
雙向循環神經網絡(Bi-directional recurrent neural networks, BRNNs)是一種 RNN,專門用於同時從前向和後向處理序列數據。與傳統 RNN 相比,BRNN 能夠保留更完整的上下文信息,使其能夠在整個序列中捕捉有用的依賴關係,從而在自然語言處理和語音識別等任務中提高預測準確性。
Table of Contents
BRNN
傳統 RNN 僅能從過去的信息進行預測,因為它是單向運行的。這種單方向處理方式,限制了模型對未來信息的利用,使其在許多應用場景中無法充分理解完整的上下文。雙向循環神經網絡(BRNN)通過同時從前向和後向處理序列來解決這一問題。這種結構允許模型利用完整的上下文信息,從而在語言處理、語音識別等多種應用中提高預測效果。
下圖是 BRNN 的架構。BRNN 由兩個獨立的 RNN 組成:
- 前向 RNN(Forward RNN):從
 到 順序處理數據。
到 順序處理數據。 - 後向 RNN(Backward RNN):從 到 順序處理數據。
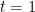 到
到  順序處理數據。
順序處理數據。在每個 time step,最終的 hidden state 是由前向和後向的 hidden states 組合而成。最後,這個合併的 hidden state 在經由 output layer 輸出預測值。

由此可見,BRNN 在計算時間與記憶體需求會比單向 RNN 高一倍。接下來,我們介紹一個 bidirectional vanilla RNN。顧名思義,這個 BRNN 是由兩個 vanilla RNN 組合而成。如果你還不熟悉 RNN 或 vanilla RNN 的話,請先參考以下文章。

前向傳播(Forward Propagation)
下圖是 BRNN forward propagation。這個 BRNN 包含兩個 vanilla RNN,一個是 forward direction RNN,另一個是 backward direction RNN。這兩個 RNN 的 hidden states 會被垂直堆疊起來,成為該 cell 的 hidden state。

BRNN cell 中的公式如下:

BRNN 的輸入  和 true labels
和 true labels  的維度如下:
的維度如下:

