
在過去十年的自然語言處理(Natural Language Processing, NLP)領域中,生成式預訓練 Transformer 模型(Generative Pre-trained Transformer, GPT)無疑是最具指標性的技術之一。GPT 不僅重新定義了語言建模(language modeling)的方式,更掀起了以預訓練(pre-training)為核心的通用語言模型(general-purpose language models)革命。本文將從 GPT 的基本架構談起,並深入探討 GPT-1 至 GPT-3 的設計理念與技術演進。
GPT 架構
GPT 的全名是 Generative Pre-trained Transformers。顧名思義,它也是使用 transformers 架構。如果你還不熟悉 Transformers 的話,請先參考以下文章。

不過,GPT 僅使用 Transformer 的 decoder 部分,如下圖所示。由於未使用 encoder,因此也移除了 cross multi-head attention 的設計。
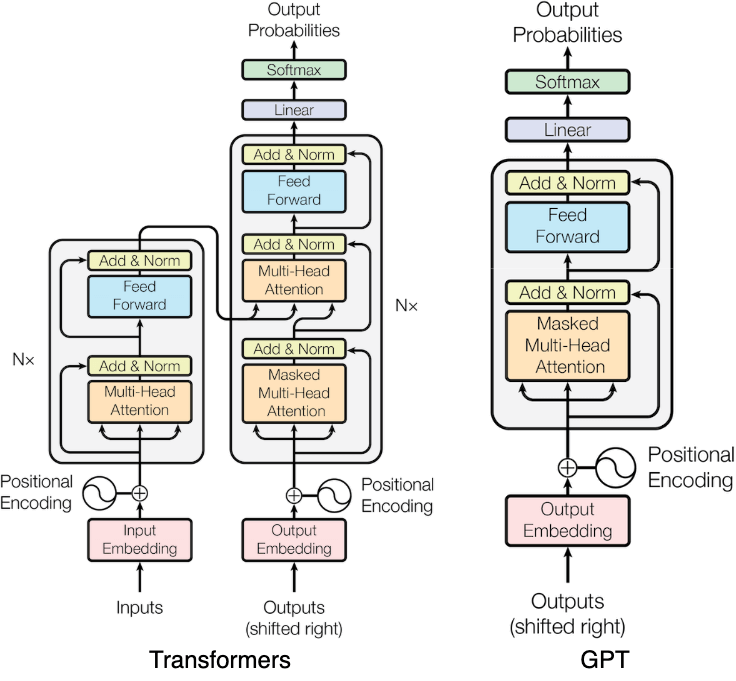
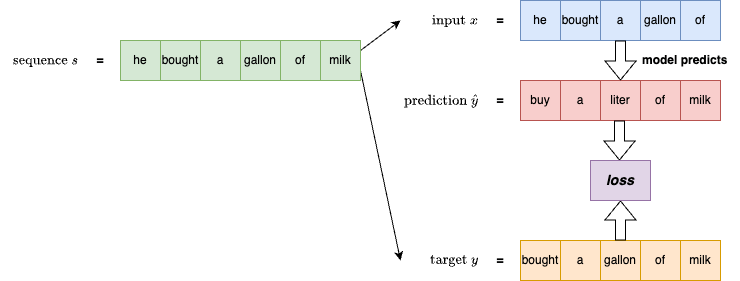
GPT 採用的語言建模目標(language modeling objective)為預測下一個 token,這種方式稱為因果語言建模(causal language modeling)。如下圖所示,左側為一個預訓練用的序列  ,將序列的前 n-1 個 token(s[:-1])作為模型輸入,並以後 n-1 個 token(s[1:])作為目標,模型則學習從輸入預測出下一個 token,透過誤差計算 loss 並更新參數。這類模型也被稱為 next-token language model。
,將序列的前 n-1 個 token(s[:-1])作為模型輸入,並以後 n-1 個 token(s[1:])作為目標,模型則學習從輸入預測出下一個 token,透過誤差計算 loss 並更新參數。這類模型也被稱為 next-token language model。
這樣的訓練方式屬於無監督預訓練(unsupervised pre-training),因為訓練資料不需標注(label)。這解決了大多數語料缺乏標註資料的問題,使我們可以大量蒐集語料來訓練模型。這不但讓模型能學習語言的統計規律,也讓它具備對世界知識的基本理解。
完成第一階段的 pre-training 後,第二階段可以針對特定任務進行微調(fine-tuning),例如分類、問答等 downstream tasks。這種先進行 pre-training、再透過 fine-tuning 的兩階段設計,不僅讓模型具備彈性,也成為 GPT 系列成功的關鍵因素。
接下來,我們將分別地介紹 GPT-1、GPT-2、和 GPT-3 設計理念與演進歷程。由於 GPT-3.5、GPT-4 及其後續的版本的完整未公開(僅公開技術報告和 system card),故將不予討論。
GPT-1
許多自然語言理解(natural language understanding, NLU)任務,例如文本蕴涵(textual entailment)、問答(question answering)、語意相似度評估(semantic similarity assessment)、文件分類(document classification)等,都高度依賴標註資料(labeled data)。然而,這些資料往往稀缺,導致模型難以訓練出良好的效果。相對地,未標註資料(unlabeled data)非常豐富。
OpenAI 的 Radford et al. 因此提出一個假設:是否可以透過 pre-training 一個大型語言模型,並僅進行極少量的 fine-tuning,就能在 downstream tasks 中達到優異表現?
