
在訓練神經網路時,選擇一個好的優化器(optimizer)是很更重要的。Adam 是其中最常見的一種,它幾乎成了預設選擇。Adam 是建立在 SGD、Momentum 和 RMSprop 的基礎之上。讓我們回頭看這段演變的過程,能更清楚了解 Adam 的原理。
Table of Contents
- 什麼是優化器(Optimizers)?
- 隨機梯度下降(Stochastic Gradient Descent, SGD)Optimizer
- 指數移動平均(Exponential Moving Average, EMA)
- Momentum Optimizer
- RMSprop(Root Mean Square Prop)Optimizer
- Adam(Adaptive Momentum Estimation)Optimizer
- L2 正則化(Regularization)與權重衰減(Weight Decay)
- AdamW(Adam with Decoupled Weight Decay)Optimizer
- AdamW 的超參數(Hyperparameters)
- 結語
- 參考
什麼是優化器(Optimizers)?
在機器學習中,訓練模型其實是一個最佳化問題(optimization problem),其目標是:
找出一組參數  ,使得 loss function
,使得 loss function  趨於最小。
趨於最小。
這就是數學中的最小化問題:

這和許多數學最優化問題類似,只是 往往是一個高維、非線性、非凸的函數,而且參數空間通常非常龐大。
由於無法直接求得這類函數的解析最小值,因此我們會使用迭代法(iterative methods),像是梯度下降(gradient descent)這類數值方法來近似找到最小值。而,所謂的優化器(optimizers),其實就是一個決定每一步參數該怎麼更新的演算法。它是訓練的核心之一。
以常見的 gradient descent 類的 optimizers 來說,主要負責以下的任務:
- 取得 gradient:根據目前參數
 ,計算 loss 對參數的 gradient 。
,計算 loss 對參數的 gradient 。 - 計算更新量:根據 gradient 與內部策略(如,adam)計算出更新方向與幅度。
- 更新參數:將新的 應用回模型中,持續進行下一步。
 ,計算 loss 對參數的 gradient
,計算 loss 對參數的 gradient  。
。 應用回模型中,持續進行下一步。
應用回模型中,持續進行下一步。Optimizers 的任務不是直接學習,而是提供有效率的學習更新方式。由以上的任務來看,或許也可以稱為學習器或收斂氣。但從數學角度來看,這個問題的本質是最小化一個函數,而這正是最優化(optimization)這門學科的核心問題。
隨機梯度下降(Stochastic Gradient Descent, SGD)Optimizer
隨機梯度下降(Stochastic Gradient Descent, SGD)是最基本的優化方法。它的想法是:
利用 loss function 對參數的 gradient,反方向前進一步,來讓 loss 減小。
其更新的公式如下:

其中:
- :模型參數。
- :學習率(learning rate)。
- :當前的 gradient。
 :當前的 gradient。
:當前的 gradient。在大型資料集上,我們不會每次都用全部的資料來計算 gradient,而是用小批次(mini-batch),這就是隨機(stochastic)的由來。
指數移動平均(Exponential Moving Average, EMA)
在了解後續的 Momentum 與 Adam 之前,我們要先了解指數移動平均(Exponential Moving Average, EMA)。它的公式如下:

其中:
- :當下的值。
- :累積的加權平均。
- :平滑參數。
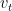 :累積的加權平均。
:累積的加權平均。 :平滑參數。
:平滑參數。各數值的加權影響力隨時間而指數式遞減,越近期的數據加權影響力越重,但較舊的數據也給予一定的加權值。所以,EMA 能夠平滑掉 gradient 的雜訊(如,某次突發的大 gradient 對參數造成巨大影響),更能提供過去資訊的整體方向感。
Momentum Optimizer
Momentum 的靈感來自物理學中動量的概念。結合 EMA,為 gradient 加上慣性,它的更新公式如下:

這個方法能在 gradient 方向穩定的維度上加速更新速度,在方向多變的維度上則可以抑制振盪。
RMSprop(Root Mean Square Prop)Optimizer
Root Mean Square Prop(RMSprop)的改進不是聚焦在方向上,而是讓每個參數維度有自己的 learning rate。它的更新公式如下:
![s_t = \beta s_{t-1} + (1 - \beta) [\nabla_\theta J(\theta)]^2 \\\\ \theta = \theta - \frac{\alpha}{\sqrt{s_t + \varepsilon}} \nabla_\theta J(\theta)](https://s0.wp.com/latex.php?latex=s_t+%3D+%5Cbeta+s_%7Bt-1%7D+%2B+%281+-+%5Cbeta%29+%5B%5Cnabla_%5Ctheta+J%28%5Ctheta%29%5D%5E2+%5C%5C%5C%5C+%5Ctheta+%3D+%5Ctheta+-+%5Cfrac%7B%5Calpha%7D%7B%5Csqrt%7Bs_t+%2B+%5Cvarepsilon%7D%7D+%5Cnabla_%5Ctheta+J%28%5Ctheta%29+&bg=ffffff&fg=000&s=1&c=20201002)
其中:
- :每個參數維度的平方 gradient 的 moving average。
- :一個很小的純量,防止除以 0。
 :每個參數維度的平方 gradient 的 moving average。
:每個參數維度的平方 gradient 的 moving average。根號操作讓更新在 gradeint 較大的維度會自動變小,而在 gradient 較小的維度不會被忽略。RMSprop 讓 learning reate 在每個維度上自動調整,抑制震盪、加速收斂,適合 gradient 幅度差異大的情況。
Adam(Adaptive Momentum Estimation)Optimizer
Adaptive Moment Estimation(Adam)結合了 Momentum 和 RMSprop。它同時追蹤了 gradient 的平均(Momentum)和平方(RMSprop):
![m_t = \beta_1 m_{t-1} + (1 - \beta_1) \nabla_\theta J(\theta) \\\\ v_t = \beta_2 v_{t-1} + (1 - \beta_2) [\nabla_\theta J(\theta)]^2](https://s0.wp.com/latex.php?latex=m_t+%3D+%5Cbeta_1+m_%7Bt-1%7D+%2B+%281+-+%5Cbeta_1%29+%5Cnabla_%5Ctheta+J%28%5Ctheta%29+%5C%5C%5C%5C+v_t+%3D+%5Cbeta_2+v_%7Bt-1%7D+%2B+%281+-+%5Cbeta_2%29+%5B%5Cnabla_%5Ctheta+J%28%5Ctheta%29%5D%5E2+&bg=ffffff&fg=000&s=1&c=20201002)
但這樣的估計其實是偏向零的,特別是剛開始時。因此 Adam 加入了 bias correction:

這樣的設計,讓 Adam 能夠自動調整每個參數的更新幅度,收斂速度快且穩定。
L2 正則化(Regularization)與權重衰減(Weight Decay)
L2 正則化(Regularization)
在訓練神經網路時,我們希望模型不要太過記住訓練資料的細節,也就是過擬合(overfitting)。為了讓模型學到更平滑或更一般化的解,我們會在 loss function 中加入 regularization 項,最常見的就是 L2 Regularization。
L2 Regularization 就是對參數本身的平方加總做懲罰:

其中:
- :原始的 loss function。
- :regularization 係數,決定懲罰程度。
- :模型參數。
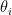 :模型參數。
:模型參數。這個懲罰會讓模型學到參數值較小的解,也就是不依賴某些特別大的權重。這可以減少模型對特定輸入特徵的依賴。
權重衰減(Weight Decay)
在實作上,L2 Regularization 可以透過改變 loss function 來達成。但是,我們也會直接在參數更新公式中引入權重衰減(weight decay):

這個公式其實等價於 L2 regularization,只是將  直接加入 gradient 裡更新,讓每次更新時都稍微縮小權重。所以,這也就稱為 weight decay。
直接加入 gradient 裡更新,讓每次更新時都稍微縮小權重。所以,這也就稱為 weight decay。
在 Adam 中,L2 Regularization ≠ Weight Decay!
L2 Regularization 和 weight decay 在 SGD 下是等價的,也就是你用哪一種方式都沒差。但是,在 Adam 下,它們不是等價的。
Adam 的更新不是簡單依照 gradient 方向,而是會依照每個參數的歷史 gradient 做 bias-corrected 平滑與縮放。也就是說,每一個維度的學習率是不一樣的。
當把 L2 項加到 loss 裡,或是在 gradient 中加入 ,這會讓 regularization 項也一起經過了 Adam 的平滑與縮放處理。導致 L2 懲罰也被變形,產生非預期的 regularization 行為。結果就是,有些參數被過度懲罰,有些則幾乎沒受影響。
AdamW(Adam with Decoupled Weight Decay)Optimizer
為了解決上述的問題,2017 年提出了 Adam with decoupled weight decay(AdamW)。它將 weight decay 從 gradient 計算中抽離出來,直接作用在參數本身:

這樣做的好處是,regularization 效果不會被 gradient 動量影響,且可以獨立控制 regularization 強度。這個修正讓 regularization 效果更加正確。現今如 PyTorch 等框架內建的 AdamW,已逐漸取代了原始 Adam,成為現代訓練的主流。
AdamW 的超參數(Hyperparameters)
AdamW 的公式中有不少 hyperparameters,一開始使用時,還真的不知道要怎麼設定。以下是常見的設定值:
| Parameters | Descriptions | Commonly used values |
|---|---|---|
 | Learning Rate | 0.001 |
 | Momentum | 0.9 |
 | RMSprop | 0.999 |
 | Prevent division by 0 |  |
 | Weight Decay | 0.01 |
以下是初始化 PyTorch 的 AdamW。
from torch.optim import AdamW
optimizer = AdamW(
model.parameters(),
lr=1e-3,
betas=(0.9, 0.999),
eps=1e-8,
weight_decay=0.01
)結語
Adam 是經過多次 optimizers 演化後的產物,結合了 Momentum 的方向穩定性與 RMSprop 的自適應 learning rate。它之所以能成為主流選擇,是因為收斂速度快、適應性強。而 AdamW 更進一步解決了 L2 regularization 在 Adam 中失效的問題,成為現代訓練最可靠的選擇之一。
參考
- Andrew Ng, Deep Learning Specialization, Coursera.









