
在實際的 control 問題中,state 與 action 往往是高維、連續且充滿噪音的,這使得以 tabular 方法為基礎的 RL 演算法難以直接應用。當我們引入函數近似,原本在理論上清楚分離的 value evaluation 與 policy improvement,開始緊密交織,並伴隨著穩定性與變異性的挑戰。本文將介紹於 on-policy control 方法在函數近似下的 Sarsa。
Table of Contents
控制問題(Control Problem)
在 control 問題中,agent 的目標不再只是評估一個已知的 policy,而是在與 environment 持續互動的過程中,同時進行 value estimation 與 policy improvement,最終逼近 optimal policy。
以 episodic task 為例,我們首先定義從時間步  開始的 discounted return 為:
開始的 discounted return 為:

其中,![\gamma \in [0,1]](https://s0.wp.com/latex.php?latex=%5Cgamma+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002) 為 discount factor,
為 discount factor, 表示 episode 終止的 time step。基於此定義,在 policy
表示 episode 終止的 time step。基於此定義,在 policy  下的 action-value function 可寫為:
下的 action-value function 可寫為:
![q_\pi(s, a) \doteq \mathbb{E} [ G_t \mid S_t=s, A_t=a]](https://s0.wp.com/latex.php?latex=q_%5Cpi%28s%2C+a%29+%5Cdoteq+%5Cmathbb%7BE%7D+%5B+G_t+%5Cmid+S_t%3Ds%2C+A_t%3Da%5D+&bg=ffffff&fg=000&s=1&c=20201002)
Control 問題是在尋找一個 optimal policy  ,使得在所有 states 上,該 policy 所選擇的 action 都能最大化對應的 action-value。形式上,我們希望滿足:
,使得在所有 states 上,該 policy 所選擇的 action 都能最大化對應的 action-value。形式上,我們希望滿足:

也就是說,optimal policy 是由 optimal action-value function 所隱含定義的。
在 tabular 方法 中,我們可以為每一個 state–action 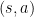 維護一個獨立的數值
維護一個獨立的數值 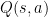 ,並透過 TD control 類型的演算法,在與 environment 的互動過程中逐步逼近
,並透過 TD control 類型的演算法,在與 environment 的互動過程中逐步逼近  。這種作法的前提,是 state space 與 action space 都必須足夠小,使得所有 都能被完整列舉與儲存。
。這種作法的前提,是 state space 與 action space 都必須足夠小,使得所有 都能被完整列舉與儲存。
然而,一旦 state space 或 action space 變得龐大,甚至是連續的,這樣的假設便不再成立。此時,tabular 表示法將無法實際運作,控制問題也必須進入 function approximation 的框架,以參數化的方式來近似 action-value function,並重新思考 policy learning 與 value learning 的互動方式。
在 prediction 問題中,函數近似主要影響的是價值估計是否準確。但在 control 問題中,value function 的近似誤差會直接回饋到 policy improvement,進而影響後續資料分佈與學習穩定性。這也是為何在 approximation 下,control 問題比 prediction 問題更為棘手。
價值函數近似(Value Function Approximation)
當 state space 或 action space 過大,甚至為連續空間時,tabular 表示法將不再可行。在此情況下,action-value function 必須改以參數化函數來近似表示:

其中, 為可學習的參數向量。此時,學習的對象已不再是單一 state–action 所對應的數值,而是整體 action-value function 在參數空間中的表示,也就是參數向量
為可學習的參數向量。此時,學習的對象已不再是單一 state–action 所對應的數值,而是整體 action-value function 在參數空間中的表示,也就是參數向量  本身。
本身。
函數近似的引入,帶來了兩個本質上的改變。
首先,不同的 state–action pair 將共享同一組參數。因此,對某一筆經驗所進行的更新,會同時影響多個狀態與動作的價值估計。這種參數共享使 agent 具備泛化(generalization)能力,能將有限的經驗延伸到未曾或較少訪問的狀態。然而,這也意味著不同 state 之間可能彼此干擾,更新方向不再彼此獨立,進而導致學習行為變得較為不穩定。
其次,在使用函數近似後,價值估計已無法再被視為對某個明確 Bellman operator 的精確求解。由於估計函數被限制在一個有限維的函數族中,學習過程實際上只能在該函數空間內,尋找一個近似滿足 Bellman 一致性的解,而非真正的 fixed point。
