
注意力模型(Attention Models)如今已成為神經網路中的一個核心概念。尤其是當紅的 GPT 模型以及 Vision Transformers(ViT)模型,皆為 attention models 的代表性應用。本文將深入探討這些模型中的關鍵的注意力機制(attention mechanisms)。
Table of Contents
注意力機制(Attention Mechanisms)
Attention models 首次被 Bahdanau et al. 於 2015 年引入至機器翻譯(machine translation)任務中。Bahdanau 所提出的注意力機制被稱為加法注意力(additive attention)。同年,Luong et al. 提出了三種不同的注意力機制,其中以點積注意力(dot product attention)最為廣泛使用。
到了 2017 年,Vaswani et al. 則提出了 Transformer 模型。該模型中的自注意力(Self-Attention)與多頭注意力(Multi-Head Attention)機制,皆基於縮放點積注意力(Scaled Dot Product Attention)。
在上述三篇論文中,雖然作者皆提出了注意力計算公式,卻鮮少深入解釋這些公式的推導動機與數學基礎。本文將著重於剖析這些公式的設計邏輯與背後原理。因此,我們預期讀者已具備 Bahdanau attention、Luong attention,以及 Transformer 架構的基本知識。若尚未熟悉,建議先參閱以下文章。


查詢、鍵與值(Queries, Keys and Values)
假設我們有一個資料庫 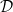 ,由鍵(keys)和值(values)所構成的
,由鍵(keys)和值(values)所構成的  筆樣本組成,定義如下:
筆樣本組成,定義如下:

例如,我們可以將一份電話簿視為一個資料庫,其內容如下所示:
{("Smith","John"),("Johnson","Emily"),("Williams","David"),
("Brown","Sarah"),("Jones","Michael"),("Miller","Laura")}現在,若對這份電話簿進行一筆查詢(query),輸入查詢樣本  ,則將回傳對應值 “Michael”。若系統允許模糊查詢(例如前綴詞比對),輸入
,則將回傳對應值 “Michael”。若系統允許模糊查詢(例如前綴詞比對),輸入  ,則可能回傳對應的 “David”。
,則可能回傳對應的 “David”。
換言之,我們的目標是對於一個查詢樣本  ,預測其對應的目標值
,預測其對應的目標值 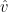 。一個最簡單的估計器(estimator)是對所有訓練資料中的目標值取平均:
。一個最簡單的估計器(estimator)是對所有訓練資料中的目標值取平均:

Nadaraya-Watson Estimator
Nadaraya-Watson 在 1964 年提出了一種非參數回歸模型(non-parametric regression model),能在未知資料分佈或模型形式的情況下,透過樣本資料進行加權平均(weighted average)來估計條件期望值:
![\hat{y}(x) \approx \mathbb{E}[Y \mid X = x]](https://s0.wp.com/latex.php?latex=%5Chat%7By%7D%28x%29+%5Capprox+%5Cmathbb%7BE%7D%5BY+%5Cmid+X+%3D+x%5D+&bg=ffffff&fg=000&s=1&c=20201002)
其對應的估計公式如下,其中  為核函數(kernel function),用以衡量查詢點
為核函數(kernel function),用以衡量查詢點  與樣本點
與樣本點  之間的相似度(similarity),亦即決定對應的
之間的相似度(similarity),亦即決定對應的  所佔的權重:
所佔的權重:

常見的選擇是高斯核(Gaussian kernel),其定義如下:

當我們選擇 Gaussian kernel 作為 ,就可以將距離越近的樣本分配更大的權重,從而實現平滑的局部加權估計。將其帶入 Nadaraya-Watson estimator 後,公式如下:

Attention 基礎
Attention mechanisms 借用 Nadaraya-Watson 透過加權平均來估計預測目標值的概念。因此,我們可以將加權平均納入最簡單的估計器,形成以下公式:

