
在許多機器學習與決策系統中,我們面對的並不是可直接量測的品質分數,而是大量兩者相比,哪一個比較好的偏好判斷。這類成對比較(pairwise comparison)資料雖然簡單,卻隱含了豐富的結構資訊。本文將從機率語意出發,逐步說明如何透過 Bradley–Terry 模型,將這些偏好比較轉化為可學習的潛在效用(latent utility)表示。
問題
在許多實務情境中,對於兩個選項,我們往往無法直接為它們各自量測一個具意義的絕對分數,但卻可以相對容易地回答,在這兩個選項之間,哪一個比較好。這類問題稱為成對比較(pairwise comparison)問題,常見的例子包括:
- 在兩個選項中,使用者更偏好哪一個?
- 兩位選手對戰時,誰比較可能獲勝?
- 在 RLHF 或偏好學習(preference learning)中,人類標注者在兩個模型回覆中會選擇哪一個?
這類資料的共同特徵在於,我們只觀察到 A 是否勝過 B 的結果,而非每個選項本身的絕對品質評分。
我們的目標是,從大量 A vs. B 的比較結果中,反推出每一個對象所對應的潛在效用(latent utility)參數,並進一步回答這個問題:給定任意兩個對象  ,相比於
,相比於  ,
, 被偏好的機率是多少?換言之, 勝過 的機率為何?
被偏好的機率是多少?換言之, 勝過 的機率為何?
為了回答這個問題,我們先將情境形式化。
假設共有  個對象。對於每一個對象 ,我們賦予一個實數值的 latent utility 參數
個對象。對於每一個對象 ,我們賦予一個實數值的 latent utility 參數  。此一參數刻畫了對象 在偏好比較中的內在效用強度(utility level)。然而,在實際資料中,我們無法直接觀察到
。此一參數刻畫了對象 在偏好比較中的內在效用強度(utility level)。然而,在實際資料中,我們無法直接觀察到 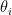 ,只能觀察到成對比較的結果,因此 本身是一個不可觀測的潛在變數。
,只能觀察到成對比較的結果,因此 本身是一個不可觀測的潛在變數。
接著,我們希望建構一個機率模型,用來描述在給定 latent utility 參數  的情況下, 勝過 的機率:
的情況下, 勝過 的機率:
![P( i \succ j \mid \theta_i, \theta_j) \in [0, 1]](https://s0.wp.com/latex.php?latex=P%28+i+%5Csucc+j+%5Cmid+%5Ctheta_i%2C+%5Ctheta_j%29+%5Cin+%5B0%2C+1%5D+&bg=ffffff&fg=000&s=1&c=20201002)
此機率模型應滿足以下幾個直覺且合理的性質:
- 若
 ,則 ; 且 與 的差距越大, 越接近 1。
,則 ; 且 與 的差距越大, 越接近 1。 - 若 ,則 ,表示在偏好上兩者不分軒輊。
- 若 ,則 ; 且差距越大, 越接近 0。
- 對於任意一對 ,比較結果必須互斥且完備,因此滿足 。
 ,則
,則  ; 且
; 且  的差距越大,
的差距越大, 越接近 1。
越接近 1。 ,則
,則  ; 且差距越大,
; 且差距越大, 。
。這些條件共同界定了我們期望 pairwise comparison 模型所具備的基本行為,也為後續引入 Bradley–Terry model 的具體形式,奠定了清楚且一致的理論出發點。
勝算(Odds)
在機率比較中,直接使用機率差往往會造成語意上的誤導。舉例而言,考慮以下兩組機率變化, 與
與  。雖然兩者的數值差同為
。雖然兩者的數值差同為 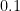 ,但其所代表的意義並不相同。前者對應於中等不確定性下的顯著改變,而後者則已接近幾乎必然的情況。
,但其所代表的意義並不相同。前者對應於中等不確定性下的顯著改變,而後者則已接近幾乎必然的情況。
這說明,在比較兩個事件發生可能性時,單純以機率差作為度量,並不總是合適。在許多情境中,更直觀且更具語意一致性的問題其實是,一個事件發生的可能性,是另一個事件的幾倍?
基於這樣的動機,我們引入勝算(odds)的概念。
對於事件  ,其 odds 定義為:
,其 odds 定義為:

其語意是,選擇 的可能性,是選擇 的幾倍?
Odds 是一個比例量(ratio),而非差值,因此在描述相對偏好強度時,能更忠實地反映機率之間的相對關係,而不會受到機率絕對尺度的影響。
進一步地,若對 odds 取對數,我們可得到 log-odds:

log-odds 的重要特性在於,它將原本位於 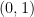 區間的機率,映射到整個實數空間
區間的機率,映射到整個實數空間 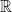 ,使相對優勢能以加法的形式來表達。這個特性使 log-odds 成為後續建構 pairwise comparison 模型時,一個特別自然且便利的表示方式。
,使相對優勢能以加法的形式來表達。這個特性使 log-odds 成為後續建構 pairwise comparison 模型時,一個特別自然且便利的表示方式。
Bradley-Terry 模型
Bradley–Terry model 是由 Ralph A. Bradley 與 Milton E. Terry 於 1952 年所提出,用來處理 pairwise comparison 資料的一個經典機率模型。
Bradley–Terry model 本質上是一個 log-odds 差值模型。對於每一個 item ,模型賦予一個實數值的 latent utility 參數 。需要特別強調的是, 並不是機率,而是用來描述該 item 在偏好比較中,位於 log-scale 上的相對效用強度。
模型的假設是,事件 的 log-odds,等於兩者 latent utility 的差值,即