在 BRNN cell 中,各個變數的維度如下:
 |  |  |  |  |
 |  |  |  |  |
 | |  |  |  |
| | | | |
 |  |  |  | |
 |  |  |  |
以下是 BRNN 的 forward propagation 的實作。
class BRNN:
def cell_forward_forward(self, xt, aft_prev, parameters):
"""
Implement a single forward step for the BRNN-cell forward direction.
Parameters
----------
xt: (ndarray (n_x, m)) - input at timestep "t"
aft_prev: (ndarray (n_a, m)) - hidden state at timestep "t-1" in the forward direction
parameters: (dict) - the parameters
"Wfx": (ndarray (n_a, n_x)) - weights for the forward input
"Wfa": (ndarray (n_a, n_a)) - weights for the forward hidden state
"bfa": (ndarray (n_a, 1)) - bias for the forward hidden state
Returns
-------
aft: (ndarray (n_a, m)) - hidden state at timestep "t" in the forward direction
zfxt: (ndarray (n_a, m)) - logit at timestep "t" in the forward direction
"""
Wfx, Wfa, bfa = parameters["Wfx"], parameters["Wfa"], parameters["bfa"]
zfxt = Wfx @ xt + Wfa @ aft_prev + bfa
aft = np.tanh(zfxt)
return aft, zfxt
def cell_forward_backward(self, xt, abt_next, parameters):
"""
Implement a single forward step for the BRNN-cell backward direction.
Parameters
----------
xt: (ndarray (n_x, m)) - input at timestep "t"
abt_next: (ndarray (n_a, m)) - hidden state at timestep "t+1" in the backward direction
parameters: (dict) - the parameters
"Wbx": (ndarray (n_a, n_x)) - weights for the backward input
"Wba": (ndarray (n_a, n_a)) - weights for the backward hidden state
"bba": (ndarray (n_a, 1)) - bias for the backward hidden state
Returns
-------
abt: (ndarray (n_a, m)) - hidden state at timestep "t" in the backward direction
zbxt: (ndarray (n_a, m)) - logit at timestep "t" in the backward direction
"""
Wbx, Wba, bba = parameters["Wbx"], parameters["Wba"], parameters["bba"]
zbxt = Wbx @ xt + Wba @ abt_next + bba
abt = np.tanh(zbxt)
return abt, zbxt
def forward(self, X, af0, abl, parameters):
"""
Implement the forward propagation for the BRNN.
Parameters
----------
X: (ndarray (n_x, m, T_x)) - input data
af0: (ndarray (n_a, m)) - initial hidden state for the forward direction
abl: (ndarray (n_a, m)) - initial hidden state for the backward direction
parameters: (dict) - the parameters
"Wfx": (ndarray (n_a, n_x)) - weights for the forward input
"Wfa": (ndarray (n_a, n_a)) - weights for the forward hidden state
"Wbx": (ndarray (n_a, n_x)) - weights for the backward input
"Wba": (ndarray (n_a, n_a)) - weights for the backward hidden state
"Wy": (ndarray (n_y, n_a * 2)) - weights for the output
"bfa": (ndarray (n_a, 1)) - bias for the forward hidden state
"bba": (ndarray (n_a, 1)) - bias for the backward hidden state
"by": (ndarray (n_y, 1)) - bias for the output
Returns
-------
AF: (ndarray (n_a, m, T_x)) - hidden states for the forward direction
AB: (ndarray (n_a, m, T_x)) - hidden states for the backward direction
Y_hat: (ndarray (n_y, m, T_x)) - predictions for each timestep
caches: (list) - caches for each timestep
"""
n_x, m, T_x = X.shape
n_y, n_a_2 = parameters["Wy"].shape
n_a = n_a_2 // 2
fcaches = []
AF = np.zeros((n_a, m, T_x))
aft_prev = af0
for t in range(T_x):
xt = X[:, :, t]
aft, zfxt = self.cell_forward_forward(xt, aft_prev, parameters)
AF[:, :, t] = aft
fcaches.append((aft, aft_prev, xt, zfxt))
aft_prev = aft
bcaches = []
AB = np.zeros((n_a, m, T_x))
abt_next = abl
for t in reversed(range(T_x)):
xt = X[:, :, t]
abt, zbxt = self.cell_forward_backward(xt, abt_next, parameters)
AB[:, :, t] = abt
bcaches.insert(0, (abt, abt_next, xt, zbxt))
abt_next = abt
caches = []
Wy, by = parameters["Wy"], parameters["by"]
Y_hat = np.zeros((n_y, m, T_x))
for t in range(T_x):
aft, aft_prev, xt, zfxt = fcaches[t]
abt, abt_next, xt, zbxt = bcaches[t]
at = np.concatenate((aft, abt), axis=0)
zyt = Wy @ at + by
y_hat_t = softmax(zyt)
Y_hat[:, :, t] = y_hat_t
caches.append((fcaches[t], bcaches[t], (at, zyt, y_hat_t)))
return AF, AB, Y_hat, caches損失函數(Loss Function)
由於我們的 BRNN 是兩個 vanilla RNN 組成的,所以也使用 softmax 輸出  ,因此使用 cross-entropy loss 作為它的 loss function。關於 cross-entropy loss 的公式與實作,請參考以下文章。
,因此使用 cross-entropy loss 作為它的 loss function。關於 cross-entropy loss 的公式與實作,請參考以下文章。
反向傳播(Backward Propagation)
BRNN 的 backpropagation 有比較複雜一點。我們要將在 output layer 中計算出來的  分割成兩個,分別給 forward direction RNN 和 backward direction RNN。Forward direction RNN 的 backpropagation 是由最後一個 time step 往前算。而,backward direction RNN 的 backpropagation 則是由第一個 time step 往後算。
分割成兩個,分別給 forward direction RNN 和 backward direction RNN。Forward direction RNN 的 backpropagation 是由最後一個 time step 往前算。而,backward direction RNN 的 backpropagation 則是由第一個 time step 往後算。