他們提出一種半監督學習(semi-supervised learning)架構,分為兩個階段:
- 無監督預訓練(Unsupervised Pre-training):利用大量未標註的文本資料,對語言模型進行生成式預訓練(generative pre-training),使模型自行學習語言的語法與語意結構,並建立通用的語言表徵(universal representation)。
- 監督微調(Supervised Fine-tuning):在每個具體任務上,使用少量的標註資料對 pre-trained 模型進行 fine-tuning。這使模型幾乎無需改變架構,就能順利應對任務轉移(task transfer)。
這種方法的優點在於:與傳統必須為每個任務設計專屬模型的方式相比,GPT-1 僅需標準語言建模結構即可廣泛應用。它是第一個證明「單一語言模型可以透過少量 fine-tuning 遷移至多種任務」的實證研究,與同期 BERT 提出的 masked language modeling 路線形成明顯對比。
GPT-1 採用 decoder-only Transformer 架構,搭配 masked self-attention。相較於原始 Transformer 架構,其主要差異在於:
- 採用學習式位置嵌入(learned positional embeddings),而非正弦位置編碼(sinusoidal)。
- 使用 GELU(Gaussian Error Linear Unit)作為 activation function,而非 ReLU。
GPT-1 的模型規格如下,模型參數總數約 117M。
- vocab_size:使用 Byte Pair Encoding(BPE) 的詞彙表,約為 40,000 tokens。
- layers:12 層 decoder-only Transformer。
- d_model:每層使用 768 維度。
- heads:每層使用 12 個 attention heads。
- d_ff:Position-wise feedforward networks 為 3072 維度。
- context length:512 tokens。
訓練語料為 BooksCorpus,包含超過 7000 本未出版書籍,涵蓋多種主題與文體,總量約 5GB。這類長篇連續文本對模型學習長距依賴與上下文理解極為有利。
GPT-1 的貢獻:
- 提出以生成式預訓練(generative pre-training)為基礎、再經判別式微調(discriminative fine-tuning)的語言模型訓練流程。
- 證明 Transformer 能有效學習長距離語境並應用於各類 downstream tasks。
- 為後續 GPT 系列模型建立架構模板與遷移學習(transfer learning)的典範。
- 首度實證語言建模任務可作為多任務遷移(task transfer)的統一表示方法。
GPT-2
儘管 GPT-1 展現出強大的性能,其在多數任務上仍依賴 supervised fine-tuning,這讓它難以直接泛化到不同的任務與領域。當時大多數系統仍是「狹義專家」:針對單一任務訓練專屬模型,無法跨任務使用。
在 OpenAI 的 Radford et al. 進一步提出:如果只透過 pre-training,而不做任何 fine-tuning,模型是否就能解決downstream tasks?