這個假設直接將前一節所介紹的 log-odds,與 latent utility 參數 連結起來,使相對偏好強度能以線性的形式表達。
接著,我們可以從 log-odds 的形式,推導出對應的機率形式。由上式可得:

進一步整理可得:

其中  為 sigmoid 函數。這表示 Bradley–Terry model 可被視為一個以 latent utility 差值作為輸入的 logistic model。
為 sigmoid 函數。這表示 Bradley–Terry model 可被視為一個以 latent utility 差值作為輸入的 logistic model。
從直覺上來看,若  ,則代表在長期、重複的比較下,選擇 的 odds 是選擇 的 3 倍;而當
,則代表在長期、重複的比較下,選擇 的 odds 是選擇 的 3 倍;而當  時,模型自然回到
時,模型自然回到  的對稱情形。
的對稱情形。
與最大概似估計(Maximum Likelihood Estimation, MLE)對齊
在實務情況下,我們並不知道 pairwise comparison 資料背後的真實機率分佈  。我們所能取得的,只有有限次的觀察樣本,例如,在比較
。我們所能取得的,只有有限次的觀察樣本,例如,在比較 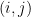 時,標注結果為 或相反。
時,標注結果為 或相反。
在這樣的設定下,Bradley–Terry model 提供了一個參數化的機率模型  ,用來描述任意一組比較結果發生的機率。然而,模型中的 latent utility 參數
,用來描述任意一組比較結果發生的機率。然而,模型中的 latent utility 參數  仍然未知,必須由資料來估計。
仍然未知,必須由資料來估計。
若我們假設這些 pairwise comparison 樣本是獨立同分佈(i.i.d.)地從某個固定但未知的真實分佈中抽樣而來,則一個自然的策略是,選擇一組參數  ,使得在該模型下,觀察到這些資料的機率最大。這正是最大概似估計(Maximum Likelihood Estimation, MLE)。若讀者對 MLE 尚不熟悉,可先參考下列文章:
,使得在該模型下,觀察到這些資料的機率最大。這正是最大概似估計(Maximum Likelihood Estimation, MLE)。若讀者對 MLE 尚不熟悉,可先參考下列文章:

具體而言,設資料集由 筆 pairwise comparison 樣本所組成,每一筆樣本可表示為  ,其中
,其中  表示在第
表示在第  次比較中,是否選擇了
次比較中,是否選擇了  勝過
勝過  。在 Bradley–Terry model 的假設下,整體的負對數概似(negative log-likelihood)可寫為:
。在 Bradley–Terry model 的假設下,整體的負對數概似(negative log-likelihood)可寫為:

這個目標函數在形式上等價於最小化模型分佈  與真實資料分佈之間的 cross-entropy;也因此,MLE 可以被視為在給定模型族的前提下,尋找一個最貼近真實資料生成機制的近似分佈
與真實資料分佈之間的 cross-entropy;也因此,MLE 可以被視為在給定模型族的前提下,尋找一個最貼近真實資料生成機制的近似分佈  。
。
結合前一節 Bradley–Terry model 所給出的 sigmoid 形式,整個學習問題最終被化約為一個標準且可微分的最佳化問題,使我們能夠以梯度式方法,有效地估計每一個 item 的 latent utility 參數 。
範例一
為了具體說明 Bradley–Terry model 搭配 MLE 在實務上是如何運作的,我們考慮一個極簡的 pairwise comparison 例子。
假設我們只有三個 item  ,並蒐集到以下成對比較結果(可視為來自使用者偏好或人類標注):
,並蒐集到以下成對比較結果(可視為來自使用者偏好或人類標注):
- :出現 8 次。
- :出現 2 次。
- :出現 9 次。
- :出現 1 次。
- :出現 6 次。
- :出現 4 次。
 :出現 8 次。
:出現 8 次。 :出現 2 次。
:出現 2 次。 :出現 9 次。
:出現 9 次。 :出現 1 次。
:出現 1 次。 :出現 6 次。
:出現 6 次。 :出現 4 次。
:出現 4 次。這些資料只告訴我們誰比較常贏誰,並未提供任何 item 的絕對品質分數。
在 Bradley–Terry model 中,我們為每個 item 指派一個 latent utility 參數  ,並假設任意一次的比較中,事件 發生的機率為:
,並假設任意一次的比較中,事件 發生的機率為:

接著,MLE 的角色便是調整這些 latent utility 參數  ,使模型所預測的勝率,盡可能符合實際觀察到的比較頻率。
,使模型所預測的勝率,盡可能符合實際觀察到的比較頻率。
以  與
與  為例,資料顯示在 10 次比較中, 勝過 的比例約為 0.8,因此模型會傾向於調整參數,使得:
為例,資料顯示在 10 次比較中, 勝過 的比例約為 0.8,因此模型會傾向於調整參數,使得:

這意味著  必須是一個正值,且其大小足以讓 sigmoid 輸出接近 0.8。
必須是一個正值,且其大小足以讓 sigmoid 輸出接近 0.8。
同理,由於 幾乎總是勝過  ,因此
,因此  會被推得更大;而 與 的比較結果則顯示兩者差距較小,對應的效用差值也會相對接近。
會被推得更大;而 與 的比較結果則顯示兩者差距較小,對應的效用差值也會相對接近。
在整體資料的共同約束下,MLE 會同時考慮所有 pairwise comparison 樣本,尋找一組  ,使所有觀察結果的聯合概似(joint likelihood)達到最大。最終得到的 latent utility 參數 ,並非來自某一次比較,而是反映了所有 pairwise 資訊所形成的全域且一致的偏好排序與強度結構。
,使所有觀察結果的聯合概似(joint likelihood)達到最大。最終得到的 latent utility 參數 ,並非來自某一次比較,而是反映了所有 pairwise 資訊所形成的全域且一致的偏好排序與強度結構。
需要注意的是,Bradley–Terry model 只依賴  的差值,因此對所有 同時加上一個常數,並不會影響模型的預測結果。這表示模型在參數上存在不識別性(non-identifiability)。在實作時,通常會透過固定其中一個參數或加入正則化條件,來消除此一自由度。
的差值,因此對所有 同時加上一個常數,並不會影響模型的預測結果。這表示模型在參數上存在不識別性(non-identifiability)。在實作時,通常會透過固定其中一個參數或加入正則化條件,來消除此一自由度。
透過這個例子可以看出,Bradley–Terry model 提供了一種機制,能夠從局部的成對比較結果,推回一組全域且一致的 latent utility 表示。而,MLE 則是將這個機制實際落地、由資料驅動完成的關鍵步驟。
範例二
在 RLHF(Reinforcement Learning from Human Feedback)的流程中,人類標注者並不會為模型回覆打出絕對分數,而是進行 pairwise comparison。給定同一個 prompt,由模型產生兩個回覆,標注者只需回答,哪一個比較好。
設想以下情境。對於某一個 prompt,語言模型產生了三個回覆 ,並蒐集到人類標注者的偏好資料:
- 在 與 的比較中,標注者多數選擇 。
- 在 與 的比較中,標注者幾乎總是選擇 。
- 在 與 的比較中,標注者略為偏好 。
這些資料只包含哪一個回覆比較好的偏好判斷,而不存在任何形式的絕對品質評分。
在 Bradley–Terry model 的設定下,我們為每一個回覆 指派一個 latent utility 參數 ,並假設人類在比較兩個回覆 時,選擇 的機率為:
在此脈略下, 可被理解為,人類偏好下的隱含效用強度。它本身不可直接觀察,只能透過 pairwise comparison 結果間接推斷。
接著,MLE 便負責利用實際的標注結果來調整這些 latent utility 參數 。例如,若在 與 的比較中,標注者經常選擇 ,則 MLE 會推動參數,使

同理,若 幾乎總是勝過 ,則 會被推得更大。而, 與 的比較結果顯示兩者差距較小,對應的 latent utility 差值也會相對接近。透過同時考慮所有比較樣本,MLE 最終會學得一組 latent utility 參數,使模型對各種 pairwise 偏好的預測,整體上最符合人類標注所隱含的偏好分佈。
在 RLHF 的實作中,這一步對應於 reward model 的訓練。
Bradley–Terry model 提供了,由 latent utility 差值到偏好機率的結構性假設,而 MLE 則使這個假設能夠從人類比較資料中被實際估計,進而學得一個可微分且可泛化的 reward 表示。
因此,從這個角度來看,RLHF 中的 reward model 並不是憑空學習一個分數函數,而是建立在一個清楚的機率模型之上。人類偏好被視為隨機變數,而 Bradley–Terry model 正是描述這種隨機偏好行為的假設之一。
結語
從 pairwise comparison 問題出發,我們首先引入 odds 與 log-odds,作為描述相對偏好強度的自然語言,並說明其為何比直接比較機率差更具語意一致性。Bradley–Terry model 則在此基礎上,對 log-odds 採取最簡潔的結構假設,將偏好行為建模為 latent score 差值的函數。透過 MLE,這個模型得以從實際的 pairwise comparison 資料中學得一組一致的 latent utility 表示。放在 RLHF 與 preference learning 的脈絡下,Bradley–Terry model 不僅提供了理論上清楚的機率解釋,也為 reward modeling 奠定了一個紮實且可實作的基礎。