以下求取 output layer 裡的偏導數。

以下求取 forward direction RNN 中所有參數的偏導數。

以下求取 backward direction RNN 中所有參數的偏導數。

以上是在每個 time step 中求取所有偏導數的方式。我們最後還要將所有求取的偏導數加總起來。

以下是 BRNN 的 backward propagation 的實作。
class BRNN:
def cell_backward_forward(self, daft, fcache, parameters):
"""
Implement a single backward step for the BRNN-cell forward direction.
Parameters
----------
daft: (ndarray (n_a, m)) - gradient of the hidden state at timestep "t" in the forward direction
fcache: (tuple) - cache from the forward direction
parameters: (dict) - the parameters
"Wfa": (ndarray (n_a, n_a)) - weights for the forward hidden state
Returns
-------
gradients: (dict) - the gradients
"dWfx": (ndarray (n_a, n_x)) - gradients for the forward input
"dWfa": (ndarray (n_a, n_a)) - gradients for the forward hidden state
"dbfa": (ndarray (n_a, 1)) - gradients for the forward hidden state
"daft": (ndarray (n_a, m)) - gradient of the hidden state at timestep "t-1" in the forward direction
"""
aft, aft_prev, xt, zfxt = fcache
dfz = (1 - aft ** 2) * daft
gradients = {
"dbfa": np.sum(dfz, axis=1, keepdims=True),
"dWfx": dfz @ xt.T,
"dWfa": dfz @ aft_prev.T,
"daft": parameters["Wfa"].T @ dfz,
}
return gradients
def cell_backward_backward(self, dabt, bcache, parameters):
"""
Implement a single backward step for the BRNN-cell backward direction.
Parameters
----------
dabt: (ndarray (n_a, m)) - gradient of the hidden state at timestep "t" in the backward direction
bcache: (tuple) - cache from the backward direction
parameters: (dict) - the parameters
"Wba": (ndarray (n_a, n_a)) - weights for the backward hidden state
Returns
-------
gradients: (dict) - the gradients
"dWbx": (ndarray (n_a, n_x)) - gradients for the backward input
"dWba": (ndarray (n_a, n_a)) - gradients for the backward hidden state
"dbba": (ndarray (n_a, 1)) - gradients for the backward hidden state
"dabt": (ndarray (n_a, m)) - gradient of the hidden state at timestep "t+1" in the backward direction
"""
abt, abt_next, xt, zbxt = bcache
dbz = (1 - abt ** 2) * dabt
gradients = {
"dbba": np.sum(dbz, axis=1, keepdims=True),
"dWbx": dbz @ xt.T,
"dWba": dbz @ abt_next.T,
"dabt": parameters["Wba"].T @ dbz,
}
return gradients
def backward(self, X, Y, parameters, Y_hat, caches):
"""
Implement the backward propagation for the BRNN.
Parameters
----------
X: (ndarray (n_x, m, T_x)) - input data
Y: (ndarray (n_y, m, T_x)) - true labels
parameters: (dict) - the parameters
"Wfx": (ndarray (n_a, n_x)) - weights for the forward input
"Wfa": (ndarray (n_a, n_a)) - weights for the forward hidden state
"Wbx": (ndarray (n_a, n_x)) - weights for the backward input
"Wba": (ndarray (n_a, n_a)) - weights for the backward hidden state
"Wy": (ndarray (n_y, n_a * 2)) - weights for the output
"bfa": (ndarray (n_a, 1)) - bias for the forward hidden state
"bba": (ndarray (n_a, 1)) - bias for the backward hidden state
"by": (ndarray (n_y, 1)) - bias for the output
"""
n_x, m, T_x = X.shape
n_a, n_x = parameters["Wfx"].shape
Wfx, Wfa, bfa = parameters["Wfx"], parameters["Wfa"], parameters["bfa"]
Wbx, Wba, bba = parameters["Wbx"], parameters["Wba"], parameters["bba"]
