
在強化學習(Reinforcement Learning, RL)中,agent 往往必須在有限且昂貴的真實互動下,學得有效的決策 policy。單純依賴真實經驗(real experience)雖然概念直觀,但在資料效率與學習速度上常受到限制;反之,完全依賴 model 進行規劃(planning),又可能因模型不準確而導致偏誤。Dyna 架構正是為了在這兩者之間取得平衡而提出,將 acting、learning 與 planning 整合於同一個學習流程中。
Table of Contents
規劃、動作和學習(Planning, Acting and Learning)
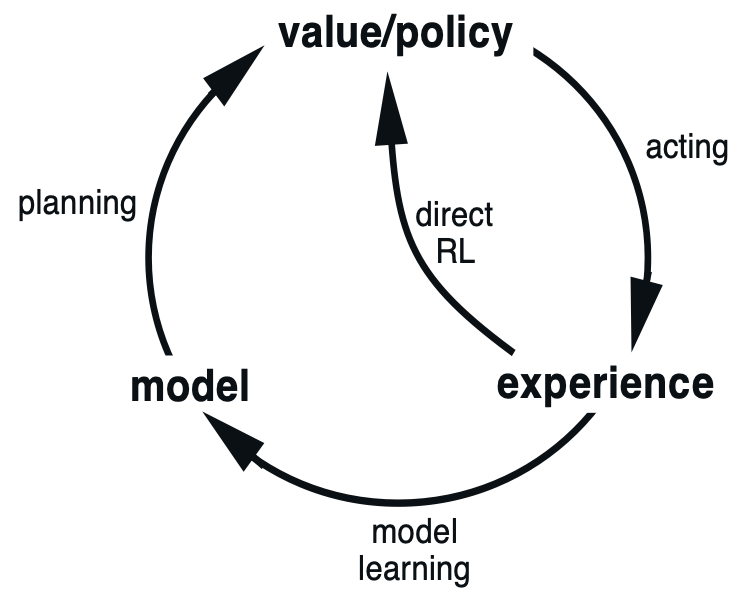
下圖展示了規劃、動作和學習(Planning, Acting and Learning)三者之間的關係。
Acting 指的是 agent 與真實環境(real environment)互動,並產生真實經驗(real experience),其形式為  。例如,在以取樣為基礎的蒙地卡羅方法(Monte Carlo, MC)與時序差分學習(Temporal Difference, TD)中,agent 皆是透過與 real environment 的直接互動,累積一連串的 real experience。
。例如,在以取樣為基礎的蒙地卡羅方法(Monte Carlo, MC)與時序差分學習(Temporal Difference, TD)中,agent 皆是透過與 real environment 的直接互動,累積一連串的 real experience。
Learning 指的是利用這些來自 real environment 的 real experience 進行學習。以 MC 與 TD 為例,它們會從實際互動中取得的樣本出發,並據此更新 action-value function。這種直接從 real experience 中學習的方式,通常被稱為直接強化學習(direct reinforcement learning, direct RL),如圖中所示。
Planning 則是指,agent 不再直接與 real environment 互動,而是改為與一個已知的 environment model 互動,從中產生模擬經驗(simulated experience),再利用這些 simulated experience 來學習 policy。例如,動態規劃(Dynamic Programming, DP)便是假設 model 是完全已知的,並透過反覆的 Bellman backup 來進行 policy evaluation 與 policy improvement。
在實務上,real experience 往往是稀缺的,且與 real environment 互動的成本可能相當昂貴,甚至具有風險。因此,為了更有效地利用有限的真實互動資料,一個常見的做法是,先利用已蒐集到的 real experience 來學習一個 environment model,之後再透過該 model 產生 simulated experience,輔助 policy 的學習。這樣的作法被稱為模型學習(model learning)。
在 RL 中,所謂的 model 用來描述 environment 的轉移動態(transition dynamics),通常可形式化為:

其中,model 描述在 state  下執行 action
下執行 action  之後,轉移至下一個 state
之後,轉移至下一個 state  並獲得 reward
並獲得 reward  的機率分佈。
的機率分佈。
有些 model 會完整提供所有可能的下一個 states 與 rewards,以及它們各自的機率分佈,這類模型稱為分佈模型(distribution model)。另一類 model 則不顯式表示完整分佈,而是根據內部的隨機機制進行抽樣,每次僅產生一組可能的結果,我們稱之為樣本模型(sample model)。
本文章即將介紹的 Dyna 架構,正是一種利用 real experience 來學習 sample model,並結合 planning 與 learning 的方法。
Q-Planning
在介紹 Dyna-Q 之前,先回顧 TD 中的 Q-Learning control。若對 Q-Learning 的更新方式尚不熟悉,可先參考以下文章。

Q-Planning 與 Q-Learning 採用完全相同的 action-value 更新公式,其核心差異並不在於學習規則本身,而在於 experience 的來源。
在 Q-Learning 中,agent 需直接與 real environment 互動,透過實際執行 action 所取得的 real experience,來更新 action-value function。這是一種典型的 model-free、以真實互動為基礎的學習方式。
相對地,Q-Planning 並不直接與 real environment 互動,而是改為與已知或已學得的 environment model 互動。agent 透過 model 產生 simulated experience,再將這些 simulated experience 套用到與 Q-Learning 相同的更新公式中,以學習 action-value function。
從這個角度來看,Q-Planning 可以被視為,將 Q-Learning 的更新機制,應用在 model 所生成的 experience 之上。這樣的做法,使得 agent 能在不增加真實互動成本的情況下,反覆進行價值更新,為後續結合 real experience 與 simulated experience 的 Dyna 架構奠定基礎。