因此,當我們在 control 問題中引入函數近似後,學習目標也隨之發生轉變。我們不再試圖恢復真正的 optimal action-value function ,而是希望在所選定的特徵表示與函數空間中,學得一個足以支撐有效 policy improvement的近似 action-value function。正是這個轉變,使得近似 control 問題總是伴隨著穩定性(stability)與偏差(bias)等議題,並成為後續演算法分析與設計時無法迴避的核心挑戰。
值得注意的是,在 prediction 問題中,函數近似主要影響的是價值估計本身的準確性。但在 control 問題中,近似誤差會經由 policy improvement 回饋到後續的資料分佈,形成一個閉迴路。
這也是為何函數近似、bootstrapping 和 policy improvement 的組合,會在理論與實務上同時帶來顯著的困難。
On-Policy
儘管在引入函數近似後,價值表示能力與理論保證皆已發生改變,control 問題在整體結構上,仍然可以被理解為 Generalized Policy Iteration(GPI) 的一種形式,也就是 policy evaluation 與 policy improvement 交替進行的過程。差別在於,當 action-value function 以  來近似表示時,這兩個步驟都不再是精確的,而只能在所選定的函數空間中進行近似。
來近似表示時,這兩個步驟都不再是精確的,而只能在所選定的函數空間中進行近似。
在 on-policy 的設定下,行為策略(behavior policy)與被評估的 policy 是一致的。具體而言,agent 依據某一個具備探索性的 policy (例如:相對於  的
的  -greedy policy)與 environment 互動,並同時使用這個 policy 來定義 TD update 所需的 target。也就是說,資料的產生與價值函數的評估,始終來自同一個 policy。
-greedy policy)與 environment 互動,並同時使用這個 policy 來定義 TD update 所需的 target。也就是說,資料的產生與價值函數的評估,始終來自同一個 policy。
Policy improvement 則是根據目前所學得的近似 action-value function,對 policy 本身進行調整,使其在逐步降低探索程度的同時,朝向對 較為 greedy 的方向移動。隨著參數 的更新,behavior policy 也會同步改變,進而影響後續所收集到的經驗分佈。
因此,整個 on-policy 控制流程,可以被視為一個線上(online)、增量式(incremental)的近似 GPI,即每一步僅根據當前的一小段經驗,對 value function 與 policy 進行局部更新,而非等待 policy evaluation 完全收斂後才進行改善。正是這種緊密交織的更新方式,使得 on-policy 方法在搭配函數近似時,通常具備較好的穩定性。
動作價值函數近似(Action-Value Function Approximation)
在正式進入具體的 control 演算法之前,有必要先釐清一個問題,即在引入函數近似後,action-value function 究竟是如何被表示,以及如何被更新的。
在線性函數近似(linear function approximation)的設定下,基本假設是,每一個 state–action pair ,都可以被映射為一個固定維度的特徵向量(feature vector) 。在此假設下,action-value function 以參數向量 的線性組合來表示:
。在此假設下,action-value function 以參數向量 的線性組合來表示:

在這個表示方式中,所有 states 與 actions 都共享同一組參數 。正因如此,函數近似才具備 generalization 的能力。一次參數更新,會同時影響到所有在特徵空間中相似的 。然而,這種參數共享也帶來了代價,即不同狀態之間的更新可能彼此干擾(interference),而這正是 tabular 方法中不存在的現象。
線性近似的一個重要優點,在於其梯度形式極為簡潔。對上述近似函數取參數梯度,可直接得到:

這使得所有基於 gradient 的 TD control 方法,其參數更新都可以統一寫成以下的形式:
![\delta_t \doteq U_t - \hat{q}(S_t, A_t, \mathbf{w}_t) \\\\ \mathbf{w}_{t+1} \doteq \mathbf{w}_t + \alpha \Big[ U_t - \hat{q}(S_t, A_t, \mathbf{w}_t) \Big] \nabla \hat{q}(S_t, A_t, \mathbf{w}_t) \\\\ \hphantom{\mathbf{w}_{t+1}} = \mathbf{w}_t + \alpha \delta_t \nabla \hat{q}(S_t, A_t, \mathbf{w}_t)](https://s0.wp.com/latex.php?latex=%5Cdelta_t+%5Cdoteq+U_t+-+%5Chat%7Bq%7D%28S_t%2C+A_t%2C+%5Cmathbf%7Bw%7D_t%29+%5C%5C%5C%5C+%5Cmathbf%7Bw%7D_%7Bt%2B1%7D+%5Cdoteq+%5Cmathbf%7Bw%7D_t+%2B+%5Calpha+%5CBig%5B+U_t+-+%5Chat%7Bq%7D%28S_t%2C+A_t%2C+%5Cmathbf%7Bw%7D_t%29+%5CBig%5D+%5Cnabla+%5Chat%7Bq%7D%28S_t%2C+A_t%2C+%5Cmathbf%7Bw%7D_t%29+%5C%5C%5C%5C+%5Chphantom%7B%5Cmathbf%7Bw%7D_%7Bt%2B1%7D%7D+%3D+%5Cmathbf%7Bw%7D_t+%2B+%5Calpha+%5Cdelta_t+%5Cnabla+%5Chat%7Bq%7D%28S_t%2C+A_t%2C+%5Cmathbf%7Bw%7D_t%29+&bg=ffffff&fg=000&s=1&c=20201002)