這成為 GPT-2 的核心研究命題,也開啟了無監督多任務學習(unsupervised multitask learning)的時代。它將多任務資訊融入訓練語料中,而非依賴 downstream fine-tuning。此外,將任務描述也視為語言輸入,以自然語言的形式 prompt。這樣就可以保持訓練與推論目標一致,皆為預測下一個 token。GPT-2 整合任務、輸入、輸出為單一文字序列,完全對齊語言模型訓練邏輯。
Radford et al. 認為,傳統系統之所以無法泛化,是因為訓練語料過於侷限,未涵蓋足夠多樣的任務形式。因此,他們建立一個全新資料集 WebText,其內容來自 Reddit 上獲得至少 3 karma 的外部連結頁面(作為品質濾網),共收錄約 45M 網頁,總文本量達 40GB,重視自然語言中任務描述的真實樣貌與多樣性。
GPT-2 雖開創了 prompt-based 推理的應用,但其實驗仍以 zero-shot 任務表現為主,尚未大規模探討 one-shot 或 few-shot 設定(這部分由 GPT-3 承接並系統化)。因此,GPT-2 是 prompt-paradigm 的開端,但未達完整 few-shot 應用階段。
GPT-2 的模型規格如下,模型參數總數約 1.5B。
- vocab_size:50257 BPE tokens。
- layers:48。
- d_model:1600 維。
- heads:25。
- d_ff:6400。
- context length:1024。
GPT-2 採用與 GPT-1 類似的架構,但在一些細節上有所調整。LayerNorm 改為置於每個 sub-block 之前(pre-LM 結構)。承襲 decoder-only Transformer 架構,僅使用 self-attention。
GPT-2 的貢獻:
- 建立 prompt-based inference 概念。透過自然語言 prompt 引導模型執行任務,取代 fine-tuning 流程。
- 語言建模即多任務學習。純粹透過語料的設計,讓模型在訓練中接觸多種任務形式。
- 證明大型模型具備零樣本能力。GPT-2 能在未經 fine-tuning 下完成問答、翻譯、摘要等任務。
- 成為 GPT-3 語境學習(in-context learning)架構的前身。其實驗與設計為後續 few-shot 模型提供關鍵基礎。
這一代模型展現了語言建模作為通用任務框架的巨大潛力,也為 GPT-3 的誕生奠定了理論與實證基礎。
GPT-3
GPT-2 展示出透過純語言建模訓練即可完成多種 downstream tasks 的潛力。然而,它的能力仍有一個限制:若遇到全新任務(未出現在訓練語料中),仍需額外 fine-tuning 才能有效執行。而人類則不然,我們常常只需幾個例子,甚至只透過自然語言指示,就能理解並執行一項新任務。
這促使在 OpenAI 的 Brown et al. 提出一項假設:如果模型夠大,並且在訓練期間見過足夠多樣的任務形式,那麼是否可以僅依賴 prompt,讓模型在推論時學會新任務?
這正是 GPT-3 的核心:語境內學習(in-context learning)。
GPT-3 的架構延續 GPT-2,但引入 交錯的 dense 與 locally banded sparse attention,在訓練效率與資源分配間取得平衡。訓練的重點強調資料的多樣性與品質,訓練語料共 570GB,涵蓋 Common Crawl(經過嚴格過濾)、WebText、Books1、Books2、和 Wikipedia。不同於傳統 supervised fine-tuning,GPT-3 僅依靠大量文字序列學習任務邏輯與結構。
GPT-3 的模型如下,模型參數總數約 175B。
- vocab_size:50257 BPE tokens。
- layers:96。
- d_model:12288。
- heads:96。
- d_ff:49152。
- context length:2048。
GPT-3 透過三種語境學習設定在多任務上進行實驗:
- Zero-shot learning:只給任務描述,不給示例。
- One-shot learning:提供一個範例。
- Few-shot learning:提供多個範例(通常 10 到 100 筆)。
下圖顯示這三種設定與傳統的 fine-tuning。

這是首次大規模系統性評估 large language model 在 zero-/one-/few-shot 情境下的表現。GPT-3 論文顯示,few-shot learning 在多數任務上表現最佳,但在某些領域(如常識推理)仍略遜於 supervised fine-tuning baseline,這點在論文中有清楚指出,提醒使用者選擇場景時應有期待管理。
GPT-3 的貢獻:
- 提出 in-context learning 作為新學習策略。不依賴 fine-tuning,也無需參數更新,僅透過 prompt 即可學習任務模式。
- 證明 scale is all you need。只要模型足夠大,能力即可自然出現(emergent behavior)。
- 徹底改變 LLM 的使用方式。由微調轉向 prompt engineering,使用者透過設計輸入格式而非訓練模型來解任務。
- 提供 few-shot 能力的量化標準。開啟對大模型 few-shot 能力的系統化研究潮流,後續被 ChatGPT 延續。
這一代模型標誌著 LLM 即萬用引擎的實現,對 LLM 技術的推進意義非凡。
模型比較
下表彙整了 GPT-1、GPT-2、GPT-3 的模型設定與語料規模。如表中所示,從 GPT-1 到 GPT-3,參數與語料的規模呈指數級增長,也使得模型的能力跨越式提升。然而,訓練這類模型的成本極高,對於個人或一般企業而言難以負擔。
| Model | Model Size | Corpus Size | vocab_size | layers | d_model | heads | d_ff | ctx_len |
|---|---|---|---|---|---|---|---|---|
| GPT-1 | 117 M | 5 G | 40,000 | 12 | 768 | 12 | 3,072 | 512 |
| GPT-2 | 1.5 B | 40 G | 50,257 | 48 | 1,600 | 25 | 6,400 | 1,024 |
| GPT-3 | 175 B | 570 G | 50,257 | 96 | 12,288 | 96 | 49,152 | 2,048 |
實作