Wy, by = parameters["Wy"], parameters["by"]
gradients = {
"dWfx": np.zeros_like(Wfx), "dWfa": np.zeros_like(Wfa), "dbfa": np.zeros_like(bfa),
"dWbx": np.zeros_like(Wbx), "dWba": np.zeros_like(Wba), "dbba": np.zeros_like(bba),
"dWy": np.zeros_like(Wy), "dby": np.zeros_like(by),
}
daf = np.zeros((n_a, m, T_x))
dab = np.zeros((n_a, m, T_x))
for t in range(T_x):
_, _, (at, zyt, y_hat_t) = caches[t]
dy = Y_hat[:, :, t] - Y[:, :, t]
dWy = dy @ at.T
dby = np.sum(dy, axis=1, keepdims=True)
gradients["dWy"] += dWy
gradients["dby"] += dby
dat = Wy.T @ dy
daf[:, :, t] = dat[:n_a, :]
dab[:, :, t] = dat[n_a:, :]
daft = np.zeros((n_a, m))
for t in reversed(range(T_x)):
fcaches, _, _ = caches[t]
grads = self.cell_backward_forward(daf[:, :, t] + daft, fcaches, parameters)
gradients["dWfx"] += grads["dWfx"]
gradients["dWfa"] += grads["dWfa"]
gradients["dbfa"] += grads["dbfa"]
daft = grads["daft"]
dabt = np.zeros_like(daft)
for t in range(T_x):
_, bcache, _ = caches[t]
grads = self.cell_backward_backward(dab[:, :, t] + dabt, bcache, parameters)
gradients["dWbx"] += grads["dWbx"]
gradients["dWba"] += grads["dWba"]
gradients["dbba"] += grads["dbba"]
dabt = grads["dabt"]
return gradients整合全部
以下的程式碼實作了一次完整的訓練流程。首先,我們將訓練資料傳入 forward propagation,計算 loss,然後再傳入 backward propagation,最終得到 gradients。為了防止 exploding gradients 的發生,我們將對 gradients 做 clipping。然後,再用它來更新參數。這就是一次完整的訓練。
class BRNN:
def optimize(self, X, Y, af_prev, ab_last, parameters, learning_rate, clip_value):
"""
Implement the forward and backward propagation for the BRNN.
Parameters
----------
X: (ndarray (n_x, m, T_x)) - input data
Y: (ndarray (n_y, m, T_x)) - true labels
af_prev: (ndarray (n_a, m)) - initial hidden state for the forward direction
ab_last: (ndarray (n_a, m)) - initial hidden state for the backward direction
parameters: (dict) - the parameters
"Wfx": (ndarray (n_a, n_x)) - weights for the forward input
"Wfa": (ndarray (n_a, n_a)) - weights for the forward hidden state
"Wbx": (ndarray (n_a, n_x)) - weights for the backward input
"Wba": (ndarray (n_a, n_a)) - weights for the backward hidden state
"Wy": (ndarray (n_y, n_a * 2)) - weights for the output
"bfa": (ndarray (n_a, 1)) - bias for the forward hidden state
"bba": (ndarray (n_a, 1)) - bias for the backward hidden state
"by": (ndarray (n_y, 1)) - bias for the output
learning_rate: (float) - learning rate
clip_value: (float) - the maximum value to clip the gradients
Returns
-------
af: (ndarray (n_a, m)) - hidden state at the last timestep for the forward direction
ab: (ndarray (n_a, m)) - hidden state at the first timestep for the backward direction
loss: (float) - the cross-entropy loss
"""
AF, AB, Y_hat, caches = self.forward(X, af_prev, ab_last, parameters)
loss = self.compute_loss(Y_hat, Y)
gradients = self.backward(X, Y, parameters, Y_hat, caches)
gradients = self.clip(gradients, clip_value)
self.update_parameters(parameters, gradients, learning_rate)
af = AF[:, :, -1]
ab = AB[:, :, 0]
return af, ab, loss範例
以下的範例中的 BRNN 模型的輸入是一個字,然後預測該字是否是 palindrome。由於,結果是是或不是 palindrome,因此我們只需要最後的預測值,而忽略其餘的輸出。