其中的權重函數(weighting function) 用來編碼查詢 與樣本
用來編碼查詢 與樣本 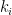 之間的相關性(relevance),進而對應到目標值
之間的相關性(relevance),進而對應到目標值 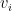 進行加權。
進行加權。
這個概念構成了注意力機制的核心思想:在一組 Key-Value 輸入中,模型根據 Query(目前關注的 token)去選擇性地注意不同的 Key,並根據注意力權重(attention weights)對應取出 Value 的加權平均,以形成新的語意向量。
因此,我們可以將對資料庫 的 attention 定義如下,其中  是純量注意力權重(scalar attention weights):
是純量注意力權重(scalar attention weights):

這個操作也被稱為注意力池化(attention pooling)。之所以稱為注意力(attention),是因為它特別關注那些具有較高權重  的項目。換句話說,對資料庫 的 attention 輸出是一個所有 Value 向量的加權線性組合。
的項目。換句話說,對資料庫 的 attention 輸出是一個所有 Value 向量的加權線性組合。
在前述的電話簿查詢例子中,傳統查詢會將其中一筆資料的權重設為 1,其餘為 0。然而在 deep learning 中,更常見的做法是讓所有權重為非負數且總和為 1:

為了達成這樣的正規化,我們引入一個 scoring function  ,用來計算未正規化的相關性分數;再透過一個分佈函數(distribution function)
,用來計算未正規化的相關性分數;再透過一個分佈函數(distribution function) 對其進行正規化,得到最終的注意力權重 :
對其進行正規化,得到最終的注意力權重 :

在深度學習中,通常會選擇可微分(differentiable)的函數作為 scoring function  以及 distribution function ,以便整個模型能透過 backpropagation 學習。Softmax 是最常見的 distribution function 之一,其正規化公式如下:
以及 distribution function ,以便整個模型能透過 backpropagation 學習。Softmax 是最常見的 distribution function 之一,其正規化公式如下:

將此 weighting function 帶入 attention pooling,即可得到以下的注意力公式:

由於資料庫 是 Key-Value 的集合,因此我們也常見以下寫法來表示 attention:

目前大多數的注意力機制都是上述公式的變體,其差異主要來自於所選用的 attention scoring function ,也就是衡量查詢 與鍵  之間相關性的方式。
之間相關性的方式。
加法注意力(Additive Attention)
Bahdanau et al. 在 2015 年提出加法注意力(additive attention),其 attention scoring function  定義如下,其中
定義如下,其中  為可學習參數(learnable parameters):
為可學習參數(learnable parameters):

這個 scoring function 的目的是衡量查詢 和鍵 之間的相關性(relevance),或更進一步地稱為相容性(compatibility)。在 Bahdanau attention 中,鍵 對應於 encoder 的 hidden state  ,而查詢 則對應於 decoder 前一個 time step 的 hidden state
,而查詢 則對應於 decoder 前一個 time step 的 hidden state  。因此,得出:
。因此,得出:

所得的  表示 decoder 在 time step
表示 decoder 在 time step  下,其上一個 hidden state 與 encoder hidden state 之間的相容性。
下,其上一個 hidden state 與 encoder hidden state 之間的相容性。
值得注意的是,這裡的注意力是依賴於 decoder 過去的 hidden state ,並對 encoder 所有位置的表示進行加權聚合。
我們可以看出,additive attention 是透過 learnable parameters 讓模型自行學習 attention scoring function。
另外,相關性(relevance)與相容性(compatibility)雖意義相近,仍有語境上的差異。在談論 queries、keys 和 values 的整體流程時,通常使用相關性(relevance)來描述某項資訊是否與查詢需求相符;然而,在專注於 attention scoring function 的上下文中,則更常使用相容性(compatibility)來描述查詢 與鍵 之間的匹配程度。
點積注意力(Dot Product Attention)
Luong et al. 在 2015 年,繼 additive attention 之後,提出了點積注意力(dot product attention),其 attention scoring function 定義如下:

在 Loung attention 中, 鍵 對應於 encoder 的 hidden state ,而查詢 對應於 decoder 的 hidden state 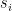 。因此,dot product attention 的一般形式可以寫成:
。因此,dot product attention 的一般形式可以寫成:

與 Bahdanau attention 不同的是,dot product attention 移除了所有 learnable parameters,並直接使用查詢 與鍵 之間的 dot product 作為 compatibility 分數。這樣的設計大幅簡化了計算,對於訓練效能而言有顯著提升。
然而,一個自然的問題是:為何  能夠有效衡量查詢 和鍵 之間的compatibility?我們可以從兩個角度來理解這個設計動機:
能夠有效衡量查詢 和鍵 之間的compatibility?我們可以從兩個角度來理解這個設計動機:
- 點積(Dot Product)和高斯核(Gaussian Kernel)的關聯
- 點積(Dot Product)和餘弦相似度(Cosine Similarity)的關聯
點積(Dot Product)和高斯核(Gaussian Kernel)的關聯
若採用 Gaussian kernel 作為 attention scoring function ,並將平方距離  展開如下:
展開如下:

其中,最後一項  僅依賴於查詢 ,對所有
僅依賴於查詢 ,對所有  配對而言都是相同的值,也就是皆為常數。在實作中,注意力分數會透過 softmax 等 distribution function 進行正規化(使總和為 1),因此這一項將在 softmax 計算中被完全抵銷。
配對而言都是相同的值,也就是皆為常數。在實作中,注意力分數會透過 softmax 等 distribution function 進行正規化(使總和為 1),因此這一項將在 softmax 計算中被完全抵銷。
此外,層正規化(layer normalization)常用於生成鍵 。這會導致每個 的 L2 範數(norm)  被限制在一定範圍內,有時甚至近似為常數。因此,第二項
被限制在一定範圍內,有時甚至近似為常數。因此,第二項  也可以被略去,而不會對注意力分數造成明顯影響。
也可以被略去,而不會對注意力分數造成明顯影響。
將這兩個項去除後,attention scoring function 可以簡化為:

這正是 dot product attention 的形式。因此,可以說 dot product attention 是 Gaussian kernel 注意力的簡化版本。
補充說明,向量的 L2 norm 定義如下:

而,layer normalization 會將單一樣本的特徵向量標準化為均值為 0、變異數為 1,其公式為:

因此,經過 LayerNorm 處理後,輸出向量的分佈是固定的,也使得 L2 norm 幾乎穩定。這就是為何我們能夠在 Gaussian kernel 的公式中,略去與 norm 有關的項,僅保留 dot product。
若尚未熟悉 layer normalization,建議先參閱以下文章。

點積(Dot Product)和餘弦相似度(Cosine Similarity)的關聯
我們也可以從 cosine similarity 的觀點來理解 dot product attention。
兩個向量 和 的夾角  可以透過餘弦值(cosine)來表示:
可以透過餘弦值(cosine)來表示:

當夾角越小(越接近 0 度), ;當夾角為 90 度,
;當夾角為 90 度, ;若夾角為 180 度,
;若夾角為 180 度, 。這就是餘弦相似度(cosine similarity),常用於衡量語意向量之間的方向相似度。
。這就是餘弦相似度(cosine similarity),常用於衡量語意向量之間的方向相似度。
若將上式兩邊同時乘以分母  ,即可得到 dot product 的形式:
,即可得到 dot product 的形式:

因此,dot product 同時反映了方向相似度(由  決定)與向量長度(magnitude)的乘積。也就是說,當兩向量方向一致,且長度較大時,dot product 會更大。
決定)與向量長度(magnitude)的乘積。也就是說,當兩向量方向一致,且長度較大時,dot product 會更大。
然而,這引出一個自然的疑問:向量的 magnitude 是否會對相似性造成誤導?也就是說,dot product 是否會因向量長度過大而導致錯誤的 attention weights?
舉例來說,若 orange 的向量為 ![[1, 0]](https://s0.wp.com/latex.php?latex=%5B1%2C+0%5D&bg=ffffff&fg=000&s=0&c=20201002) ,而 lemon 的向量為
,而 lemon 的向量為 ![[2, 0]](https://s0.wp.com/latex.php?latex=%5B2%2C+0%5D&bg=ffffff&fg=000&s=0&c=20201002) ,則
,則