雖然 GPT-3 並未開源,但 OpenAI 曾釋出 GPT-2 的原始碼,並可作為我們學習其架構的絕佳範本。GPT-2 的官方實作使用 TensorFlow,本章將以 PyTorch 重寫並說明其關鍵部分。
模型架構
GPT 是 decoder-only Transformer 模型,基本結構與標準 Transformer 的 decoder 相似。因此,如果你還不太了解 Transformers 的話,請先參考以下文章。
以下是 GPT-2 的實作。輸入為 token ID 序列,加上 learned position embeddings。每層 attention 與 FFN 運算後接 LayerNorm 與 residual connections。
class CausalSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
assert config.d_model % config.n_head == 0
self.n_head = config.n_head
self.d_head = config.d_model // config.n_head
self.W_q = nn.Linear(config.d_model, config.d_model)
self.W_k = nn.Linear(config.d_model, config.d_model)
self.W_v = nn.Linear(config.d_model, config.d_model)
self.W_o = nn.Linear(config.d_model, config.d_model)
self.attention_dropout = nn.Dropout(config.attention_dropout_prob)
self.residual_dropout = nn.Dropout(config.residual_dropout_prob)
attention_mask = (torch.tril(torch.ones(config.n_positions, config.n_positions))
.view(1, 1, config.n_positions, config.n_positions))
self.register_buffer("attention_mask", attention_mask, persistent=False)
def forward(self, x):
"""
Causal self-attention forward pass.
Args
----
x: (batch_size, seq_len, d_model)
Returns
-------
output: (batch_size, seq_len, d_model)
"""
batch_size, seq_len, _ = x.shape
# (batch_size, seq_len, d_model) for Q, K, V
Q = self.W_q(x)
K = self.W_k(x)
V = self.W_v(x)
# (batch_size, n_head, seq_len, d_head) for Q, K, V
Q = Q.view(batch_size, seq_len, self.n_head, self.d_head).transpose(1, 2)
K = K.view(batch_size, seq_len, self.n_head, self.d_head).transpose(1, 2)
V = V.view(batch_size, seq_len, self.n_head, self.d_head).transpose(1, 2)
# Causal mask: we only allow attention to current and previous positions
mask = self.attention_mask[:, :, :seq_len, :seq_len]
attention, attention_weights = self.scaled_dot_product_attention(Q, K, V, mask)
attention = attention.transpose(1, 2).contiguous() # (batch_size, seq_len, n_head * d_head)
attention = attention.view(batch_size, seq_len, -1) # (batch_size, seq_len, d_model)
# Linear projection
output = self.W_o(attention)
output = self.residual_dropout(output)
return output
def scaled_dot_product_attention(self, Q, K, V, mask):
scores = Q @ K.transpose(-2, -1) / math.sqrt(self.d_head) # (batch_size, n_head, seq_len, seq_len)
scores = scores.masked_fill(mask == 0, float('-inf'))
weights = torch.softmax(scores, dim=-1) # (batch_size, n_head, seq_len, seq_len)
weights = self.attention_dropout(weights)
attention = weights @ V # (batch_size, n_head, seq_len, d_head)
return attention, weights
class FeedForward(nn.Module):
def __init__(self, config):
super().__init__()
self.linear1 = nn.Linear(config.d_model, config.d_ff)
self.activation = nn.GELU()
self.linear2 = nn.Linear(config.d_ff, config.d_model)
self.dropout = nn.Dropout(config.residual_dropout_prob)
def forward(self, x):
"""
Feed-forward network forward pass.
