
LLM 在推理任務中的表現,近年因思路鏈(Chain-of-Thought, CoT)的提出而大幅改變。這類方法透過引導 LLM 產生逐步推理的過程,使 LLM 得以展現類似人類的思考結構。然而,隨著任務複雜度提升,傳統 CoT 的限制也逐漸浮現,促使後續研究不斷提出改良策略。本文介紹 CoT 及其延伸方法。
Table of Contents
Chain-of-Thought Prompting, CoT
Chain-of-Thought(CoT)是由 Wei et al. 於 2022 年提出的一種 prompting 技術。它是一種透過逐步推理方式引導 LLM 處理複雜推理任務的技術。其基本概念源自人類解題過程的觀察。在思考多步驟問題時,人類通常會將任務分解為多個中介步驟,逐項解決,最後整合為最終答案。例如,在處理一個典型的數學敘述題時,人類會自然地思考:「送給媽媽 2 朵花後還剩下 10 朵;再送給爸爸 3 朵後剩下 7 朵;因此答案是 7。」這種逐步拆解、遞進式的推理序列正是 CoT 想要賦予 LLM 的能力。
Wei et al. 的想法是,如果在例示(exemplars)中提供具備逐步推理結構的範例,即使 LLM 從未專門為推理微調,它也能在 few-shot 的情境中自主產生類似的 CoT。研究顯示,只要 LLM 規模足夠,它便能模仿這種逐步推理方式,並在許多先前無法成功的推理任務上展現明顯改善。
在原始論文的設計中,CoT 屬於一種純粹依賴 prompting 的方法。也就是說, LLM 的行為完全由提示內容引導,而非依賴額外訓練。這也是 CoT 具代表性的特徵之一,使其可套用於各種 LLMs,只要這些 LLM 具備足夠的規模與語言能力。
CoT 的特性如下:
- CoT 透過在提示中加入帶有中介步驟的範例,使 LLM 自動學會將原始問題拆分為多個較小的邏輯單位。
- CoT 產生的推理過程使研究者能判斷 LLM 推理過程是否合理,或在哪一步可能產生錯誤。這對 LLM 行為分析、錯誤診斷、以及後續改良方法的設計具有重要價值。
- CoT 不侷限於特定任務。它可以應用於任何能以語言方式進行逐步推理的問題。
- CoT 不需要微調,不需要額外標註,也不需要修改模型架構。
範例
下面是一個 one-shot prompt,其一開始的 example 是直接回答答案,而沒有使用 CoT。
Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now? A: The answer is 11. Q: The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?
LLM 會輸出以下的錯誤答案。
A: The answer is 27.
現在我們將這個 example 的回答改成 CoT 的回答方式。
Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now? A: Roger started with 5 balls. 2 cans of 3 tennis balls each is 6 tennis balls. 5 + 6 = 11. The answer is 11. Q: The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?
LLM 則會用 CoT 的方式回答出正確答案。
A: The cafeteria had 23 apples originally. They used 20 to make lunch. So they had 23 - 20 = 3. They bought 6 more apples, so they have 3 + 6 = 9. The answer is 9.
Self-Consistency, SC
Self-Consistency(SC)是由 Wang et al. 於 2023 年提出的一種針對 CoT 方法的增強技術。其主要用來解決 CoT 的單一路徑推理所帶來的不穩定性問題。原始 CoT 依賴 LLM 生成一條推理序列並據此給出答案,但這條序列往往脆弱,可能因 LLM 的隨機性、語境擾動或提示措辭不同而產生錯誤。而 SC 的想法是,若一個問題具有穩定的語義結構, LLM 在多次推理時即便生成不同的推理軌跡,仍應在最終答案上呈現一致的聚合趨勢。
SC 的做法如下:
- 使用較高的 temperature sampling、nucleus sampling、或 top-k sampling 來產生多條推理序列,使 LLM 能探索不同的推理方向。LLM 會在每一次採樣中生成一條完整的 CoT,並提供最終答案。
- 採樣完成後,SC 不直接評估每條推理軌跡的語意合理性,而是簡化為對每次採樣的最終答案進行投票。因此 SC 將所有採樣結果彙整,並選擇出現頻率最高的答案作為最終輸出。
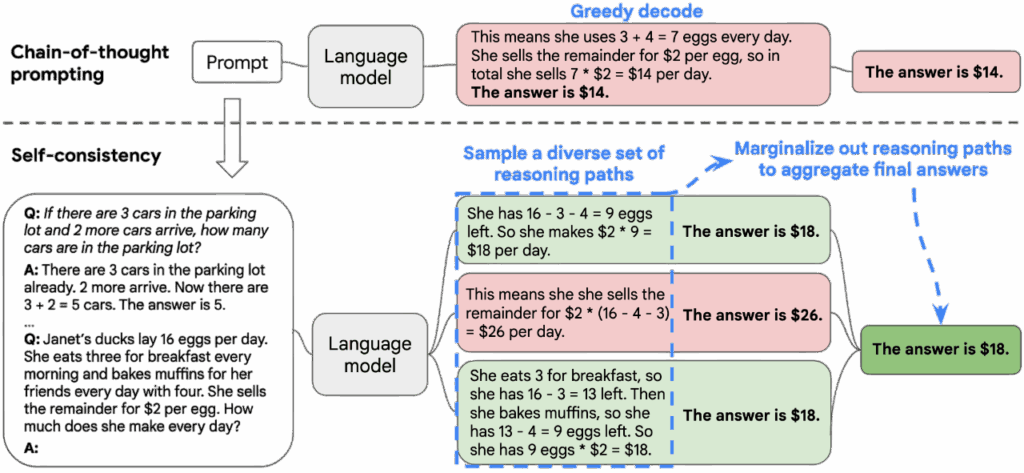
範例
以下是 SC 的實作。我們使用 zero-shot prompting,但是利用 “think step by step” 來使 LLM 使用 CoT 的方式來回答問題。我們還讓 LLM 回答同樣的問題十次,並且使用較高的 temperature。這可以使得 LLM 每次的回答都不太一樣。最後,收集所有的答案,取出現次數最多的那個答案。
from collections import Counter
import re
from question import QUESTION
from utilities import llm
PROMPT = """
Solve the following problem step by step.
{premise_block}
Let's think step by step.
{question_sentence}
""".strip()
def build_prompt(premise_sentences: list[str], question_sentence: str) -> str:
premise_block = "\n".join(premise_sentences)
return PROMPT.format(premise_block=premise_block, question_sentence=question_sentence)
def extract_final_answer(text) -> str | None:
numbers = re.findall(r"-?\d+", text)
if not numbers:
return None
return numbers[-1]
def split_sentences(text: str) -> list[str]:
sentences = re.split(r"(?<=[.?!])\s+", text.strip())
return [s.strip() for s in sentences if s.strip()]
def identify_question_index(sentences: list[str]) -> int:
numbered = []
for i, s in enumerate(sentences, 1):
numbered.append(f"{i}. {s}")
numbered_text = "\n".join(numbered)
prompt = f"""
Which sentence is the main question the user wants answered?
Return ONLY the number. Do not write anything else. Do not repeat the sentence.
{numbered_text}
Answer with a single number (1, 2, ..., or {len(numbered)}):
"""
output = llm(prompt)
match = re.search(r"\d+", output)
if not match:
raise ValueError(f"LLM failed to output a number: {output}")
return int(match.group())
def solve_problem(prompt, n=10) -> str:
answers = []
for i in range(n):
output = llm(prompt, temperature=0.8)
answer = extract_final_answer(output)
if answer is not None:
answers.append(answer)
if not answers:
raise ValueError("No valid answers from LLM.")