雖然兩者語意相近,但 dot product 僅因 magnitude 不同就造成偏差。
在高維空間中,任意兩個隨機向量幾乎呈現正交,因此模型不太可能偶然生成兩個方向完全一致的向量。而在實際應用中,embedding 向量是透過整體損失函數(loss function)學習而來,模型的 learnable parameters 通常會自動調整向量的方向與長度,以避免類似的語意偏誤。也因此,許多模型會使用層正規化(layer normalization)或將向量投影至單位球面(unit sphere)上,以減少 magnitude 的影響。
縮放點積注意力(Scaled Dot Product Attention)
Vaswani et al. 在 2017 年,提出了縮放點積注意力(scaled dot product attention),其 attention scoring function 定義如下,其中  為查詢向量 的維度。
為查詢向量 的維度。

這個式子與原本的 dot product attention 相比,多了一個除以  的縮放因子。其目的,是為了避免在高維空間中 dot product 值變得太大,導致 softmax 輸出極端不穩定,進而造成梯度爆炸或消失。
的縮放因子。其目的,是為了避免在高維空間中 dot product 值變得太大,導致 softmax 輸出極端不穩定,進而造成梯度爆炸或消失。
那麼為什麼是除以 呢?
假設有兩個 維的向量  ,它們的 dot product 為:
,它們的 dot product 為:

我們假設向量中的每個元素  為獨立、期望值為 0、變異數為 1 的隨機變數(例如服從高斯分布
為獨立、期望值為 0、變異數為 1 的隨機變數(例如服從高斯分布 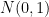 )。則
)。則  的期望為 0,變異數為 1。因為獨立變數相乘,變異數相乘。
的期望為 0,變異數為 1。因為獨立變數相乘,變異數相乘。

由於 dot product 是 個獨立變數的總和,其變異數為 。

換句話說, 的變異數會隨著維度 線性增長。若不加以調整,這將導致 softmax 函數的輸入在高維空間中具有越來越大的數值幅度,進而產生極端尖銳的輸出結果。也就是 softmax 會高度集中於單一元素,使幾乎所有的機率質量都落在該元素上。這種現象會削弱梯度的傳遞,並阻礙模型的學習。
的變異數會隨著維度 線性增長。若不加以調整,這將導致 softmax 函數的輸入在高維空間中具有越來越大的數值幅度,進而產生極端尖銳的輸出結果。也就是 softmax 會高度集中於單一元素,使幾乎所有的機率質量都落在該元素上。這種現象會削弱梯度的傳遞,並阻礙模型的學習。
為了讓 的變異數穩定為 1,我們只需將其除以標準差 $\sqrt{d}$:

這樣一來,進入 softmax 前的值就被標準化處理,保持數值穩定,也提升了注意力權重的學習效率。因此,scaled dot product attention 的核心精神在於,維持 dot product 的變異數穩定,使 softmax 不會因高維輸入而失效。
結語
儘管在早期論文中,這些注意力 scoring functions 的設計往往以直覺驅動,缺乏完整的數學動機與推理,但透過回顧其與核方法(kernel methods)與相似度量(similarity measures)之間的連結,我們得以更深層理解這些公式背後的合理性與原理。
參考
- Sneha Chaudhari, Varun Mithal, Gungor Polatkan, and Rohan Ramanath. 2021. An Attentive Survey of Attention Models. ACM Transactions on Intelligent Systems and Technology (TIST), Volume 12, Issue 5. No., 53, Pages 1 – 32. https://dl.acm.org/doi/10.1145/3465055.
- Aston Zhang, Zack C. Lipton, Mu Li, and Alex J. Smola. 2023, Dive into Deep Learning. Chapter 11: Attention Mechanisms and transformers.
- Dzmitry Bahdanau, KyungHyun Cho, and Yoshua Bengio. 2015. Neural Machine Translation by Jointly Learning to Align and Translate. In ICLR.
- Minh-Thang Luong, Hieu Pham, and Christopher Manning. 2015. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1412–1421.
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan Gomez,
Łukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. Advances in Neural Information Processing Systems 30.









