
注意力機制(Attention mechanism)是深度學習中的一種方法,它讓模型在產生其輸出的每個部分時專注於其輸入中最相關的部分。相較於傳統 sequence models 經常難以處理較長的輸入,attention 允許模型在產生輸出序列的每個部分時動態地聚焦輸入序列的不同部分。
Table of Contents
注意力機制(Attention Mechanism)
傳統的 neural sequence model(如簡單的 encoder-decoder)將讀取整個輸入 sequence,然後嘗試將其全部壓縮為單一向量(context vector 或 thought vector)。我們可以將這個向量想成是輸入資訊的 summary。這個單一向量用於產生每個輸出。問題是單一的 summary 可能會遺失有關輸入的重要細節。如果還不太了解 sequence model 的話,可以先參考以下文章。

Attention 透過讓模型在每次產生輸出時分別查看輸入的不同部分來解決此問題。它不是使用單一的輸入 summary,而是使用一組權重來表示在預測下一個輸出時輸入的每個部分應該有多重要。因此,attention model 使神經網路能夠根據上下文動態調整輸入 sequence 中各元素的重要性。
注意力機制中兩種著名的類型是 Bahdanau Attention 和 Luong Attention。
Bahdanau Attention
由 D. Bahdanau et al. 在 2015 年提出,也因此被稱為 Bahdanau attention。它使用一個 alignment model 來計算 decoder 的前一個 hidden state 與每個 encoder 的 hidden state 之間的 alignment scores,然後透過應用這些 attention weights 來產成 context vector。
下圖是一個 Bahdanau attention 模型。我們在 encoder 裡使用一層 bi-directional GRU(BiGRU),而在 decoder 則是使用一層 uni-directional GRU。在該 paper 中,Bahdanau 使用一個非常類似於 GRU 的模型,因此我們這邊直接使用 GRU。當然,encoder 和 decoder 也可以使用其他的 RNN 模型,也可以是 multi-layers 的 RNN。當 encoder 使用 bi-directional RNN 時,那我們要將它 forward 和 backward 的 hidden state 垂直地堆疊起來。

在 encoder 輸出所有的 hidden states 後,我們用以下的式子來計算 context vector。對於 context vector 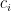 ,先用 alignment model
,先用 alignment model  先計算在 time step
先計算在 time step  對每個 encoder hidden state
對每個 encoder hidden state  的 energy
的 energy  。Alignment model 對在位置
。Alignment model 對在位置  周圍的輸入和位置 的輸出之間進行匹配評分。這個 就是 alignment score。然後,再用
周圍的輸入和位置 的輸出之間進行匹配評分。這個 就是 alignment score。然後,再用 softmax 計算對每個 encoder hidden state 的 weight  。這個 weight 可以決定每個 encoder hidden state 對 context vector 的重要性,因此將它們相乘後在相加就是最後的 context vector。
。這個 weight 可以決定每個 encoder hidden state 對 context vector 的重要性,因此將它們相乘後在相加就是最後的 context vector。

最後,計算出來的 context vector 、上一個輸出 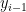 、和一個 decoder hidden state
、和一個 decoder hidden state  會作為目前 time step 的 RNN 的輸入。
會作為目前 time step 的 RNN 的輸入。

Alignment model 是一個前饋神經網路(feed-forward neural network),並與系統所有的 components 一起進行聯合訓練。它將 和 先經過 linear transformations 後,再將它們相加起來。因此 Bahdanau attention 也被稱為 additive attention。
Bahdanau Attention 實作
現在我們來實作上圖中的 Bahdanau attention 模型。以下是 encoder 的實作,它使用一個 bi-directional GRU(BiGRU)。我們在最後使用一個 full connected layer 來轉換 encoder hidden states 的維度,使得符合 decoder 的預期維度。
class BahdanauAttentionEncoder(nn.Module):
def __init__(self, input_dim, embed_dim, encoder_hidden_dim, decoder_hidden_dim):
super(BahdanauAttentionEncoder, self).__init__()
self.embedding = nn.Embedding(input_dim, embed_dim)
self.gru = nn.GRU(embed_dim, encoder_hidden_dim, num_layers=1, batch_first=True, bidirectional=True)
self.fc = nn.Linear(encoder_hidden_dim * 2, decoder_hidden_dim)
def forward(self, src):
"""
Args
src: (batch_size, src_len)
Returns
all_hidden: (batch_size, src_len, encoder_hidden_dim * 2)
decoder_hidden_init: (batch_size, decoder_hidden_dim)
"""
embedded = self.embedding(src) # (batch_size, src_len, embed_dim)
# all_hidden: (batch_size, src_len, hidden_dim * 2)
# final_hidden_state: (num_layers * 2, batch_size, hidden_dim)
all_hidden, final_hidden = self.gru(embedded)
# Map to decoder's initial hidden state
final_forward_hidden = final_hidden[-2, :, :]