其中, 為 step size,而 TD target
為 step size,而 TD target  與對應的 TD error
與對應的 TD error  ,則是由所採用的 control 演算法所決定。也正因如此,在實際實作中,線性近似的關鍵從來不在於 gradient 如何計算,而在於 feature 如何設計。
,則是由所採用的 control 演算法所決定。也正因如此,在實際實作中,線性近似的關鍵從來不在於 gradient 如何計算,而在於 feature 如何設計。
從表示能力的角度來看,線性 action-value approximation 等價於假設真實的  ,可以被投影到由 feature vector 所張成的線性子空間中。學習的結果,並不是恢復真正的最優 action-value function ,而是在該特徵空間內,找到一組參數 ,使得 能夠滿足某種近似的 Bellman 一致性(Bellman consistency)。
,可以被投影到由 feature vector 所張成的線性子空間中。學習的結果,並不是恢復真正的最優 action-value function ,而是在該特徵空間內,找到一組參數 ,使得 能夠滿足某種近似的 Bellman 一致性(Bellman consistency)。
Episodic Semi-Gradient Sarsa
在 tabular 設定下,Sarsa 的更新式為:
![Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha \Big[ R_{t+1} + \gamma Q(S_{t+1}, A_{t+1}) - Q(S_t, A_t) \Big]](https://s0.wp.com/latex.php?latex=Q%28S_t%2C+A_t%29+%5Cleftarrow+Q%28S_t%2C+A_t%29+%2B+%5Calpha+%5CBig%5B+R_%7Bt%2B1%7D+%2B+%5Cgamma+Q%28S_%7Bt%2B1%7D%2C+A_%7Bt%2B1%7D%29+-+Q%28S_t%2C+A_t%29+%5CBig%5D+&bg=ffffff&fg=000&s=1&c=20201002)
此更新式可被理解為,使用實際在下一個 state 中所採取的 action  ,來估計目前 policy 下的 action-value,並據此修正當前的估計。也因此,Sarsa 屬於典型的 on-policy TD control 方法。
,來估計目前 policy 下的 action-value,並據此修正當前的估計。也因此,Sarsa 屬於典型的 on-policy TD control 方法。
當 state–action space 過大,無法再以 table 的形式維護 時,我們改以線性函數近似來表示 action-value function:

在此設定下,學習的對象不再是某一個 所對應的數值,而是參數向量 本身。我們希望透過調整 ,使得在互動過程中:

因此,control 問題在引入函數近似後,便轉化為一個參數學習問題,即如何根據 TD error,逐步修正 ,使近似 action-value function 能夠更貼近目前 policy 所對應的真實價值。
在 episodic task 中,Sarsa 的 TD target 與 TD error 定義為:

由於 action-value function 以參數化形式表示,更新時需對參數取 gradient。結合線性近似下的梯度形式  ,episodic Sarsa 的參數更新式可寫為:
,episodic Sarsa 的參數更新式可寫為:
![\mathbf{w}_{t+1} \doteq \mathbf{w}_t + \alpha \Big[ R_{t+1} + \gamma \hat{q}(S_{t+1}, A_{t+1}, \mathbf{w}_t) - \hat{q}(S_t, A_t, \mathbf{w}_t) \Big] \nabla \hat{q}(S_t, A_t, \mathbf{w}_t) \\\\ \hphantom{\mathbf{w}_{t+1}} = \mathbf{w}_t + \alpha \Big[ R_{t+1} + \gamma \hat{q}(S_{t+1}, A_{t+1}, \mathbf{w}_t) - \hat{q}(S_t, A_t, \mathbf{w}_t) \Big] \mathbf{x}(S_t, A_t)](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bw%7D_%7Bt%2B1%7D+%5Cdoteq+%5Cmathbf%7Bw%7D_t+%2B+%5Calpha+%5CBig%5B+R_%7Bt%2B1%7D+%2B+%5Cgamma+%5Chat%7Bq%7D%28S_%7Bt%2B1%7D%2C+A_%7Bt%2B1%7D%2C+%5Cmathbf%7Bw%7D_t%29+-+%5Chat%7Bq%7D%28S_t%2C+A_t%2C+%5Cmathbf%7Bw%7D_t%29+%5CBig%5D+%5Cnabla+%5Chat%7Bq%7D%28S_t%2C+A_t%2C+%5Cmathbf%7Bw%7D_t%29+%5C%5C%5C%5C+%5Chphantom%7B%5Cmathbf%7Bw%7D_%7Bt%2B1%7D%7D+%3D+%5Cmathbf%7Bw%7D_t+%2B+%5Calpha+%5CBig%5B+R_%7Bt%2B1%7D+%2B+%5Cgamma+%5Chat%7Bq%7D%28S_%7Bt%2B1%7D%2C+A_%7Bt%2B1%7D%2C+%5Cmathbf%7Bw%7D_t%29+-+%5Chat%7Bq%7D%28S_t%2C+A_t%2C+%5Cmathbf%7Bw%7D_t%29+%5CBig%5D+%5Cmathbf%7Bx%7D%28S_t%2C+A_t%29+&bg=ffffff&fg=000&s=1&c=20201002)
這個方法被稱為 episodic semi-gradient one-step Sarsa。所謂 semi-gradient,是指在更新時,TD target 中所包含的  被視為常數,而未對其再取 gradient。這種做法雖然偏離了對某一明確誤差函數的完整 gradient descent,但在 on-policy 與線性近似的條件下,仍具備良好的實務穩定性。
被視為常數,而未對其再取 gradient。這種做法雖然偏離了對某一明確誤差函數的完整 gradient descent,但在 on-policy 與線性近似的條件下,仍具備良好的實務穩定性。

Expected Sarsa with Function Approximation
Episodic Semi-Gradient Sarsa 使用實際採取的下一個 action 所對應的動作價值,作為 TD target,因此在概念上忠實反映了目前的 behavior policy。然而,這樣的設計也帶來一個實務上的問題,TD target 的變異性會直接受到 exploring 行為的影響。
當 policy 為 -greedy 時,即使在 value function 已大致收斂的階段,agent 仍會以機率 採取非 greedy action。這些偶發的探索行為,會使得  出現明顯波動,進而導致 TD target 在不同時間步之間高度不穩定。結果是,參數更新的方向受到隨機抽樣的影響,學習效率與穩定性都可能因此下降。
出現明顯波動,進而導致 TD target 在不同時間步之間高度不穩定。結果是,參數更新的方向受到隨機抽樣的影響,學習效率與穩定性都可能因此下降。
Expected Sarsa 正是針對此一問題所提出的改進版本。其核心想法是,既然 TD target 的隨機性來自於對下一個 action 的抽樣,而該 action 的分佈本身已由目前的 policy 明確定義,那麼便可以直接對 action-value 取期望,而非再進行一次隨機抽樣。具體而言,在 state  下,Expected Sarsa 的更新式為:
下,Expected Sarsa 的更新式為:
![\displaystyle Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha [R_{t+1} + \gamma \sum_a \pi(a \mid S_{t+1}) Q(S_{t+1}, a) - Q(S_t, A_t)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+Q%28S_t%2C+A_t%29+%5Cleftarrow+Q%28S_t%2C+A_t%29+%2B+%5Calpha+%5BR_%7Bt%2B1%7D+%2B+%5Cgamma+%5Csum_a+%5Cpi%28a+%5Cmid+S_%7Bt%2B1%7D%29+Q%28S_%7Bt%2B1%7D%2C+a%29+-+Q%28S_t%2C+A_t%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
在此設定下,exploring 行為仍然完整地保留在 policy 中,但其影響已被平均地反映於期望值之中,而不再以高變異的形式直接注入 TD target。
結合線性函數近似與 semi-gradient 的更新方式後,Expected Sarsa 的參數更新式可寫為:
![\displaystyle \mathbf{w}_{t+1} \doteq \mathbf{w}_t + \alpha \Big[ R_{t+1} + \gamma \sum_a \pi(a \mid S_{t+1}) \hat{q}(S_{t+1}, a, \mathbf{w}_t) - \hat{q}(S_t, A_t, \mathbf{w}_t \Big] \nabla \hat{q}(S_t, A_t, \mathbf{w}_t) \\\\ \hphantom{\mathbf{w}_{t+1}} = \mathbf{w}_t + \alpha \Big[ R_{t+1} + \gamma \sum_a \pi(a \mid S_{t+1}) \hat{q}(S_{t+1}, a, \mathbf{w}_t) - \hat{q}(S_t, A_t, \mathbf{w}_t \Big] \mathbf{x}(S_t, A_t)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbf%7Bw%7D_%7Bt%2B1%7D+%5Cdoteq+%5Cmathbf%7Bw%7D_t+%2B+%5Calpha+%5CBig%5B+R_%7Bt%2B1%7D+%2B+%5Cgamma+%5Csum_a+%5Cpi%28a+%5Cmid+S_%7Bt%2B1%7D%29+%5Chat%7Bq%7D%28S_%7Bt%2B1%7D%2C+a%2C+%5Cmathbf%7Bw%7D_t%29+-+%5Chat%7Bq%7D%28S_t%2C+A_t%2C+%5Cmathbf%7Bw%7D_t+%5CBig%5D+%5Cnabla+%5Chat%7Bq%7D%28S_t%2C+A_t%2C+%5Cmathbf%7Bw%7D_t%29+%5C%5C%5C%5C+%5Chphantom%7B%5Cmathbf%7Bw%7D_%7Bt%2B1%7D%7D+%3D+%5Cmathbf%7Bw%7D_t+%2B+%5Calpha+%5CBig%5B+R_%7Bt%2B1%7D+%2B+%5Cgamma+%5Csum_a+%5Cpi%28a+%5Cmid+S_%7Bt%2B1%7D%29+%5Chat%7Bq%7D%28S_%7Bt%2B1%7D%2C+a%2C+%5Cmathbf%7Bw%7D_t%29+-+%5Chat%7Bq%7D%28S_t%2C+A_t%2C+%5Cmathbf%7Bw%7D_t+%5CBig%5D+%5Cmathbf%7Bx%7D%28S_t%2C+A_t%29+&bg=ffffff&fg=000&s=1&c=20201002)
從實作角度來看,這個更新式與 semi-gradient Sarsa 幾乎完全相同,唯一的差異在於 TD target 的計算方式。然而,這個看似細微的改動,卻對學習行為帶來實質影響。由於 TD target 不再依賴單一隨機 action,Expected Sarsa 的更新方向通常更為平滑,對 step size 的敏感度也相對較低。特別是在回饋變異大、或 exploring 風險較高的環境中,Expected Sarsa 往往能展現出比 Sarsa 更穩定的收斂行為。
範例
Semi-Gradient Sarsa 使用 Neural Network 實作
在以下程式碼中,我們以 Semi-Gradient Sarsa 作為 on-policy 的 TD control 方法,並使用 neural network 來近似 action-value function 。由於 TD target 本身包含下一步的估計值(亦即 bootstrap),而該估計值同樣由目前的近似函數所產生,因此若將 target 也納入反向傳播,更新將不再對應於一般意義下的 TD 設定。
因此,本實作採用 semi-gradient 的更新方式,即將 TD target 視為常數,只對當前的預測項  取 gradient 並進行參數更新,而不對 target 項回傳 gradient。換言之,反向傳播僅作用於目前估計這一側,以維持 TD control 的典型更新形式與學習行為。
取 gradient 並進行參數更新,而不對 target 項回傳 gradient。換言之,反向傳播僅作用於目前估計這一側,以維持 TD control 的典型更新形式與學習行為。
import numpy as np
import torch
from torch import nn, optim
from mlp_q_network import MLPQNetwork
class MLPQNetwork(nn.Module):
def __init__(self, observation_dim: int, n_actions: int, hidden_dim: int):
super().__init__()
self.network = nn.Sequential(
nn.Linear(observation_dim, hidden_dim),
nn.LayerNorm(hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.LayerNorm(hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, n_actions),
)
def forward(self, s: torch.Tensor) -> torch.Tensor:
return self.network(s)
class MLPSarsa:
def __init__(
self,
observation_dim: int,
n_actions: int,
*,
hidden_dim: int,
lr=1e-4,
grad_clip=5.0,
gamma=0.99,
epsilon=0.1,
):
self.observation_dim = observation_dim
self.n_actions = n_actions
self.grad_clip = grad_clip
self.gamma = gamma
self.epsilon = epsilon
self.q_network = MLPQNetwork(observation_dim, n_actions, hidden_dim)
self.optimizer = optim.Adam(self.q_network.parameters(), lr=lr)
@torch.no_grad()
def q_s(self, s: np.ndarray) -> np.ndarray:
x = torch.tensor(s, dtype=torch.float32).unsqueeze(0)
q = self.q_network(x).squeeze(0)
return q.numpy()
def act(self, s: np.ndarray, greedy: bool = False) -> tuple[int, np.ndarray]:
q = self.q_s(s)
if not greedy and np.random.rand() < self.epsilon:
a = np.random.randint(self.n_actions)