Args
----
x: (batch_size, seq_len, d_model)
Returns
-------
x: (batch_size, seq_len, d_model)
"""
return self.dropout(self.linear2(self.activation(self.linear1(x))))
class GPT2Block(nn.Module):
def __init__(self, config):
super().__init__()
self.layer_norm1 = nn.LayerNorm(config.d_model, eps=config.layer_norm_epsilon)
self.attention = CausalSelfAttention(config)
self.layer_norm2 = nn.LayerNorm(config.d_model, eps=config.layer_norm_epsilon)
self.ffn = FeedForward(config)
def forward(self, x):
"""
Transformer block forward pass.
Args
----
x: (batch_size, seq_len, d_model)
Returns
-------
x: (batch_size, seq_len, d_model)
"""
x = x + self.attention(self.layer_norm1(x))
x = x + self.ffn(self.layer_norm2(x))
return x
class GPT2Model(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.wte = nn.Embedding(config.vocab_size, config.d_model)
self.wpe = nn.Embedding(config.n_positions, config.d_model)
self.dropout = nn.Dropout(config.embedding_dropout_prob)
self.blocks = nn.ModuleList([GPT2Block(config) for _ in range(config.n_layer)])
self.layer_norm = nn.LayerNorm(config.d_model, eps=config.layer_norm_epsilon)
self.apply(self._init_weights)
def _init_weights(self, module):
if isinstance(module, nn.Linear):
nn.init.normal_(module.weight, std=self.config.initializer_range)
if module.bias is not None:
nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
nn.init.normal_(module.weight, std=self.config.initializer_range)
def forward(self, input_ids, position_ids=None):
"""
Model forward pass.
Args
----
input_ids: (batch_size, seq_len)
position_ids: (batch_size, seq_len)
Returns
-------
hidden_states: (batch_size, seq_len, d_model)
"""
batch_size, seq_len = input_ids.shape
if position_ids is None:
position_ids = torch.arange(seq_len, device=input_ids.device).unsqueeze(0).expand(batch_size, -1)
hidden_states = self.dropout(self.wte(input_ids) + self.wpe(position_ids))
for block in self.blocks:
hidden_states = block(hidden_states)
return self.layer_norm(hidden_states)最後一層輸出經 linear 投影至 vocab size,用於預測下一個 token。計算 loss 時,將 logits 對齊至 label(也就是將 input 向右偏移一個 token)。
class GPT2LMHeadModel(nn.Module):
def __init__(self, config):
super().__init__()
self.transformer = GPT2Model(config)
self.lm_head = nn.Linear(config.d_model, config.vocab_size, bias=False)
self.lm_head.weight = self.transformer.wte.weight # weight tying
def forward(self, input_ids, labels=None):
"""
Language model forward pass.
Args
----
input_ids: (batch_size, seq_len)
labels: (batch_size, seq_len)
Returns
-------
logits: (batch_size, seq_len, vocab_size)
loss: (optional) cross-entropy loss
"""
hidden_states = self.transformer(input_ids)
logits = self.lm_head(hidden_states)
loss = None
if labels is not None:
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
loss = F.cross_entropy(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
return logits, loss在 GPT-2 的論文中,Radford et al. 比較了多組不同設定的模型。其中最小的設定是下面程式碼中的第一組設定。而,最大的設定是下面程式碼中的第二組設定,使用這組設定的模型也被稱為 GPT-2 模型。
# Small config
@dataclass
class GPT2Config:
vocab_size: int = 50257
n_positions: int = 1024
d_model: int = 768
n_layer: int = 12
n_head: int = 12
d_ff: int = 3072
residual_dropout_prob: float = 0.1
embedding_dropout_prob: float = 0.1
attention_dropout_prob: float = 0.1
layer_norm_epsilon: float = 1e-5
initializer_range: float = 0.02