Dyna 架構
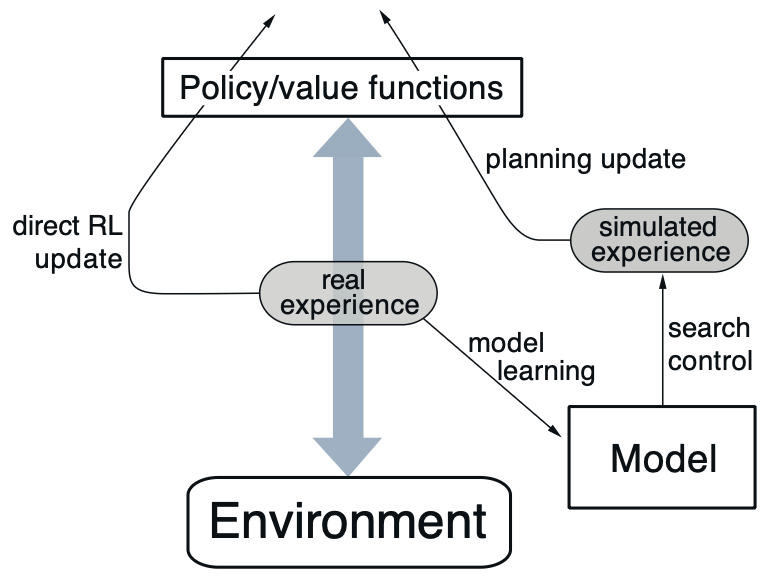
Dyna 是一個用來整合 online planning agent 所需之主要功能的簡單且通用的架構。其想法是,在同一個學習循環中,同時結合 real experience 與 simulated experience,以提升學習效率。
在圖中,real experience 代表 agent 與 real environment 互動所產生的一段經驗軌跡(trajectory),其形式為一連串的 。
由 real experience 指向左側的箭頭,表示 agent 直接根據 real experience 進行學習,也就是所謂的 direct reinforcement learning(direct RL)update。這一步驟可用來更新 value function 或 policy,其形式與一般的 TD 或 Q-Learning 完全一致。
由 real experience 指向右側的箭頭,則表示 model learning 的過程。agent 利用蒐集到的 real experience 來學習 environment model,使 model 能夠近似描述 environment 的轉移動態(transition dynamics)。
在 model 建立之後,agent 便可透過該 model 產生 simulated experience。這個從 model 中選擇 state–action,並產生對應模擬轉移的過程,被稱為搜尋控制(search control),其目的在於決定要對哪些 state 與 action 進行 planning。
最後,agent 再根據這些 simulated experience 進行規劃更新(planning update),以改善 value function 或 policy。由於 planning update 與 direct RL update 在形式上可以完全相同,Dyna 架構得以在單一學習框架中,無縫地整合 real experience 與 simulated experience。
Dyna-Q
Dyna-Q 演算法是 Dyna 架構中的一個具體實例。其想法是,將 Q-Learning 與 Q-Planning 同時納入同一個學習流程中,使 agent 能夠在與 real environment 互動的同時,也利用 model 所產生的 simulated experience 進行 planning。
在 Dyna-Q 中,Q-Learning 負責處理來自 real environment 的 real experience,而 Q-Planning 則負責處理來自 model 的 simulated experience。兩者雖然 experience 來源不同,但皆使用相同的 action-value 更新公式。
具體而言,Dyna-Q 演算法中的步驟 a 到 d,對應的正是 Q-Learning 的流程。agent 與 real environment 互動,取得 real experience,並立即根據這些 experience 進行 action-value function 的更新。這一部分屬於 direct reinforcement learning(direct RL)。
接著,在步驟 e 中,agent 利用剛取得的 real experience 來更新環境模型(model learning),使 model 能夠逐步逼近 real environment 的 transition dynamics。
最後,在步驟 f 中,agent 透過該 model 產生 simulated experience,並對這些 simulated experience 套用與 Q-Learning 相同的更新公式,進行 Q-Planning。這一步驟即為 Dyna 架構中的 planning update,其目的在於在不增加真實互動成本的前提下,進一步改善 action-value function。

Dyna-Q+
當 environment 具有隨機性,且 agent 只能觀察到有限數量的樣本,或是由於 model 採用泛化能力有限的函數近似方式時,都可能導致所學得的 model 與 real environment 不一致。另一種情況是,environment 的 dynamics 已經發生改變,但 agent 尚未再次嘗試對應的 state–action,因此尚未觀察到新的行為模式。上述情形都可能使 model 變得不正確。
當 model 與 real environment 存在落差時,planning 過程中所產生的 simulated experience 便可能帶有系統性偏誤,進而導致 agent 學得次佳的 policy。
在 planning 的情境中,探索(exploration)指的是嘗試那些有助於改善或修正 model 的動作;相對地,利用(exploitation)則是指在當前 model 的假設下,選擇被認為最有利的動作。若 planning 過度偏向 exploitation,agent 便可能長期依賴一個已經過時或不準確的 model。
為了處理上述問題,Dyna-Q+ 在 Dyna-Q 的基礎上,引入了明確的 planning 探索機制。具體而言,Dyna-Q+ 會對每一個 state–action pair 紀錄,自上一次實際與 environment 互動以來,已經經過了多少個 time steps。若某個 state–action 長時間未被嘗試,則代表其 traisition dynamics 可能已經發生變化,而 model 出錯的風險也隨之提高。