else:
ties = np.flatnonzero(np.isclose(q, q.max()))
a = np.random.choice(ties)
p = np.ones(self.n_actions) * (self.epsilon / self.n_actions)
greedy_a = np.argmax(q)
p[greedy_a] += 1.0 - self.epsilon
return a, p
def update(self, s: np.ndarray, a: int, r: float, s_prime: np.ndarray, terminated: bool) -> float:
s_t = torch.tensor(s, dtype=torch.float32).unsqueeze(0)
s_tp1 = torch.tensor(s_prime, dtype=torch.float32).unsqueeze(0)
q_t_s = self.q_network(s_t).squeeze(0)
q_t_sa = q_t_s[a]
with torch.no_grad():
if terminated:
target = torch.tensor(r, dtype=torch.float32)
else:
a_tp1, _ = self.act(s_prime)
q_tp1_s = self.q_network(s_tp1).squeeze(0)
q_sa = q_tp1_s[a_tp1]
target = r + self.gamma * q_sa
loss = 0.5 * (target - q_t_sa) ** 2
self.optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(self.q_network.parameters(), self.grad_clip)
self.optimizer.step()
return float(loss.item())Semi-Gradient Expected Sarsa 使用 Neural Network 實作
在以下程式碼中,我們以 Semi-Gradient Expected Sarsa 作為 on-policy 的 TD control 方法,並使用 neural network 來近似 action-value function 。整體訓練流程與 Semi-Gradient Sarsa 相同,差別僅在於 TD target 的定義方式。
由於 TD target 本身包含對下一個 state 下 action-value 的期望,而該期望同樣是由目前的近似函數所計算得出,因此更新時仍採用 semi-gradient 的作法,即將 TD target 視為常數,只對當前預測項 取 gradient 進行反向傳播,而不對 target 項回傳 gradient。
換言之,在 neural network 的實作中,Expected Sarsa 並未改變參數更新的本質形式,而只是以對 action-value 取期望的方式,取代了 Sarsa 中對單一下一步 action 的抽樣。這樣的設計,使得 TD target 更為平滑,並在維持 on-policy 架構的前提下,進一步降低了更新的變異性。
import numpy as np
import torch
from torch import nn, optim
from mlp_q_network import MLPQNetwork
class MLPExpectedSarsa:
def __init__(
self,
observation_dim: int,
n_actions: int,
*,
hidden_dim: int,
lr=1e-4,
grad_clip=5.0,
gamma=0.99,
epsilon=0.1,
):
self.observation_dim = observation_dim
self.n_actions = n_actions
self.grad_clip = grad_clip
self.gamma = gamma
self.epsilon = epsilon
self.q_network = MLPQNetwork(observation_dim, n_actions, hidden_dim)
self.optimizer = optim.Adam(self.q_network.parameters(), lr=lr)
@torch.no_grad()
def q_values(self, s: np.ndarray) -> np.ndarray:
x = torch.tensor(s, dtype=torch.float32).unsqueeze(0)
q = self.q_network(x).squeeze(0)
return q.numpy()
def act(self, s: np.ndarray, greedy: bool = False) -> tuple[int, np.ndarray]:
q = self.q_values(s)
if not greedy and np.random.rand() < self.epsilon:
a = np.random.randint(self.n_actions)
else:
ties = np.flatnonzero(np.isclose(q, q.max()))
a = np.random.choice(ties)
p = np.ones(self.n_actions) * (self.epsilon / self.n_actions)
greedy_a = np.argmax(q)
p[greedy_a] += 1.0 - self.epsilon
return a, p