final_backward_hidden = final_hidden[-1, :, :]
hidden_cat = torch.cat((final_forward_hidden, final_backward_hidden), dim=1)
decoder_hidden_init = self.fc(hidden_cat) # (batch_size, decoder_hidden_dim)
return all_hidden, decoder_hidden_init以下實作 weight 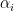 的計算。
的計算。
class BahdanauAttention(nn.Module):
def __init__(self, encoder_hidden_dim, decoder_hidden_dim, attention_dim):
super(BahdanauAttention, self).__init__()
self.W = nn.Linear(decoder_hidden_dim, attention_dim)
self.U = nn.Linear(encoder_hidden_dim * 2, attention_dim)
self.v = nn.Linear(attention_dim, 1, bias=False)
def forward(self, decoder_hidden, encoder_all_hidden):
"""
Args
decoder_hidden: (batch_size, decoder_hidden_dim)
encoder_all_hidden: (batch_size, src_len, encoder_hidden_dim * 2)
Returns
alpha: (batch_size, src_len)
"""
Ws = self.W(decoder_hidden).unsqueeze(1) # (batch_size, 1, decoder_hidden_dim)
Uh = self.U(encoder_all_hidden) # (batch_size, src_len, attention_dim)
energy = self.v(torch.tanh(Ws + Uh)) # (batch_size, src_len, 1)
energy = energy.squeeze(2) # (batch_size, src_len)
alpha = torch.softmax(energy, dim=1) # (batch_size, src_len)
return alpha以下是 decoder 的實作。它使用一個 uni-directional GRU。在計算出 context vector 後,它將 context vector 與當然的輸入垂直地堆疊起來作爲 GRU 的輸入。
class BahdanauAttentionDecoder(nn.Module):
def __init__(self, output_dim, embed_dim, decoder_hidden_dim, encoder_hidden_dim, attention_dim):
super(BahdanauAttentionDecoder, self).__init__()
self.embedding = nn.Embedding(output_dim, embed_dim)
self.attention = BahdanauAttention(encoder_hidden_dim, decoder_hidden_dim, attention_dim)
self.gru = nn.GRU(
embed_dim + encoder_hidden_dim * 2, decoder_hidden_dim, num_layers=1, batch_first=True, bidirectional=False,
)
self.fc = nn.Linear(decoder_hidden_dim, output_dim)
def forward(self, input_token, decoder_hidden, encoder_all_hidden):
"""
Args
input_token: (batch_size)
decoder_hidden: (batch_size, decoder_hidden_dim)
encoder_all_hidden: (batch_size, src_len, encoder_hidden_dim * 2)
Returns
prediction: (batch_size, output_dim)
final_hidden: (batch_size, decoder_hidden_dim)
"""
input_token = input_token.unsqueeze(1) # (batch_size, 1)
embedded = self.embedding(input_token) # (batch_size, 1, embed_dim)
alpha = self.attention(decoder_hidden, encoder_all_hidden) # (batch_size, src_len)
alpha = alpha.unsqueeze(1) # (batch_size, 1, src_len)
context = torch.bmm(alpha, encoder_all_hidden) # (batch_size, 1, encoder_hidden_dim * 2)
rnn_input = torch.cat((embedded, context), dim=2) # (batch_size, 1, embed_dim + encoder_hidden_dim * 2)
decoder_hidden = decoder_hidden.unsqueeze(0) # (1, batch_size, decoder_hidden_dim)
# all_hidden: (batch_size, 1, decoder_hidden_dim)
# final_hidden: (1, batch_size, decoder_hidden_dim)
all_hidden, final_hidden = self.gru(rnn_input, decoder_hidden)
final_hidden = final_hidden.squeeze(0) # (batch_size, decoder_hidden_dim)
prediction = self.fc(all_hidden.squeeze(1)) # (batch_size, output_dim)
return prediction, final_hidden以下將 encoder、attention、與 decoder 整合起來。
class BahdanauAttentionModel(nn.Module):
def __init__(self, encoder, decoder):
super(BahdanauAttentionModel, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, src, tgt, teacher_forcing_ratio=0.5):