假設某一個 transition 在 model 中的預期 reward 為 ,且該 transition 已經經過  個 time steps 未被實際嘗試,則在進行 planning update 時,Dyna-Q+ 會使用以下形式的 reward:
個 time steps 未被實際嘗試,則在進行 planning update 時,Dyna-Q+ 會使用以下形式的 reward:

其中, 為一個正的常數,用來控制探索誘因的強度。隨著 增加,額外的 bonus 也會隨之變大,促使 agent 在 planning 時重新關注那些長時間未被嘗試的 state–action。
為一個正的常數,用來控制探索誘因的強度。隨著 增加,額外的 bonus 也會隨之變大,促使 agent 在 planning 時重新關注那些長時間未被嘗試的 state–action。
透過這樣的設計,Dyna-Q+ 能在 planning 階段主動引導 exploration,使 agent 即使在 model 可能已經過時的情況下,仍能持續測試所有可達的 state transitions,進而提升對非平穩環境的適應能力。
Dyna-Q+ 範例
Dyna-Q+ 實作
在以下的程式碼,我們忠實地實作 Dyna-Q+ 方法。
程式碼中的 env 是 Gymnasium 的 Env 物件。Gymnasium 的前身是 OpenAI Gym。它提供了眾多的 RL 環境的數據,讓我們可以在模擬的環境中,測試 RL 演算法。
Environment 中有 env.observation_space.n 個 states。因此,state 的編號就從整數 0 到 env.observation_space.n - 1。變數 Q 是一個浮點數的 2D-array,每一個 element 都是一對 state 和 action 的 action-value 的估計值。例如,Q[0][0] 是 state 0 的 action 0 的 action-value 估計值。
當把  時,reward bonus 就會永遠是 0,這就等同於 Dyna-Q。
時,reward bonus 就會永遠是 0,這就等同於 Dyna-Q。
import numpy as np
from non_stationary_cliff_walking import NonStationaryCliffWalking
class DynaQPlus:
def __init__(
self,
env: NonStationaryCliffWalking,
alpha=0.1,
gamma=1,
epsilon=0.01,
kappa=0.5,
planning_steps=10,
):
self.env = env
self.alpha = alpha
self.gamma = gamma
self.epsilon = epsilon
self.kappa = kappa
self.planning_steps = planning_steps
self.Q = np.zeros((self.env.observation_space.n, self.env.action_space.n), dtype=float)
self.model = {}
self.t = 0
self.last_time = np.zeros((self.env.observation_space.n, self.env.action_space.n), dtype=int)
def _init_sa_if_not_exists(self, s: int) -> None:
for a in range(self.env.action_space.n):
if (s, a) not in self.model:
self.model[(s, a)] = (0.0, s, False)
def _random_argmax(self, q_s: np.ndarray) -> int:
ties = np.flatnonzero(np.isclose(q_s, q_s.max()))
return np.random.choice(ties)
def _act(self, s: int):
if np.random.rand() < self.epsilon:
return np.random.choice(self.env.action_space.n)
else:
return self._random_argmax(self.Q[s])
def _q_learning_update(self, s: int, a: int, r: float, s_prime: int, terminated: bool):
"""Direct RL"""
if terminated:
self.Q[s][a] += self.alpha * (r + self.gamma * 0 - self.Q[s][a])
else:
self.Q[s][a] += self.alpha * (r + self.gamma * np.max(self.Q[s_prime]) - self.Q[s][a])
def _model_update(self, s: int, a: int, r: float, s_prime: int, terminated: bool):
"""Model Learning"""
self.model[(s, a)] = (r, s_prime, terminated)
def _plan(self) -> None:
seen_sa = list(self.model.keys())