def update(self, s: np.ndarray, a: int, r: float, s_prime: np.ndarray, terminated: bool) -> float:
s_t = torch.tensor(s, dtype=torch.float32).unsqueeze(0)
s_tp1 = torch.tensor(s_prime, dtype=torch.float32).unsqueeze(0)
q_t_s = self.q_network(s_t).squeeze(0)
q_t_sa = q_t_s[a]
with torch.no_grad():
if terminated:
target = torch.tensor(r, dtype=torch.float32)
else:
q_tp1_s = self.q_network(s_tp1).squeeze(0)
p = torch.ones(self.n_actions, dtype=torch.float32) * (self.epsilon / self.n_actions)
a_start = torch.argmax(q_tp1_s).item()
p[a_start] += 1.0 - self.epsilon
expected_q_tp1 = torch.sum(q_tp1_s * p)
target = r + self.gamma * expected_q_tp1
loss = 0.5 * (target - q_t_sa) ** 2
self.optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(self.q_network.parameters(), self.grad_clip)
self.optimizer.step()
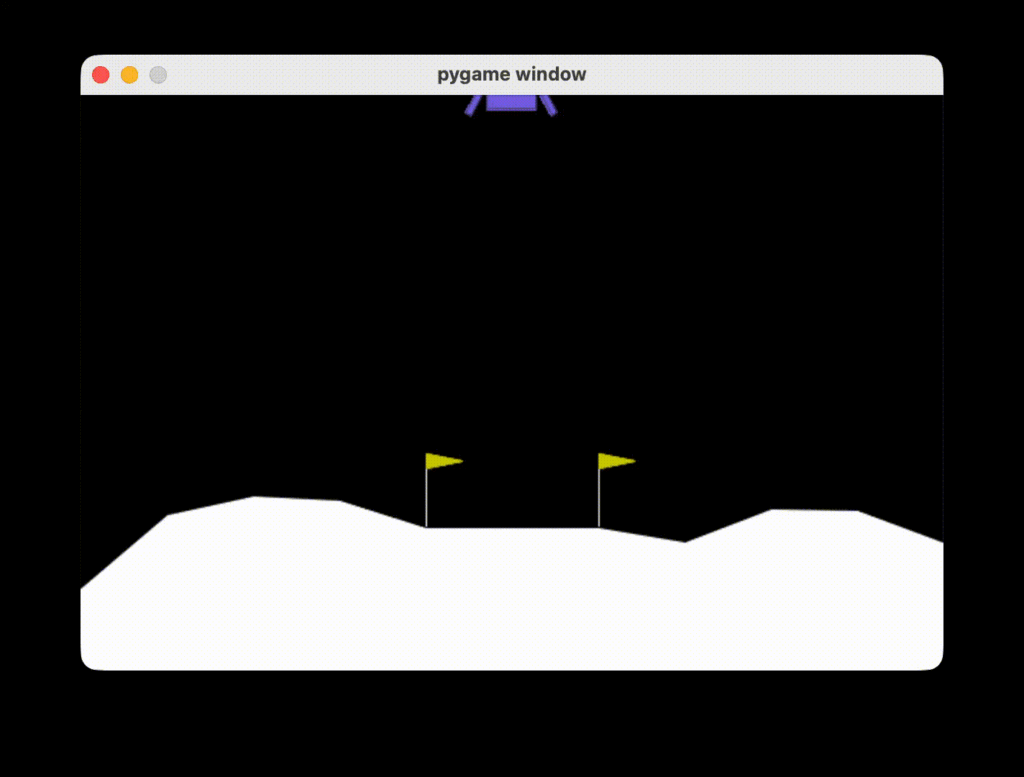
return float(loss.item())Lunar Lander
Lunar Lander 是一個經典的火箭軌跡最佳化問題。根據龐特里亞金最大值原理(Pontryagin’s maximum principle),在 optimal policy 下,引擎不是以全推力運作,就是完全關閉。因此,這個環境採用了離散動作空間,對應於引擎的開啟或關閉。
Action space 中共有四個 actions:
- 0:不執行任何動作。
- 1:啟動左側引擎。
- 2:啟動主引擎。
- 3:啟動右側引擎。
每一個 state 是一個 8 維向量,其內容依序包含:
- Lander 的 x 和 y 座標位置。
- Lander 在 x 和 y 的線性速度。
- Lander 的角度。
- Lander 的角速度。
- 兩個 boolean 值,分別表示 Lander 的左右腳是否與地面接觸。
對於每一個 time step,reward 為:
- Lander 越接近地面,reward 越高;反之,reward 越低。
- Lander 的移動速度越慢,reward 越高;反之,reward 越低。
- Lander 的傾斜角度越大,reward 越低。
- 每當有一隻腳與地面接觸時,reward 增加 10 分。
- 每一個 frame 中,只要側向的引擎啟動一次,reward 減少 0.03 分。
- 每一個 frame 中,只要主引擎啟動一次,reward 減少 0.3 分。
若 episode 以墜毀或安全著陸結束,則會額外給予一次性回饋:
- 墜毀:-100 分。
- 安全著陸:+100 分。
當一個 episode 的 total rewards 達到 200 分以上時,即被視為成功解(solution)。
以下的程式碼中,我們訓練 Expected Sarsa 和 Sarsa 1000 episodes。
import time
import gymnasium as gym
from expected_sarsa_nn import MLPExpectedSarsa
from sarsa_nn import MLPSarsa
GYM_ID = "LunarLander-v3"
N_EPISODES = 1000
MAX_STEPS = 10_000
ALGO = "Sarsa"
# ALGO = "Expected Sarsa"
def play_game(agent: MLPExpectedSarsa, episodes=1):
visual_env = gym.make(GYM_ID, render_mode="human")
for episode in range(episodes):
state, _ = visual_env.reset()
terminated = False
truncated = False
total_reward = 0.0
step_count = 0
input("Press Enter to play game")
print(f"Episode {episode + 1} starts")
while not terminated and not truncated:
action, _ = agent.act(state, greedy=True)
state, reward, terminated, truncated, _ = visual_env.step(action)
total_reward += reward
step_count += 1
visual_env.render()
print(f"Episode {episode + 1} is finished: Total reward is {total_reward}, steps = {step_count}")
time.sleep(1)
visual_env.close()