counts = Counter(answers)
final_answer = counts.most_common(1)[0][0]
return final_answer
def self_consistency(question: str) -> str:
sentences = split_sentences(question)
question_index = identify_question_index(sentences)
question_sentence = sentences[question_index - 1]
premise_sentences = [s for i, s in enumerate(sentences, 1) if i != question_index]
prompt = build_prompt(premise_sentences, question_sentence)
return solve_problem(prompt)
if __name__ == "__main__":
answer = self_consistency(QUESTION)
print(f"Self-Consistency\n\nQuestion:\n{QUESTION}\n\nAnswer:\n{answer}")
Least-to-Most Prompting, L2M
Least-to-Most Prompting(L2M)是由 Zhou et al. 於 2023 年提出的一種建立在問題分解(problem decomposition)的推理方法。Zhou et al. 認為,許多複雜推理問題都可以拆解成一連串較簡單的子問題,並透過逐步解決這些子問題來構建最終解答。人類在處理複雜任務時往往自然地採取此策略,例如先確立子目標、逐步完成中間步驟,再整合結果解決整體問題。L2M 採用相同原理,透過提示方式引導 LLM 重現這種由簡入繁的推理程序。
在原始論文中,L2M 被定位為一種結構化 prompting 技術。 LLM 先為原始問題產生一組子問題,接著逐一回答這些子問題,最後再以子問題的解答組合成最終答案。
L2M 的做法如下:
- 問題分解(Decomposition): LLM 首先被要求將原始問題分解為多個彼此相關但難度較低的子問題。拆解本身就是一個推理動作。 LLM 必須理解問題語義、辨識隱含的結構,並將其化為可獨立回答的子任務。
- 子問題求解(Subproblem solving):完成拆解後, LLM 會依序回答每一個子問題,而每個子問題的答案可能成為下一步推理的必要條件。
- 最終整合:當所有子問題都獲得解答後, LLM 會再根據這些結果融合出最終解答。
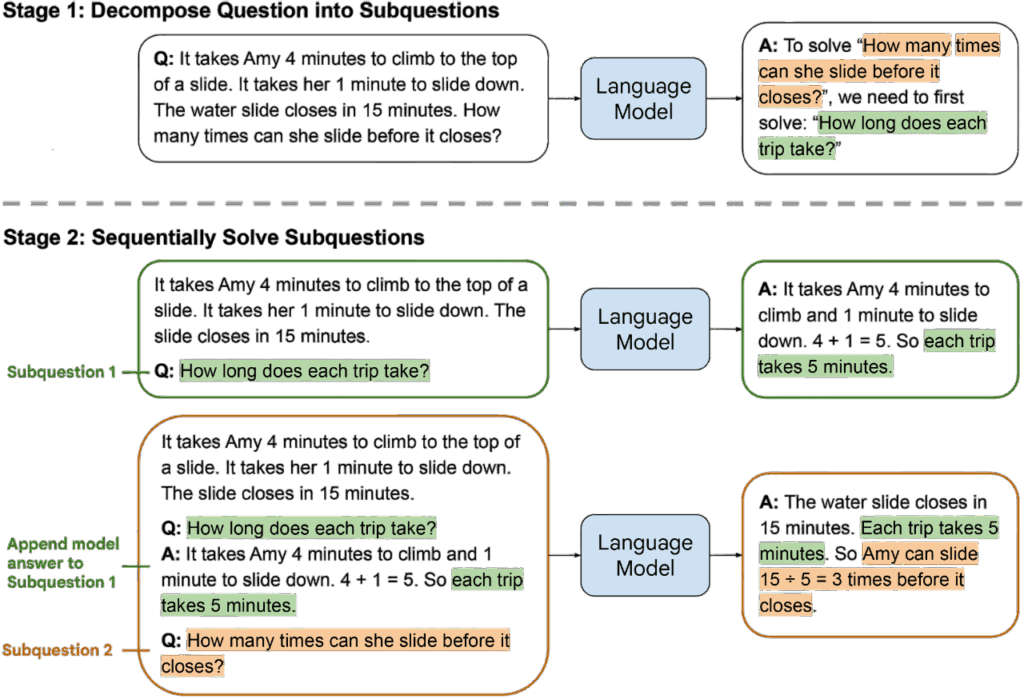
範例
以下 L2M 的實作。我們先用 LLM 來對輸入的問題  產生出一連串的子問題(
產生出一連串的子問題( )。首先,讓 LLM 回答
)。首先,讓 LLM 回答  ,得到答案
,得到答案  。接下來,讓 LLM 回答
。接下來,讓 LLM 回答  ,得到
,得到  。如此反覆下去,直到得到所有子問題的答案。最後,再讓 LLM 回答
。如此反覆下去,直到得到所有子問題的答案。最後,再讓 LLM 回答  ,得到最終的答案。
,得到最終的答案。
import re
from question import QUESTION
from utilities import llm
SUBPROBLEM_GENERATOR_PROMPT = """
Break the following problem into simple subproblems.
Each subproblem should be a small step required to solve the final question.
Return ONLY subproblems per each line. No explanation. Not solution.
Problem:
{input}
Output format:
SP 1: "subproblem 1"
SP 2: "subproblem 2"
...
"""
SUBPROBLEM_PROMPT = """
You are solving a complex problem by breaking it into smaller subproblems.
Original problem:
{input}
Previously solved subproblems:
{solved_subproblems}
Now solve the next subproblem:
{next_subproblem}
Return ONLY the short answer.
"""
FINAL_PROMPT = """
Use the solved subproblems to answer the final question.
Original problem:
{input}
Solved subproblems:
{solve_subproblems}
Based on the above, give the final answer to the original question.
Return ONLY the short answer.