以下是 BRNN 模型的 training 函式。
class BRNN:
def preprocess_input(self, input, char_to_idx):
"""
Preprocess the input text data.
Parameters
----------
input: (tuple) - tuple containing the input text data and the true label
char_to_idx: (dict) - dictionary mapping characters to indices
Returns
-------
X: (ndarray (n_x, 1, T_x)) - input data for each time step
Y: (ndarray (n_y, 1, T_x)) - true labels for each time step
"""
word, label = input
n_x = len(char_to_idx)
T_x = len(word)
X = np.zeros((n_x, 1, T_x))
for t, ch in enumerate(word):
X[char_to_idx[ch], 0, t] = 1
Y = np.zeros((2, 1, T_x))
if label == 1:
Y[0, 0, :] = 1.0
Y[1, 0, :] = 0.0
else:
Y[0, 0, :] = 0.0
Y[1, 0, :] = 1.0
return X, Y
def train(self, dataset, char_to_idx, num_iterations=100, learning_rate=0.01, clip_value=5):
"""
Train the RNN model on the given text.
Parameters
----------
dataset: (list) - list of tuples containing the input text data and the true labels
char_to_idx: (dict) - dictionary mapping characters to indices
num_iterations: (int) - number of iterations for the optimization loop
learning_rate: (float) - learning rate for the optimization algorithm
clip_value: (float) - maximum value for the gradients
Returns
-------
losses: (list) - cross-entropy loss at each iteration
"""
losses = []
for i in range(num_iterations):
np.random.shuffle(dataset)
total_loss = 0.0
af_prev = self.af0
ab_next = self.abl
for input in dataset:
X, Y = self.preprocess_input(input, char_to_idx)
af_prev, ab_next, loss = self.optimize(
X, Y, af_prev, ab_next, self.parameters, learning_rate, clip_value
)
total_loss += loss
avg_loss = total_loss / len(dataset)
losses.append(avg_loss)
print(f"Iteration {i}, Loss: {avg_loss}")
return losses最後,以下的程式碼顯示如何訓練我們的模型,並且使用模型來做預測。
def get_palindrome_dataset():
palindromes = ["racecar", "madam", "kayak", "rotator", "noon", "civic"]
non_palindromes = ["hello", "abcde", "python", "world", "carrot", "banana"]
dataset = []
for palindrome in palindromes:
dataset.append((palindrome, 1))
for non_palindrome in non_palindromes:
dataset.append((non_palindrome, 0))
return dataset
if __name__ == "__main__":
dataset = get_palindrome_dataset()
chars = sorted(list(set(''.join([word for word, _ in dataset]))))
vocab_size = len(chars)
char_to_idx = {ch: i for i, ch in enumerate(chars)}
idx_to_char = {i: ch for ch, i in enumerate(chars)}
brnn = BRNN(64, vocab_size, 2)
losses = brnn.train(dataset, char_to_idx, 300, 0.01, 5.0)
correct = 0
for word, label in dataset:
X, Y = brnn.preprocess_input((word, label), char_to_idx)
_, _, Y_hat, _ = brnn.forward(X, brnn.af0, brnn.abl, brnn.parameters)
pred_probs = Y_hat[:, 0, -1]
predicted_label = 1 if (pred_probs[0] > pred_probs[1]) else 0
if predicted_label == label:
correct += 1
print(f"Accuracy: {correct / len(dataset)}")變體
與標準 RNN 一樣,BRNN 也有多種變體,例如雙向 LSTM(BiLSTM)和雙向 GRU(BiGRU)。這些變體透過 gating mechanisms 解決標準 RNN 的梯度消失問題,並能夠更有效地學習長距離依賴關係。
結語
BRNN 透過同時考慮過去和未來的信息,使其能夠更準確地處理序列數據。無論是文本、語音,還是時序數據,BRNN 都能夠提供比單向 RNN 更強的預測能力。通過結合 LSTM 或 GRU,模型能夠進一步緩解梯度消失問題,並學習長期依賴關係。
參考
- Andrew Ng, Deep Learning Specialization, Coursera.