# Larget config
@dataclass
class GPT2Config:
vocab_size: int = 50257
n_positions: int = 1024
d_model: int = 1600
n_layer: int = 48
n_head: int = 25
d_ff: int = 6400
residual_dropout_prob: float = 0.1
embedding_dropout_prob: float = 0.1
attention_dropout_prob: float = 0.1
layer_norm_epsilon: float = 1e-5
initializer_range: float = 0.02Pre-training
在實作 GPT 的預訓練階段前,需準備合適的訓練語料。考量資源限制,我們選擇使用 Hugging Face 提供的 wikitext-2-raw-v1 資料集,其大小約為 10MB,遠小於 GPT-2 論文中的 WebText 資料集,但已足以觀察模型行為。
from pathlib import Path
from datasets import load_dataset
ds = load_dataset("wikitext", "wikitext-2-raw-v1", split="train")
out_path = "wikitext2_train.txt"
out_path = Path(out_path); out_path.parent.mkdir(parents=True, exist_ok=True)
with out_path.open("w", encoding="utf‑8") as f:
for line in ds["text"]:
line = line.strip()
if line: # skip blank lines
f.write(line + "\n")
print("Wrote", out_path, "with", len(ds), "rows")資料處理流程為,先將每一行文字轉為 token ID 序列,並將所有 token ID 串接成單一長序列,再切割成等長 segments。每個 segment 形成一筆訓練資料。這樣的輸入設定正好符合 causal language modeling 的訓練方式。只需使用 CrossEntropyLoss,模型便能學習預測下一個 token的能力。
class PretrainingDataset(Dataset):
def __init__(self, tokenizer, file_path: str, seq_len: int = 1024):
super().__init__()
self.seq_len = seq_len
all_ids: List[int] = []
with open(file_path, "r", encoding="utf-8") as f:
for line in f:
line = line.strip()
if not line:
continue
all_ids.extend(tokenizer.encode(line))
# drop the tail so we have an exact multiple of seq_len
total = len(all_ids) - (len(all_ids) % seq_len)
self.data = torch.tensor(all_ids[:total], dtype=torch.long).view(-1, seq_len)
def __len__(self):
return self.data.size(0)
def __getitem__(self, idx):
x = self.data[idx]
return x, x最後,以下是 pre-training 流程。這套 pre-training 流程亦適用於 GPT-3。儘管 GPT-3 與 GPT-2 在模型細節上有些差異,但整體架構與訓練方法基本相同,皆屬於 next-token language model。
def get_tokenizer():
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token # GPT‑2 has no pad token; reuse <EOS>
return tokenizer
def train_loop(model, dataloader, epochs: int, lr: float, save_dir: Path):
opt = torch.optim.AdamW(model.parameters(), lr=lr, betas=(0.9, 0.999), weight_decay=0.01)
scheduler = torch.optim.lr_scheduler.LinearLR(
opt, start_factor=1.0, end_factor=0.0, total_iters=len(dataloader) * epochs
)
global_step = 0
best_loss = float("inf")
save_dir.mkdir(parents=True, exist_ok=True)
for epoch in range(1, epochs + 1):
model.train()
running_loss = 0.0
for batch_idx, (input_ids, labels) in enumerate(dataloader):
sys.stdout.write(f"\rEpoch {epoch} Batch {batch_idx} / {len(dataloader)}")
sys.stdout.flush()
opt.zero_grad()
_, loss = model(input_ids, labels=labels)
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), 1.0)
opt.step()
scheduler.step()
running_loss += loss.item()
global_step += 1
avg_loss = running_loss / len(dataloader)
print(f",\ttrain_loss={avg_loss:.4f}")
# simple checkpointing
torch.save(model.state_dict(), save_dir / "last.pt")
if avg_loss < best_loss:
best_loss = avg_loss
torch.save(model.state_dict(), save_dir / "best.pt")
def pretrain():
tokenizer = get_tokenizer()
dataset = PretrainingDataset(tokenizer, "wikitext2_train.txt")
dataloader = DataLoader(dataset, batch_size=8, sampler=RandomSampler(dataset))
model = GPT2LMHeadModel(GPT2Config())
train_loop(model, dataloader, epochs=5, lr=2.5e-4, save_dir=Path("./model"))
