p} [H(Y \mid X=x)] \\\\ \hphantom{H(Y \mid X)} = \mathbb{E}_{x \sim p} \Big[ \mathbb{E}_{y \sim p(\cdot \mid x)} [I(y \mid x)] \Big] \\\\ \hphantom{H(Y \mid X)} = \sum_{x \in X} \sum_{y \in Y} p(x, y) (-\log p(y \mid x))](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+H%28Y+%5Cmid+X%29+%3D+%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%7D+%5BH%28Y+%5Cmid+X%3Dx%29%5D+%5C%5C%5C%5C+%5Chphantom%7BH%28Y+%5Cmid+X%29%7D+%3D+%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%7D+%5CBig%5B+%5Cmathbb%7BE%7D_%7By+%5Csim+p%28%5Ccdot+%5Cmid+x%29%7D+%5BI%28y+%5Cmid+x%29%5D+%5CBig%5D+%5C%5C%5C%5C+%5Chphantom%7BH%28Y+%5Cmid+X%29%7D+%3D+%5Csum_%7Bx+%5Cin+X%7D+%5Csum_%7By+%5Cin+Y%7D+p%28x%2C+y%29+%28-%5Clog+p%28y+%5Cmid+x%29%29+&bg=ffffff&fg=000&s=1&c=20201002)
因此,conditional entropy 衡量的是,在已知隨機變數 的情況下,對 平均而言所需的資訊量。換言之,在已知隨機變數 的情況下,對 的平均不確定性。
Conditional entropy 和 Shannon entropy 的關係是:
 :在完全不知道任何資訊時,對 的不確定性。
:在完全不知道任何資訊時,對 的不確定性。- :在已知 之後,對 剩下的不確定性。
 :在已知
:在已知 由於額外資訊只能減少、而不會增加不確定性,因此必然有:

若 與 彼此獨立,亦即  ,則觀察 並不會提供任何關於 的資訊,此時有:
,則觀察 並不會提供任何關於 的資訊,此時有:

回到先前 David 與 Wayne 考試的例子。若兩人分屬不同班級,甚至不同年級,其考試結果彼此無關、可視為獨立,則觀察 Wayne 的考試結果,並不會改變我們對 David 成績的判斷,因此:

然而,若 David 與 Wayne 同班、考同一份試卷,則情況便不同。假設當 Wayne 考不及格時,往往代表該次試卷特別困難,這將使 David 考及格的機率顯著下降。此時,觀察到  ,確實降低了我們對 David 考試結果的不確定性。
,確實降低了我們對 David 考試結果的不確定性。
假設在這樣的情境下:

則在條件 之下,David 考試結果的 entropy 為:

可以看到,在給定 Wayne 考不及格這個資訊後,David 的考試結果幾乎可以確定為不及格,其不確定性顯著降低。這個例子清楚說明了,conditional entropy 刻畫的正是,在已知部分資訊後,剩餘的不確定性。
資訊增益(Information Gain)
考慮兩個離散隨機變數 。
- 在未知 的情況下,隨機變數 的不確定性可由其 entropy 來衡量。
- 在已知某一特定事件 的情況下, 的機率分佈更新為 ,其剩餘的不確定性則為 。
 。
。因此,在觀察到特定事件 之後, 的不確定性所減少的量,便可自然地定義為資訊增益(information gain):

Information gain 衡量的是,在觀察到特定結果 之後,我們對 所實際獲得的資訊量,亦即 的不確定性被消除的程度。若觀察到 後, 的分佈變得更加集中,則 information gain 便會較大;反之,若條件分佈與原本分佈幾乎相同,則 information gain 接近於零。
我們再回到先前 David 與 Wayne 的考試例子。假設在不知道 Wayne 考試結果之前,David 考試結果的 entropy 為:

而在觀察到 Wayne 考不及格的情況下,David 考試結果的條件 entropy 為:

則在得知 之後,對 David 考試結果所獲得的 information gain 為:

這表示,單是觀察到 Wayne 考不及格這一個事件,便使我們對 David 考試結果的平均不確定性減少了約 0.69。此例清楚說明,information gain 描述的正是,某一具體觀測結果,對另一隨機變數所帶來的資訊價值。
互資訊(Mutual Information)
由於在事件發生之前,我們並不知道隨機變數 會取哪一個具體值,因此,若要衡量 對 在整體平均意義下所能提供的資訊量,便需要對所有可能的 依其發生機率取期望。此時,information gain 的期望值便形成了互資訊(mutual information):
![I(Y ; X) = \mathbb{E}_{x \sim p} [ IG(Y ; X = x)] = H(Y) - H(Y \mid X)](https://s0.wp.com/latex.php?latex=I%28Y+%3B+X%29+%3D+%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%7D+%5B+IG%28Y+%3B+X+%3D+x%29%5D+%3D+H%28Y%29+-+H%28Y+%5Cmid+X%29+&bg=ffffff&fg=000&s=1&c=20201002)
Mutual information 具有對稱性,因此有:

這表示 mutual information 並不偏向任何一個隨機變數,而是描述 與 之間所共享的資訊量。亦即,其中一方能夠消除對另一方不確定性的那一部分。
從另一個角度來看,mutual information 也可以寫成以下與機率分佈直接相關的等價形式:

此形式清楚顯示,mutual information 衡量的是,聯合分佈  與獨立假設下分佈
與獨立假設下分佈  之間的差異。若 與 相互獨立,則兩者相等,互資訊為零。
之間的差異。若 與 相互獨立,則兩者相等,互資訊為零。
回到先前 David 與 Wayne 的考試例子。假設:
- ,。
- 。
- 當 Wayne 不及格時, 。
- 當 Wayne 及格時, 。
 ,
, 。
。 。
。 。
。 。
。首先,David 考試結果的 entropy 為:

接著計算在不同條件下的 entropy:

再對 Wayne 的考試結果取期望,可得 conditional entropy:

因此,David 與 Wayne 考試結果之間的 mutual information 為:

這表示 Wayne 的考試結果確實能提供關於 David 的資訊。當 Wayne 不及格時,David 幾乎必定不及格;當 Wayne 及格時,David 及格的機率也略為上升。然而,由於 Wayne 幾乎總是及格,使得高度資訊性的事件發生機率極低,因此在整體平均意義下,mutual information 仍然相當有限。
交叉熵(Cross-Entropy)
我們已經知道,可以使用 Shannon entropy 來衡量一個機率分佈 的平均資訊量:
![H(X) = \mathbb{E}_{x \sim p} [ I(x) ] = \mathbb{E}_{x \sim p} [ -\log p(x) ]](https://s0.wp.com/latex.php?latex=H%28X%29+%3D+%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%7D+%5B+I%28x%29+%5D+%3D+%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%7D+%5B+-%5Clog+p%28x%29+%5D+&bg=ffffff&fg=000&s=1&c=20201002)
然而,在實務情境中,真實資料的機率分佈 往往是未知的。我們通常只能透過某個模型,得到一個近似分佈  ,用來描述或預測資料的生成行為。換言之,雖然資料實際上是依據 產生的,但我們在進行編碼或預測時,卻是依據
,用來描述或預測資料的生成行為。換言之,雖然資料實際上是依據 產生的,但我們在進行編碼或預測時,卻是依據  來分配機率。
來分配機率。
在此情況下,一個自然的問題是,當資料來自真實分佈 ,卻使用模型分佈 來描述事件時,平均需要多少資訊量?
基於這個動機,交叉熵(cross-entropy)被定義為:
![\displaystyle H(p, q) = \mathbb{E}_{x \sim p} [-\log q(x)] = \sum_{x \in X} p(x) (-\log q(x))](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+H%28p%2C+q%29+%3D+%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%7D+%5B-%5Clog+q%28x%29%5D+%3D+%5Csum_%7Bx+%5Cin+X%7D+p%28x%29+%28-%5Clog+q%28x%29%29+&bg=ffffff&fg=000&s=1&c=20201002)
因此,cross-entropy 衡量的是,在資料由真實分佈 所產生的前提下,若使用模型分佈 來進行編碼或預測,平均所需承擔的資訊成本。
若模型分佈剛好等於真實分佈,即  ,則 cross-entropy 會退化為 entropy 本身:
,則 cross-entropy 會退化為 entropy 本身:

從直覺角度來看,可以整理出以下關係:
- 若模型分佈 與真實分佈 非常接近,則 會略大於、但非常接近 。
- 若模型分佈 與真實分佈 差異很大,則 會顯著大於 。
因此,entropy  可被視為 cross-entropy
可被視為 cross-entropy  的理論下界:
的理論下界:
 。
。
此不等式反映了一個事實,使用錯誤的機率分佈來描述資料,必然會付出額外的平均資訊成本。
讓我們再次回到 David 的考試例子,但這次只考慮 David 一人。假設隔壁班老師看到 David 上課時看著前方(其實在發呆),誤以為他相當認真,於是主觀認為 David 及格的機率為 0.8。此時,我們有:

首先,真實分佈 的 entropy 為:

這代表,若班導師使用正確的分佈 來預測 David 的考試結果,長期平均而言,每次所承受的 surprisal 為 0.88。
接著,若隔壁班老師使用錯誤的模型分佈 來預測,則其 cross-entropy 為:

隔壁班老師使用錯誤的模型分佈 來預測 David 的考試結果時,平均所承受的 surprisal 為 1.72。換言之,隔壁班老師會比班導師多承受  的 surprisal。
的 surprisal。
也就是說,隔壁班老師在長期預測下,平均每次需承受 1.72 的 surprisal。相較於使用正確分佈的情況,他將額外多付出 的資訊成本。
Kullback-Leibler Divergence(KL Divergence)
我們已經知道,對於一個真實機率分佈 ,其 entropy 定義為:

這個量描述的是,在已完全知道真實分佈 的前提下,平均仍然無法避免的不確定性。
另一方面,當資料仍然來自真實分佈 ,但我們卻使用另一個模型分佈 來描述或編碼資料時,其平均資訊成本由 cross-entropy 給出:

此時, 與 之間的差值,正好對應到一個問題。即,在資料本身的不可避免不確定性之外,有多少額外的資訊成本,是因為使用了不正確的分佈 所導致的?
基於這個動機,Kullback–Leibler divergence(KL divergence)被定義為 cross-entropy 與 entropy 之差:

因此,KL divergence 衡量的是,當真實分佈為 ,卻使用 來描述資料時,相對於使用正確分佈 ,平均而言多付出的資訊量。也正因為它描述的是,相對於正確描述所增加的代價,在資訊理論中,KL divergence 亦被稱為相對熵(relative entropy)。
需要特別注意的是,KL divergence 雖然常被用來衡量兩個分佈之間的差異,但它並不是一個距離(distance)。一般而言, ,且不滿足對稱性與三角不等式。不過,從資訊論與機率建模的角度來看,它依然是最自然、也最具操作意義的不匹配度量。
,且不滿足對稱性與三角不等式。不過,從資訊論與機率建模的角度來看,它依然是最自然、也最具操作意義的不匹配度量。
再次回到 David 的考試例子。班導師使用真實分佈 來預測 David 的考試結果,而隔壁班老師則使用錯誤的模型分佈 。前面我們已計算得:

因此,這兩種描述策略之間,平均每次所需資訊量的差異為:

這表示,隔壁班老師因為使用了錯誤的機率分佈來預測 David 的考試結果,平均每次需要多付出 0.84 的資訊成本。這個數值,正是模型分佈 相對於真實分佈 的資訊浪費程度。
最大概似估計(Maximum Likelihood Estimation, MLE)
對於一組獨立同分佈(independent and identically distributed, i.i.d.)的觀測資料  。在給定模型分佈
。在給定模型分佈  的情況下,模型對整個資料集的 likelihood 定義為:
的情況下,模型對整個資料集的 likelihood 定義為:

其中,i.i.d. 指的是每一筆資料彼此獨立(independent),且皆由同一個機率分佈(identically distributed)隨機抽樣而得。
最大概似估計(Maximum Likelihood Estimation, MLE)的目標,是選擇一組參數  ,使得模型對已觀察到的資料給出最大的機率:
,使得模型對已觀察到的資料給出最大的機率:

由於乘積形式在數值計算與最佳化上不便處理,實務上通常對 likelihood 取對數,得到 log-likelihood:

因此,MLE 可等價地寫為:

將上述最大化問題乘以 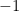 ,即可轉為等價的最小化問題:
,即可轉為等價的最小化問題:

其中, 正是事件 在模型分佈 下的 self-information。因此,MLE 的意義可以重新表述為,選擇一組模型參數,使模型對觀察到的資料所對應的 self-information 總和最小。
正是事件 在模型分佈 下的 self-information。因此,MLE 的意義可以重新表述為,選擇一組模型參數,使模型對觀察到的資料所對應的 self-information 總和最小。
換言之,MLE 並非只是一個機率最大化技巧,而是在資訊論意義下,嘗試用模型分佈對資料進行最有效率的描述。
然而,上述 log-likelihood 仍然只反映了一次有限抽樣結果。理想上,我們真正關心的是,模型在真實資料生成分佈 下,平均而言所需付出的資訊成本。也就是以下期望值:
![\mathbb{E}_{x \sim p}[-\log q\theta(x)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%7D%5B-%5Clog+q%5Ctheta%28x%29%5D+&bg=ffffff&fg=000&s=1&c=20201002)
但由於真實分佈 未知,這個期望無法直接計算。在目前僅能觀察到有限資料的情況下,唯一可行的做法,是使用由樣本所誘導出的經驗分佈(empirical distribution)來近似真實分佈:

根據大數法則,當樣本數  足夠大,且資料為 i.i.d. 時,對任意可積函數
足夠大,且資料為 i.i.d. 時,對任意可積函數  ,由 empirical distribution 所計算的期望值,會收斂至其在真實分佈 下的期望值:
,由 empirical distribution 所計算的期望值,會收斂至其在真實分佈 下的期望值:
![\displaystyle \mathbb{E}_{x \sim \hat{p}_n}[f(x)] = \frac{1}{n} \sum_{i=1}^n f(x_i) \longrightarrow \mathbb{E}_{x \sim p}[f(x)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D_%7Bx+%5Csim+%5Chat%7Bp%7D_n%7D%5Bf%28x%29%5D+%3D+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5En+f%28x_i%29+%5Clongrightarrow+%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%7D%5Bf%28x%29%5D+&bg=ffffff&fg=000&s=1&c=20201002)
將 取為  ,即可得到:
,即可得到:
![\displaystyle \frac{1}{n} \sum_{i=1}^n -\log q_\theta(x_i) \approx \mathbb{E}_{x \sim p}\big[-\log q_\theta(x)\big] = H(p, q_\theta)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5En+-%5Clog+q_%5Ctheta%28x_i%29+%5Capprox+%5Cmathbb%7BE%7D_%7Bx+%5Csim+p%7D%5Cbig%5B-%5Clog+q_%5Ctheta%28x%29%5Cbig%5D+%3D+H%28p%2C+q_%5Ctheta%29+&bg=ffffff&fg=000&s=1&c=20201002)
也就是說,log-likelihood 的 empirical average,正是在近似真實分佈 與模型分佈 之間的 cross-entropy。
因此,最大化 log-likelihood 等價於最小化 cross-entropy:

回顧先前的關係式:

其中, 僅由真實資料生成分佈 所決定,與模型參數 無關。故在以 為最佳化變數時,有:

這導致一個重要結論,MLE 在本質上,等價於最小化模型分佈 與真實分佈 之間的 KL divergence。從資訊論的角度來看,MLE 可以被理解為,選擇一個模型分佈,使其在描述由真實資料生成機制所產生的樣本時,平均所需付出的資訊成本最小。
這也正是為什麼在現代機器學習中,最大化 likelihood、最小化 cross-entropy 與最小化 KL divergence 會反覆以不同形式出現。它們其實描述的是同一個目標,只是站在不同的視角而已。
結語
透過這一連串推導可以看出,entropy 描述的是資料本身無法避免的不確定性,而 cross-entropy 與 KL divergence 則描述了模型選擇所帶來的額外資訊成本。MLE 並非僅是形式上的機率最大化,而是在資訊論意義下,嘗試以模型分佈最有效率地描述資料生成機制。從這個角度來看,最小化 cross-entropy 與最小化 KL divergence,其實都是在逼近真實分佈的不同表述。這也解釋了為何在現代機器學習中,這些資訊理論量會反覆出現在損失函數與訓練目標之中。理解這條理論脈絡,有助於我們在使用模型時,不僅知道怎麼做,也清楚為什麼這樣做是合理的。