"""
Args
src: (batch_size, src_len)
tgt: (batch_size, tgt_len)
teacher_forcing_ratio: float - probability to use teacher forcing
Returns
outputs: (batch_size, tgt_len, tgt_vocab_size)
"""
batch_size, tgt_len = tgt.shape
tgt_vocab_size = self.decoder.fc.out_features
outputs = torch.zeros(batch_size, tgt_len, tgt_vocab_size)
encoder_all_hidden, decoder_hidden = self.encoder(src)
input_token = tgt[:, 0]
for t in range(1, tgt_len):
prediction, decoder_hidden = self.decoder(input_token, decoder_hidden, encoder_all_hidden)
outputs[:, t] = prediction
teacher_force = torch.rand(1).item() < teacher_forcing_ratio
input_token = tgt[:, t] if teacher_force else prediction.argmax(1)
return outputsLuong Attention
由 M. Luong et al. 在 2015 年提出,也因此被稱為 Luong attention。他提出三種 alignment scores 的計算方法。這些方法主要是透過 dot products 來簡化計算 encoder 和 decoder 的 hidden states 之間的 alignment scores。另外,他還提中兩種 attentions,分別為 global attention 和 local attention。
Global attention 模型主要的想法是,當 decoder 當在計算 context vector ,它要考慮所有的 encoder hidden states,如同 Bahdanau attention。Global attention 有一個缺點,就是每一個輸出字必須關注(attend)所有的輸入字。這樣的計算量是相當昂貴的,而且在翻譯較長的 sequence 變得不切實際。Local attention 可以讓每一個輸出字選擇只專注一小部分的輸入字。本文章將只有介紹 global attention。
下圖是一個 Luong global attention 模型。我們在 encoder 裡使用一層 bi-directional LSTM(BiLSTM),而在 decoder 則是使用一層 uni-directional LSTM。當然,encoder 和 decoder 也可以使用其他的 RNN 模型,也可以是 multi-layers 的 RNN。當 encoder 使用 bi-directional RNN 時,那我們要將它 forward 和 backward 的 hidden state 垂直地堆疊起來。

計算 context vector 與 weight 的方法與 Bahdanau 的方法相同。然而,在計算 alignment scores 時,Luong attention 使用的是當前 decoder 的 hidden state。

我們來看一下這三個函式:
- Dot:它對目前 decoder 的 hidden state
 與每一個 encoder 的 hidden state 做 dot product。
與每一個 encoder 的 hidden state 做 dot product。 - General:基於 dot 函式,它引入一個 learnable parameter 。
- Concat:基本上,這個與 Bahdanau 的 alignment model 很相似,差別在於使用當前的 decoder 的 hidden state 並且只有使用乘法運算。
 。
。在得出 context vector 之後,將它與 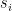 做一些運算後,就直接被用來預測輸出,這點與 Bahdanau attention 不同。Bahdanau attention 將得出的 context vector 做為 decoder 中的 RNN 的輸入。
做一些運算後,就直接被用來預測輸出,這點與 Bahdanau attention 不同。Bahdanau attention 將得出的 context vector 做為 decoder 中的 RNN 的輸入。

在三個 alignment score 函式中,dot 函式是最簡單也是最被 cited 最多。因此 Luong attention 也被稱為 dot attention。
Luong Attention 實作
現在我們來實作上圖中的 Luong attention 模型。以下是 encoder 的實作,它使用一個 bi-directional LSTM(BiLSTM)。我們在最後使用一個 full connected layer 來轉換 encoder hidden states 的維度,使得符合 decoder 的預期維度。此 encoder 基本上與 Bahdanau attention 的 encoder 相同,只是內部使用不同的 RNN。
class LuongAttentionEncoder(nn.Module):
def __init__(self, input_dim, embed_dim, encoder_hidden_dim, decoder_hidden_dim):
super(LuongAttentionEncoder, self).__init__()
self.embedding = nn.Embedding(input_dim, embed_dim)
self.lstm = nn.LSTM(embed_dim, encoder_hidden_dim, num_layers=1, batch_first=True, bidirectional=True)
self.fc = nn.Linear(encoder_hidden_dim * 2, decoder_hidden_dim)
def forward(self, src):
"""
Args
src: (batch_size, src_len)
Returns
all_hidden: (batch_size, src_len, decoder_hidden_dim)
decoder_hidden_init: (batch_size, decoder_hidden_dim)
decoder_cell_init: (batch_size, decoder_hidden_dim)
"""
embedded = self.embedding(src) # (batch_size, src_len, embed_dim)