pretrain()
# Output:
Epoch 1 Batch 286 / 287, train_loss=6.9670
Epoch 2 Batch 286 / 287, train_loss=6.1676
Epoch 3 Batch 286 / 287, train_loss=5.8620
Epoch 4 Batch 286 / 287, train_loss=5.6536
Epoch 5 Batch 286 / 287, train_loss=5.5112Sampling
完成 pre-training 後,我們可以利用模型進行文字生成。這類應用廣泛,例如對話系統、文本補全、文章撰寫等。程式碼中,我們用到常見的 temperature、top_k、和 top_p。它們的作用大致為:
- temperature:調整 logits 的平滑程度。在 softmax 前做 logits / temperature。
- temperature > 1:增加隨機性(平坦分佈)
- temperature < 1:降低隨機性(尖銳分佈)
- top_k:僅保留機率前 k 高的 token,其他設為 −∞,避免選擇低機率 token。
- top_p:依機率累加排序,保留總機率超過 p 的最小 token 子集,其餘設為 −∞。
透過這些策略可在控制生成品質與增加創造性之間取得平衡。
def sample(
model: GPT2LMHeadModel, tokenizer, prompt: str, max_new_tokens: int = 100,
temperature: float = 1.0, top_k: int = 0, top_p: float = 0.9,
) -> str:
model.eval()
with torch.no_grad():
input_ids = torch.tensor([tokenizer.encode(prompt)])
for _ in range(max_new_tokens):
logits, _ = model(input_ids[:, -model.transformer.config.n_positions:])
logits = logits[:, -1, :] / max(temperature, 1e-5)
if top_k > 0:
top_k = min(top_k, logits.size(-1))
kth_vals = torch.topk(logits, top_k)[0][..., -1, None]
logits = logits.where(logits >= kth_vals, torch.full_like(logits, -float("inf")))
if top_p < 1.0:
sorted_logits, sorted_idx = torch.sort(logits, descending=True)
sorted_probs = torch.softmax(sorted_logits, dim=-1)
cumprobs = sorted_probs.cumsum(dim=-1)
keep_mask = cumprobs <= top_p
keep_mask[..., 0] = True # always keep the best token
remove_idx = sorted_idx[~keep_mask]
logits[0, remove_idx] = -float("inf")
probs = torch.softmax(logits, dim=-1)
if torch.isnan(probs).any() or torch.isinf(probs).any():
next_token = torch.argmax(logits, dim=-1, keepdim=True)
else:
next_token = torch.multinomial(probs, num_samples=1)
input_ids = torch.cat([input_ids, next_token], dim=-1)
if next_token.item() == tokenizer.eos_token_id:
break
return tokenizer.decode(input_ids[0], skip_special_tokens=True)
def generate(model_path):
model = GPT2LMHeadModel(GPT2Config())
model.load_state_dict(torch.load(model_path, map_location="cpu", weights_only=True))
tokenizer = get_tokenizer()
prompt = "Q: What is Valkyria Chronicles? A:"
output = sample(model, tokenizer, prompt, max_new_tokens=100, temperature=1.0, top_k=0, top_p=0.9)
print(f"Prompt=> {prompt}")
print(f"Output=> {output}")
generate("./model/best.pt")Fine-tuning
雖然 GPT-2 和 GPT-3 論文皆未對模型進行 downstream 任務的 supervised fine-tuning(分別聚焦於 zero-shot 與 in-context learning),但其架構與訓練方式仍支援 fine-tuning 機制。
Fine-tuning 的兩種應用方向:
- Continued Pre-training:使用新的未標註語料進行額外 pre-training,學習特定領域的語言模式(如醫療、法律文本)。
- Supervised Fine-tuning:利用標註資料針對特定任務(如情感分析、問答、對話)進行 fine-tuning。
這兩種方式皆在工業界被廣泛應用,特別是在後續的指令微調(instruction tuning)、RLHF(reinforcement learning from human feedback)等工作流程中發揮關鍵作用。
在實作上,只需將 downstream task 格式整理為文字輸入(prompt)與目標輸出(label),即可利用 pre-trained 模型進行 fine-tuning。
以下程式碼展示如何對 pre-trained 模型做 fine-tuning。
fine_tuning_examples = [
{"prompt": "Q: Who wrote Frankenstein?", "response": "Mary Shelley."},
{"prompt": "Translate to Spanish: Hello!", "response": "Hola!"},
{"prompt": "Summarize: GPT‑2 is", "response": "GPT‑2 is a language model released by OpenAI."}
]
class PromptResponseDataset(Dataset):
def __init__(self, tokenizer, json: list[dict[str, str]], seq_len: int = 1024, eos_token: str = "\n"):