if not seen_sa:
return
for _ in range(self.planning_steps):
s, a = seen_sa[np.random.choice(len(seen_sa))]
r, s_prime, terminated = self.model[(s, a)]
if self.kappa > 0.0:
tau = self.t - self.last_time[s, a]
bonus = self.kappa * np.sqrt(tau)
else:
bonus = 0
self._q_learning_update(s, a, r + bonus, s_prime, terminated)
def run(self, n_episodes=5000, max_steps=1_000) -> None:
for i_episode in range(1, n_episodes + 1):
print(f"\rEpisode: {i_episode}/{n_episodes}", end="", flush=True)
s, _ = self.env.reset()
self._init_sa_if_not_exists(s)
for i in range(max_steps):
print(f"\rEpisode: {i_episode}/{n_episodes}, steps={i}", end="", flush=True)
a = self._act(s)
s_prime, r, terminated, truncated, _ = self.env.step(a)
self._init_sa_if_not_exists(s_prime)
done = terminated or truncated
self._q_learning_update(s, a, r, s_prime, done)
self._model_update(s, a, r, s_prime, done)
self.t += 1
self.last_time[s, a] = self.t
self._plan()
s = s_prime
if done:
break
self.env.end_episode()
print()
def create_pi_by_Q(self) -> np.ndarray:
pi = np.zeros((self.env.observation_space.n, self.env.action_space.n), dtype=float)
for s in range(self.env.observation_space.n):
A_start = self._random_argmax(self.Q[s])
pi[s][A_start] = 1.0
return piCliff Walking
Cliff Walking 涉及在一個網格世界(grid world)中,從起始位置移動到目標位置,同時避免掉落懸崖,如下圖。

Cliff Walking 問題中每個 state 就是玩家的目前的 position。因此共有 36 個 states,分別是上面三排加上左下的格子, 。 目前的 position 由以下公式算出:
。 目前的 position 由以下公式算出:

有四個 actions,分別是:
- 0:Move up
- 1:Move right
- 2:Move down
- 3:Move left
每一步皆給予 −1 reward。但若玩家踏入懸崖(cliff),則會受到 −100 reward。
為了刻意製造 environment 發生改變的情境,我們實作了一個 NonStationaryCliffWalking,用以取代原本的 cliff walking 環境。在訓練初期,NonStationaryCliffWalking 會將 extra_cliff_row 所在的列同樣視為 cliff。而當訓練進行至 switch_episode 之後,該列才會被開放為可通行區域。隨著 environment dynamics 的改變,Dyna-Q+ agent 能夠逐步修正其內部 model,並相應地調整 optimal policy,以適應新的 environment 結構。
import gymnasium as gym
class NonStationaryCliffWalking(gym.Wrapper):
def __init__(self, env: gym.Env, switch_episode=3000, extra_cliff_row=2):
super().__init__(env)
self.switch_episode = switch_episode
self.extra_cliff_row = extra_cliff_row
self._n_episodes = 0
self.switched = False
def _to_rc(self, s: int) -> tuple[int, int]:
return divmod(s, 12)
def _to_s(self, r: int, c: int) -> int:
return r * 12 + c
def _is_cliff(self, r: int, c: int) -> bool:
base = (r == 4 - 1) and (1 <= c <= 12 - 2)
extra = False if self.switched else (r == self.extra_cliff_row) and (1 <= c <= 12 - 2)
return base or extra
def step(self, action):