# all_hidden: (batch_size, src_len, encoder_hidden_dim * 2)
# final_hidden, final_cell: (num_layers * 2, batch_size, encoder_hidden_dim)
all_hidden, (final_hidden, final_cell) = self.lstm(embedded)
# Map to decoder's initial hidden and cell states
final_forward_hidden = final_hidden[-2, :, :]
final_backward_hidden = final_hidden[-1, :, :]
final_hidden = torch.cat((final_forward_hidden, final_backward_hidden), dim=1)
final_forward_cell = final_cell[-2, :, :]
final_backward_cell = final_cell[-1, :, :]
final_cell = torch.cat((final_forward_cell, final_backward_cell), dim=1)
decoder_hidden_init = self.fc(final_hidden) # (batch_size, decoder_hidden_dim)
decoder_cell_init = self.fc(final_cell) # (batch_size, decoder_hidden_dim)
b, s, d = all_hidden.shape
all_hidden_2d = all_hidden.view(b * s, d)
all_hidden_2d = self.fc(all_hidden_2d)
all_hidden = all_hidden_2d.view(b, s, self.fc.out_features) # (batch_size, src_len, decoder_hidden_dim)
return all_hidden, decoder_hidden_init, decoder_cell_init以下是 dot score function 的實作。
class LuongDotAttention(nn.Module):
def __init__(self):
super(LuongDotAttention, self).__init__()
def forward(self, decoder_hidden, encoder_all_hidden):
"""
Args
decoder_hidden: (batch_size, decoder_hidden_dim)
encoder_all_hidden: (batch_size, src_len, decoder_hidden_dim)
Returns
alpha: (batch_size, src_len)
"""
decoder_hidden = decoder_hidden.unsqueeze(1) # (batch_size, 1, decoder_hidden_dim)
scores = torch.bmm(decoder_hidden, encoder_all_hidden.transpose(1, 2)) # (batch_size, 1, src_len)
scores = scores.squeeze(1) # (batch_size, src_len)
alpha = torch.softmax(scores, dim=1) # (batch_size, src_len)
return alpha以下是 general score function 的實作。
class LuongGeneralAttention(nn.Module):
def __init__(self, decoder_hidden_dim):
super(LuongGeneralAttention, self).__init__()
self.W_a = nn.Linear(decoder_hidden_dim, decoder_hidden_dim, bias=False)
def forward(self, decoder_hidden, encoder_all_hidden):
"""
Args
decoder_hidden: (batch_size, decoder_hidden_dim)
encoder_all_hidden: (batch_size, src_len, decoder_hidden_dim)
Returns
alpha: (batch_size, src_len)
"""
encoder_all_hidden_transformed = self.W_a(encoder_all_hidden) # (batch_size, src_len, decoder_hidden_dim)
decoder_hidden = decoder_hidden.unsqueeze(1) # (batch_size, 1, decoder_hidden_dim)
scores = torch.bmm(decoder_hidden, encoder_all_hidden_transformed.transpose(1, 2)) # (batch_size, 1, src_len)
scores = scores.squeeze(1) # (batch_size, src_len)
alpha = torch.softmax(scores, dim=1) # (batch_size, src_len)
return alpha以下是 concat score function 的實作。
class LuongConcatAttention(nn.Module):
def __init__(self, decoder_hidden_dim):
super(LuongConcatAttention, self).__init__()
self.W_a = nn.Linear(decoder_hidden_dim * 2, decoder_hidden_dim, bias=False)
self.v = nn.Linear(decoder_hidden_dim, 1, bias=False)
def forward(self, decoder_hidden, encoder_all_hidden):
"""
Args
decoder_hidden: (batch_size, decoder_hidden_dim)
encoder_all_hidden: (batch_size, src_len, decoder_hidden_dim)
Returns
alpha: (batch_size, src_len)
"""
b, s, d = encoder_all_hidden.shape
decoder_hidden_expanded = decoder_hidden.unsqueeze(1).expand(-1, s, -1) # (batch_size, src_len, hidden_dim)