"""
def generate_subproblems(question: str) -> list[str]:
prompt = SUBPROBLEM_GENERATOR_PROMPT.format(input=question)
output = llm(prompt)
lines = output.strip().splitlines()
subproblems = []
for line in lines:
match = re.match(r"\s*SP\s*\d+\s*:\s*(.+)", line.strip())
if match:
subproblems.append(match.group(1).strip())
return subproblems
def solve_subproblem(question: str, next_subproblem: str, solved: list[tuple[str, str]]):
solved_block = "\n".join(f"{i + 1}. {p} -> {a}" for i, (p, a) in enumerate(solved)) if solved else "(none)"
prompt = SUBPROBLEM_PROMPT.format(input=question, solved_subproblems=solved_block, next_subproblem=next_subproblem)
return llm(prompt)
def solve_final_problem(question: str, subproblems, answers):
solved_subproblems = []
for i, (sp, ans) in enumerate(zip(subproblems, answers), 1):
solved_subproblems.append(f"{i}. Subproblem: {sp}")
solved_subproblems.append(f" Answer: {ans}")
sp_block = "\n".join(solved_subproblems)
prompt = FINAL_PROMPT.format(input=question, solve_subproblems=sp_block)
return llm(prompt)
def l2m(question: str) -> str:
subproblems = generate_subproblems(question)
solved_pairs = []
answers = []
for i in range(len(subproblems)):
answer_i = solve_subproblem(question, subproblems[i], solved_pairs)
solved_pairs.append((subproblems[i], answer_i))
answers.append(answer_i)
return solve_final_problem(question, subproblems, answers)
if __name__ == "__main__":
answer = l2m(QUESTION)
print(f"Least-To-Most Prompting, L2M\n\nQuestion:\n{QUESTION}\n\nAnswer:\n{answer}")
Program-Aided Language Models, PAL
Program-Aided Language Models(PAL)是由 Gao et al. 於 2023 年提出的一種將 LLM 的推理能力與外部程式執行環境結合的推理技術。其核心思想是將推理任務中可以形式化、可計算、或可透過程序明確求解的部分交由程式語言執行,而讓 LLM 負責產生程式碼、規劃計算流程、並決定如何利用外部工具獲得正確答案。
Gao et al. 指出 LLM 在自然語言推理上具有強大的語義能力,但在算術、符號操作、複雜計算或需要精確執行的邏輯任務上仍存在明顯限制。例如, LLM 可能在算式中產生表面上合理但實際錯誤的數值,或在長鏈式推理中累積語言生成誤差。PAL 嘗試透過語言與程式的協同方式減少這些錯誤,並打造一套更可靠的混合推理架構。

範例
以下是 PAL 的實作。我們不直接讓 LLM 回答問題,而是讓 LLM 產生出可執行的 Python 程式碼,而然後執行程式碼來得到答案。
import re
from question import QUESTION
from utilities import llm
PROMPT = """
Write a Python function solve() that solves the problem below.
The function must return ONLY the final answer as an integer.
Problem:
{input}
Return ONLY the python code.
The Python code must define a function:
def solve():
# compute the answer
return <integer>
"""
def generate_code(question: str) -> str:
prompt = PROMPT.format(input=question)
output = llm(prompt)
match = re.search(r"```(.*?)```", output, re.DOTALL)
return match.group(1).strip()
def execute_code(code: str) -> int:
local_vars = {}