s_prime, r, terminated, truncated, info = self.env.step(action)
row, col = self._to_rc(s_prime)
if self._is_cliff(row, col):
r = -100.0
terminated = True
s_prime = self._to_s(4 - 1, 0)
return s_prime, r, terminated, truncated, info
def end_episode(self) -> None:
self._n_episodes += 1
if self._n_episodes >= self.switch_episode:
self.switch()
def switch(self) -> None:
self.switched = True以下程式碼中,我們使用 Dyna-Q+ 解決 CliffWalking 問題。
import time
import gymnasium as gym
import numpy as np
from dyna_q_plus import DynaQPlus
from non_stationary_cliff_walking import NonStationaryCliffWalking
GYM_ID = "CliffWalking-v1"
def play_game(policy, episodes=1):
base_visual_env = gym.make(GYM_ID, render_mode="human")
visual_env = NonStationaryCliffWalking(base_visual_env)
visual_env.switch()
for episode in range(episodes):
state, _ = visual_env.reset()
terminated = False
truncated = False
total_reward = 0
step_count = 0
print(f"Episode {episode + 1} starts")
while not terminated and not truncated:
action = np.argmax(policy[state])
state, reward, terminated, truncated, _ = visual_env.step(action)
total_reward += reward
step_count += 1
time.sleep(0.3)
print(f"Episode {episode + 1} is finished: Total reward is {total_reward}, steps = {step_count}")
time.sleep(1)
visual_env.close()
if __name__ == "__main__":
print(f"Gym environment: {GYM_ID}")
print("Start Dyna-Q+ (kappa=0.05)")
env = NonStationaryCliffWalking(gym.make(GYM_ID))
dynaq_plus = DynaQPlus(env, kappa=0.05) # Dyna-Q (kappa = 0)
dynaq_plus.run()
dynaq_plus_policy = dynaq_plus.create_pi_by_Q()
play_game(dynaq_plus_policy)
env.close()
print("\n")在本實驗中,我們於訓練初期將 extra_cliff_row 視為 cliff,使 agent 必須避開該區域。當訓練進行至 switch_episode 後,該 cliff 被移除,environment dynamics 隨之改變。
在切換前,agent 逐漸學會採取保守但安全的路徑,表現穩定。切換後,原本被視為高風險的區域重新變為可通行路徑。然而,由於既有 model 仍保留舊世界的錯誤假設,純 Dyna-Q 會持續高估該區域的風險,導致 policy 長時間無法調整。
相較之下,Dyna-Q+ 透過在 planning 階段引入 exploration bonus,鼓勵重新嘗試長時間未被採取的行為,使 agent 能較快重新探索已改變的環境,並修正過時的 model。結果顯示,Dyna-Q+ 在 non-stationary 環境下具有更好的適應能力,能更快收斂至新的有效策略。

結語
Dyna 架構提供了一個統一的視角,來理解 model-free 與 model-based RL 之間的關係。透過將 real experience 同時用於 direct RL 與 model learning,並進一步產生 simulated experience 進行 planning,Dyna 能夠在不額外增加真實互動成本的情況下,大幅提升資料使用效率。Dyna-Q 具體展現了這種整合方式,將 Q-Learning 與 Q-Planning 納入單一迴圈中,使每一次互動都能被多次利用。
參考
- Adam White and Martha White. Reinforcement Learning Specialization. University of Alberta and Coursera.
- Richard S. Sutton and Andrew G. Barto. 2020. Reinforcement Learning: An Introduction, 2nd. The MIT Press.