concat_input = torch.cat((decoder_hidden_expanded, encoder_all_hidden), dim=2) # (batch_size, src_len, hidden_dim * 2)
concat_output = torch.tanh(self.W_a(concat_input)) # (batch_size, src_len, hidden_dim)
scores = self.v(concat_output) # (batch_size, src_len, 1)
scores = scores.squeeze(2) # (batch_size, src_len)
alpha = torch.softmax(scores, dim=1) # (batch_size, src_len)
return alpha以下是 decoder 的實作。它使用一個 uni-directional LSTM。與 Bahdanau attention 的 decoder 設計相當不同。它先計算出當前的 hidden state 後,才去計算 context vector 。
class LuongAttentionDecoder(nn.Module):
def __init__(self, attention, output_dim, embed_dim, decoder_hidden_dim):
super(LuongAttentionDecoder, self).__init__()
self.embedding = nn.Embedding(output_dim, embed_dim)
self.lstm = nn.LSTM(embed_dim, decoder_hidden_dim, num_layers=1, batch_first=True)
self.attention = attention
self.W_c = nn.Linear(decoder_hidden_dim * 2, decoder_hidden_dim)
self.W_s = nn.Linear(decoder_hidden_dim, output_dim)
def forward(self, input_token, decoder_hidden, decoder_cell, encoder_all_hidden):
"""
Args
input_token: (batch_size)
decoder_hidden: (batch_size, decoder_hidden_dim)
decoder_cell: (batch_size, decoder_hidden_dim)
encoder_all_hidden: (batch_size, src_len, decoder_hidden_dim)
Returns
prediction: (batch_size, output_dim)
final_hidden: (batch_size, hidden_dim)
final_cell: (batch_size, hidden_dim)
"""
input_token = input_token.unsqueeze(1) # (batch_size, 1)
embedded = self.embedding(input_token) # (batch_size, 1, embed_dim)
decoder_hidden = decoder_hidden.unsqueeze(0) # (1, batch_size, hidden_dim)
decoder_cell = decoder_cell.unsqueeze(0) # (1, batch_size, hidden_dim)
# decoder_all_hidden: (batch_size, 1, hidden_dim)
# final_hidden, final_cell: (1, batch_size, hidden_dim)
decoder_all_hidden, (final_hidden, final_cell) = self.lstm(embedded, (decoder_hidden, decoder_cell))
final_hidden = final_hidden.squeeze(0) # (batch_size, hidden_dim)
final_cell = final_cell.squeeze(0) # (batch_size, hidden_dim)
alpha = self.attention(final_hidden, encoder_all_hidden) # (batch_size, src_len)
alpha = alpha.unsqueeze(1) # (batch_size, 1, src_len)
context = torch.bmm(alpha, encoder_all_hidden) # (batch_size, 1, hidden_dim)
context = context.squeeze(1) # (batch_size, hidden_dim)
hidden_cat = torch.cat((context, final_hidden), dim=1) # (batch_size, hidden_dim * 2)
luong_hidden = torch.tanh(self.W_c(hidden_cat)) # (batch_size, hidden_dim)
prediction = self.W_s(luong_hidden) # (batch_size, output_dim)
return prediction, final_hidden, final_cell以下將 encoder、attention、與 decoder 整合起來。
class LuongAttentionModel(nn.Module):
def __init__(self, encoder, decoder):
super(LuongAttentionModel, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, src, tgt, teacher_forcing_ratio=0.5):
"""
Args
src: (batch_size, src_len)
tgt: (batch_size, tgt_len)
teacher_forcing_ratio: float - probability to use teacher forcing
Returns
outputs: (batch_size, tgt_len, tgt_vocab_size)
"""
batch_size, tgt_len = tgt.shape
tgt_vocab_size = self.decoder.W_s.out_features
outputs = torch.zeros(batch_size, tgt_len, tgt_vocab_size)
encoder_all_hidden, hidden, cell = self.encoder(src)
input_token = tgt[:, 0]
for t in range(1, tgt_len):
output, hidden, cell = self.decoder(input_token, hidden, cell, encoder_all_hidden)