global_vars = {"__builtins__": {"range": range, "len": len}}
exec(code, global_vars, local_vars)
if "solve" not in local_vars:
raise ValueError("solve() function not defined in code")
return local_vars["solve"]()
def pal(question: str) -> int:
code = generate_code(question)
return execute_code(code)
if __name__ == "__main__":
answer = pal(QUESTION)
print(f"Program-aided Language Model, PAL\n\nQuestion:\n{QUESTION}\n\nAnswer:\n{answer}")
Tree-of-Thought, ToT
Tree-of-Thought(ToT)是由 Yao et al. 於 2023 提出的一種將 LLM 的推理能力從單一路徑的 CoT 提升至具有分支結構的搜尋過程的推理框架。Yao et al. 認為,複雜推理問題通常具備內在的樹狀結構,而非單一線性的邏輯序列。若僅依賴 CoT 所生成的一次性推理步驟, LLM 可能因早期錯誤而導致整條推理路徑失效。ToT 的提出正是為了解決這一限制,使 LLM 能在多個候選推理路徑間進行選擇、評估與搜尋,以達到更穩定、更可靠的推理性能。
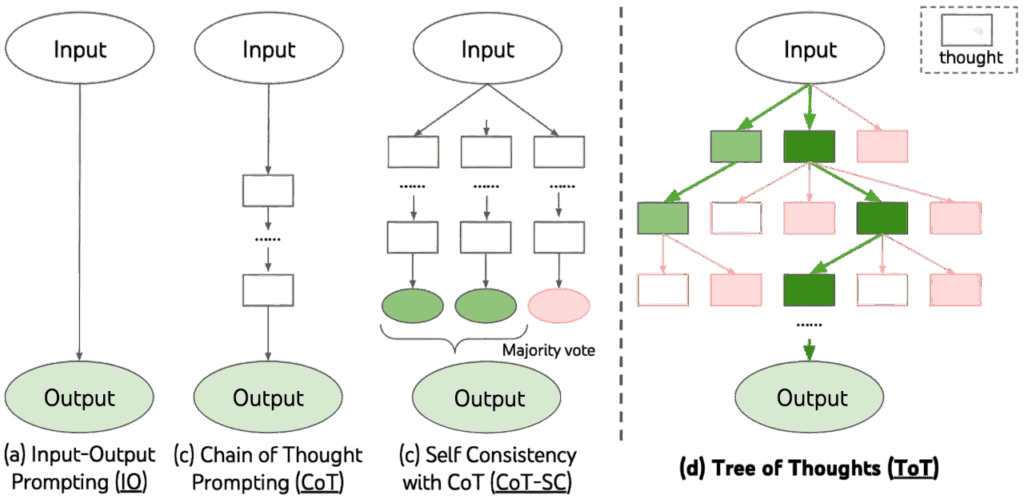
ToT 的架構如下:
- 思維分解(Thought Decomposition):CoT 會產生一條連貫的推理序列,但它不會明確地定義其中的推理單位(thought)。ToT 透過對問題性質的分析,將推理過程拆解為若干中介思維步驟(thoughts),每個 thought 都是推理樹中的一個節點。
- 思維生成器(Thought Generator):在推理樹的每個狀態底下,LLM 必須產生下一步的 k 個候選 thought。有兩種不同策略:
- Sample:使用類似 CoT 的語境,讓 LLM 獨立地生成 k 個候選 thoughts。適用於 thought space 大且多樣性高的任務(如 Creative Writing)。
- Propose:讓 LLM 在同一個 prompt 中依序提出 k 個不同的候選。適用於 thought space 較小、較容易重複的任務。
- 狀態評估器(State Evaluator):在每一層生成完候選狀態後,ToT 需要評估每個 state 的好壞。其目的是為搜尋演算法提供啟發式訊號。有兩種評估策略:
- Value: LLM 透過 value prompt 針對每個 state 給出一個分數或等級。
- Vote:當任務較難以直接賦予數值,ToT 改以投票方式比較所有候選 state,並選出其中最值得探索的一個。
- 搜尋演算法(Search Algorithm):ToT 將生成與評估的結果帶入搜尋演算法中。有兩種搜尋演算法:
- Breadth-first search(BFS)
- Depth-first search(DFS)

範例
以下是 ToT 並且使用 BFS 的實作。ToT 是一個樹狀圖,所以當使用 BFS 時,我們會對樹狀圖一層一層地處理。對於每一層,我們對每一個節點也就是 state,產生出 k 個 thoughts。然後將每一個 thought 與原始問題做評估,並指保留該層 breadth 個最高分數的 state。如此反覆做 size 層,最後取分數最高的 thought 為答案。
import json
import re
from question import QUESTION
from utilities import llm
COT_PROMPT = """
Here are some examples of input-output pairs for solving simple reasoning problems.
Input:
John has 4 apples. He buys 3 more. How many apples does he have?
Output:
John has a total of 7 apples.
Input:
Alice has 10 candies. She gives 4 to Bob. How many candies does Alice have left?
Output:
Alice has 6 candies left.
Input:
Tom has 8 pencils. He loses 3 and buys 2 more. How many pencils does he have now?
Output:
Tom has 7 pencils now.
Now solve the following problem.
Input:
{input}
""".strip()
PROPOSE_PROMPT = """
{input}
Please propose {k} different possible outputs (answers) for the last Input.
Return them as a JSON list of strings, for example:
["...", "...", ...]
""".strip()
PROPOSE_WITH_ATTEMPT_PROMPT = """
{input}
Here is the current attempt at solving the problem:
{current_attempt}
You may refine, correct, or provide alternative outputs based on this attempt.