self.seq_len = seq_len
examples: List[torch.Tensor] = []
for obj in json:
text = obj["prompt"] + eos_token + obj["response"] + eos_token
tokens = tokenizer.encode(text)[: seq_len]
padding = [tokenizer.eos_token_id] * (seq_len - len(tokens))
examples.append(torch.tensor(tokens + padding, dtype=torch.long))
self.data = torch.stack(examples)
def __len__(self):
return self.data.size(0)
def __getitem__(self, idx):
x = self.data[idx]
return x, x
def fine_tune():
tokenizer = get_tokenizer()
dataset = PromptResponseDataset(tokenizer, fine_tuning_examples)
dataloader = DataLoader(dataset, batch_size=4, sampler=RandomSampler(dataset))
model = GPT2LMHeadModel(GPT2Config())
model.load_state_dict(torch.load("./model/best.pt", map_location="cpu", weights_only=True))
train_loop(model, dataloader, epochs=5, lr=2.5e-4, save_dir=Path("./model_fine_tuned"))
fine_tune()下程式碼利用 fine-tuned 模型來生成文字。
def generate(model_path):
model = GPT2LMHeadModel(GPT2Config())
model.load_state_dict(torch.load(model_path, map_location="cpu", weights_only=True))
tokenizer = get_tokenizer()
prompt = "Q: Who wrote Frankenstein? A:"
output = sample(model, tokenizer, prompt, max_new_tokens=100, temperature=1.0, top_k=0, top_p=0.9)
print(f"Prompt=> {prompt}")
print(f"Output=> {output}")
generate("./model_fine_tuned/best.pt")計算模型大小
了解模型參數量對資源預估與部署成本非常關鍵。
GPT-2 模型使用以下的設定:
@dataclass
class GPT2Config:
vocab_size: int = 50257
n_positions: int = 1024
d_model: int = 1600
n_layer: int = 48
n_head: int = 25
d_ff: int = 6400
residual_dropout_prob: float = 0.1
embedding_dropout_prob: float = 0.1
attention_dropout_prob: float = 0.1
layer_norm_epsilon: float = 1e-5
initializer_range: float = 0.02累加模型中各部分的參數,即可算出 GPT-2 模型約 1.56 億個參數,對應 OpenAI 所公開的 1.5B 規模。你也可以利用類似邏輯自行估算任意 Transformer 模型的參數數量。
vocab_size = 50257
n_positions = 1024
d_model = 1600
d_ff = 6400
n_layer = 48
w_qkv = 3 * d_model * d_model
b_qkv = 3 * d_model
w_out, b_out = d_model * d_model, d_model
self_attention = w_qkv + b_qkv + w_out + b_out
print(f"self_attention={self_attention:,}") # 10,246,400
w1, b1 = d_model * d_ff, d_ff
w2, b2 = d_ff * d_model, d_model
feedforward = w1 + b1 + w2 + b2
print(f"feedforward={feedforward:,}") # 20,488,000
layer_norm_1_2 = 4 * d_model
block = self_attention + feedforward + layer_norm_1_2
print(f"block={block:,}") # 30,740,800
wte = vocab_size * d_model
wpe = n_positions * d_model
blocks = n_layer * block
layer_norm = 2 * d_model
model_params = wte + wpe + blocks + layer_norm
print(f"model_params = {model_params:,}") # 1,557,611,200 (~1.56 B)
結語
從 GPT-1 採用 pre-training 搭配 fine-tuning 的架構開始,接著發展到 GPT-2 僅透過 pre-training 結合 prompt 推理的方式,再到 GPT-3 所實現的 few-shot 通用模型,GPT 系列徹底改變了自然語言處理的發展向。
幾個關鍵的變革包括:
- 不再需要針對每個任務訓練獨立模型。一個統一架構就能應對各種任務。
- 語言模型具備世界知識與語言理解能力,可直接用於生成與推論。
- Prompt 設計成為新時代的編程技巧。人類學會如何與模型溝通,而不是訓練它。
這場從 117M 到 175B 參數的演進,不僅是模型規模的擴張,更是對語言理解與知識泛化能力的深度探索。GPT 不只讓語言模型成為 AI 應用的核心引擎,也促使我們重新思考學習本身的意義。
參考
- Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving Language Understanding by Generative Pre-Training. OpenAI.
- Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language Models are Unsupervised Multitask Learners. OpenAI.
- Tom B. Brown, Benjamin Mann, Nick Pyder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language Models are Few-Shot Learners. OpenAI.
- GPT-2 source code.