outputs[:, t] = output
teacher_force = torch.rand(1).item() < teacher_forcing_ratio
input_token = tgt[:, t] if teacher_force else output.argmax(1)
return outputs範例
以下程式碼顯示如何使用本文章中的 Bahdanau attention 和 Luong attention 的實作。當使用 Luong attention model 時,我們還可以選擇要使用的 score function。
from bahdanau_attention import *
from luong_attention import *
SOS_TOKEN = 0
EOS_TOKEN = 1
PAD_TOKEN = 2
english_sentences = [
"hello world",
"good morning",
"i love you",
"cat",
"dog",
"go home",
]
spanish_sentences = [
"hola mundo",
"buenos dias",
"te amo",
"gato",
"perro",
"ve a casa",
]
def build_vocab(sentences):
vocab = list(set([word for sentence in sentences for word in sentence.split(" ")]))
vocab = ["<sos>", "<eos>", "<pad>"] + vocab
tkn2idx = {tkn: idx for idx, tkn in enumerate(vocab)}
idx2tkn = {idx: tkn for tkn, idx in tkn2idx.items()}
return vocab, tkn2idx, idx2tkn
def convert_sentence_to_idx(sentence, tkn2idx):
sentence_idx = [tkn2idx[tkn] for tkn in sentence.split(" ")]
sentence_idx.insert(0, SOS_TOKEN)
sentence_idx.append(EOS_TOKEN)
return sentence_idx
def pad_sentence(sentence, max_len):
return sentence + [PAD_TOKEN] * (max_len - len(sentence))
src_vocab, src_tkn2idx, src_idx2tkn = build_vocab(english_sentences)
tgt_vocab, tgt_tkn2idx, tgt_idx2tkn = build_vocab(spanish_sentences)
src_sentences = [convert_sentence_to_idx(sentence, src_tkn2idx) for sentence in english_sentences]
tgt_sentences = [convert_sentence_to_idx(sentence, tgt_tkn2idx) for sentence in spanish_sentences]
src_max_len = max([len(sentence) for sentence in src_sentences])
tgt_max_len = max([len(sentence) for sentence in tgt_sentences])
src_sentences = [pad_sentence(sentence, src_max_len) for sentence in src_sentences]
tgt_sentences = [pad_sentence(sentence, tgt_max_len) for sentence in tgt_sentences]
ENCODER_EMBEDDING_DIM = 16
ENCODER_HIDDEN_DIM = 32
DECODER_EMBEDDING_DIM = 16
DECODER_HIDDEN_DIM = 32
ATTENTION_HIDDEN_DIM = 32
LEARNING_RATE = 0.01
EPOCHS = 50
using = "luong" # "bahdanau" or "luong"
loung_attention = "concat" # "general", "concat", or "dot"
if using == "bahdanau":
encoder = BahdanauAttentionEncoder(len(src_tkn2idx), ENCODER_EMBEDDING_DIM, ENCODER_HIDDEN_DIM, DECODER_HIDDEN_DIM)
decoder = BahdanauAttentionDecoder(
len(tgt_tkn2idx), DECODER_EMBEDDING_DIM, DECODER_HIDDEN_DIM, ENCODER_HIDDEN_DIM, ATTENTION_HIDDEN_DIM
)
model = BahdanauAttentionModel(encoder, decoder)
else:
if loung_attention == "general":
attention = LuongGeneralAttention(DECODER_HIDDEN_DIM)
elif loung_attention == "concat":
attention = LuongConcatAttention(DECODER_HIDDEN_DIM)
else:
attention = LuongDotAttention()
encoder = LuongAttentionEncoder(len(src_vocab), ENCODER_EMBEDDING_DIM, ENCODER_HIDDEN_DIM, DECODER_HIDDEN_DIM)
decoder = LuongAttentionDecoder(attention, len(tgt_vocab), DECODER_EMBEDDING_DIM, DECODER_HIDDEN_DIM)
model = LuongAttentionModel(encoder, decoder)
optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
criterion = nn.CrossEntropyLoss(ignore_index=PAD_TOKEN)
def train():
training_pairs = []
for src, tgt in zip(src_sentences, tgt_sentences):
src_tensor = torch.tensor(src, dtype=torch.long)
tgt_tensor = torch.tensor(tgt, dtype=torch.long)
training_pairs.append((src_tensor, tgt_tensor))