def train(env: gym.Env, agent: MLPExpectedSarsa):
for i_episode in range(1, N_EPISODES + 1):
print(f"\rEpisode: {i_episode}/{N_EPISODES}", end="", flush=True)
s, _ = env.reset()
done = False
G = 0.0
steps = 0
a, _ = agent.act(s)
while not done and steps < MAX_STEPS:
s_prime, r, terminated, truncated, _ = env.step(a)
G += r
done = terminated or truncated
if done:
a_prime = 0
else:
a_prime, _ = agent.act(s_prime)
agent.update(s, a, r, s_prime, done)
s, a = s_prime, a_prime
steps += 1
if __name__ == "__main__":
env = gym.make(GYM_ID)
if ALGO == "Sarsa":
agent = MLPSarsa(
observation_dim=env.observation_space.shape[0],
n_actions=env.action_space.n,
hidden_dim=256,
)
else:
agent = MLPExpectedSarsa(
observation_dim=env.observation_space.shape[0],
n_actions=env.action_space.n,
hidden_dim=256,
)
train(env, agent)
env.close()
play_game(agent)在相同的實驗設定下,我們分別以 Semi-Gradient Sarsa 與 Semi-Gradient Expected Sarsa,於 LunarLander 環境中訓練 agent 共 1000 個 episodes,結果呈現出截然不同的學習行為。Sarsa 的 agent 往往在訓練早期便頻繁墜毀。相對地,Expected Sarsa 的 agent 則傾向於採取較為保守的策略,並逐步學會減速、修正姿態,最終能以相對穩定的方式完成降落。
這樣的差異,可以直接從兩者 TD target 的定義方式 來理解。Semi-Gradient Sarsa 在每一次更新時,使用的是實際採取的下一個動作 所對應的 action-value 作為學習目標,因此 TD target 會強烈受到探索行為隨機性的影響。在 LunarLander 這類高風險的連續控制環境中,即使探索率 已相對不高,偶發的非 greedy 動作仍可能在接近地面時造成劇烈的姿態或速度變化,進而引發極端的負回饋。
這些高變異的 TD target 會被直接注入到參數更新之中。在函數近似的設定下,單一樣本的劇烈誤差不只影響當前狀態,還會透過參數共享擴散至其他狀態與動作。結果是,學到的 policy 容易出現過度修正或激進控制的行為模式,表現為快速但高度不穩定的動作,最終導致頻繁墜毀。
相較之下,Expected Sarsa 在 TD 更新時,並不依賴單一隨機動作,而是對下一個 state 下所有可能動作的 action-value 取期望值。這使得 exploring 行為所帶來的風險,被平均地納入學習訊號之中,從而大幅降低 TD target 的變異性。在函數近似的情境下,這種較為平滑的更新方向,能有效避免參數在連續更新中產生劇烈震盪,使 agent 更容易學會逐步減速、細緻修正姿態,並在接近地面時維持穩定控制。
因此,Expected Sarsa 雖然在初期的學習速度較慢,但最終展現出的行為更安全,也更符合任務本身對精細控制的要求。
綜合來看,這個實驗結果清楚說明:在 on-policy control with function approximation 的設定下,演算法之間的關鍵差異,並不在於是否使用神經網路,而在於 TD target 如何處理探索行為所引入的不確定性。Expected Sarsa 透過期望式的更新機制,在穩定性與學習效率之間取得了較佳的折衷,特別適合應用於像 LunarLander 這類對動作連續性與精細度高度敏感的控制問題。
結語
當 control 問題進入函數近似的設定後,學習行為的關鍵不再僅由演算法名稱所決定,而是取決於 TD target 的設計方式,以及其如何處理探索所引入的不確定性。在 on-policy 架構下,Semi-Gradient Sarsa 與 Expected Sarsa 共享相同的更新形式與實作流程,但僅僅因為 TD target 是否對下一步動作取期望,便展現出截然不同的穩定性與行為特徵。從 LunarLander 的實驗結果來看,Expected Sarsa 以較平滑的更新方向,換取了更穩定且安全的控制行為,清楚說明在 on-policy control with approximation 的情境中,穩定性往往比短期學習速度更為關鍵。這也再次強調,理解 TD 方法的本質,不應只停留在更新公式本身,而必須回到學習訊號如何被構造、以及它如何影響整體學習動態。
參考
- Adam White and Martha White. Reinforcement Learning Specialization. University of Alberta and Coursera.
- Richard S. Sutton and Andrew G. Barto. 2020. Reinforcement Learning: An Introduction, 2nd. The MIT Press.