Please propose {k} different possible outputs (answers) for the last Input.
Return them as a JSON list of strings, for example:
["...", "...", ...]
""".strip()
VALUE_PROMPT = """
Evaluate how correct the following output is for the given input.
Input:
{input}
Output:
{output}
Give a score between 0 and 1, where:
- 1 means "definitely correct and consistent with the input"
- 0 means "definitely incorrect or inconsistent"
Return ONLY this JSON:
{{"value": <number>}}
""".strip()
def propose_prompt_wrap(question: str, current_attempt: str | None, k: int) -> str:
cot_question = COT_PROMPT.format(input=question)
if current_attempt:
prompt = PROPOSE_WITH_ATTEMPT_PROMPT.format(input=cot_question, current_attempt=current_attempt, k=k)
else:
prompt = PROPOSE_PROMPT.format(input=cot_question, k=k)
return prompt
def propose_thoughts(question: str, current_attempt: str | None, k: int) -> list[str]:
prompt = propose_prompt_wrap(question, current_attempt, k)
output = llm(prompt)
match = re.search(r"\[.*]", output, re.DOTALL)
if not match:
raise ValueError("No JSON list found in LLM output:\n" + output)
json_array = json.loads(match.group())
return [thought.strip() for thought in json_array if isinstance(thought, str) and thought.strip()]
def evaluate_thought(question: str, thought: str) -> float:
prompt = VALUE_PROMPT.format(input=question, output=thought)
output = llm(prompt)
match = re.search(r"\{.*}", output, re.DOTALL)
if not match:
raise ValueError("No JSON object found in LLM output:\n" + output)
obj = json.loads(match.group())
value = float(obj["value"])
return max(0.0, min(1.0, value))
def tot_bfs(question: str, step: int = 3, size: int = 3, breadth: int = 3) -> str:
current_attempts: list[str | None] = [None]
for d in range(step):
next_attempts = []
for attempt in current_attempts:
thoughts = propose_thoughts(question=question, current_attempt=attempt, k=size)
scored = []
for thought in thoughts:
score = evaluate_thought(question, thought)
scored.append((score, thought))
scored.sort(key=lambda x: x[0], reverse=True)
next_attempts.extend([t for _, t in scored[:breadth]])
current_attempts = next_attempts[:breadth]
return current_attempts[0]
if __name__ == "__main__":
answer = tot_bfs(QUESTION)
print(f"Tree-of-Thought, ToT\n\nQuestion:\n{QUESTION}\n\nAnswer:\n{answer}")
限制
以上介紹了 CoT、SC、L2M、PAL、以及 ToT 等多種推理技術。這些方法雖然在形式上彼此不同,從單一路徑推理到多路採樣、從問題分解到樹狀搜尋、從語言推理到程式輔助,但它們皆具有一個共同本質,即這些都是以提示設計(prompting)為核心的技術。換言之,它們並未改變 LLM 的推理能力本身,而是透過提示的設計方式,使 LLM 在既有能力範圍內展現更清晰、更可觀察或更具結構性的推理行為。
然而,提示式推理方法的核心侷限也十分明顯。不同的推理任務需要不同的 prompt 格式、不同的示例、不同的結構化框架,只要任務型態改變,整個提示策略便需重新設計。也因此,這些方法不足以構成可跨任務、可普遍適用的推理機制,而更像是一系列針對不同問題類型所設計的啟發式使用方式。 LLM 的推理品質仍然取決於 prompt 的精確性,而非 LLM 內部具備對推理過程的控制或保障。
結語
CoT 系列方法的發展讓我們開始理解推理不僅是 LLM 能力的呈現,更需要透過適當的框架來組織與引導。未來的推理研究勢必將超越 prompt-based 技術,朝向具備推理控制力、可驗證性與跨任務泛化能力的更高層次模型式推理(model-based reasoning)。然而,這些早期方法仍是了解 LLM 推理行為的基礎,也為後續發展提供不可或缺的概念脈絡。
參考
- Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS 2022.
- Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-Consistency Improves Chain of Thought Reasoning in Language Models. In International Conference on Learning Representations, ICLR 2023.
- Denny Zhou, Nathanael Scharli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, and Ed Chi. 2023. Least-to-Most Prompting Enables Complex Reasoning in Large Language Models. 2023. In International Conference on Learning Representations, ICLR 2023.
- Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. PAL: Program-aided Language Models. In Proceedings of the 40th International Conference on Machine Learning, ICML 2023.
- Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS 2023.