for epoch in range(EPOCHS):
total_loss = 0
for src_tensor, tgt_tensor in training_pairs:
src_tensor = src_tensor.unsqueeze(0)
tgt_tensor = tgt_tensor.unsqueeze(0)
optimizer.zero_grad()
outputs = model(src_tensor, tgt_tensor)
outputs_dim = outputs.shape[-1]
outputs = outputs[:, 1:, :].reshape(-1, outputs_dim)
tgt = tgt_tensor[:, 1:].reshape(-1)
loss = criterion(outputs, tgt)
loss.backward()
optimizer.step()
total_loss += loss.item()
if (epoch + 1) % 10 == 0:
print(f"Epoch: {epoch + 1}, Loss: {total_loss}")
def translate_beam_search(sentence, beam_width=3, max_length=10):
model.eval()
src_idx = convert_sentence_to_idx(sentence, src_tkn2idx)
src_idx = pad_sentence(src_idx, src_max_len)
src_tensor = torch.tensor(src_idx, dtype=torch.long)
with torch.no_grad():
src_tensor = src_tensor.unsqueeze(0)
if using == "bahdanau":
encoder_all_hidden, decoder_hidden = model.encoder(src_tensor)
else:
encoder_all_hidden, decoder_hidden, decoder_cell = model.encoder(src_tensor)
if using == "bahdanau":
beam = [([SOS_TOKEN], decoder_hidden, None, 0.0)]
else:
beam = [([SOS_TOKEN], decoder_hidden, decoder_cell, 0.0)]
completed_sentences = []
for _ in range(max_length):
new_beam = []
for tokens, decoder_hidden, decoder_cell, score in beam:
if tokens[-1] == EOS_TOKEN:
completed_sentences.append((tokens, score))
new_beam.append((tokens, decoder_hidden, decoder_cell, score))
continue
input_index = torch.tensor([tokens[-1]], dtype=torch.long)
with torch.no_grad():
if using == "bahdanau":
prediction, decoder_hidden = model.decoder(input_index, decoder_hidden, encoder_all_hidden)
else:
prediction, decoder_hidden, decoder_cell = model.decoder(
input_index, decoder_hidden, decoder_cell, encoder_all_hidden
)
log_probs = torch.log_softmax(prediction, dim=1).squeeze(0)
topk = torch.topk(log_probs, beam_width)
for tkn_idx, tkn_score in zip(topk.indices.tolist(), topk.values.tolist()):
new_tokens = tokens + [tkn_idx]
new_score = score + tkn_score
new_beam.append((new_tokens, decoder_hidden, decoder_cell, new_score))
new_beam.sort(key=lambda x: x[3], reverse=True)
beam = new_beam[:beam_width]
for tokens, decoder_hidden, decoder_cell, score in beam:
if tokens[-1] != EOS_TOKEN:
completed_sentences.append((tokens, score))
completed_sentences.sort(key=lambda x: x[1], reverse=True)
best_tokens, best_score = completed_sentences[0]
if best_tokens[0] == SOS_TOKEN:
best_tokens = best_tokens[1:]
if EOS_TOKEN in best_tokens:
best_tokens = best_tokens[:best_tokens.index(EOS_TOKEN)]
return " ".join([tgt_idx2tkn[idx] for idx in best_tokens])
def test():
test_sentences = [
"hello world",
"i love you",
"cat",
"go home",
]
for sentence in test_sentences:
translation = translate_beam_search(sentence)
print(f"src: {sentence}, tgt: {translation}")
if __name__ == '__main__':
train()
test()結語
Bahdanau 使用的 alignment model 是加法計算方法,所以計算量較大但通常更具表現力,因此它適合需要捕捉複雜細微對齊關係的情境。Luong 採用的乘性方法計算更簡單,速度較快且更易擴展,因此在需要快速訓練和推論或計算資源有限時更為合適。
參考
- Dzmitry Bahdanau, KyungHyun Cho, and Yoshua Bengio. 2015. Neural Machine Translation by Jointly Learning to Align and Translate. In ICLR.
- Minh-Thang Luong, Hieu Pham, and Christopher Manning. 2015. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1412–1421.









